摘要
JDK1.8相较于1.7对HashMap做了很大的优化,比如加入了新数据结构红黑树、Hash算法的优化和扩容的优化。
本篇结合这些区别,探索HashMap的结构实现和功能原理。
存储结构-字段
从数据结构来看,HashMap是数组+链表+红黑树实现的,如图所示:
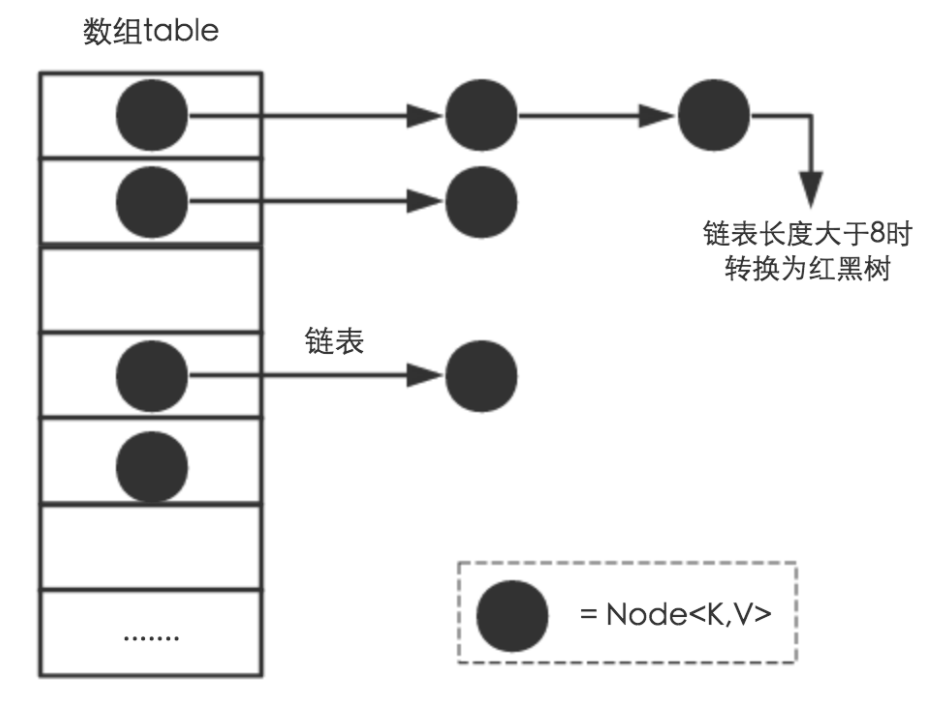
HashMap中重要的几个属性(JDK 1.8):
1 static final int MAXIMUM_CAPACITY = 1 << 30; // 所能容纳的Node极限数量 2 static final float DEFAULT_LOAD_FACTOR = 0.75f; // 负载因子 3 static final int TREEIFY_THRESHOLD = 8; // 当链表长度超过8时,将链表结构转为红黑树结构 4 static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // Node[] table的初始化长度length(默认值是16)
功能实现-方法
1.确定哈希桶数组索引位置
不管是增加、删除、查找键值对,定位到哈希桶数组的位置都是很关键的第一步。HashMap的数据结构是基于数组和链表(和红黑树),所以元素分布的越均匀,尽量使得每个位置上都只有一个元素(没有链表),那么我们用hash算法获取元素的时候,马上就可以得到,不需要遍历链表。HashMap定位索引位置,直接决定了hash方法的离散性能。下面看它是怎么做的:
static final int hash(Object key) { int h; // 第一步:h = key.hashCode() 取key的hashCode值 // 第二步:h ^ (h >>> 16) 高位参与运算 return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); } 对于任意给定的对象,key的hashCode()返回值是一定的不变的。 为什么用这个算法? key.hashCode()函数调用的是key键值类型自带的哈希函数,返回int型散列值。
Java中'&'与、'|'或、'^'异或、'<<'左移位、'>>'右移位
2.分析HashMap的put方法
1 public V put(K key, V value) { 2 return putVal(hash(key), key, value, false, true); 3 } 4 static final int hash(Object key) { 5 int h; 6 return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); 7 } 8 final V putVal(int hash, K key, V value, boolean onlyIfAbsent, 9 boolean evict) { 10 Node<K,V>[] tab; Node<K,V> p; int n, i; 11 // 判断数组table是否为空或为null,否则执行resize()进行扩容 12 if ((tab = table) == null || (n = tab.length) == 0) 13 n = (tab = resize()).length; 14 // 根据Key计算的hash值得到插入的数组索引i,如果tab[i]==null,直接新建节点,添加至数组上 15 if ((p = tab[i = (n - 1) & hash]) == null) 16 tab[i] = newNode(hash, key, value, null); 17 else { 18 Node<K,V> e; K k; 19 // 判断tab[i]的首个元素是否和要取的key一样,如果相同直接覆盖value 20 if (p.hash == hash && 21 ((k = p.key) == key || (key != null && key.equals(k)))) 22 e = p; 23 // 判断tab[i]是否为TreeNode,即是否为红黑树,如果是,在树中处理 24 else if (p instanceof TreeNode) 25 e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); 26 // 否则,遍历tab[i]上的链表 27 else { 28 for (int binCount = 0; ; ++binCount) { 29 // 如果链表的长度大于8,那么将链表转红黑树,在红黑树中执行插入操作 30 if ((e = p.next) == null) { 31 p.next = newNode(hash, key, value, null); 32 if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st 33 treeifyBin(tab, hash); 34 break; 35 } 36 // 如果发现链表中有相同的key(hash相同、key值也相同) 37 if (e.hash == hash && 38 ((k = e.key) == key || (key != null && key.equals(k)))) 39 break; 40 p = e; 41 } 42 } 43 44 if (e != null) { // existing mapping for key 45 V oldValue = e.value; 46 if (!onlyIfAbsent || oldValue == null) 47 e.value = value; 48 afterNodeAccess(e); 49 return oldValue; 50 } 51 } 52 // 超过最大容量,就进行扩容 53 ++modCount; 54 if (++size > threshold) 55 resize(); 56 afterNodeInsertion(evict); 57 return null; 58 }
① 判断键值对数组table[i]是否为空或为null,否则执行resize()进行扩容;
② 根据键值key计算hash值得到插入的数组索引i,如果table[i]==null,直接新建节点添加,转向⑥,如果table[i]不为空,转向③;
③ 判断table[i]的首个元素是否和key一样,如果相同直接覆盖value,否则转向④,这里的相同指的是hashCode以及equals;
④ 判断table[i] 是否为treeNode,即table[i] 是否是红黑树,如果是红黑树,则直接在树中插入键值对,否则转向⑤;
⑤ 遍历table[i],判断链表长度是否大于8,大于8的话把链表转换为红黑树,在红黑树中执行插入操作,否则进行链表的插入操作;遍历过程中若发现key已经存在直接覆盖value即可;
⑥ 插入成功后,判断实际存在的键值对数量size是否超多了最大容量threshold,如果超过,进行扩容。