1.读取
# 读取数据 def read_dataset(): # 打开csv文件 sms = open('../data/SMSSpamCollection', 'r', encoding='utf-8') sms_label = [] # 标题 sms_data = [] # 数据 # 读取csv数据 csv_reader = csv.reader(sms, delimiter=' ') for line in csv_reader: sms_label.append(line[0]) # 提取出标签 sms_data.append(preprocessing(line[1])) # 对每封邮件做预处理 sms.close() return sms_data, sms_label
2.数据预处理
# 数据预处理 def preprocessing(text): tokens = [word for sent in nltk.sent_tokenize(text) for word in nltk.word_tokenize(sent)] # 分词 stops = stopwords.words('english') # 使用英文的停用词表 tokens = [token for token in tokens if token not in stops] # 停用词 tokens = [token.lower() for token in tokens if len(token) >= 3] # 大小写、长度<3 tag = nltk.pos_tag(tokens) # 词性 lmtzr = WordNetLemmatizer() tokens = [lmtzr.lemmatize(token, pos=get_wordnet_pos(tag[i][1])) for i, token in enumerate(tokens)] # 词性还原 preprocessed_text = ' '.join(tokens) return preprocessed_text
3.数据划分—训练集和测试集数据划分
from sklearn.model_selection import train_test_split
x_train,x_test, y_train, y_test = train_test_split(data, target, test_size=0.2, random_state=0, stratify=y_train)
def split_dataset(data, label): x_train, x_test, y_train, y_test = train_test_split(data, label, test_size=0.2, random_state=0, stratify=label) return x_train, x_test, y_train, y_test
4.文本特征提取
sklearn.feature_extraction.text.CountVectorizer
sklearn.feature_extraction.text.TfidfVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf2 = TfidfVectorizer()
观察邮件与向量的关系
向量还原为邮件
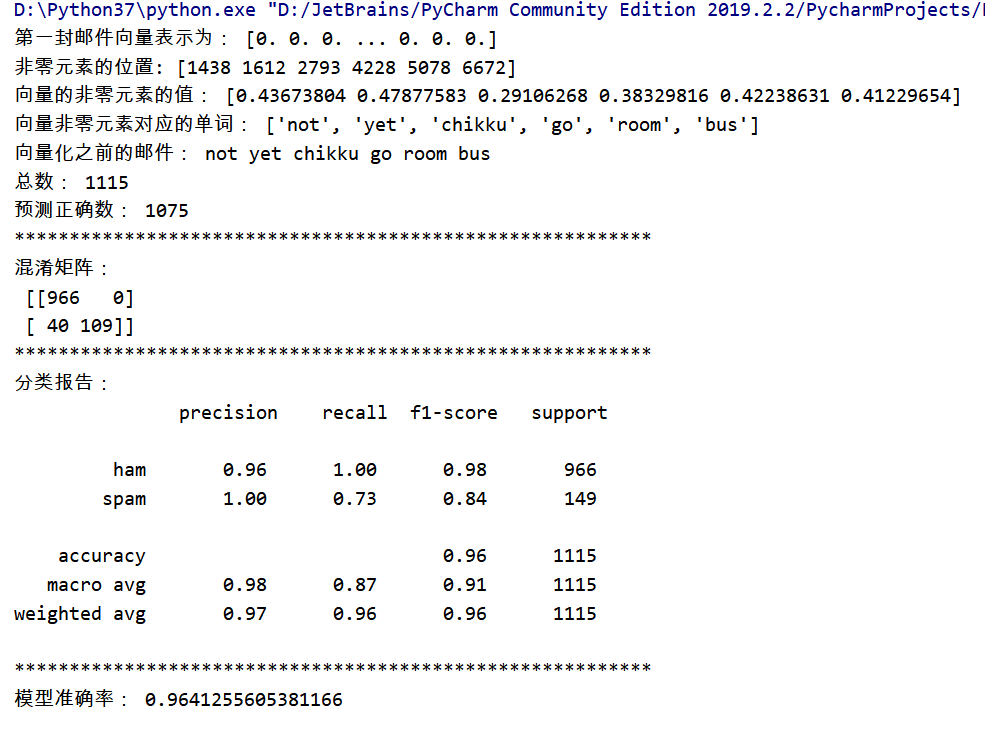
# 把原始文本转化为tf-idf的特征矩阵 def tfidf_dataset(x_train, x_test): tfidf = TfidfVectorizer() X_train = tfidf.fit_transform(x_train) # X_train用fit_transform生成词汇表 X_test = tfidf.transform(x_test) # X_test要与X_train词汇表相同,因此在X_train进行fit_transform基础上进行transform操作 return X_train, X_test, tfidf # 向量还原邮件 def revert_mail(x_train, X_train, model): s = X_train.toarray()[0] print("第一封邮件向量表示为:", s) # 该函数输入一个矩阵,返回扁平化后矩阵中非零元素的位置(index) a = np.flatnonzero(X_train.toarray()[0]) # 非零元素的位置(index) print("非零元素的位置:", a) print("向量的非零元素的值:", s[a]) b = model.vocabulary_ # 词汇表 key_list = [] for key, value in b.items(): if value in a: key_list.append(key) # key非0元素对应的单词 print("向量非零元素对应的单词:", key_list) print("向量化之前的邮件:", x_train[0])
4.模型选择
from sklearn.naive_bayes import GaussianNB
from sklearn.naive_bayes import MultinomialNB
说明为什么选择这个模型?
