RNN
title: notation
rnn是squenece2squence的model, 如果我不用signspeaker的方法把动作切成小片的话, 似乎rnn对我的意义不大,我是将squence2one的应用。
有点像video里面的活动识别问题,输入一个序列输出1个类别
title: notations
x<t>,代表某个example里序列的第 t 个元素,Tx代表样本x的长度(序列的长度),Ty代表输出y的长度(序列长度
x(i)<t>第i 个样本的序列 t 元素。
Tx(i) 代表第 i 个样本的序列长度,每个样本序列长度可能不一样

dnn在这个问题里的缺陷,不能适应不同长度的输入和输出
不能让不同位置的神经元分享学习到的参数
rnn前向传播
信息量很大,先初始化一个a0为0向量,然后计算的激活值由上一个单元的a和这个单元的X共同做出来,
整一个是一个神经元还是一层呢,我不太确定这里的用词
假设整一个是一层,那么每个神经元可以输出一个y,y可以是各种类型的数据,输出y的时候所使用的激活函数也根据问题类别确定
反正图里的这些单元,share同样的学习参数,waa,wax,wya,ba,by

title: Different types of RNNs
rnn有many2many的结构,也有many2one的结构
many2one的结构,rnn在最后的一个单元输出一个值就可以了,包含了所有的信息
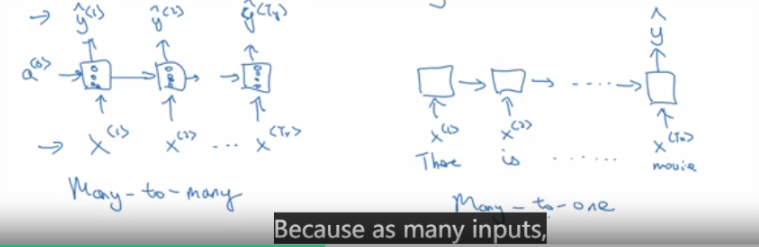
还有one2many的结构,比如自动作曲,还有many2many但是输入输出不等长的结构(在翻译应用里),像这样就是用前面的神经元
专门读取输入X,计算激励,后面的神经元专门输出Y

title: language model and sequence generation
language model输出一句话的概率,就是基于语言本身的概率,来辅助语音识别,辅助机器翻译等等
title: sampling novel squences from a trained RNN
输入为0, 然后让rnn做出序列输出,看看得到什么样的句子,这里很奇怪,为什么要把上一时刻的y作为下一时刻的x输入,完全零输入不是更好
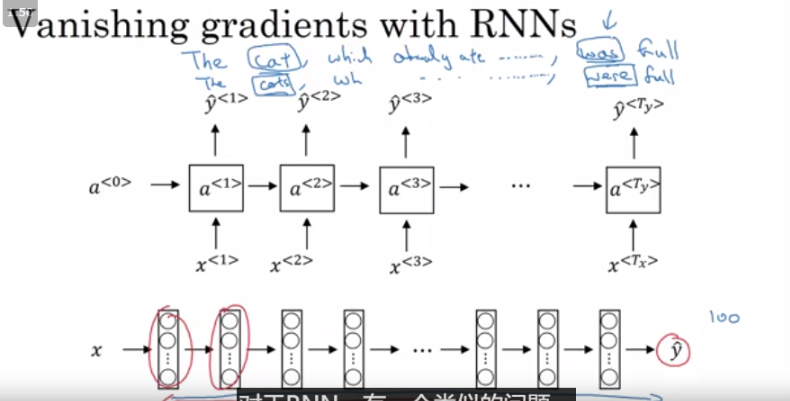
title: Vanishing gradients with RNNs
层数比较深的情况下,反向传播很难影响到靠前面的层
但是我们希望尽可能建立前后的联系,例子cat......was, cats.......were.
简单的rnn只能捕捉到它附件的词的影响
title: Gated Recurrent Unit (GRU)
本质上,就是多了一个memory cell,这个cell里面有很多维,认为这些维度存储的东西可以被很后面的神经元用到
那么每次经过一个神经元,考虑要不要更新这个cell,用一个gate决定的数字来控制更新的过程,这个gate呢也还是用
这些东西算的,反正是这么个思想吧
