模式识别与机器学习 [国科大]
模式: 为了能够让机器执行和完成识别任务,必须对分类识别对象进行科学的抽象,建立它的数学模型,用以描述和代替识别对象,这种对象的描述即为模式。
模式识别系统过程:
- 特征提取与选择
- 训练学习
- 分类识别
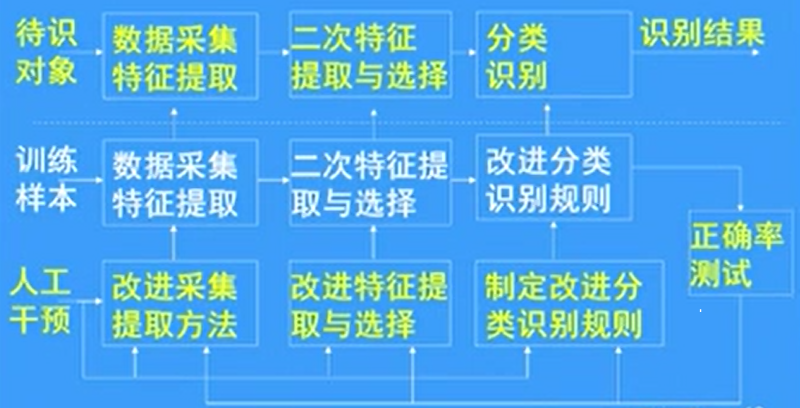
模式识别过程从信息层次、形态转换上讲,是由分析对象的物理空间通过特征提取转换为模式的特征空间,然后通过分类识别转换为输出的类别空间。
特征提取是对研究对象本质的特征进行量测并讲结果数值化或将对象分解并符号化,形成特征矢量、符号串或关系图,产生代表对象的模式。
特征选择是在满足分类识别正确率的条件下,按某种准则尽量选用对正确分类识别作用较大的特征,从而用较少的特征来完成分类识别任务。
在模式采集和预处理中,一般要用到模数(A/D)转换。A/D转换必须注意:
- 采样率,必须满足采样定理
- 量化等级,取决于精度要求
在数据采集过程中,一般我们会进行一些预处理过程,如
- 去噪声:消除或减少模式采集中的噪声及其它干扰,提高信杂比(信噪比)
- 去模糊:消除或减少数据图像模糊及几何失真,提高清晰度
- 模式结构转换:例如把非线性模式转变为线性模式,以利于后续处理,等等
预处理的方法包括: 滤波,变换,编码,归一化等
特征提取/选择的目的: 降低维数,减少内存消耗,使分类错误减小
分类: 把特征空间划分成类空间,影响分类错误率的因数:
- 分类方法
- 分类器的设计
- 提取的特征
- 样本质量
模式识别的主流技术有:
- 统计模式识别
- 结构模式识别
- 模糊模式识别
- 人工神经网络方法
- 人工智能方法
- 子空间法
统计模式识别直接利用各类的分布特征或隐含地利用概率密度函数、后验概率等概念进行分类识别。基本的技术有聚类分析、判别类域代数界面法、统计决策法、最近邻法等。
结构模式识别将对象分解为若干基本单元,即基元;其结构关系可以用字符串或图来表示,即句子;通过对句子进行句法分析,根据文法而决定其类别。
模糊模式识别将模式或模式类作为模糊集,将其属性转化为隶属度,运用隶属函数、模糊关系或模糊推理进行分类识别。
人工神经网络方法由大量的基本单元,即神经元互联而成的非线性动态系统。
人工智能方法研究如何是机器具有人脑功能的理论和方法,故将人工智能中有关学习、知识表示、推理等技术用于模式识别。
子空间法根据各类训练样本的相关阵通过线性变换由原始模式特征空间产生各类对应的子空间,每个子空间与每个类别一一对应。
特征矢量一个分析对象的n个特征量测值分别为 (x_1,x_2,...,x_3),它们构成一个n维特征矢量(x),(x = (x_1,x_2,...,x_n)^T,x)是原对象(样本)的一种数学抽象,用来代表原对象,即为原对象的模式。
特征空间对某对象的分类识别是对其模式,即它的特征矢量进行分类识别。各种不同取值的(x)的全体构成了(n)维空间,这个(n)维空间称为特征空间,不同场合特征空间可记为 (X^n, R^n)或(Omega)。特征矢量(x)便是特征空间中的一个点,所以特征矢量有时也称为特征点。
随机变量由于量测系统随机因素的影响及同类不同对象的特征本身就是在特征空间散步的,同一个对象或同一类对象的某特征测值是随机变量。由随机分量构成的矢量称为随机矢量。同一类对象的特征矢量在特征空间中是按某种统计规律随机散步的。
协方差矩阵和自相关矩阵都是对称矩阵。设(A)为对称矩阵,对任意的矢量(x, x^TAx)是(A)的二次型。若对任意的(x)恒有:
则称(A)为非负定矩阵。协方差矩阵是非负定的。
独立必不相关,反之不一定。
在正态分布的情况下,独立于不相关是等价的。
聚类分析概念
聚类分析基本思想:
假设 对象集客观存在着若干个自然类,每个自然类中个体的某些属性具有较强的相似性。
原理 将给定模式分成若干组,每组内的模式是相似的,而组间各模式差别较大。
该方法的有效性取决于分类算法和特征点分布情况的匹配。
分类无效的情况有:
- 特征选取不当使分类无效;
- 特征选择不足可能使不同类别的模式判为一类;
- 特征选取过多可能无益反而有害,增加分析负担并使分析效果变差;
- 量纲选择不当。
聚类分析过程:
- 特征提取
- 模式相似性度量
- 点与类之间的距离
- 类与类之间的距离
- 聚类准则及聚类算法
- 有效性分析
模式相似性测度
模式相似性测度方法
- 距离测度
- 相似测度
- 匹配测度
距离测度
测度基础: 两个矢量矢端的距离
测度数值:两矢量各相应分量之差的函数
欧式(Euclidean)距离
绝对值距离(Manhattan距离)
切氏(Chebyshev)距离
明(Minkowski)氏距离
马氏(Mahalanobis)距离
设n维矢量(vec x_i)和(vec x_j)是矢量集({vec x_1, vec x_2,...,vec x_m})中的两个矢量,马氏距离(d)定义为
其中
马氏距离具有平移不变性。
对于 (vec y = vec x)进行类变换即(vec y = Avec x),其中(A)为非奇异矩阵,马氏距离不变。
马氏距离的性质: 对于一切非奇异线性变化都是不变的。即,具有坐标系比例、旋转、平移不变性,并且从统计意义上尽量去掉了分量间的相关性。
例题

