目录
1.zookeeper概述
2.什么是zookeeper?
3.为什么使用zookeeper?
4.zookeeper的特性
5.事务Transaction的ACID特性
6.zookeeper的应用场景主要是?
7.zookeeper的角色与系统模型
8.leader角色与leader选举机制
9.二阶提交和三阶提交
10.2PC-3PC主要区别
11.zookeeper的主要协议
12.Paxos协议概述
13.zookeeper系统模型
14.会话(Session)
15.数据节点(Znode)
16.zookeeper的顺序号
17.zookeeper的保证
18.zookeeper工作原理
1.zookeeper概述
zookeeper又叫做分布式过程协同服务技术,它是为用户的分布式应用程序提供协调服务的。
zookeeper本身就是一个分布式程序,而且可以组建专门由zookeeper组成的集群。但是有一个条件就是他要满足半数以上节点必须是存活的(因为这样它才能发起一种机制叫做投票机制)。
zookeeper所提供的服务涵盖:主从协调、服务器节点动态上下线、统一配置管理、分布式共享锁、统一名称服务等。
虽然说可以提供各种服务,但是zookeeper在底层只提供了2个功能:
a.管理(存储、读取)用户程序提交的数据;
b.并为用户程序提供数据节点监听服务。
通俗的来说,zookeeper顾名思义就是动物园管理员,它是拿来管理大象(Hadoop)、蜜蜂(Hive)、小猪(Pig)的管理员。
Apache Hbase和Apache Solr以及LinkedIn sensei等项目(还有kafka、spark等)中都采用到了zookeeper。
zookeeper是一个分布式的、开放源码的分布式应用程序协调服务,zookeeper是以Fast Paxos协议为基础,实现同步服务,配置维护和命名服务等分布式应用。
zookeeper意欲设计一个易于编程的环境,它的文件系统使用我们所熟悉的目录树结构(zookeeper不依赖于hdfs,也就是说它在本地文件系统上就能搞定,它有单独属于自己的一套所谓文件系统目录树,不过这个需要我们进入客户端才能看到)。
zookeeper使用Java所编写,但是支持Java和c两种编程语言。
众所周知,协调服务非常容易出错,但是却很难恢复正常(为什么?因为协调服务需要管理所有人的动作,一旦出现了所谓的协调不一致,或者说步调不一致,整个协调服务就面临失败的风险,整个集群可能就会崩溃)。例如,协调服务很容易处于竞态以至于出现死锁(什么叫做竞态?比如说发生了资源争抢,此时共享式资源为了保护自身就会加锁,那么就会出现死锁)。设计zookeeper的目的是为了减轻分布式应用程序所承担的协调任务。
在分布式系统中,每一个机器节点虽然都能明确的知道自己在进行事物操作过程中的结果是成功还是失败,但是无法直接获取到其他分布式节点的操作结果(结果需要通过网络进行结果传输)。因此,当一个事物操作需要跨越多个分布式节点的时候,为了保持事务处理的ACID(原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability))特性,就需要引入一个称之为“协调者(Coordinator)”的组件来统一调度所有分布式节点的执行逻辑,这些被调度的分布式节点则被称为“参与者(Participant)”。协调者负责调度参与者的行为,并最终决定了这些参与者是否要把事务真正提交。基于这个思想,衍生出了二阶段提交和三阶段提交两种协议一致性算法。
2.什么是zookeeper?
zookeeper是Google的Chubby一个开源的实现,是Hadoop的分布式协调服务。
它包含一个简单的原语集,分布式应用程序可以基于它实现同步服务,配置维护和命名服务等。
3.为什么使用zookeeper?
大部分分布式应用需要一个主控、协调器或控制器来管理物理分布的子进程(如资源、任务分配等);
目前,大部分应用需要开发私有的协调程序,缺乏一个通用的机制;
协调程序的反复编写浪费,且难以形成通用、伸缩性好的协调器;
zookeeper提供通用的分布式锁服务,用以协调分布式应用。
4.zookeeper的特性
zookeeper是简单的
zookeeper是富有表现力的
zookeeper具有高可用性
zookeeper采用松耦合交互方式
zookeeper是一个资源库
5.事务Transaction的ACID特性
原子性(Atomicity)
事务必须是原子工作单元;对于其数据修改,要么全都执行,要么全都不执行。
一致性(Consistency)
事务在完成时,必须使所有的数据都保持一致状态。
例如,当开发用于转账的应用程序时,应避免在转账过程中任意移动小数点。
隔离性(Isolation)
由并发事务所作的修改必须与任何其他并发事务所作的修改隔离。
持久性(Durability)
事务完成后,它对于系统的影响是永久的。
6.zookeeper的应用场景主要是?
