这是一个有关Paxos算法非常形象的讲解与示范。Paxos是能够基于一大堆完全不可靠的网络条件下却能可靠确定地实现共识一致性的算法。也就是说:它允许一组不一定可靠的处理器(服务器)在某些条件得到满足情况下就能达成确定的安全的共识,如果条件不能满足也确保这组处理器(服务器)保持一致。
什么是共识?
具体来说是这样:分布式系统中由于网络之间通讯可能会中断,虽然概率很低,但是没有100%完美的网络因此,依靠网络通讯的计算机之间要达成共识就比较困难,假设有X, Y和Z三台计算机谋划在周一攻击人类世界,它们的攻击计划是只要所有计算机可用于战斗时就一起进行攻击,不落下任何一台机器,但是当他们决定具体什么时间开始攻击时,在这个关键问题上往往会出错。
一个基本问题是,每台机器都有自己的攻击时间建议,计算机X可以建议在08:00时间,因为这个时间正是周一早晨,而人们刚刚过完狂欢的周末休息天,但是计算机Z认为13:00比较好,理由当然也有一大堆,让这三台计算机基于某个时刻达成共识是非常困难的,因此,也给人类反击留下了机会。
另外一个情况是,这三台计算机是位于世界不同的位置,之间通讯或许通过电缆或者其他不太可靠的网络设备通讯,如果X建议在08:00,它必须确认它的这个建议能够到达活着的Y和Z,以免一个人战斗。
问题是:我们不能准确地知道某个计算机的延迟的原因:是因为性能慢了还是已经是彻底死机不能用?
那么,X怎么知道其他两个计算机是可用的呢?也就是说,当X和其他两个计算机通讯发现得到响应要过很长时间,它不能确定这两台计算机到底还能不能继续活下去,也许这次通讯有延迟了,下一次它们又活过来了没有延迟了,也许下次延迟更长了一点,也许下次延迟稍微短了一点,这些随机概率问题使得X不能确定Y和Z到底是出了什么问题造成延迟的,是因为处理了某个特别耗费CPU的任务还是因为死锁等原因?当然,有些天真的设计者会说,只要我们将性能监控到位,如果延迟超过一定时间,我们人工介入告诉X确切情况就可以,那么这种人工介入的分布式系统不是一个天然自洽的自动化系统了,不在我们讨论范围之内,而且这样的系统会让人疲于奔命。
因为X不能确定Y或Z是否可用,所以X仅仅只能和Y与Z中一台基于攻击时间达成共识,就无法完全三台机器全部投入战斗的计划。注意的是,X Y Z三台中任何一台都可能会出现延迟,这就造成了三台机器之间任何通讯都是无法确认可靠的,比如X发出消息给Z,Z确认后回执给X,但是这段时间X突然死机了,那么Z要等待X多长时间才能知道它收到确认呢?还是再次等待X回复确认的确认,这样无限循环下去也不能解决它们之间通讯可能出现随机不可靠的问题。
所有关键问题在于:由于这三台机器之间通讯是无法保证100%可靠,它们就不能就任何事情达成共识。
下面以分布式拍卖案例说明这种情况以及Paxos的基本原理?
在传统拍卖场景中,价高者先得,这些拍卖者都是在同一个房间,彼此能够直接看得到对方的报价,如果我们假设分布式拍卖是将这些拍卖者分离到不同的地方,这样我们可以用拍卖者之间的联系模拟分布式计算机之间的通讯。
假设拍卖者各自在自己家里拍卖,通过邮局信件发出自己的拍卖信息,拍卖者之间除非等到邮局投递人告诉他们彼此之间的报价,否则是无法知道对方报价的。如果邮局信件投递这个环节出了问题,投递速度慢了甚至无法投递了,那么整个拍卖程序就无法继续进行下去。
Paxos解决共识思路
Paxos是一个解决共识问题consensus problem的算法,现实中Paxos的实现以及成为一些世界级软件的心脏,如Cassandra, Google的 Spanner数据库, 分布式锁服务Chubby. 一个被Paxos管理的系统实际上谈论的是值 状态和跟踪等问题,其目标是建造更高可用性和强一致性的分布式系统。
Paxos完成一次写操作需要两次来回,分别是prepare/promise, 和 propose/accept:
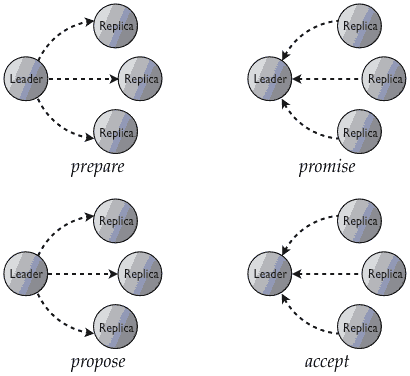
第一次由提交者Leader向所有其他服务器发出prepare消息请求准备,所有服务器中大多数如果回复诺言承诺就表示准备好了,可以接受写入;第二次提交者向所有服务器发出正式建议propose,所有服务器中大多数如果回复已经接收就表示成功了。
为了详细描述这个两段过程,首先让我们定义一下我们将使用的一些名词术语:
- 一个流程是系统中计算机的一个. 人们使用有关复制或节点等词语表达,都差不多。