模式相似性测度
测度基础: 以两矢量的方向是否相近作为考虑的基础,矢量长度并不重要。设
- 角度相似系数
注意:坐标系的旋转和尺度的缩放是不变的,但对一般的线性变换和坐标系的平移不具有不变性。
- 相关系数
实际上是数据中心化后的矢量夹角余弦
相关系数的取值在 [-1,1],取值为1时,两组数据最相关。
- 指数相似系数
式中(sigma^2_i)为相应分量的协方差,(n)为矢量维度,它不受量纲变化的影响。
- 匹配测度
当特征只有两个状态(0, 1)时,常使用匹配测度。0表示无此特征,1表示有此特征,故称之为二值特征。对于给定的(x)和(y)中的某两个相应分量(x_i)与(y_j):
若(x_i=1,y_j=1),则称(x_i)与(y_j)是(1-1)匹配;
若(x_i=1,y_j=0),则称(x_i)与(y_j)是(1-0)匹配;
若(x_i=0,y_j=1),则称(x_i)与(y_j)是(0-1)匹配;
若(x_i=0,y_j=0),则称(x_i)与(y_j)是(0-0)匹配。
对于二值(n)维特征矢量可定义如下相似性测度
令 (a = sum_i x_iy_i) 为(vec x)与(vec y)的(1-1)匹配的特征数目
令 (b = sum_i y_i(1-x_i)) 为(vec x)与(vec y)的(0-1)匹配的特征数目
令 (c = sum_i x_i (1-y_i)) 为(vec x)与(vec y)的(1-0)匹配的特征数目
令 (e = sum_i (1-x_i)(1-y_i)) 为(vec x)与(vec y)的(0-0)匹配的特征数目
Tanimoto测度
例题
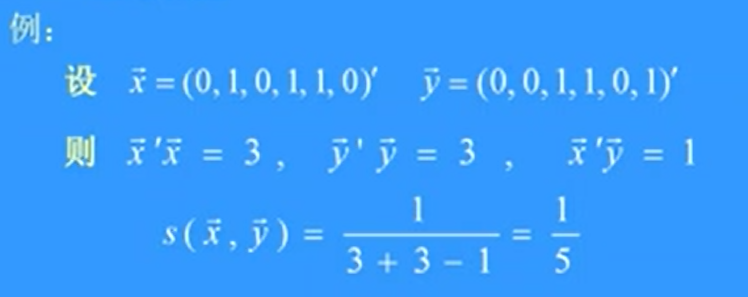
可以看出,它等于共同具有的特征数目与分别具有的特征种类数目之比。这里只考虑了(1-1)匹配而不考虑(0-0)匹配。
Rao测度
注:(1-1)匹配特征数目和所选用的特征数目之比

简单匹配系数
注:上式分子为(1-1)匹配特征数目与(0-0)匹配特征数目之和,分母为所考虑的特征数目。

Dice系数

Kulzinsky系数
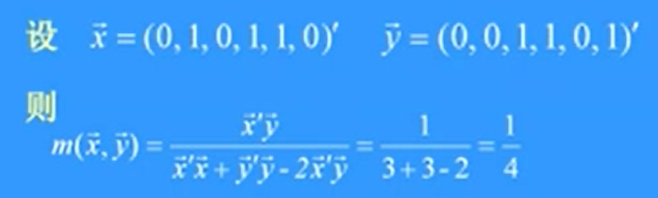
类的定义
定义1
若集合S中任意两个元素(x_i,x_i)的距离(d_{ij})有
则称S相对于阙值h组成一类。
定义2
若集合S中任一元素(x_i)与其他各元素(x_j)间的距离(d_{ij})均满足
则称S相对于阙值h组成一类(k为集合元素个数)
定义3
若集合S中任意两个元素(x_i, x_j)的距离(d_{ij})满足
则称S相对于阙值h,r组成一类
定义4
若集合S中元素满足对于任一 (x_i in S),都存在某 (x_j in S)使它们的距离
则称S相对于阙值h组成一类。