这个实验主要思想是在创建数据库表的时候,
通过增加一个额外的字段,也就是时间戳字段,
例如在同步表 tt1 和表 tt2 的时候,
通过检查那个表是最新更新的,那个表就作为新表,而另外的表最为旧表被新表中的数据进行更新。
实验数据如下:
mysql database 5.1
test.tt1( id int primary key , name varchar(50) );
mysql.tt2( id int primary key, name varchar(50) );
快照表,可以将其存放在test数据库中,
同样可以为了简便,可以将其创建为temporary 表类型。
数据如图 kettle-1
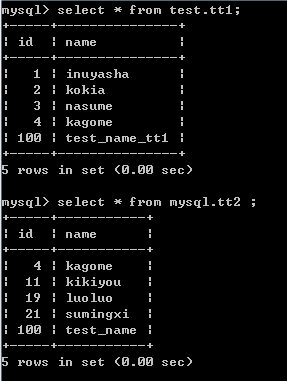
kettle-1
============================================================
主流程如图 kettle-2
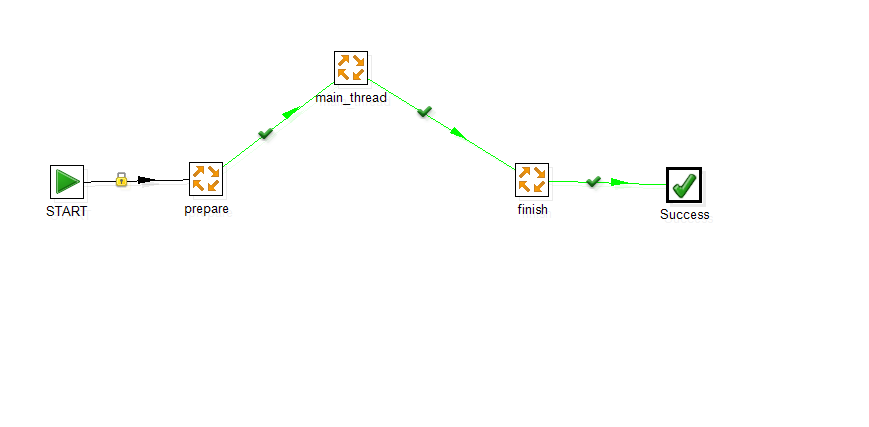
kettle-2
在prepare中,向 tt1,tt2 表中增加 时间戳字段,
由于tt1,tt2所在的数据库是不同的,所以分别创建两个数据库的连接。
prepare
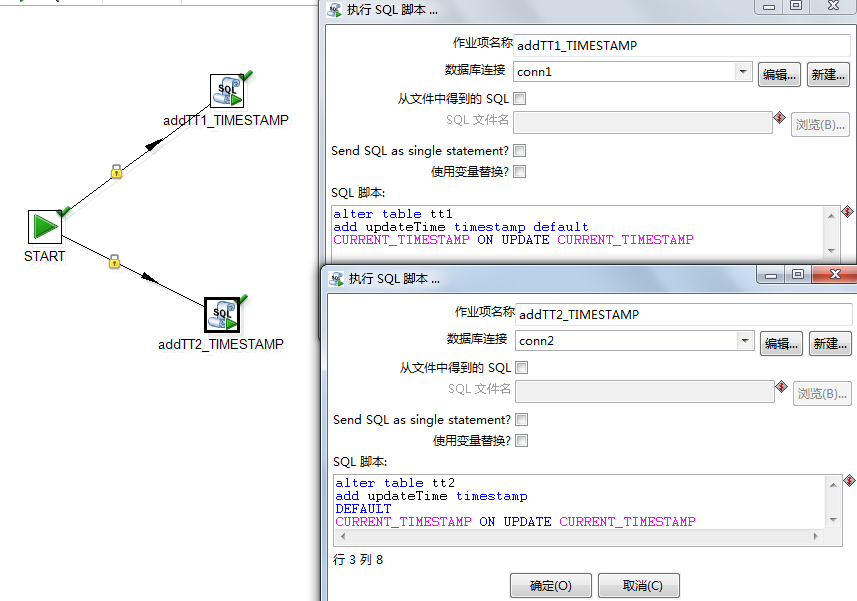
kettle-3
在执行这个job之后,就会在数据库查询的时候看到下面的字段:
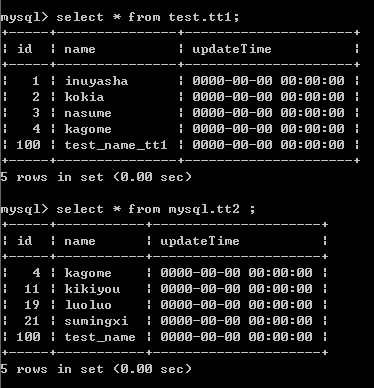
kettle-4
然后, 我们来对tt1表做一个 insert 操作 一个update操作吧~