(1) 服务器状态的动态感知,例:
主从模式:(master选举机制)HBASE主从集群HADOOP 2.x HA机制
Hadoop2.0,使用zookeeper的事务处理确保整个集群只有一个活跃的NameNode,存储配置信息等。
HBase,使用zookeeper的事务处理确保整个集群只有一个HMaster,察觉HRegionServer联机和宕机,存储访问控制列表等。
zookeeper集群自身群首保证:(leader选举机制)zookeeper集群自身,但是要满足半数以上存活
(2) 统一配置管理统一名称服务,例:
分布式应用中,通常需要有一套完整的命名规则,既能够产生唯一的名称又便于人识别和记住。通常情况下用树形的名称结构是一个理想的选择,树形的名称结构是一个有层次的目录结构,既对人友好又不会重复。
Name Service是zookeeper内置的功能,只要调用zookeeper的API就能实现。
(3) 分布式共享锁管理
7.zookeeper的角色与系统模型
Leader-群首
Follower-追随者
Observer-观察者
PS:如果是单机使用的话,只有一种角色就是standalone
角色检查命令速记:$ZOOKEEPER_HOME/bin/zkServer.sh status

8.leader角色与leader选举机制
leader作为整个zookeeper集群的主节点,负责响应所有对zookeeper状态变更的请求。它会将每个状态更新请求进行排序和编号,以便保证整个集群内部消息处理的FIFO(First In First Out)。
一个zookeeper集群里只有一个leader,当这个leader死了之后,剩下的follower需要再选举一个leader。此时剩余的节点必须超过半数以上。
集群容灾公式=集群个数/2-1(这里可以看到他的值是奇数)
集群容灾允许集群损坏一半的机器(生成系统中)(但是这只是一个阈值,最好不要在实际中发生损坏一半这种事)
leader选举
每个server启动以后都询问其他的server它要投票给谁。
对于其他server的询问,server每次根据自己的状态都回复自己推荐的leader的id和上一次处理事务的zxid(系统启动时每个server都会推荐自己)。
受到所有server回复后,就计算出zxid最大的那个server,并将这个server相关信息设置成下一次要投票的server。
计算这过程中获得票数最多的server为获胜者,如果获胜者的票数超过半数,则该server被选为leader。否则,继续这个过程,直到leader被选举出来。
leader就会开始等待server连接
follower连接leader,将最大的zxid发送给leader
leader根据follower的zxid确定同步点
完成同步后通知follower已经成为uptodate状态
follower收到uptodate消息后,又可以重新接受client的请求服务了

9.二阶提交和三阶提交
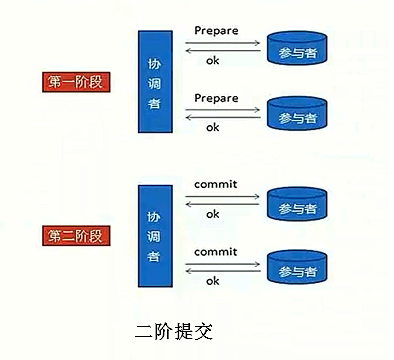
二阶段提交协议简称2PC,即Two-Phase Commit的缩写。顾名思义,二阶段协议一共分为2个阶段。
阶段一:提交事务请求
协调者向所有参与者询问,是否可以执行事务操作?
如果所有参与者的回答都是可以,那么就进入下一个阶段,真正执行事务提交。
注意:如果这个阶段有参与者没有回答,则将一直等待其回答或者依赖协调者自身的超时机制进行事务中断。
阶段二:执行事务提交
将事务提交执行,各个参与者负责自己的部分,最终都将自己的执行结果反馈给协调者。
注意:如果所有参与者都正确回答,在协调者向所有参与者分配其要提交的任务时网络出现问题,将会造成只有一部分接收到协调者信息的参与者执行自身所负责的那部分事务。这样就会导致整个分布式系统出现数据不一致的情况,俗称脑裂。
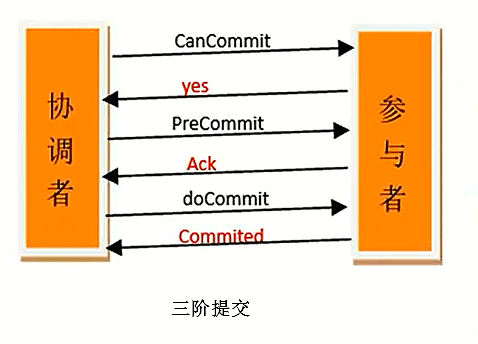
三阶段提交(Three-Phase commit),也叫三阶段提交协议(Three-Phase commit protocol),是二阶段提交(2PC)的改进版本。
阶段一:询问是否可以执行事务
这个阶段协调者向所有的参与者询问是否可参加执行事务。参与者接收到来自协调者的请求后如果自身可以执行,就进入准备阶段。
阶段二:准备提交事务
如果阶段一中的所有参与者回答的结果都是正常的,就执行事务的预提交。
注意:如果有任何一个参与者向协调者反馈的是非正常的,或者在等待超时之后协调者无法接收到所有参与者的反馈响应,那么就会中断事务。
阶段三:执行事务
真正进行事务提交。
注意:如果此时协调者出现问题或者协调者和参与者之间的网络出现问题,参与者都会在等待超时之后,继续进行事务提交,这种情况必然会导致分布式数据的不一致性。
二阶提交举例:
你喜欢一个女孩,有一天你鼓起勇气去问这个女孩?
