在上篇《Web Api 端点设计 与 Oauth》后,接着我们思考Web Api 的内部数据:
其他文章:《API接口安全加强设计方法》
第一 实际使用应该返回怎样的数据 ?
如何减少api访问次数非常重要,但是我们会遇到,当我们尽可能的返回多的信息,多的字段,那么一次请求,将会带来大量的毫无意义的信息。当我们尽可能的节约,那么客户端需要多次请求才能拿到想要的数据,于是高不成,低不就。
优化方法:让客户端来选择响应的内容,例:
http://api.example.com/v1/users/12345?fields=name,age
通过fields来指定想要返回的字段,那么还可以进行怎样的分类呢?
利用响应群来获取想要的数据
small :
字段1,字段2,字段3
medium:
字段1,字段2,字段3,字段4,字段5,字段6
large:
字段1,字段2,字段3,字段4,字段5,字段6,字段7,字段8
通过分配group参数,来指定想要的哪些群组
第二 状态码是否必要?
我们来看一下某些数据:
{
“status” : {
"result" : "success",
"errorCode" : 0,
}
"response" :{
.......实际的数据......
}
}
我们写接口常常有这个习惯,将状态码写于返回值中,这样也可以,但我们经常忽略了,web api 大部分都是基于http协议,可以说http已经完成了封装的工作。http协议首部可以放置状态码,可以选择合适的状态码来返回。然而很多人都没有处理这个状态吗。我以前在对接的过程中,便和对接的公司产生了歧义。
返回的json数据中的code是0,失败的错误码,但对方提出了问题,为什么已经返回失败的错误码,但你们的http状态码是为200.
回到问题本身,我个人认为状态码是需要的,但同时也要做好http状态码的处理,这样做出来的api不容易让人产生误解。
第三 数据是否应该扁平化 ?
我们来看两个例子:
具有层级关系的:
{
"id" : 1111 ,
"message" : "hello" ,
"sender" : {
"id" : 123,
.......
}
"receiver" : {
"id" : 123,
......
}
}
使用扁平化的方式:
{
"id" : 1111 ,
"message" : "hello" ,
"sender_id" : 123,
"sender_....." : ....,
"receiver_id" : 123
"receiver_...." : ....,
}
这种情况我们要具体分析,上述那种情况,可以明显的看出接受方receive,和发送方send,那么此时用层级关系比较好
而像下述这种情况:
使用层级形式:
{
"id" : 23245,
"name" : 'xxx',
"profile" :{
"birthday" : 45,
"gender" : "male",
}
}
使用扁平化方式:
{
"id" : 23245,
"name" : 'xxx',
"birthday" : 45,
"gender" : "male",
}
这种情况下,使用层级跟使用扁平化没什么区别,而使用层级还会让json的尺寸变大,那我们可以在此用扁平化
第四 状态码太多,大致分类是?
HTTP状态码由三个十进制数字组成,第一个十进制数字定义了状态码的类型,后两个数字没有分类的作用。HTTP状态码共分为5种类型:
|
HTTP状态码分类 |
|
|
分类 |
分类描述 |
|
1** |
信息,服务器收到请求,需要请求者继续执行操作 |
|
2** |
成功,操作被成功接收并处理 |
|
3** |
重定向,需要进一步的操作以完成请求 |
|
4** |
客户端错误,请求包含语法错误或无法完成请求 |
|
5** |
服务器错误,服务器在处理请求的过程中发生了错误 |
罗列各种状态码我就不罗列了。
利用http缓存优化 Api
一)强制缓存
强制缓存,在缓存数据未失效的情况下,可以直接使用缓存数据,那么浏览器是如何判断缓存数据是否失效呢?在没有缓存数据的时候,浏览器向服务器请求数据时,服务器会将数据和缓存规则一并返回,缓存规则信息包含在响应header中。