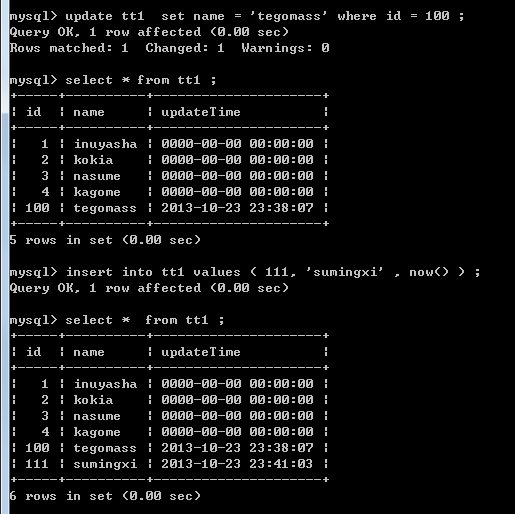
kettle-5
在原表上无论是insert操作还是update操作,对应的updateTime都会发生变更。
如果tt1 表 和 tt2 表中 updateTime 字段为最新时间的话,则说明该表是新表 。
下面只要是对应main_thread的截图:
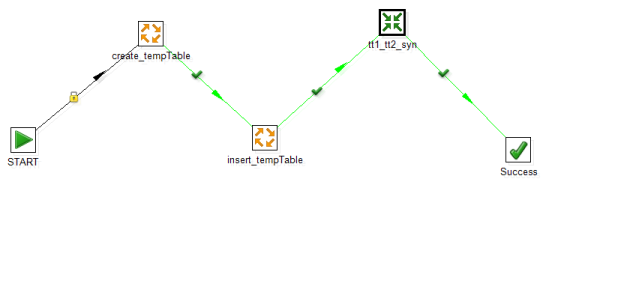
kettle-6
在这里介绍一下Main的层次:
Main
START
Main.prepare
Main.main_thread
{
START
main_thread.create_tempTable
main_thread.insert_tempTable
main_thread.tt1_tt2_syn
SUCCESS
}
Main.finish
SUCCESS
在main_thread中的过程是这样的:
作为一个局部的整体,使它每隔200s内进行一次循环,
这样的话,如果在其中有指定的表 tt1 或是 tt2 对应被更新或是插入的话,
该表中的updateTime字段就会被捕捉到,并且进行同步。
如果没有更新出现,则会走switch的 default 路线对应的是write to log.
继续循环。
首先创建一个快照表,然后将tt1,tt2表中的最大(最新)时间戳的值插入到快照表中。
然后,通过一个transformation来判断那个表的updateTime值最新,
来选择对应是 tt1表来更新 tt2 还是 tt2 表来更新 tt1 表;
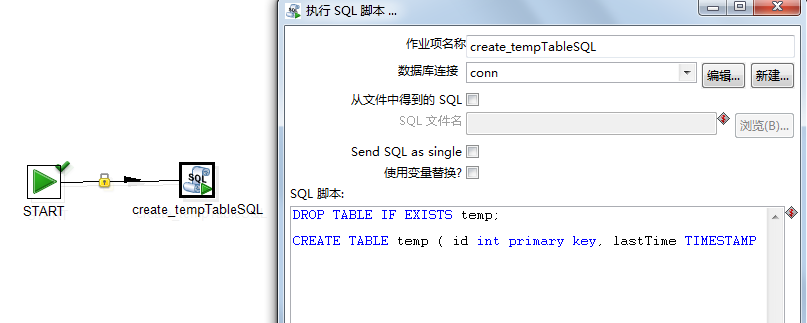
main_thread.create_tempTable.JOB:
