本文首先介绍 Erlang 运行时中需要使用无锁队列的场合,然后介绍无锁队列的基本原理及会遇到的问题,接下来介绍 Erlang 运行时中如何通过“线程进度”机制解决无锁队列的问题,并介绍 Erlang 运行时中提供的一个通用无锁队列的实现及其在 ERTS 异步线程池中的应用。
无锁队列在 ERTS 中的应用场合
为了提升 Erlang 运行时在多核/众核处理器上的 scalability,Erlang 运行时使用了大量无锁数据结构,无锁队列(lock-free queue)就是其中广泛使用的一种并发数据结构。其中最重要的应用应该是 Erlang 运行时从 ERTS 5.9 版本(对应 Erlang/OTP R15B)开始引入的“delayed deallocation”(延迟释放)特性。在大规模的多线程程序中,如果通过加锁的方式保护是用一个内存分配器,那么在内存分配和释放的应用中一定会引起大量的争用,这种争用对于 scalability 的损害是非常大的。因此在这种情况下,最直观的解决方案是每一个线程都使用自己的内存分配器实例。这种方案的确解决了多个线程争用分配器分配内存的问题,但是释放内存依然还有问题。内存分配了就要释放,在多线程程序中,一个生产者线程分配的数据对象很有可能会传递到其他线程去处理,其他消费者线程用完了数据之后,那么数据对象应该由谁来释放呢?如果由消费者释放的话,消费者为了访问生产者的内存分配器实例,不得不使用锁,因此又出现了使用锁的问题。此外,如果生产者和消费者不在同一个处理器核心上,甚至在不同的 NUMA 节点上,那么释放内存还会造成 cache 失效以及产生 NUMA 跨节点流量的问题,使得释放内存的开销增大,影响消费者的处理能力。因此数据对象最好是能够在生产者这一端释放。生产者可以选择合适的时机释放内存,既能避免上述问题,还能保证自己的 latency 水平。
这种谁分配谁负责释放的机制称为“延迟释放”。ERTS 在实现延迟释放的时候采用的也是类似于“消息传递”的方式:消费者将要释放的内存的指针通过一个无锁的队列发送到分配这个指针的线程。ERTS 中,调度器特定的(scheduler specific)的内存分配器以及调度器特有的内存预分配器都使用了这种无锁队列来传递释放内存块的任务。实际上这两种分配器使用的无锁队列的代码都差不多。
此外,ERTS 5.9 还引入了一个通用的、多对一的(many-to-one)无锁队列。多对一的意思是说可以有多个生产者并发地向队列中 enqueue 数据,而只能有一个消费者从队列中 dequeue 数据,当然,生产者和消费者可以并发地操作这个无锁队列。由于在 ERTS 中可以使用这种多对一生产者消费者模型的场合非常多,所以 ERTS 未来会越来越多地使用这个通用队列。目前(本文编写的时候 ERTS 版本为 5.10.3,对应 Erlang/OTP R1602),在 ERTS 中只有一些作业调度和异步线程池使用了通用队列。
内存分配器使用的无锁队列和通用无锁队列的相同点在于:两者都是多对一的。两者的区别在于:前者对于入队的顺序并不敏感,因为入队的内容都表示要释放的内存块,释放的顺序并不重要,因此前者在并发 enqueue 数据的时候,插入的数据会出现在队列的尾端或尾端附近的位置,不要求一定出现在尾端,因此支持更高的并发度;而后者则保证 enqueue 数据的时候数据一定插在尾端后面,从而确保了公平性。
本文下面会以通用无锁队列为例介绍这个无锁队列的工作原理,并且讨论通用无锁队列在异步线程池中的应用。由于内存分配器中使用无锁队列更多的和内存分配器本身相关,所以为了不偏题本文主要讨论通用无锁队列的实现原理,应用部分主要讨论通用无锁队列在异步线程池中应用的具体实例。有了这个基础之后,就好理解无锁队列在其他场合的应用。其他场合无锁队列的应用就可以在介绍其他组件的文章中顺便提及。
无锁队列的基本原理以及“线程进度”机制的支持
无锁队列
本节介绍无锁队列的基本原理,并介绍之前一篇文章介绍的“线程进度”机制到底是怎样利用的。
这里的无锁队列如下图所示,是以链表的形式实现的,每一个节点表示一个元素。节点通过 next 指针链接到下一个节点,节点内部通过 data 指针指向节点表示的实际数据。最后一个节点的 next 指针设置为 NULL。队列数据结构本身维护一个指向第一个节点的 head 指针以及一个指向最后一个节点的 tail 指针。
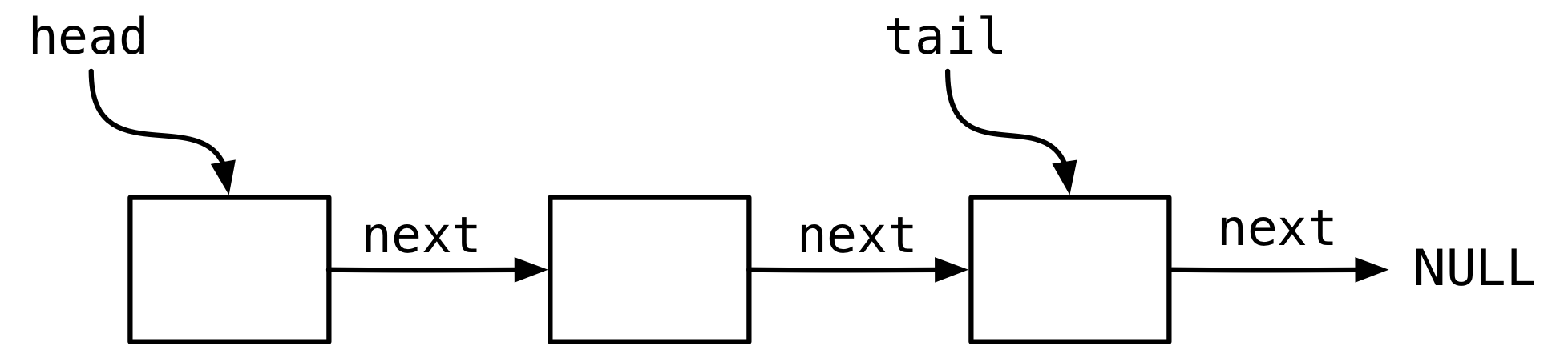
