统计匹配字符串个数:
grep -o "id" train-v1.1.json | wc -l
生成的txt一不小心带了./,用vim替换:
:%s/./single/single #%s/xxx/yyy/g是全文本替换,这里用将特殊字符.和/转换成普通字符
生成图片list:
find dir/ -name "*.jpg" -exec basename {} ; > lists.txt #加上basename就不带路径了
find oriPic -name "*.jpg" -exec basename {} ; | sort -n> list1.txt #按文件名升序
find oriPic -name "*.jpg" -exec basename {} ; | sort -r> list1.txt #按文件名降序
find -name "._*" -exec rm {} ; #删除讨厌的._开头的隐藏文件
txt乱序:
cat total.txt | awk 'BEGIN{srand()}{print rand()" "$0}' | sort -k1,1 -n | cut -f2- > totals.txt
txt相隔固定行数删除:
cat in.txt | awk '{if ( NR % 2==0)print $0}' > out.txt #隔一行删除并保存到out.txt
txt寻找匹配字符并删除到行尾:
:%s/.jpg.*// #删除每行的.jpg及后面的字符
:%s/.*.jpg// #删除每行开头到.jpg的字符
根据list拷贝:
cp `cat list.txt` list/ #list.txt里包含完整路径,desDir是要被拷贝的路径
拷贝/删除大量小文件:
find fromDir/ -name "*.xml" | xargs -I {} cp {} toDir/
上述命令在某次安装软件的时候用到,用homebrew装的,提示brew linkapps不可用:
ln -s `find /usr/local/ -name "mpv.app"` /Applications/mpv.app
删除带某些字符的行:
sed -e '/abc/d' a.txt > a.log #删除带abc的行保存到a.log
多线程压缩大量小文件:
tar czvf xxx.tar.gz xxx #单线程压缩 tar -cf - xxx | pigz -p 12 > xxx.tar.gz #多线程压缩,需要安装pigz,12是线程数
if [ "${file##*.}"x = "txt"x ] #后缀是否txt
目录下图片批量生成list:
for file in `ls ./` do if [ -d $file ] then find $file -name "*.jpg" -exec basename {} ; > $file.txt fi done
一个路径下有大量图片,平均拆分:
find img/ -name "*.jpg" > list.txt #假设跟路径名img,图片后缀.jpg wc -l list.txt #查看总数,假设为5万,平均拆成5份 split -l 10000 list.txt new #将会生成5个new开头文件:newaa newab等 mkdir new_a #新建一个文件夹 cat newaa | xargs -I mv {} new_a {} #newaa里的1万行图片移动到new_a #其他路径如法炮制,当要拆分的数量比较多时可以写个后台执行
支持断点续传的wget:
wget -c -t 0 地址 #-c断点续传 -t 0表示不限制次数
split -b 100M data.bak sdata #按字节 split -l 1000 large_file.txt stxt #按行
sshfs user_name@host_name:/xxx/yyy/zzz ./zzz #远程目录挂载到本地 fusermount -u mount_point #卸载 umount -fl ./mount_point #出现device is busy的解决办法
find ./ -size 0c #0大小文件 find ./ -size +3k -a -size -10k #找出当前目录[3KB,10KB]大小的文件
linux打开windows生成的中文文档乱码:作者讲要2次保存utf-8,亲测直接windows下记事本打开另存为,然后linux下vim打开就不是乱码了:
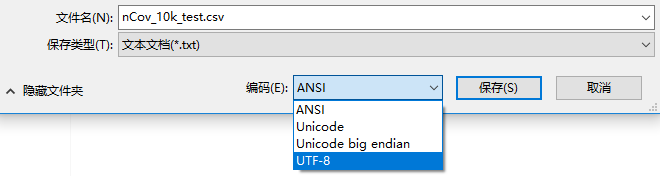
# 转换编码 def re_encode(path): with open(path, 'r', encoding='GB2312', errors='ignore') as file: lines = file.readlines() with open(path, 'w', encoding='utf-8') as file: file.write(''.join(lines)) re_encode('data/data22724/nCov_10k_test.csv') re_encode('data/data22724/nCoV_100k_train.labled.csv')
-------------------------------------------