- 一个客户端是属于系统中一个成员的计算机,但是询问系统值是什么或者要求系统获取一个新的值。
Paxos构建分布式数据库的小片段: 它仅仅实现流程将一个新的东西精确地写入系统中,流程是由Paxos的一个实例管治,可以失败或者不知道任何东西、或者大多数流程都知道一个同样的值,这就是共识,Paxos并不真的告诉我们如何用它来构建数据库或类似的东西,它只是负责独立节点之间通讯的流程, 这些流程服务器会基于一个新值执行决定,Paxos会存储一个值数据,只是一次性的,一旦你第一次设置以后就不能再改变它。
Paxo读操作
其实Paxos精华是在写操作,将读操作放在写操作前面讲解,是着重Paxos以大多数服务器达成共识为重要标志,通过读取判断是否达成共识这一状态。
为了从Paxos系统中读取一个值数据,客户端会请求读取所有流程中存储的当前值,然后从大多数流程服务器中获得这个值,如果数量凑不够大多数或者没有足够的客户端响应,读取操作失败,下面图示你会看到一个客户端询问其他节点他们的值是多少,这些节点返回值给客户端,当客户端获得了大多数节点的响应,返回的值都是同样的,它就算成功地读操作了,并顺便保存读结果。
与单节点系统(只有一台服务器)相比这有些奇怪,这两个系统中,客户端都需要观察系统已决定状态,但是在非分布式系统中像MySQL或一个memcached服务器中, 客户端只需直接向标准的状态存储的服务器地址获取状态即可,在简单的Paxos中, 客户端也是同样的方式观察状态,但是因为并没有标准的状态存储的服务器地址,它需要询问所有的成员,以便能够确定仅有一个会报告值数据,实际上是大多数节点都持有的值数据,如果客户端询问一个节点,有可能这个节点流程已经过期,得到了错误的值数据,流程失效过期的原因有很多:由于不可靠的网络导致本应送达到它们的消息丢失了;或者他们也许当机然后使用了一个过期状态恢复;或者算法还在运行计算中,流程并没有正好得到消息等等。在现实中使用Paxos实现时,其实不需要每个节点都进行一次读取,会有更好的读取方式,但是他们都是拓展的原始 Paxos 算法。
Paxos写操作
当一个客户端要求写入系统一个新值时,让我们看看Paxos让我们集群的流程都做了什么?下面的过程都是只有一个值的写入,最终我们能用这个流程作为原始数据,允许值数据在彼此之间一个个设置,但是基本的Paxos算法管治了一个新值数据的写操作流程, 然后做重复的事情。
首先Paxos管理的系统中一个客户端要求写入一个新值,客户端这里如图所示是红圈,其它流程是蓝圈, Paxos能保证客户端发送它们的写请求到Paxos集群中任何成员, 这里演示中客户端随机挑选流程中任意一个,这种方式是重要且巧妙的,意味著没有任何单点风险,意味着我们的Paxos管治系统能继续保持在线可用,无论任何一个节点当机或其他不可用原因无响应。如果我们设计一个特定节点作为“推荐人proposer”或者 "the master" 等, 如果这个主节点死机,那么整个系统就崩溃了。
当写请求被接受后,Paxos流程会接受这个写新值到系统中请求“建议”, “建议”是Paxos中一个正式概念: 向一个Paxos管治的系统建议可能会成功或失败,需要步骤来确保共识能够达成维系,这个建议以准备消息从那些与客户端连接的流程节点们被发往整个系统。
序列号
这个准备消息保存在被建议的值数据中,它们也称为序列号sequence number,序列号是由建议流程产生的,它定义了接受流程应该准备接受带有序列号的建议,这个序列号是关键: 它用于表明新旧建议之间的区别,如果两个流程试图获得需要设置一个值,Paxos认为最后一个流程应该有优先权,这样让流程分辨哪个是最后一个,这样它就能设置最新的值。
这些接受的流程能够进行在系统中关键的检查:这个在到来的准备消息中序列号是我见过的最高级别吗?如果是,那就很cool, 我能准备好接受将要到来的值数据,那就不要管之前听到的任何其他值数据了,你能看到这个过程在右边演示中:客户端每隔一段向一个流程建议一个新值,这个流程发送准备消息给其他流程,然后那些流程注意到这是一个成功的更高的超过旧的新序列号,然后就放手那些旧建议。
这里有一个顺序的设计(先发送准备消息),这是为避免单点风险,如果没有这个顺序,Paxos中成员就无法分辨哪个建议是他们可以有信心地准备接受的。
