模块:用来从逻辑上组织代码,本质是.py结尾的Python文件。
Python Package(包): 用来从逻辑上组织模块,本质是文件夹,必须带有__init__.py文件。
导入模块:
1、import module_name1,module_name2...... 导入模块文件,调用时用module_name.variable_name。
2、from module_name import * 导入模块文件内的所有代码,调用时直接用模块内的变量名称。如果当前文件内有变量和模块文件内的变量同名的话,就近执行,哪个最近解释的就执行哪个。
3、from module import func as func_module 使用as关键字区分当前文件内的变量和模块文件内的变量。
4、from module import func as func_module1,func2 as func_module2
推荐1、3、4方法。
import module_name本质:把模块文件运行一遍,然后把模块文件内容赋值给模块文件名。调用格式:module_name.variable_name
from module import func本质:解释模块中的func。调用格式:variable_name
导入包:import package_name
当前文件与package文件同级。
导入包的本质:运行package目录下的__init__.py文件。
模块分类:
1、标准库,Python自带
2、开源模块,第三方模块
3、自定义模块
time模块:
时间戳:从1970年1月1日零时起至今的秒数;
格式化时间:字符串表示时间,可以自定义格式;
%Y:年
%m:月
%d:日
%A:星期几
%H:时
%M:分
%S:秒
struct_time:元组方式表示时间,有9个元素
不同时间表示方法之间的转化:
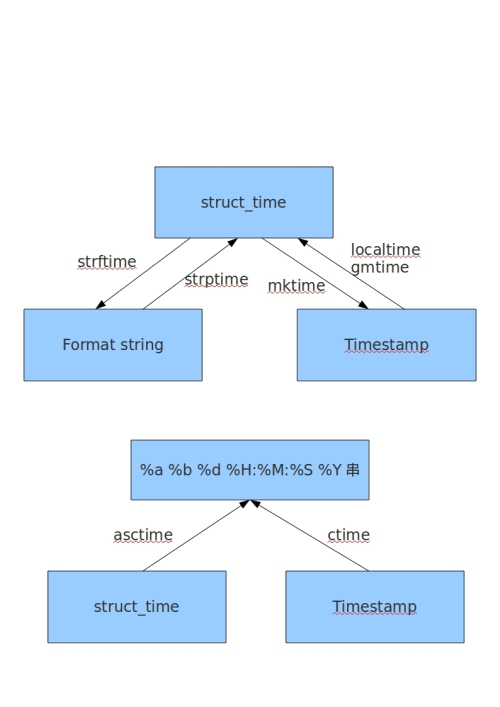
time.time()
返回时间戳模式的时间:
1538570674.6409438
time.localtime()
返回元组形式的本地时间:
time.struct_time(tm_year=2018, tm_mon=10, tm_mday=3, tm_hour=20, tm_min=45, tm_sec=45, tm_wday=2, tm_yday=276, tm_isdst=0)
time.gmtime()
返回元组形式的标准时间:
time.struct_time(tm_year=2018, tm_mon=10, tm_mday=3, tm_hour=12, tm_min=45, tm_sec=55, tm_wday=2, tm_yday=276, tm_isdst=0)
random模块:
import random print(random.random()) #随机产生0-1之间的浮点数 print(random.uniform(5,10)) #随机产生5-10之间的浮点数 print(random.randrange(0,101,5)) #随机产生0-101且步长为5的整数 print(random.choice(range(0,101,5))) #随机产生0-101且步长为5的整数 print(random.randint(0,10)) #随机产生0-10的整数,包括10 print(random.choice('abcdefg123456789')) #从序列中随机选择一个元素 print(random.sample([1,2,3,4,5,6],2)) #从样本中随机选择2个元素,输出为list items=[1,2,3,4,5,6] random.shuffle(items) #打乱items的排列顺序,改变items。 print(items)
其中,random.choice()和random.sample()参数均是序列。序列可以是list,tuple,string,不可以是字典。
OS模块:
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.curdir 返回当前目录: ('.')
os.pardir 获取当前目录的父目录字符串名:('..')