解析:模型需要根据数据集中特征的特点来进行选取,垃圾邮件分类重点在于文档中单词出现的频率以及文档的重要性,不符合正态分布的特征。应选择多项式分布模型。比如鸢尾花数据等,其中判定是否为鸢尾花需要通过4种特征判断,并且这4种特征大小分布范围呈正态分布形状,因此鸢尾花的判断可以采用高斯型分布较为合适。
# 模型选择(根据数据特点选择多项式分布) def mnb_model(x_train, x_test, y_train, y_test): mnb = MultinomialNB() mnb.fit(x_train, y_train) ypre_mnb = mnb.predict(x_test) print("总数:", len(y_test)) print("预测正确数:", (ypre_mnb == y_test).sum()) return ypre_mnb
5.模型评价:混淆矩阵,分类报告
from sklearn.metrics import confusion_matrix
confusion_matrix = confusion_matrix(y_test, y_predict)
说明混淆矩阵的含义
混淆矩阵:
True Positive(真正,TP):将正类预测为正类数
True Negative(真负,TN):将负类预测为负类数
False Positive(假正,FP):将负类预测为正类数误报 (Type I error)
False Negative(假负,FN):将正类预测为负类数→漏报 (Type II error)
说明准确率、精确率、召回率、F值分别代表的意义
意义:
准确率:被分对的样本数除以所有的样本数,通常来说,正确率越高,分类器越好。(TP+TN)/总
精确率:表示被分为正例的示例中实际为正例的比例。 TP/(TP+FP)
召回率 :召回率是覆盖面的度量,度量有多个正例被分为正例。TP/(TP+FN)
F值 : 精确率 * 召回率 * 2 / ( 精确率 + 召回率) 。F值就是准确率(P)和召回率(R)的加权调和平均。
# 模型评价:混淆矩阵,分类报告 def class_report(ypre_mnb, y_test): conf_matrix = confusion_matrix(y_test, ypre_mnb) print("**********************************************************") print("混淆矩阵: ", conf_matrix) c = classification_report(y_test, ypre_mnb) print("**********************************************************") print("分类报告: ", c) print("**********************************************************") print("模型准确率:", (conf_matrix[0][0] + conf_matrix[1][1]) / np.sum(conf_matrix))
★整体代码实现如下:
from sklearn.model_selection import train_test_split from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.naive_bayes import MultinomialNB from sklearn.metrics import confusion_matrix, classification_report import numpy as np import nltk from nltk.corpus import stopwords from nltk.stem import WordNetLemmatizer import csv # 根据词性,生成还原参数pos def get_wordnet_pos(treebank_tag): if treebank_tag.startswith('J'): # 形容词 return nltk.corpus.wordnet.ADJ elif treebank_tag.startswith('V'): # 动词 return nltk.corpus.wordnet.VERB elif treebank_tag.startswith('N'): # 名词 return nltk.corpus.wordnet.NOUN elif treebank_tag.startswith('R'): # 副词 return nltk.corpus.wordnet.ADV else: return nltk.corpus.wordnet.NOUN # 数据预处理 def preprocessing(text): tokens = [word for sent in nltk.sent_tokenize(text) for word in nltk.word_tokenize(sent)] # 分词 stops = stopwords.words('english') # 使用英文的停用词表 tokens = [token for token in tokens if token not in stops] # 停用词 tokens = [token.lower() for token in tokens if len(token) >= 3] # 大小写、长度<3 tag = nltk.pos_tag(tokens) # 词性 lmtzr = WordNetLemmatizer() tokens = [lmtzr.lemmatize(token, pos=get_wordnet_pos(tag[i][1])) for i, token in enumerate(tokens)] # 词性还原 preprocessed_text = ' '.join(tokens) return preprocessed_text # 读取数据 def read_dataset(): # 打开csv文件 sms = open('../data/SMSSpamCollection', 