先看 enqueue 一个节点。如果是单线程的队列,那么很简单,只需要分配一个节点,设置好新节点的数据指针和next指针,然后将 tail 指针指向的节点的 next 指针修改为新节点,最后将 tail 指针向后挪一位指向新的节点。
在多线程的环境中,enqueue 一个节点也需要更新这两个指针,不过我们需要采用原子的 CAS 指令。 首先将新节点插入最后一个节点的 next,这一步的操作看下面的伪代码:
1 ilast = tail; 2 while (1) { 3 last = ilast; 4 itmp = CAS(&last->next, this, NULL); 5 if (itmp == NULL) 6 break; 7 ilast = itmp 8 }
首先读取 tail 指针当前快照 放在 ilast 中,也就是可以先赌一把,认为 ilast 指向的是最后一个节点。然后进入 while 循环,通过一个 CAS 操作判定之前的赌注是否正确。这个 CAS 操作的意义是:在一个原子操作中,将 last->next 指针的值和 NULL 比较,如果相等的话,就把 last->next 替换为 this,this 表示指向新节点的指针,否则不动 last->next。在读这种使用了原子操作的代码的时候,要注意 CAS 调用的参数顺序和返回值。这里的 CAS 操作实际上对应的是 ERTS 中的 erts_atomic_cmpxchg_mb 调用,而这个调用遵循的是 Intel 平台 cmpxchg 指令的格式,所以这个 CAS 操作的参数顺序是:第一个参数表示原子变量,第二个表示要设置的值,第三个表示要比较的值。返回值的规定是:如果成功,则返回老的值,如果失败,则返回原来的值。而其他有些原子库或一些书或文章中使用的 CAS 操作的参数中第二和第三个参数可能是和这个 CAS 相反的,而且有的返回值通过 1(true)和 0(false)分别表示成功和失败。
继续回到这段代码。如果 CAS 操作成功了,也就是返回的 itmp 等于新设置的值 NULL,那么退出循环。如果不成功,itmp 就等于 last->next,然后 ilast = itmp,也就是说下次尝试 CAS 的时候向后移动了一个节点。想象一下这个场景,当很多线程在并发 enqueue 队列的时候,由于一次只能有一个线程成功地完成 CAS 操作,其他线程都要重试,因此看上去好像是很多线程在追逐终点一样。直到最后大家都插入了自己的节点。
下一步的操作是要更新 tail 指针,伪代码如下:
1 while (1) { 2 if (this->next != NULL) { 3 ilast = tail 4 return ilast; 5 } 6 itmp = CAS(&tail, this, ilast); 7 if (ilast == itmp) 8 return this; 9 ilast = itmp; 10 }
进入 while 循环之后,首先判断 this->next 是否为 NULL,如果不是,说明当前线程在插入完节点之后还有其他并发线程在我之后也插入了新的节点,那么我就不用负责更新 tail 指针了,等别人更新好了,在这些并发线程中必然有一个插入的节点是最后一个,因此必然有一个线程能够更新 tail 指针。那个线程就是发现 this->next 等于 NULL 的线程,这个线程进入第 6 行的 CAS 操作。这个 CAS 操作比较 tail 和 ilast 的值。还记得 ilast 指针指向谁吗?根据前面插入节点的代码,这个 ilast 指向 this 之前的那个节点。如果是单线程的话,这个 CAS 操作一步就成功了,将 tail 从 this 之前的那个节点挪到 this。而多线程并发的情况下,执行到第 6 行的时候 tail 不太可能恰好指向 this 之前的那个节点,所以第 9 行将 ilast 更新为 tail 的老值,下一次进入循环的时候,必然有一个线程能成功地在 CAS 操作中将 tail 从随便什么老值设置为对应的 this。想象一下这样的场景:tail 指针也在多个并发线程的共同努力下不停地向后跳动。如果并发 enqueue 都完成了操作,那么 tail 必然最终指向最后一个节点。如果有很多并发的 enqueue 在同时操作,那么实际的 tail 指针会在这些 enqueue 操作开始之前时候的位置以及当前最后一个节点之间的某个位置。