main_thread.insert_tempTable.Job:

PS: 对于第二个SQL 应该改成(不修改会出错的)
set @var1 = ( select MAX(updatetime) from tt2);
insert into test.temp values ( 2 , @var1 ) ;
因为conn对应的是连接mysql(数据库实例名称),
但是我们把快照表和tt1 表都存到了test(数据库实例名称)里面。
在上面这个图中对应的语句是想实现,在temp表中插入两行记录元组。
其中id为1 的元组对应的temp.lastTime 字段 是 从tt1 表中选出的 updateTime 值为最新的,
id 为2的元组对应的 temp.lastTime 字段 是 从 tt2 表中选出的 updateTime 值为最新的 字段。
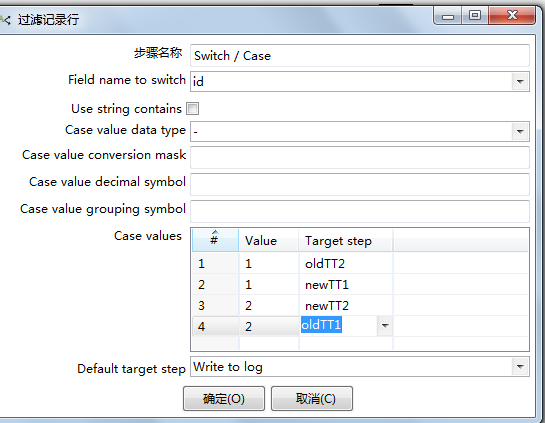
当然 , id 是用来给后续 switch 操作提供参考的,用于标示最新 updateTime 是来自 tt1 还是 tt2,
同样也可以使用 tableName varchar(50) 这种字段 来存放 最新updateTime 对应的 数据库.数据表的名称也可以的。
main_thread.tt1_tt2_syn.Transformation:
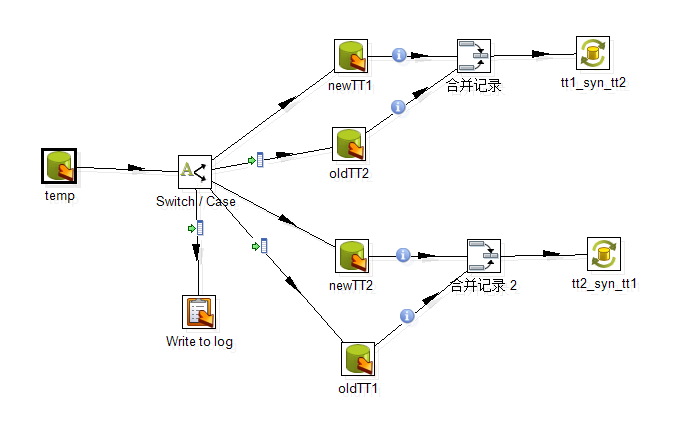
首先,创建连接 test 数据库的 temp 表的连接,
选择 temp表中 对应 lastTime 值最新的所在的记录
所对应的 id 号码。
首先将temp中 lastTime 字段进行 降序排列,