os.makedirs('dirname1/dirname2') 可生成多层递归目录
os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() 删除一个文件
os.rename("oldname","newname") 重命名文件/目录
os.stat('path/filename') 获取文件/目录信息
os.sep 输出操作系统特定的路径分隔符,win下为"\",Linux下为"/"
os.linesep 输出当前平台使用的行终止符,win下为"
",Linux下为"
"
os.pathsep 输出用于分割文件路径的字符串
os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix'
os.system("bash command") 运行shell命令,直接显示
os.environ 获取系统环境变量
os.path.abspath(path) 返回path规范化的绝对路径
os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) 返回path最后的文件名。如何path以/或结尾,那么就会返回空值。即os.path.split(path)的第二个元素
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
sys模块:
sys.argv 命令行参数List,第一个元素是程序本身路径 sys.exit(n) 退出程序,正常退出时exit(0) sys.version 获取Python解释程序的版本信息 sys.maxint 最大的Int值 sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 sys.platform 返回操作系统平台名称
json和pickle模块:
用于序列化的两个模块
- json,用于字符串 和 python数据类型间进行转换
- pickle,用于python特有的类型 和 python的数据类型间进行转换
Json模块提供了四个功能:dumps、dump、loads、load
pickle模块提供了四个功能:dumps、dump、loads、load
shelve模块:
shelve模块是一个简单的k,v将内存数据通过文件持久化的模块,可以持久化任何pickle可支持的python数据格式。
import shelve
d = shelve.open('shelve_test') # 打开一个文件
name = ["alex", "rain", "test"]
d["test"] = name # 持久化列表
d.close()
读取数据:
import shelve
d=shelve.open("shelve_test")
print(d.get('test'))
输出:
['alex', 'rain', 'test']
XML模块:
现有xml文件内容如下:
<?xml version="1.0"?>
<data>
<country name="Liechtenstein">
<rank updated="yes">2</rank>
<year>2008</year>
<gdppc>141100</gdppc>
<neighbor name="Austria" direction="E"/>
<neighbor name="Switzerland" direction="W"/>
</country>
<country name="Singapore">
<rank updated="yes">5</rank>
<year>2011</year>
<gdppc>59900</gdppc>
<neighbor name="Malaysia" direction="N"/>
</country>
<country name="Panama">
<rank updated="yes">69</rank>
<year>2011</year>
<gdppc>13600</gdppc>
<neighbor name="Costa Rica" direction="W"/>
<neighbor name="Colombia" direction="E"/>
</country>
</data>
从此文件中获取信息:
import xml.etree.ElementTree as ET
tree = ET.parse("xmltest.xml") #xmltest.xml是xml文件名
root = tree.getroot()
print(root.tag)
# 遍历xml文档
for child in root:
print(child.tag, child.attrib)
for i in child:
print(i.tag, i.text,i.attrib)
# 只遍历year 节点
for node in root.iter('year'):
print(node.tag, node.text)
修改xml文件:
import xml.etree.ElementTree as ET
tree = ET.parse("xmltest.xml")
root = tree.getroot()
# 修改
for node in root.iter('year'):
new_year = int(node.text) + 1
node.text = str(new_year)
node.set("updated", "yes")
tree.write("xmltest.xml")
# 删除node
for country in root.findall('country'):
rank = int(country.find('rank').text)
if rank > 50:
root.remove(country)
tree.write('output.xml')
创建xml文件:
import xml.etree.ElementTree as ET
new_xml = ET.Element("people")
person1 = ET.SubElement(new_xml, "person1", attrib={"enrolled": "yes"})
person1.text="刚田武"
age = ET.SubElement(person1, "age", attrib={"checked": "no"})
age.text = '23'
sex = ET.SubElement(person1, "sex")
sex.text="男"
person2 = ET.SubElement(new_xml, "person2", attrib={"enrolled": "no"})
person2.text="猪刚鬣"
age = ET.SubElement(person2, "age")
age.text = '22'
sex = ET.SubElement(person2, "sex")
sex.text="男"
et = ET.ElementTree(new_xml) # 生成文档对象
et.write("朱二娃和基佬强.xml", encoding="utf-8", xml_declaration=True)
生成的xml文件不会自动换行。