下面讨论 dequeue 的操作。由于这个队列是M对1的,所以 dequeue 端只有一个线程操作,原则上应该很简单,只要修改 head 指针即可,对吧?事实上,dequeue 操作才是麻烦之处,因为 dequeue 涉及到资源释放的问题。如果过早释放资源,那么有可能释放正在被使用的资源;如果在dequeue的时候释放资源,那么会出现之前提到的释放“外地”资源的问题。因此,最合适的方式应该是将资源释放延迟到“适当”的实际。下面的“线程进度机制”的作用就是确定适当的时机。
这里不得不提一下传统教科书上(例如“The Art of Multiprocessor Programming”[1])的无锁队列。教科书上介绍的一般是论文[2]提出的 M&S 无锁队列,同样这个队列的也是命名于其两个发明者。M&S 无锁队列是大部分操作系统以及程序语言运行时中使用的无锁队列。M&S 无锁队列的 enqueue 操作和 dequeue 操作都支持多线程并发访问。M&S 无锁队列的 enqueue 操作和上面介绍的基本思想差不多,也是分两步修改两个指针。但是 dequeue 操作会检查 head 指针和 tail 指针的碰撞,并且在碰撞发生的情况下“帮助”修改 tail 指针。判断队列为空的条件就是看 head 指向的节点的 next 是否为 NULL。
M&S 无锁队列的 enqueue 线程和 dequeue 线程都会修改 tail 指针,显然在多线程程序中,特别是涉及处理器核心数特别多的程序中应该避免这种情况。为了将两种操作分离开,ERTS 无锁队列将 enqueue 操作会操作的数据放在一条 cache 线中,将 dequeue 操作会操作的数据放在另一条 cache 线中。那么这个 dequeue 操作简化的伪代码是这样的:
1 inext = head->next; 2 if (inext == NULL) 3 return NULL; 4 head = inext; 5 return head;
先判断 head 指向节点的 next 是否为 NULL,即是否最后一节点,如果是的话,说明队列为空。如果不是的话,head 向后移动一个位置,然后返回 head 指向的节点。
那么返回(即 dequeue)的节点什么时候才能安全释放呢?考虑下面的情形:
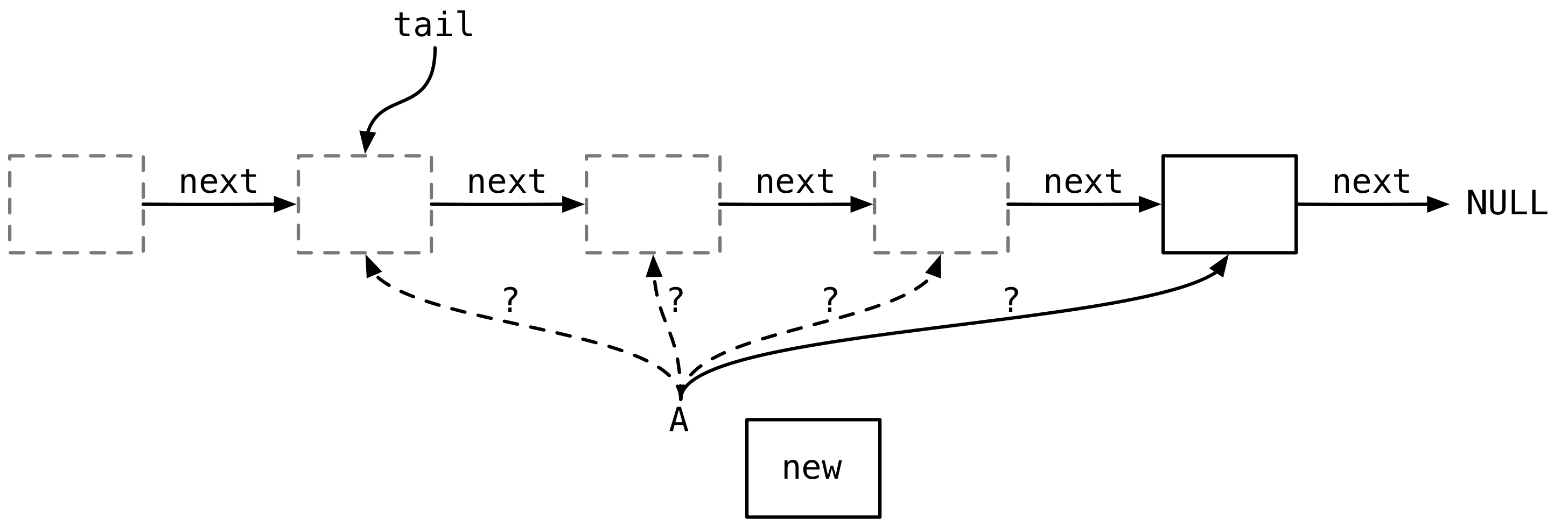
图中有一个线程 A,速度很慢。图中的 tail 指针的状态是 A 刚进入 enqueue 操作时看到的状态。线程 A 带着新节点 new 在慢悠悠地一个接一个地找 next 指针为 NULL 的节点,可是由于 A 太慢了,很多其他并发线程已经插入了很多节点在后面。更糟糕的是,消费者 dequeue 的速度也已经超越了 A 扫描的速度,图中灰色节点都是已经 dequeue 出去的节点,这意味着 A 在扫描逻辑上已经不存在的节点。如果这些节点在被 dequeue 之后就被释放了,而 A 还在操作这些节点,例如修改 next 指针或其他操作,那么会引起内存访问的异常,导致 Erlang 虚拟机崩溃。
从 ERTS 5.9 开始,Erlang 引入了“线程进度”机制,用于判定可以安全释放节点的时机。
线程进度机制
年初的时候我写过一篇博文[3]分析 ERTS 5.9 新引入的线程进度(thread progress)机制的实现原理。但是当时我并没有弄明白 ERTS 中的无锁算法是怎样利用线程进度机制的,无锁队列 ErtsThrQ_t 数据结构也非常复杂,包含了一些和线程进度相关的字段,API 也包含一些和线程进度相关的接口。后来这一块就搁置了,直到 RELEASE 项目发布了 WP2 的报告 D2.3,里面介绍了线程进度机制和延迟释放相关的原理。可是看了文档写得还是有点抽象,后来直接给 Rickard Green 大神发电邮讨论了一下,在大神的点拨下豁然开朗,所以也就有了这篇博文,算是弥补了一大遗憾。
单纯把线程进度机制抽取出来,这个机制的作用是跟踪 ERTS 中所有受管线程(managed thread)的进度值。就所有线程而言,ERTS 还有一个全局的进度值。所有受管线程都需要在特定的点调用 erts_thr_progress_update() 更新自己的进度。如果自己是 leader,还需要调用 erts_thr_progress_leader_update() 更新全局进度。下面是进度值的规则(从[3]中摘出的比较重要的规则):