然后选择id , 并且将选择记录仅限定成一行。
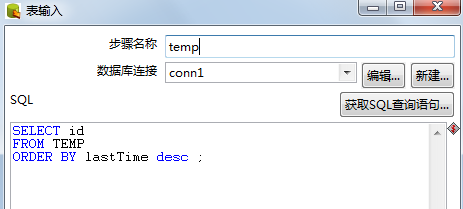
然后根据id的值进行 switch选择。
在这里LZ很想使用,SQL Executor,
但是它无法返回对应的id值。
但是表输入可以返回对应的id值,
并被switch接收到。
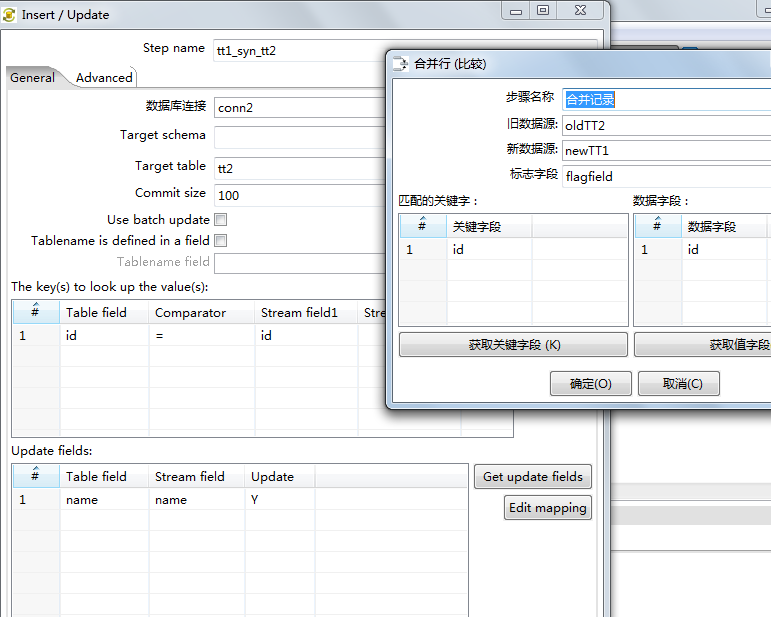
下图是对应 switch id = 1 的时候:即 tt1 更新 tt2
注意合并行比较 的新旧数据源 的选择
和Insert/Update 中的Target table的选择
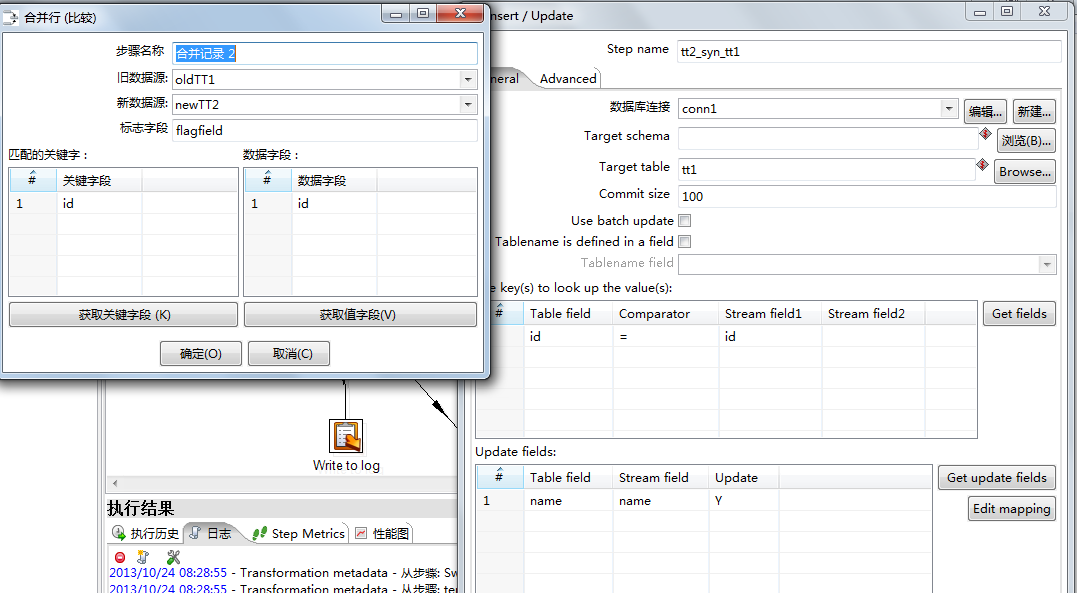
下图是对应 switch id = 2 的时候:即 tt2 更新 tt1
注意合并行比较 的新旧数据源 的选择
和Insert/Update 中的Target table的选择
但是考虑到增加一个 column 会浪费很多的空间,
所以咋最终结束同步之后使用 finish操作步骤来将该 updateTime这个字段进行删除操作即可。
这个与Main中的prepare的操作是相对应的。
Main.finish
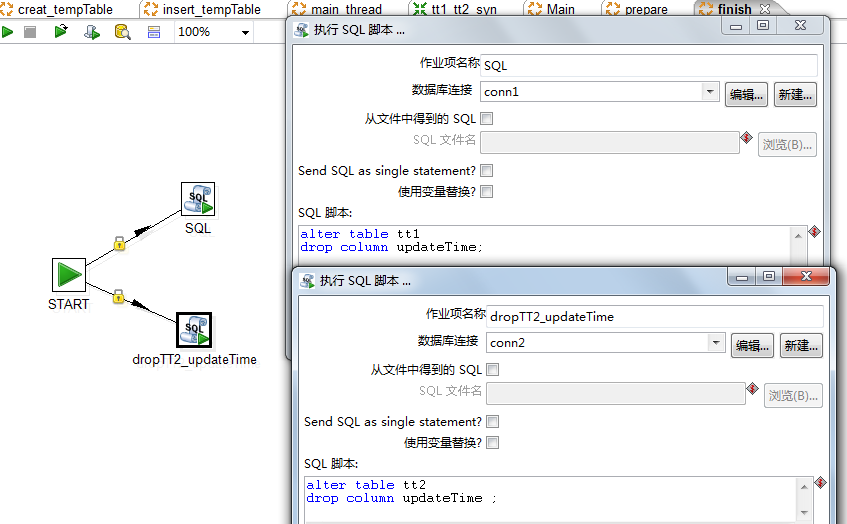
这样的话,实验环境已经搭建好了,
接下来进行,实验的数据测试了,写到下一个博客中。
当然,触发器也是一种同步的好方法,写到后续博客中吧~
时间戳的方式相比于触发器,较为简单并且通用,
但是 数据库表中的时间戳字段,很费空间,并且无法对应删除操作,
也就是说 表中删除一行记录, 该表应该作为新表来更新其余表,但是由于记录删除 时间戳无所依附所以无法记录到。