第一阶段:我可以追你吗?
女孩同意了!(当然,只收乐观的去想)
第二阶段:女孩追到手进入到恋爱阶段。
三阶段提交举例:
可以参考TCP协议的三次握手
与二阶段提交不同的是,三阶段提交有2个改动点:
(1) 引入超时机制。同时在协调者和参与者中都引入超时机制。
(2) 在第一阶段和第二阶段中插入了一个准备阶段。保证了在最后提交阶段之前各参与节点的状态是一致的。
也就是说,除了引入超时机制之外,3PC把2PC的准备阶段再次一分为二,这样三阶段提交就有CanCommit、PreCommit、DoCommit三个阶段。
10.2PC-3PC主要区别
相对于2PC,3PC主要解决的是单点故障问题,并减少阻塞.。因为一旦参与者无法及时收到来自协调者的信息之后,他会默认执行commit。而不会一直持有事务资源并处于阻塞状态。但是这种机制也会导致数据一致性问题。因为由于网络原因,协调者发送的abort响应没有及时被参与者接收到,那么参与者在等待超时之后执行了commit操作,这样就和其他接到abort命令并执行回滚的参与者之间存在数据不一致的情况。
了解了2PC和3PC之后,我们可以发现,无论是二阶段提交还是三阶段提交都无法彻底解决分布式的一致性问题。Google Chubby的作者Mike Burrows说过,there is only one consensus protocol,and that's Paxos-all other approaches are just broken versions of Paxos.意即世上只有一种一致性算法,那就是Paxos,所有其他一致性算法都是Paxos算法的不完整版。
11.zookeeper的主要协议
二阶段提交、三阶段提交协议和Paxos协议都是分布式应用程序的通用协议,即在大部分的分布式应用程序中都可以使用。ZAB(zookeeper Atomic Broadcast,zookeeper原子消息广播协议)协议是zookeeper设计之初专门为雅虎内部那些高吞吐量、低延迟、健壮、简单的分布式场景设计的。所以ZAB不是一种通用型算法,而是一种特别为zookeeper设计的崩溃可恢复的原子消息广播算法。ZAB算法可以看成是Paxos协议的一种具体实现。
zookeeper中将自己的角色设置主要为Leader、Follower、OBserver。Leader和Follower都是zk的server,只不过由Leader(只有一个,类似于Hadoop中的NameNode)对外提供服务,众多Follower(类似于Secondary NameNode,不过Follower会有多个)随时等Leader出现问题时选举出一个新Leader来继续对外提供以保证zk服务的高可用。
12.Paxos协议概述
举一个简单的例子来说明整个选举的过程:
假设有五台服务器组成的zookeeper集群,它们的id从1-5。同时它们都是最新启动的,也就是没有历史数据,在存放数据量这一点上,都是一样的。假设这些服务器依序启动,来看看会发生什么?
(1) 服务器1启动,此时只有它一台服务器启动了,它发出去的包没有任何响应,所以它的选举状态一直是LOOKING状态。
(2) 服务器2启动,它与最开始启动的服务器1进行通信,互相交换自己的选举结果,由于两者都没有历史记录,所以id值较大的服务器2胜出,但是由于没有达到超过半数以上的服务器都同意选举它(这个例子中的半数以上是3),所以服务器1,2还是继续保持LOOKING状态。
(3) 服务器3启动,根据前面的理论分析,服务器3成为服务器1,2,3中的老大,而与上面不同的是,此时有三台服务器选举了它,所以它成为了这次选举的leader。
(4) 服务器4启动,根据前面的分析,理论上服务器4应该成为服务器1,2,3,4中最大的,但是由于前面已经有半数以上的服务器选举了服务器3,所以它只能接受当小弟的命了。
(5) 服务器5启动,同4一样,当小弟。
13.zookeeper系统模型

14.会话(Session)
Session是指客户端会话。在zookeeper中,一个客户端连接是指客户端和服务器之间的一个TCP长连接。zookeeper对外的服务端口默认是2181,客户端启动的时候,首先会与服务器建立一个TCP连接,从第一次连接建立开始,客户端会话的生命周期就开始了,通过这个连接,客户端能够通过心跳检测与服务器保持有效的会话,也能够向zookeeper服务器发送请求并接受响应,同时还能够通过该连接接收来自服务器的watch事件通知,Session的sessionTimeOut值用来设置一个客户端会话的超时间。当由于服务器压力太大、网络故障或是客户端主动断开连接等各种原因导致的客户端连接断开时,只要在sessionTimeOut规定的时内能重新连接上集群中的任意一台服务器,那么之前创建的会话仍然有效。
15.数据节点(Znode)
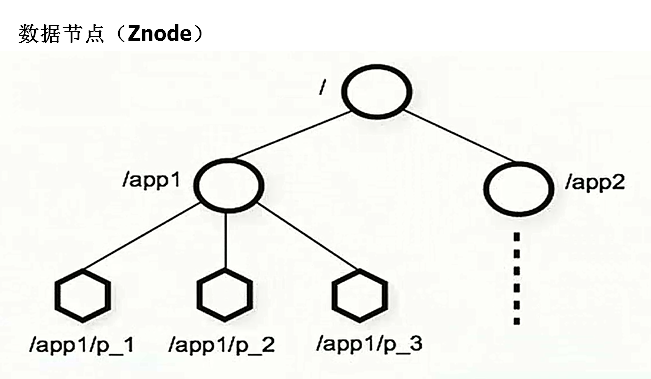
在分布式中我们通常说的“节点”是指组成集群的每一台机器。然而,在zookeeper中,“节点”分为两类,第一类同样是指构成集群的机器,我们称之为机器节点。第二类则是指数据模型中的数据单元,我们称之为数据节点——Znode。zookeeper将所有数据存储在内存中,数据模型是一棵树(ZNode Tree),由斜杠(/)进行分割的路径,就是一个Znode,例如/foo/path1。每个ZNode都会保存自己的数据内容,同时还会保存一系列属性信息。
Znode有4种形式的目录节点,PERSISTENT、PERSISTENT_SEQUENTIAL、EPHEMERAL、EPHEMERAL_SEQUENTIAL。
在zookeeper中,ZNode可以分为持久(persistent)节点和临时(ephemeral)节点两类。所谓持久节点是指一旦这个ZNode被创建了,除非主动进行ZNode的移除操作,否则ZNode将一直保存在zookeeper上。而临时节点就不一样了,他的生命周期和客户会话绑定,一旦客户端会话失败,那么这个客户端创建的所有临时节点都会被删除。临时节点不可以有子节点。另外,zookeeper还允许用户为每一个节点添加一个特殊的属性SEQUENTIAL。一旦节点被标记上这个属性,那么在这个节点被创建的时候,zookeeper会自动在其节点名后面追加上一个整型数字,这个整型数字是由父节点维护的自增数字。
zookeeper在各种分布式场景下发挥作用的主要方式就是数据节点和监控器,我们可以给数据节点赋予任意我们想赋予的含义,来协助我们更好的处理分布式程序中所面临的问题。具体案例详见后文中的zookeeper的其他典型应用场景。
16.zookeeper的顺序号
创建Znode时设置顺序标识,Znode名称后会附加一个值
顺序号是一个单调递增的计数器,由父节点维护
在分布式系统中,顺序号可以被用于为所有的事件进行劝解排序,这样客户端可以通过顺序号推断事件的顺序
17.zookeeper的保证
更新请求顺序进行,来自同一个client的更新请求按其发送顺序依次执行
数据更新原子性,一次数据更新要么成功,要么失败
全局唯一数据视图,client无论连接到哪个server,数据视图都是一致的
实时性,在一定时间范围内,client能读到最新数据
18.zookeeper工作原理
zookeeper的核心是原子广播,这个机制保证了各个server之间的同步。实现这个机制的协议叫做ZAB协议。ZAB协议有两种模式,它们分别是恢复模式和广播模式。
当服务启动或者leader崩溃后,ZAB就进入了恢复模式,当leader被选举出来,且大多数server完成了和leader的状态同步后,恢复模式就结束了。状态同步保证了leader和server具有相同的系统状态。
广播模式需要保证proposal被按顺序处理,因此zk采用了递增的事务id号(zxid)来保证。所有的提议(proposal)都在被提出的时候加上了zxid。实现中zxid是一个64位的数字,它高32位是epoch用来标识leader关系是否改变,每次一个leader被选出来,它都会有一个新的epoch。低32位是个递增计数。
当leader崩溃或者leader失去大多数的follower,这时候zk进入恢复模式,恢复模式需要重新选举出一个新的leader,让所有的server都恢复到一个正确的状态。
一旦leader已经和多数的follower进行了状态同步后,它就可以开始广播消息了,即进入广播状态。这时候当一个server加入zookeeper服务中,它会在恢复模式下启动,发现leader,并和leader进行状态同步。待到同步结束,它也参与消息广播。zookeeper服务一直维持在Broadcast状态,直到leader崩溃了或者leader失去了大部分的followers支持。