- 在受管的线程集合中,有且只有一个线程是 leader 线程
- 每一个受管线程都在固定的位置更新自己的进度值
- leader 线程除了更新自己的进度值之外,还要更新全局进度值
- 所有受管线程的进度值和全局进度值初始化为 0
- 线程运行到更新点的时候更新自己的进度值,但是这个进度值不超过全局进度值 +1
- leader 线程更新完了自己的进度值之后,要检查所有受管线程的进度值是否都达到了全局进度值 +1,如果达到了,则更新全局进度值 +1
每一个受管的线程都有责任在固定点更新进度,比如调度器线程会在前一个 Erlang 进程调度出之后下一个 Erlang 进程调度入之前、进入睡眠之前以及唤醒的时候会更新进度。受管线程也就是可以保证以一定的频度更新进度的线程,对于这一类线程,我们了解这些线程的全部工作流程,知道这些线程一定不会无故挂起,而且一定会调用进度更新函数。调度器就是这样的线程。而异步线程池中的异步线程会调用外部的驱动代码,所以执行行为是不可控的,可能会延迟很长的时间不更新进度,因此异步线程就不属于受管线程了。
下面看一个具体的例子,这个例子展示了几个线程更新进度的理想情况(即没有任何受管线程在睡眠)。图中的横轴表示时间轴,上下一共 4 根时间轴是对齐的。第一根轴表示全局的进度值变化,下面 3 根轴分别表示 3 个受管线程 T1、T2 和 T3 的进度更新情况:
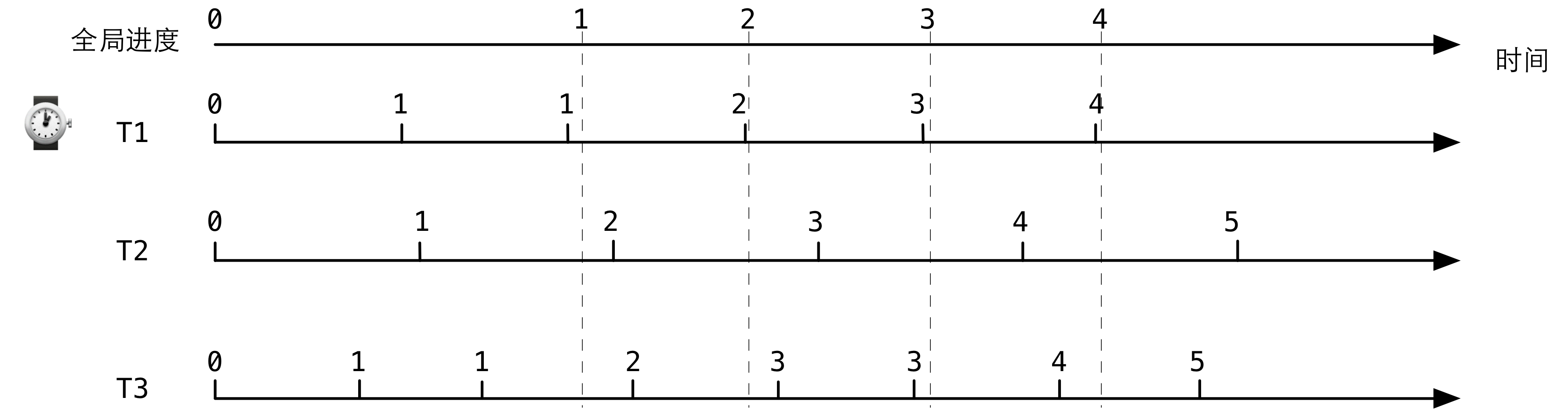
下面 3 根轴上的一个 tick 表示线程调用一次 erts_thr_progress_update()。所有的进度值初始都为 0,其中 T1 为 leader 线程。T3 线程的速度最快,因此调用进度更新的间隔也最小。T3 首先将进度更新为1,然后 T1 和 T2 依次更新。然后由于 leader 还没有更新,所以全局进度依然为 0,所以 T3 第二次更新的时候依然为 1。接下来,leader T1 更新,将全局进度更新为 1。之后的更新以此类推。从中可以看出,跑得快的线程虽然调用更新更频繁,但是如果全局进度没有更新,也不会更新进度值。而全局进度在更新的时候,要扫描所有线程的进度是否都更新了。所以从这里可以隐约看出,全局进度是在保证什么东西。
那么线程进度是在保证什么呢?线程进度是要保证两件事情的判定:
- 受管线程从一个任意状态返回到一个固定的已知状态。
- 线程执行了一次完整的内存屏障。
关于第一件事情,所谓的已知状态就是调用 erts_thr_progress_update() 时的状态,这个函数是线程进度机制提供的函数,所以线程进度机制必然知道线程在干什么了,那么也就说明在这个状态下保证线程没有在干其他任何事情。比如说,线程在调用这个函数之前正在访问一个数据结构,那么调用这个函数的时候,说明线程一定完成了对之前的数据结构的访问。假定有一个线程通过 erts_thr_progress_later() 调用请求下一个线程,那么当这个线程调用 erts_thr_progress_has_reached_this() 返回 true 的时候,说明所有受管线程至少更新了进度一次。当然,线程可以请求 ERTS 在到达全局进度的时候将自己唤醒,然后进入睡眠状态,而不是反复查询是否到达下一个进度。
上面的描述还是比较抽象,那么线程进度机制对于我们的无锁队列到底有什么用途呢?我们之前说了无锁队列的一个问题,就是要判定在什么时候能够真正将节点的内存释放,关键问题在于我们不知道 enqueue 什么时候结束执行。有了线程进度机制就好办了,线程产生进度的时候说明 enqueue 一定完成了一次执行,那么只要等待下一次全局进度更新的时候,我们就可以判定所有的线程都至少完成了一次 enqueue 操作。
如下图所示,这个图其实是上面那个图的真实应用。图中有 3 个生产者在调用 enqueue 操作(通过图中时间轴上的小盒子表示),我们从观察者 T4 的角度来看这些并发的 enqueue 操作:
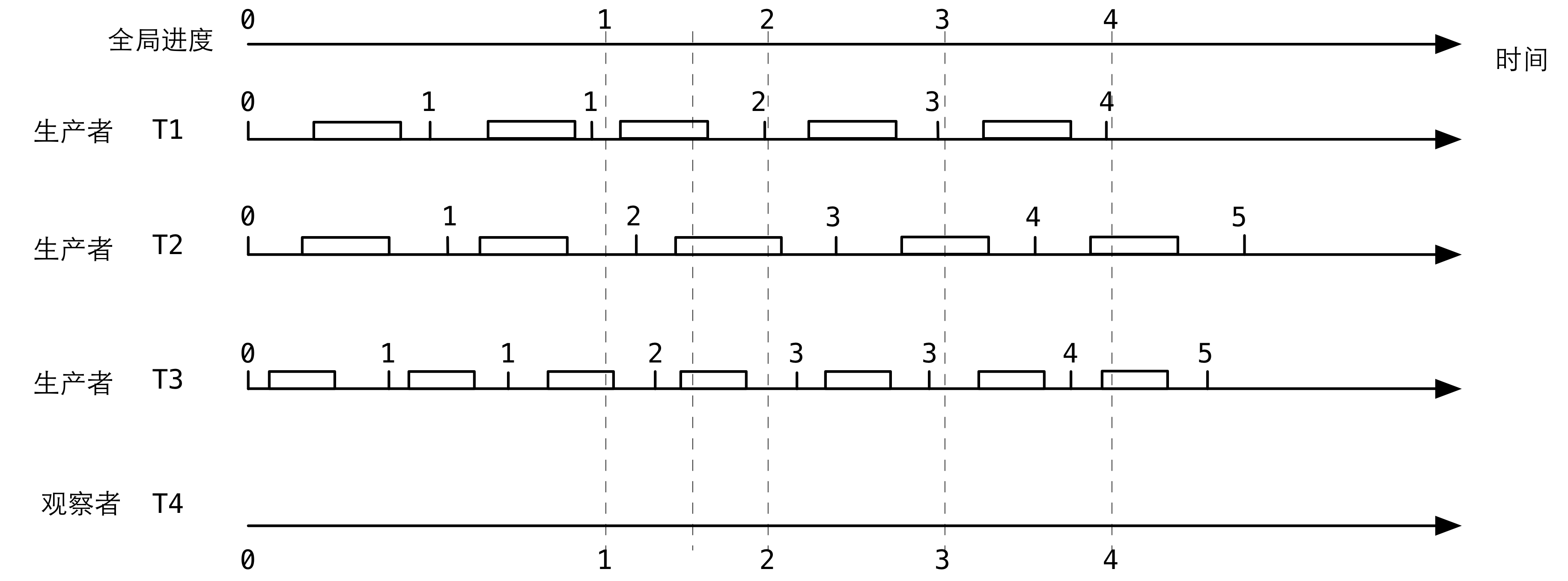