对于强制缓存来说,响应header中会有两个字段来标明失效规则(Expires/Cache-Control)
使用chrome的开发者工具,可以很明显的看到对于强制缓存生效时,网络请求的情况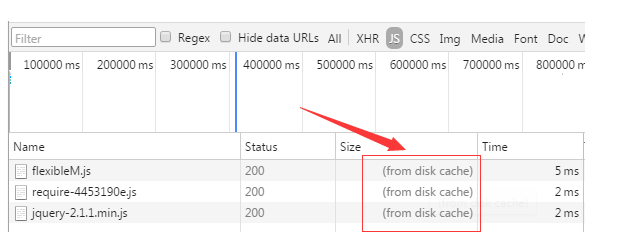
Expires
Expires的值为服务端返回的到期时间,即下一次请求时,请求时间小于服务端返回的到期时间,直接使用缓存数据。
不过Expires 是HTTP 1.0的东西,现在默认浏览器均默认使用HTTP 1.1,所以它的作用基本忽略。
另一个问题是,到期时间是由服务端生成的,但是客户端时间可能跟服务端时间有误差,这就会导致缓存命中的误差。
所以HTTP 1.1 的版本,使用Cache-Control替代。
Cache-Control
Cache-Control 是最重要的规则。常见的取值有private、public、no-cache、max-age,no-store,默认为private。
private: 客户端可以缓存
public: 客户端和代理服务器都可缓存(前端的同学,可以认为public和private是一样的)
max-age=xxx: 缓存的内容将在 xxx 秒后失效
no-cache: 需要使用对比缓存来验证缓存数据(后面介绍)
no-store: 所有内容都不会缓存,强制缓存,对比缓存都不会触发(对于前端开发来说,缓存越多越好,so...基本上和它说886)
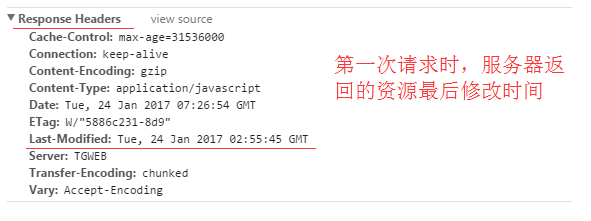
例如:
图中Cache-Control仅指定了max-age,所以默认为private,缓存时间为31536000秒(365天)
也就是说,在365天内再次请求这条数据,都会直接获取缓存数据库中的数据,直接使用。
二)对比缓存
对比缓存,顾名思义,需要进行比较判断是否可以使用缓存。
浏览器第一次请求数据时,服务器会将缓存标识与数据一起返回给客户端,客户端将二者备份至缓存数据库中。
再次请求数据时,客户端将备份的缓存标识发送给服务器,服务器根据缓存标识进行判断,判断成功后,返回304状态码,通知客户端比较成功,可以使 用缓存数据。
第一次访问:

再次访问:
 :
:
通过两图的对比,我们可以很清楚的发现,在对比缓存生效时,状态码为304,并且报文大小和请求时间大大减少。
原因是,服务端在进行标识比较后,只返回header部分,通过状态码通知客户端使用缓存,不再需要将报文主体部分返回给客户端。
对于对比缓存来说,缓存标识的传递是我们着重需要理解的,它在请求header和响应header间进行传递,
一共分为两种标识传递:
Last-Modified / If-Modified-Since
Last-Modified:
服务器在响应请求时,告诉浏览器资源的最后修改时间。
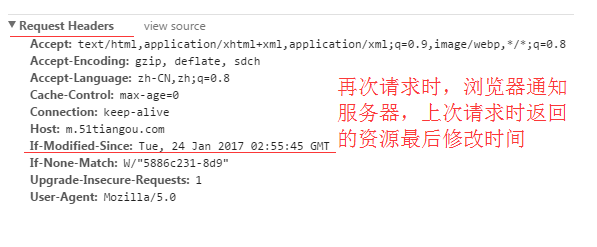
If-Modified-Since:
再次请求服务器时,通过此字段通知服务器上次请求时,服务器返回的资源最后修改时间。
服务器收到请求后发现有头If-Modified-Since 则与被请求资源的最后修改时间进行比对。
若资源的最后修改时间大于If-Modified-Since,说明资源又被改动过,则响应整片资源内容,返回状态码200;
若资源的最后修改时间小于或等于If-Modified-Since,说明资源无新修改,则响应HTTP 304,告知浏览器继续使用所保存的cache。
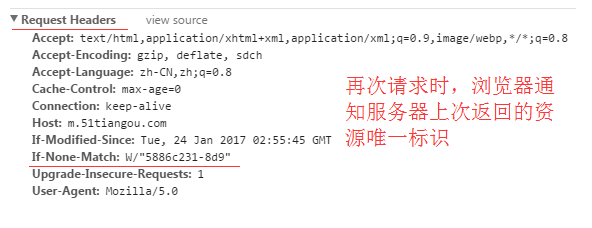
Etag / If-None-Match(优先级高于Last-Modified / If-Modified-Since)
服务器响应请求时,告诉浏览器当前资源在服务器的唯一标识(生成规则由服务器决定)。
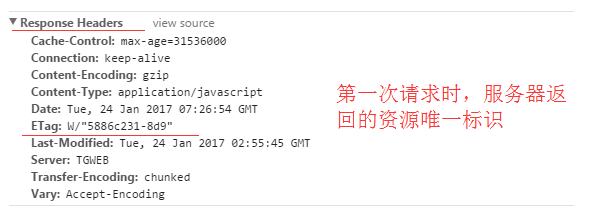
If-None-Match:
再次请求服务器时,通过此字段通知服务器客户段缓存数据的唯一标识。
服务器收到请求后发现有头If-None-Match 则与被请求资源的唯一标识进行比对,
不同,说明资源又被改动过,则响应整片资源内容,返回状态码200;
相同,说明资源无新修改,则响应HTTP 304,告知浏览器继续使用所保存的cache。