1,粘包现象
让我们基于tcp先制作一个远程执行命令的程序(1:执行错误命令 2:执行ls 3:执行ifconfig)
注意注意注意:
res=subprocess.Popen(cmd.decode('utf-8'), shell=True, stderr=subprocess.PIPE, stdout=subprocess.PIPE)
的结果的编码是以当前所在的系统为准的,如果是windows,那么res.stdout.read()读出的就是GBK编码的,在接收端需要用GBK解码
且只能从管道里读一次结果
注意:命令ls -l ; lllllll ; pwd 的结果是既有正确stdout结果,又有错误stderr结果
服务端:
import socket import struct import subprocess phone = socket.socket(socket.AF_INET,socket.SOCK_STREAM) phone.bind(("127.0.0.1",9090)) phone.listen(5) while True: conn,cline_addr = phone.accept() print("客户端:",cline_addr) while True: try: cmd = conn.recv(1024) if len(cmd) == 0: break print("客户端发来信息:",cmd.decode("utf-8")) # 运行系统令命 obj = subprocess.Popen(cmd.decode("utf-8"),shell=True,stderr=subprocess.PIPE,stdout=subprocess.PIPE) stdout = obj.stdout.read() stderr = obj.stderr.read() size = len(stdout)+len(stderr) header = struct.pack("i",size) conn.send(stdout) conn.send(stderr) except ConnectionRefusedError: break conn.close()
客户端:
import socket import struct phone = socket.socket(socket.AF_INET,socket.SOCK_STREAM) phone.connect(("127.0.0.1",9090)) while True: cmd = input(">>>").strip() if cmd == "q": break if len(cmd) == 0: continue phone.send(cmd.encode("utf-8")) header = phone.recv(4) total_size = struct.unpack("i",header)[0] size = 0 while size < total_size: date = phone.recv(1024) size+=len(date) print(date.decode("gbk")) else: print() phone.close()
2,什么是粘包
须知:只有TCP有粘包现象,UDP永远不会粘包,为何,且听我娓娓道来
只有TCP存在粘包,UDP永远不会粘包。因为TCP协议是面向流的协议,这也是容易出现粘包问题的原因。而UDP是面向消息的协议,每个UDP段都是一条消息,应用程序必须以消息为单位提取数据,不能一次提取任意字节的数据,这一点和TCP是很不同的。
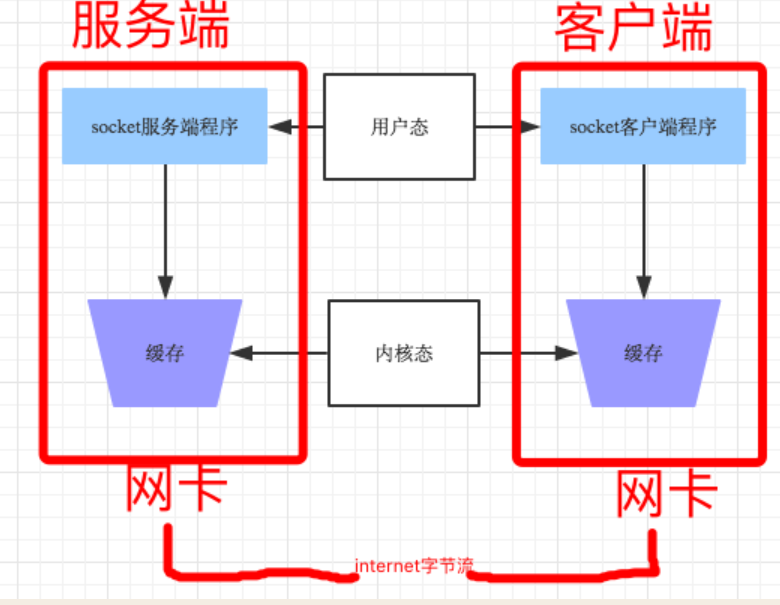
所谓粘包问题主要还是因为接收方不知道消息之间的界限,不知道一次性提取多少字节的数据所造成的。
此外,发送方引起的粘包是由TCP协议本身造成的,TCP为提高传输效率,发送方往往要收集到足够多的数据后才发送一个TCP段。若连续几次需要send的数据都很少,通常TCP会根据优化算法把这些数据合成一个TCP段后一次发送出去,这样接收方就收到了粘包数据。
- TCP(transport control protocol,传输控制协议)是面向连接的,面向流的,提供高可靠性服务。收发两端(客户端和服务器端)都要有一一成对的socket,因此,发送端为了将多个发往接收端的包,更有效的发到对方,使用了优化方法(Nagle算法),将多次间隔较小且数据量小的数据,合并成一个大的数据块,然后进行封包。这样,接收端,就难于分辨出来了,必须提供科学的拆包机制。 即面向流的通信是无消息保护边界的。
- UDP(user datagram protocol,用户数据报协议)是无连接的,面向消息的,提供高效率服务。不会使用块的合并优化算法,, 由于UDP支持的是一对多的模式,所以接收端的skbuff(套接字缓冲区)采用了链式结构来记录每一个到达的UDP包,在每个UDP包中就有了消息头(消息来源地址,端口等信息),这样,对于接收端来说,就容易进行区分处理了。 即面向消息的通信是有消息保护边界的。