T1 仍然是 leader 线程。假设在全局进度 1 和 2 之间的某个时间点,即图中用虚线标出的时间点,在这个时间点我们可以看到 3 个生产者都在调用 enqueue,这时的 tail 指针是在一个范围内变化。但是如果此时我们取当前 tail 的一个快照,然后调用一次 erts_thr_progress_later(),那么在到达下一次全局进度(即 3)的时候,我们可以保证在调用 erts_thr_progress_later() 时刻的所有 enqueue 都完成了执行并返回了,所以可以认为在到达下一次全局进度的时候,tail 快照之前的所有节点都是可以安全释放的。看这个设计多巧妙:下一次全局进度刚好是 3 而不是 2,如果是 2 的话,T2 的那个 enqueue 操作还没有完成执行。
因此,我们就这样通过线程进度机制判定了哪些节点是可以安全释放的。无锁队列的用户应该负责将这些要释放的节点发送给原来分配这些节点的线程,让原来的线程负责释放。
另外提一下线程进度机制实现上的优化。线程进度机制之所以需要选择一个 leader 线程的原因,是为了让这个线程负责更新全局进度值。假设没有 leader 线程,而是用一个原子变量(计数器)表示全局进度,那么这个原子变量一定会成为争用的瓶颈。但是如果这样设计:每个普通线程在自己的 cache 线上更新自己的进度数据,当然更新的时候只读取全局进度值,leader 线程在更新的时候只读所有线程的进度值,然后再更新自己的 cache 线上的全局进度值。在这种设计下:线程自己更新的时候,如果全局进度没有更新,那么只需要更新自己的 cache 线,不会产生 cache 通信;如果全局进度有更新,那么会产生一次全局进度值所在的 cache 线到每一个线程所在 cache 的广播流量。leader 线程在更新全局进度值的时候,只需要通过 cache 总线从每一个其他线程的 cache 线收集一次数据。可以看出,线程进度机制的 cache 通信模式是非常高效的。
ERTS 5.10(对应 Erlang/OTP R16)起线程进度机制有所改进,改进了对非受管线程的管理,这是为了重写 port 任务调度而做的改进。增加了允许非受管线程延迟全局进度的功能。目前我对 port 任务调度了解不多,所以这一块也就不妄作评论了。
好了,理论说得够多了,下面开始看代码。
ERTS 中的通用无锁队列
下面是无锁队列的结构体:
1 struct ErtsThrQ_t_ { 2 /* 3 * This structure needs to be cache line aligned for best 4 * performance. 5 */ 6 union { 7 /* Modified by threads enqueuing */ 8 ErtsThrQTail_t data; 9 char align__[ERTS_ALC_CACHE_LINE_ALIGN_SIZE(sizeof(ErtsThrQTail_t))]; 10 } tail; 11 /* 12 * Everything below this point is *only* accessed by the 13 * thread dequeuing. 14 */ 15 struct { 16 erts_atomic_t head; 17 ErtsThrQLive_t live; 18 ErtsThrQElement_t *first; 19 ErtsThrQElement_t *unref_end; 20 int clean_reached_head_count; 21 struct { 22 int automatic; 23 ErtsThrQElement_t *start; 24 ErtsThrQElement_t *end; 25 } deq_fini; 26 struct { 27 #ifdef ERTS_SMP 28 ErtsThrPrgrVal thr_progress; 29 int thr_progress_reached; 30 #endif 31 int um_refc_ix; 32 ErtsThrQElement_t *unref_end; 33 } next; 34 int used_marker; 35 void *arg; 36 void (*notify)(void *); 37 } head; 38 struct { 39 int finalizing; 40 ErtsThrQLive_t live; 41 void *blk; 42 } q; 43 };
这个结构体主要分为三大块:tail、head 和 q。