'r', encoding='utf-8') sms_label = [] # 标题 sms_data = [] # 数据 # 读取csv数据 csv_reader = csv.reader(sms, delimiter=' ') for line in csv_reader: sms_label.append(line[0]) # 提取出标签 sms_data.append(preprocessing(line[1])) # 对每封邮件做预处理 sms.close() return sms_data, sms_label # 划分数据集 def split_dataset(data, label): x_train, x_test, y_train, y_test = train_test_split(data, label, test_size=0.2, random_state=0, stratify=label) return x_train, x_test, y_train, y_test # 把原始文本转化为tf-idf的特征矩阵 def tfidf_dataset(x_train, x_test): tfidf = TfidfVectorizer() X_train = tfidf.fit_transform(x_train) # X_train用fit_transform生成词汇表 X_test = tfidf.transform(x_test) # X_test要与X_train词汇表相同,因此在X_train进行fit_transform基础上进行transform操作 return X_train, X_test, tfidf # 向量还原邮件 def revert_mail(x_train, X_train, model): s = X_train.toarray()[0] print("第一封邮件向量表示为:", s) # 该函数输入一个矩阵,返回扁平化后矩阵中非零元素的位置(index) a = np.flatnonzero(X_train.toarray()[0]) # 非零元素的位置(index) print("非零元素的位置:", a) print("向量的非零元素的值:", s[a]) b = model.vocabulary_ # 词汇表 key_list = [] for key, value in b.items(): if value in a: key_list.append(key) # key非0元素对应的单词 print("向量非零元素对应的单词:", key_list) print("向量化之前的邮件:", x_train[0]) # 模型选择(根据数据特点选择多项式分布) def mnb_model(x_train, x_test, y_train, y_test): mnb = MultinomialNB() mnb.fit(x_train, y_train) ypre_mnb = mnb.predict(x_test) print("总数:", len(y_test)) print("预测正确数:", (ypre_mnb == y_test).sum()) return ypre_mnb # 模型评价:混淆矩阵,分类报告 def class_report(ypre_mnb, y_test): conf_matrix = confusion_matrix(y_test, ypre_mnb) print("**********************************************************") print("混淆矩阵: ", conf_matrix) c = classification_report(y_test, ypre_mnb) print("**********************************************************") print("分类报告: ", c) print("**********************************************************") print("模型准确率:", (conf_matrix[0][0] + conf_matrix[1][1]) / np.sum(conf_matrix)) if __name__ == '__main__': sms_data, sms_label = read_dataset() # 读取数据集 x_train, x_test, y_train, y_test = split_dataset(sms_data, sms_label) # 划分数据集 X_train, X_test, tfidf = tfidf_dataset(x_train, x_test) # 把原始文本转化为tf-idf的特征矩阵 revert_mail(x_train, X_train, tfidf) # 向量还原成邮件 y_mnb = mnb_model(X_train, X_test, y_train, y_test) # 模型选择 class_report(y_mnb, y_test) # 模型评价
测试结果如下:
6.比较与总结
如果用CountVectorizer进行文本特征生成,与TfidfVectorizer相比,效果如何?
CountVectorizer:只考虑词汇在文本中出现的频率,属于词袋模型特征。
TfidfVectorizer: 除了考滤某词汇在文本出现的频率,还关注包含这个词汇的所有文本的数量。能够削减高频没有意义的词汇出现带来的影响, 挖掘更有意义的特征。属于Tfidf特征。
相比之下,文本条目越多,Tfid的效果会越显著。
CountVectorizer与TfidfVectorizer相比,对于负类的预测更加准确,而正类的预测则稍逊色。但总体预测正确率也比TfidfVectorizer稍高,相比之下似乎CountVectorizer更适合进行预测。总的来看,用CountVectorizer虽在总样本中表现看似优秀,但其实际对样本个体预测的误差要高于使用TfidfVectorizer。因为TfidfVectorizer能够过滤掉一些常见的却无关紧要本的词语,同时保留影响整个文本的重要字词,更适用于垃圾邮件分类。