我们不能想象有另外不同的共识算法,不是按照如下步骤:首先发送第一个消息询问其他流程,以确保将设置的新值是最新的值,尽管方式可以再简单些,但是可能就不能满足共识算法安全的需求了,如果两个流程正好同时建议不同的值,如下所示:
大自然经常会这样欺骗我们,每个包都能另外一半的流程相信它们接受的也许是正确也许是错误的值,系统将进入一个僵局,存在两个相同数量的组却有不同的值,那么就无法确定大多数这个概念了,这个僵局能够被第一个Paxos消息避免,因为Paxos的序列号,那些有问题的建议将有被其他更低的序列号,这样序列号更高的建议就会毫不含糊地被大多数流程接收,它们也首先获得了更高的序列号,然后如果接受到更低的序列号就会拒绝,Paxos 就是这样通过用序列号控制整个系统的时间节奏。
注意:保证没有两个建议使用相同的序列号是很重要的,这是确保他们的顺序,这样每个序列号只有一个建议,这样才能比较两个建议,实现Paxos时,全局唯一有序的序列号实际是精确系统时间和集群中节点数量的拷贝,随着时间不断增加,从来不会重复。
Paxos第一阶段:准备Perpare/诺言Promises
Paxos的第一阶段是prepare/promise,准备阶段就是将建议值发送到各个目标节点。
当建议被发到目标节点后,流程会会检查建议中的序列号,是否是它们见到过的最高级,如果是最高级,它们会发出一个promise不再接受比这个新序列号更旧的建议了,这个诺言promise作为消息从许下诺言的流程发到提交建议新值的流程服务器,这个诺言消息给提交建议的流程后,提交建议的流程需要自己统计一下有多少其他流程已经发回它们的诺言promise了,如果判断数量上是否达到大多数?如果大多数流程已经同意接受这个建议或者更高级序列号的建议,这个提交建议的流程就能知道它获得了发言权(因为有大多数支持),这样就开始讲话,算法中的下一步处理将可能进行;如果回复诺言的节点数量没有达到大多数,也就是共识没有达成,这样这个节点提交的建议将退出,客户端要求的写操作失败。
为了决定一个建议是否已经有足够的回复诺言promises, 提交建议者只是统计一下它接受到的 promise 消息数量,然后和整个系统中节点服务器数量比较一下,“足够”意味着大多数(N/2 + 1)个流程服务器在某段时间内都回复了诺言promises。如果超过一半的流程服务器没有返回诺言,这意味着这个建议没有被大多数通过,那么在前面描述的读算法中就不能满足大多数的要求,也就不能达成共识,这个建议就退出。其他包括网络分区错误也可能会阻止大多数达成共识,
第二阶段:Paoxs接纳Acceptance
当完成prepare/promise阶段,进入了 propose/accept阶段。
一旦建议提交者已经从大多数其他流程服务器获得了诺言,它会要求许诺的流程服务器接收它们之前承诺接受的新值数据,这是一个“确认commit”阶段,如果没有冲突建议 失败或分区错误,那么这个新建议将被所有其他节点接受,那么Paxos过程就完成了。
你能看到右边的演示,注意这个演示比上面promise在最后多了一个动作,也就是提交建议者将新值发给那些许诺言的流程服务器,让它们接受了这个新值。
接受的过程也许可能会发生失败,在回复了诺言消息以后,在接受到Accept消息之前,如果有足够多的服务器正好在这个时间段失败,那么接受行为只能是少数服务器,那么Paxos进入了厄运状态:一些流程服务器接受了新值,而不是全部的,这种不一致已经在前面读操作中描述:一个客户端试图从系统中大多数节点服务器读取它们同意接受的值,它发现一些节点服务器报告有不同的值数据,这会引起读失败,但是Paxos还保持一致性,不允许在没有达成共识情况下任何写操作发生,这种坏的情况在实践中经常通过重复接受阶段来让大多数节点最终接受。
总结
Paxos算法是保证在分布式系统中写操作能够顺利进行,保证系统中大多数状态是一致的,没有机会看到不一致,因此,Paxos算法的特点是一致性>可用性。
vector clock向量时钟是另外一种保证复制的算法,其特点是可用性>一致性,但是,一旦发生冲突,不像Paxos能自行解决,需要人工干预编写代码解决。
Paxos算法和Vector Clock都是由Leslie Lamport提出。
Raft算法
最终一致性其实比MVCC简单
ACID中C与CAP定理中C的区别
Cassandra 2.0的轻量事务
CAP定理
分布式事务
转自:https://www.jdon.com/artichect/paxos.html