tail 是一个联合体,里面有用的数据部分是 ErtsThrQTail_t 类型的 data,表示和 tail 指针相关的操作,所有的 enqueue 操作都只会操作 ErtsThrQTail_t 中的数据。tail 联合体的另一部分是用来 cache 对齐的,字节数等于 cache 线大小的倍数,而且是大于 ErtsThrQTail_t 字节数的最小值。这种 cache 对齐方式在 ERTS 代码中非常常见。后面会详细介绍 ErtsThrQTail_t 中的字段。
接下来是 head,所有的 dequeue 操作只会操作 head 中的数据。tail 和 head 占用的是不同的 cache 线,所以可以保证 enqueue 线程和 dequeue 线程不会在 cache 上互相干扰。head 结构体中字段不少,大多都和线程进度机制有关:
- head:是一个原子变量,指向逻辑上的队头
- live:队列中元素的生存期,长期或短期,会影响内存分配/释放的策略。如果是长期对象,则使用普通的内存分配器。如果是短期对象,那么分配和释放操作频繁,因此会使用短生存期对象的专用
- first:指向队列中第一个元素
- unref_end:表示unreferenced end pointer,指向最后一个未被其他线程引用的元素,也就是说,在这个指针指向的元素之前的元素都是可以安全释放的
- clean_reached_head_count:清理该释放的元素时使用的计数器。当 first 碰到 head 的时候记录一次。(具体意图我暂不明了)
- deq_fini:dequeue finilization相关的数据。automatic 表示是否在 dequeue 的时候自动释放节点。如果希望延迟释放的话一般都会把这个字段设置为 0。start 和 end 表示目前需要释放的一段节点的头和尾。延迟释放的时候,应该把这个数据发送给要负责释放内存的线程
- next:表示到达下一个全局的线程进度时相关的数据。thr_progress 表示在等待下次进度的具体进度值;thr_progress_reached 表示是否到达了下次的进度值;um_refc_ix 和非受管线程有关(具体操作的是 tail 中的数据)
- used_marker:是否使用 marker,marker即哨兵元素,当队列为空的时候用来占位
- arg,nofity:用于通知新的元素插入,一般都是调用 notify 唤醒线程。
接下来是 q,q 结构体中的字段描述的是和队列本身相关的数据。finalizing 表示是否正在销毁整个队列。live 表示整个队列的生存期,ERTS 中用来发送消息的队列一般都是长期队列。blk 是指向整个队列数据结构所占内存块的指针,销毁队列的时候会用到。
下面是 tail 部分的结构体定义:
1 typedef struct { 2 ErtsThrQElement_t marker; 3 erts_atomic_t last; 4 erts_atomic_t um_refc[2]; 5 erts_atomic32_t um_refc_ix; 6 ErtsThrQLive_t live; 7 #ifdef ERTS_SMP 8 erts_atomic32_t thr_prgr_clean_scheduled; 9 #endif 10 void *arg; 11 void (*notify)(void *); 12 } ErtsThrQTail_t;
marker 是哨兵元素。last (应该)指向队列中的最后一个元素,也就是前面讨论无锁队列原理时说到的 tail 指针。
um_refc[2]、um_refc_ix 和非受管线程有关。前面可以看出来,线程进度机制的主要目的是为了判定一个数据结构是否被其他线程引用了。传统的引用计数方式在众核多线程环境中会因为 cache 一致性而引起严重的 cache 通信过重问题,因此才会通过受管线程更新自身进度的方式来简介管理数据的引用。而由于非受管线程无法保证进度更新,因此非受管线程的管理仍然通过传统的引用计数的方式。这里的 um_refc 指的就是 unmanaged reference count,um_refc_ix 就是索引 um_refc 数组的 index。由于非受管线程对这种机制使用的频率远比受管线程低,所以这种低效的方式也不会造成太大的性能问题(因此我们也不详细讨论非受管线程相关的内容)。
接下来是 live,表示元素的生存期,和 head 里面的 live 是一样的,只不过这个 live 专门由 enqueue 线程在分配内存的时候访问。
thr_prgr_clean_scheduled 的意义目前不明了,在代码中也没有使用到。
下面的 arg 和 notify 和 head 中对应的是一样的。
知道了这些数据结构中各个字段的作用之后,我们就好看懂 API 具体实现的代码了。下面简单介绍一下 ERTS 无锁队列提供的几个重要 API:
- erts_thr_q_initialize():根据提供的参数初始化无锁队列。
- erts_thr_q_destroy():销毁队列。
- erts_thr_q_clean():清理队列。逐个释放从 head.first 到 head.unref_end 之间的元素,根据 automatic 的设置,直接释放元素或将要释放的元素放在一个待释放元素的链表中。根据线程进度的情况,向后挪动 head.unref_end 指针。如果挪不动 head.unref_end,而且确实有元素需要释放,那么返回 ERTS_THR_Q_NEED_THR_PRGR 状态,告诉调用者 需要调用无锁队列 API erts_thr_q_need_thr_progress() 获得下一步的全局进度值,然后调用 erts_thr_progress_wakeup() 请求唤醒,然后没事的话就睡眠。这个调用返回的是和无锁队列有关的状态,除了之前提到的 ERTS_THR_Q_NEED_THR_PRGR 之外,还有 ERTS_THR_Q_CLEAN,表示队列是“干净”的,即没有需要清理的垃圾,看上去就像单线程的普通队列那样。还有一个状态 ERTS_THR_Q_DIRTY,表示队列中存在已经 dequeue 但是还没有释放的元素,不过不需要等待下一次的全局进度就可以安全释放。clean 操作一次不会释放全部的元素,而是执行指定数目的释放操作。
- erts_thr_q_inspect():快速判断当前队列的状态。
- erts_thr_q_prepare_enqueue():参见下一条。
- erts_thr_q_enqueue_prepared():如果要在某个专门的线程中分配元素,那么可以调用前一条分配好元素,然后调用这一条传入分配好的元素并 enqueue。
- erts_thr_q_enqueue():enqueue 操作,会自动分配元素。
- erts_thr_q_dequeue():dequeue 操作,返回队头的元素,不释放元素,但是会调用 clean 操作。如果队列设置了 head.deq_fini.automatic 为 1,说明调用者要求当场就释放元素,dequeue 操作会让 clean 一次释放 ERTS_THR_Q_MAX_DEQUEUE_CLEAN_OPS 个元素。而如果设置的 head.deq_fini.automatic 为 0,那么说明不要求当场释放元素,而是把要释放的元素链接在另一个链表中,那么就会让 clean 一次释放 ERTS_THR_Q_MAX_SCHED_CLEAN_OPS 个元素。这两个常量明显第一个应该比第二个小。在 ERTS 中前一个设置为 3,后一个设置为 50。
- erts_thr_q_get_finalize_dequeue_data():获得前面所说的要释放的元素的链表。
- erts_thr_q_append_finalize_dequeue_data():将两个上述链表合并为一个。
- erts_thr_q_finalize_dequeue():调用这条 API 对上述链表进行操作,完成真正的释放工作。显然,这条 API 应该在分配元素的线程中调用。
- erts_thr_q_need_thr_progress():参见之前 erts_thr_q_clean() 条目的描述。
相信有了上面对每一条 API 具体需求的说明之后,代码读起来就应该没问题了。由于代码实在太多,所以这里就不细品了。 有兴趣的读者如果在读代码过程中有具体的问题可以找我讨论。
无锁队列在 ERTS 异步线程池中的应用
异步线程是 ERTS 中访问 I/O 使用的线程,目前文件操作使用到了异步线程池。Erlang 进程要做文件操作的时候,会请求操作文件的 port 驱动程序,port 驱动程序将文件访问的操作通过无锁队列以消息传递的方式发送给异步线程池中的某一个异步线程。异步线程通过 dequeue 操作取出 async 任务之后以同步的方式执行具体的操作,因此异步线程可能会阻塞。操作结束之后,异步线程将操作结果放在另一个无锁队列中。Erlang 调度器会时不时地检查自己是否有 aux 任务要执行。如果在这个无锁队列中 dequeue 出了异步线程投递进来的结果,那么 Erlang 调度器就会把这个结果以消息的方式发回给原来发出请求的 Erlang 进程。Erlang 中的文件操作基本上就是这么个原理。
(实在是写累了,以上过程的具体代码分析就待续吧。。。如果太长的话,也许就放到另外一篇里面了)
小结
Erlang 运行时可以说是高并发多线程程序的宝库,里面充满了各种极致的优化,任何一个细节都可能值得慢慢品味。
总结起来,ERTS 针对多核/众核的优化原则都是一些基本常识,比如说争用的资源要分散开,尽量避免对资源的争用;cache 线要注意避免伪共享;为了避免对 latency 造成影响,能延迟的事情尽量延迟,然后放在恰当的时机解决;尽量使用细粒度的同步,甚至使用无锁的数据结构。
RELEASE 项目是欧盟的一个针对 Erlang 在众核处理器或大型分布式系统上各种优化的项目。项目参与者包括 Ericsson AB 以及一些在 Erlang 上做过不少工作的大学,当然还少不了 Erlang Solutions 公司。貌似各种 Erlang 的用户会议,还有 Erlang workshop 基本上都是这些学校和公司的人在活动。
RELEASE 项目的 Work Package 2 (WP2) 部分的目标是“improving the Erlang Virtual Machine (VM) by re-examining its runtime system architecture, identifying possible bottlenecks that affect its performance, scalability and responsiveness, designing and implementing improvements and changes to its components and, whenever improvements without major changes are not possible, proposing alternative mechanisms able to eliminate these bottlenecks”。目前已经发布的报告有 D2.1、D2.2 和 D2.3。D2.1 和 scalability 分析有关。D2.2 主要涉及到 ERTS 中 ETS 的 scalability 优化,在 Erlang 中支持高效的 DTrace/SystemTap 所做的工作,以及在 Blue Gene/Q 巨型机上移植 Erlang 的工作。D2.3 则是关于 Erlang 虚拟机中各种 scalability 优化,包括本文介绍的高效的线程进度机制和内存延迟释放。D2.4 还没有发布。这些报告可以在这里下载到,读这些 scalability 相关优化的报告真是一件令人激动的事情,不仅适合专门搞 Erlang 的同学们,还适合所有搞大型并发系统的同学们借鉴。
我觉得 Erlang 就像一个大型的宝藏一样,从大的架构到小的细节,里面处处充满了值得我们学习品味的地方。
[1] Herlihy, M. and Shavit, N. (2008). The Art of Multiprocessor Programming. Morgan Kaufmann.
[2] Michael, M. M. and Scott, M. L. (1996). Simple, fast, and practical non-blocking and blocking concurrent queue algorithms. In Proceedings of the fifteenth annual ACM symposium on Principles of distributed computing, PODC ’96, pages 267–275, New York, NY, USA. ACM.
[3] Erlang运行时源码分析之——线程进度机制. http://www.cnblogs.com/zhengsyao/archive/2013/01/27/erts_thread_progress.html