1、发现问题
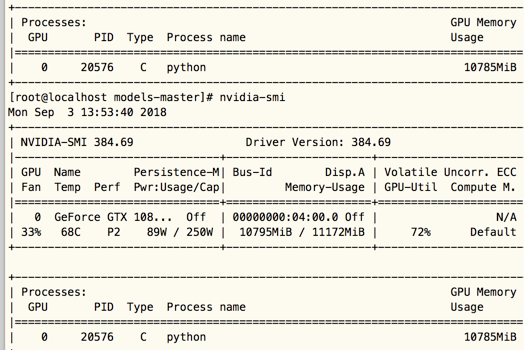
目前模型训练一次需要11秒左右,怀疑GPU没有成功调用

查看GPU是否成功调用,nvidia-smi,nvidia-smi 命令解读
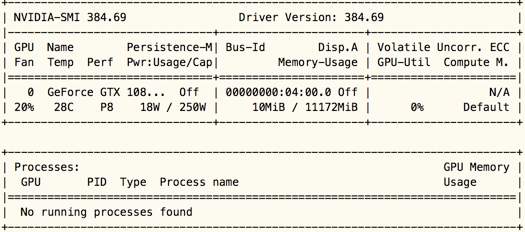
发现没有相关GPU的进程在跑,GPU没有被调用,什么问题?需要去查找下原因,首先想到的是我们的tensorflow版本是否是GPU版本的。
2、查看tensorflow版本
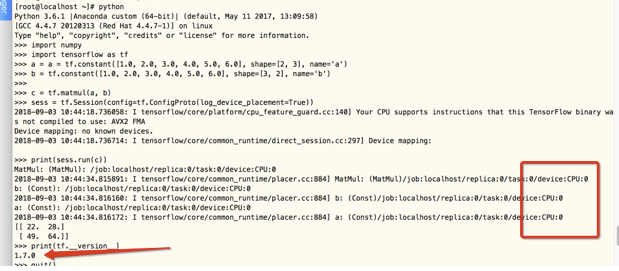
显示默认调用的是CPU,然后tensorflow版本为1.7.0,在查阅的时候发现调用GPU还和cuda 和 cudnn有关

先来查看下我们的cuda版本
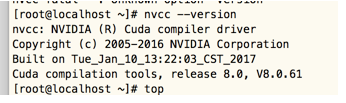
版本为8.0,看看是否和我们的tensorflow版本有冲突,参考:TensorFlow GPU 版本总结

显示1.5版本以上,需cuda 9.0版本,而我们的tensorflow版本为1.7,理论上是需要cuda 9.0以上的版本,现在有两个思路:
1、升级cuda版本;
2、降级tensorflow版本。
网上初略查了下,升级cuda可能遇到的问题会比较多,下面我们采用第2种思路
3、降级tensorflow版本到1.4
pip install tensorflow-gpu==1.4.0
测试跑的是GPU还是CPU
import numpy
import tensorflow as tf
a = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[2, 3], name='a')
b = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[3, 2], name='b')
c = tf.matmul(a, b)
sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))
print(sess.run(c))
之后就会出现详细的信息:

然后设置train.py里面的文件,不同模块找不同模块的train.py文件,在object_detection模块修改一下内容:

修改为False即可,在运行模块,可以发现速度快了很多
服务器终端输入:nvidia-smi,发现已经有相关GPU的进程在跑