- tcp是基于数据流的,于是收发的消息不能为空,这就需要在客户端和服务端都添加空消息的处理机制,防止程序卡住,而udp是基于数据报的,即便是你输入的是空内容(直接回车),那也不是空消息,udp协议会帮你封装上消息头。
产生粘包的两种场景:
#1、发送端需要等缓冲区满才发送出去,造成粘包(发送数据时间间隔很短,数据了很小,会合到一起,产生粘包) #2、接收方不及时接收缓冲区的包,造成多个包接收(客户端发送了一段数据,服务端只收了一小部分,服务端下次再收的时候还是从缓冲区拿上次遗留的数据,产生粘包)
3,解决粘包的方法
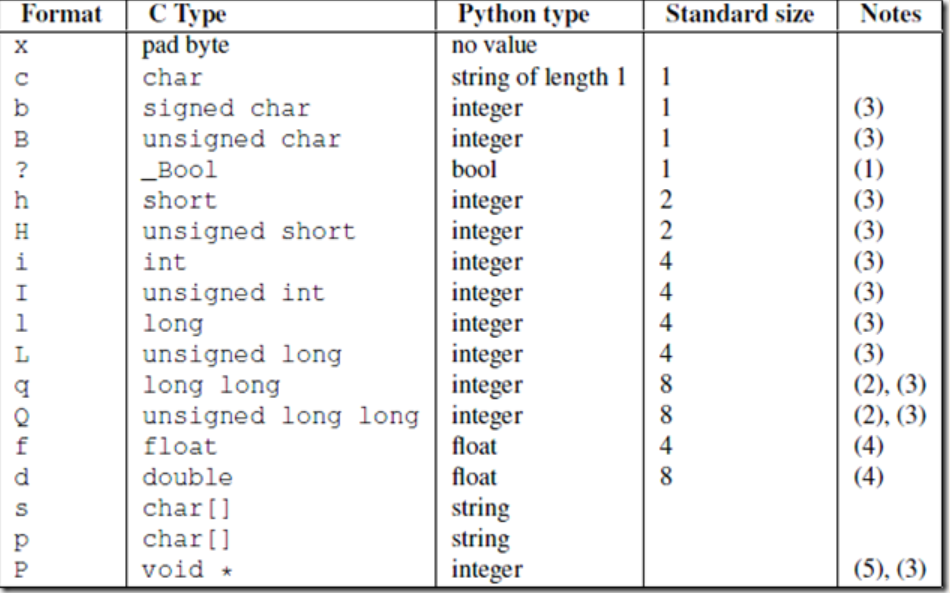
使用struct模块
为字节流加上自定义固定长度报头,报头中包含字节流长度,然后一次send到对端,对端在接收时,先从缓存中取出定长的报头,然后再取真实数据
服务端自定义报头
# 服务端应该满足两个特点: # 1、一直对外提供服务 # 2、并发地服务多个客户端 import subprocess import struct import json from socket import * server=socket(AF_INET,SOCK_STREAM) server.setsockopt(SOL_SOCKET,SO_REUSEADDR,1) #就是它,在bind前加 server.bind(('127.0.0.1',8083)) server.listen(5) # 服务端应该做两件事 # 第一件事:循环地从板连接池中取出链接请求与其建立双向链接,拿到链接对象 while True: conn,client_addr=server.accept() # 第二件事:拿到链接对象,与其进行通信循环 while True: try: cmd=conn.recv(1024) if len(cmd) == 0:break obj=subprocess.Popen(cmd.decode('utf-8'), shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE ) stdout_res=obj.stdout.read() stderr_res=obj.stderr.read() total_size=len(stdout_res)+len(stderr_res) # 1、制作头 header_dic={ "filename":"a.txt", "total_size":total_size, "md5":"123123xi12ix12" } json_str = json.dumps(header_dic) json_str_bytes = json_str.encode('utf-8') # 2、先把头的长度发过去 x=struct.pack('i',len(json_str_bytes)) conn.send(x) # 3、发头信息 conn.send(json_str_bytes) # 4、再发真实的数据 conn.send(stdout_res) conn.send(stderr_res) except Exception: break conn.close()
客户端自定义报头
import struct import json from socket import * client=socket(AF_INET,SOCK_STREAM) client.connect(('127.0.0.1',8083)) while True: cmd=input('请输入命令>>:').strip() if len(cmd) == 0:continue client.send(cmd.encode('utf-8')) # 接收端 # 1、先手4个字节,从中提取接下来要收的头的长度 x=client.recv(4) header_len=struct.unpack('i',x)[0] # 2、接收头,并解析 json_str_bytes=client.recv(header_len) json_str=json_str_bytes.decode('utf-8') header_dic=json.loads(json_str) print(header_dic) total_size=header_dic["total_size"] # 3、接收真实的数据 recv_size = 0 while recv_size < total_size: recv_data=client.recv(1024) recv_size+=len(recv_data) print(recv_data.decode('utf-8'),end='') else: print()