郑昀 20090905
在Social Media领域,不管是搜索结果,还是页面展示,只要不是编辑挑选的,只要是机器智能决定的,都需要以某种顺序排列。
那么,除了按时间顺序或按投票数排列外,还会有哪些有效的展示模式呢?
下面罗列我所见:
模式一、Reddit模式
Reddit的排序算法一文曾经介绍过 Reddit 会综合考虑以下因素:
- 文章的新鲜程度;
- 支持票数和反对票数;
- Discoverers和Followers效应(削减Followers的投票权重)。
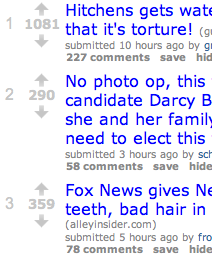
图1 Reddit 排序示例
从上图可以看出,让新鲜且投票数还不足够多的文章能快速突破进入榜单,是很重要的。
在从Social Media海量数据中寻找专家的五大手法中SPEAR模式认为:“专家应该是发现者,而不是趋势的跟随者。experts应该是第一批收藏和标记高质量文章的人,从而召唤起社区内其他用户的围观。用户发现优质内容越早,表明该用户专业程度越高。所以,要区分“Discoverers”和“Followers”。”Reddit 正是通过log10 的使用,使得早期的投票(即Discoverers)获得更大的权重。比如,前10票获得的权重,与11到101票所获得的权重是一样的。
如你所知,玩聚SR 在给出热门链接时也采用了同样的排序规则,我曾经给出过简化的算法。
模式二、OneRiot PulseRank模式
实时搜索引擎 OneRiot 的 PulseRank,能够充分地把社会化因素考虑进来,做到搜索结果排序的 Socially Relevant 。
PulseRank 所考虑的因素:
- 新鲜程度 Freshness ;
- 域名的权威程度 Domain Authority :这个不同Team会有不同看法,到底是传统门户的域名权重更大,还是独立博客的域名更有价值。
- 推荐者的权重 People Authority :系统要能识别推荐者是否是spammer,要能发现某些推荐者总是推荐同一个链接或者同一个域名下的链接(你总是日复一日地推荐某一个站的链接,应该降低你的权重),也要能发现某些人的推荐总能得到更大范围的“二次传播”。
- 传播加速度 Acceleration :主要检测推荐的速率,从而区分新出现的页面和广为人知的热门页面。
当然它还考虑来自Twitter、Digg以及OneRiot Share的推荐数量。
推荐越多,排在Pulse搜索结果最前面的可能性越大;新鲜程度也影响非常大,其他因素的影响比较难以被注意到。所以这还是 Reddit模式的增强版,只不过聚合了不同Social站点的推荐数,并加了几个因子。
参考资源:
1、Ranking Algorithm for the Realtime Web: OneRiot “Pulse Rank” Update
模式三、digg模式
Digg 有很多技巧:
1、投票的速度:比如一篇文章最开始的半小时内能迅速收集到40~50个投票,那么是谁投的就无关紧要,这篇文章就会上首页。
2、投票用户的级别。不过Digg的《A couple updates》宣布了Top users总是伴随着行为异常和可憎,所以本因素将不断被降低。并且如果你拥有非常多的好友,那么你提交的文章就需要更多的Digg才能上首页,通常是新用户的2~3倍。
3、评论的数量,以及评分的数量。如果一篇文章有40个评论,其中20个对它评级在-4分以下,那么显然这篇文章不会上首页。
4、Bury的数量。还会考虑到Bury的类型,如重复的故事、Spam、错误的分类等。如果一篇文章在Upcoming队列中,获得了3个Bury,那么它就永远被Buried了。如果文章是在首页并且拥有1000个Diggs,那么需要大约10~15个Bury才能让它消失(消失指只能访问最终页面,任何类别的导航页都不会看到这篇文章了)。
5、投票用户的 Popular Ratio。如果10~15个Popular Ratio在70%以上的用户都投了一篇文章,那么它上首页会很容易。你可以 Digg用户页面上查到每个用户的Popular Ratio。
Digg 的算法久经考验,不断被修正,并且充分利用了它所能收集的一切信息,值得借鉴。
和 Digg 一样,Newsvine 也考虑得很全:
- 用户的声望;
- 用户好友的声望;
- 评论;
- 域名权重;
- 浏览数和停留时间。
参考来源:
1、The Digg Algorithm - Unofficial FAQ
2、Newsvine Algorithm and potential ranking factors for exposure
模式四、Seeds模式
这是一种第三方应用深入某个Social Media的刺探式统计方法。事先选定一个key users集合(比如创始人以及其他核心用户,被称之为“seeds”),然后从这批用户开始扫描建立Social Graph,通过统计inbound links和好友关系,得出被扫描的social media的不同指标的排行榜,这就是Spinn3r rank所用到的手法。这种模式并不限于计算Top Users。
它所用到的两个技巧倒是经常看到:
- 从 Approved Sources 开始扫描:一个好的算法,当然要从好源开始,Techmeme 和 玩聚SR 都是这么做的;
- 遍历 friendship :spammers或水平不那么高的用户,要想从 seeds 这里获得连接显然是不大可能的。
好了,这就是我观察到的Social Media中经常出现的几种排序规则算法。如果你有补充,请留言或follow me。
郑昀 北京报道 20090905
其他参考文章:
2、ranking by semantic similarity
还推荐您阅读我的以下文章: