redis源码分析之内存布局
1. 介绍
众所周知,redis是一个开源、短小、高效的key-value存储系统,相对于memcached,redis能够支持更加丰富的数据结构,包括:
- 字符串(string)
- 哈希表(map)
- 列表(list)
- 集合(set)
- 有序集(zset)
主流的key-value存储系统,都是在系统内部维护一个hash表,因为对hash表的操作时间复杂度为O(1)。如果数据增加以后,导致冲突严重,时间复杂度增加,则可以对hash表进行rehash,以此来保证操作的常量时间复杂度。
那么,对于这样一个基于hash表的key-value存储系统,是如何提供这么丰富的数据结构的呢?这些数据结构在内存中如何存储呢?这篇文章将用大量的图片演示redis的内存布局和数据存储。
2. redisServer
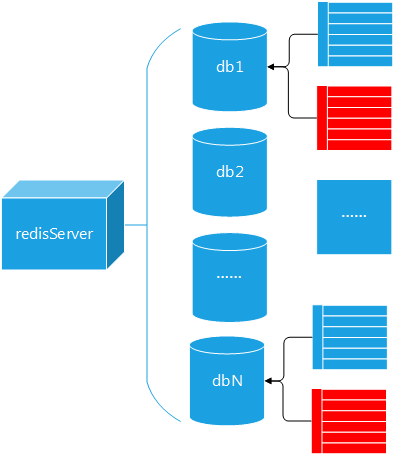
在redis系统内部,有一个redisServer结构体的全局变量server,server保存了redis服务端所有的信息,包括当前进程的PID、服务器的端口号、数据库个数、统计信息等等。当然,它也包含了数据库信息,包括数据库的个数、以及一个redisDb数组。
struct redisServer {
……
redisDb *db;
int dbnum; /* Total number of configured DBs */
……
}显然,dbnum就是redisDb数组的长度,每一个数据库,都对应于一个redisDb,在redis的客户端中,可以通过select N来选择使用哪一个数据库,各个数据库之间互相独立。例如:可以在不同的数据库中同时存在名为”redis”的key。

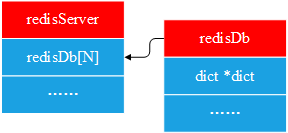
从上面的分析中可以看到,server是一个全局变量,它包含了若干个redisDb,每一个redisDb是一个keyspace,各个keyspace互相独立,互不干扰。
下面来看一下redisDb的定义:
/* Redis database representation. There are multiple databases identified
* by integers from 0 (the default database) up to the max configured
* database. The database number is the 'id' field in the structure. */
typedef struct redisDb {
dict *dict; /* The keyspace for this DB */
dict *expires; /* Timeout of keys with a timeout set */
dict *blocking_keys; /* Keys with clients waiting for data (BLPOP) */
dict *ready_keys; /* Blocked keys that received a PUSH */
dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS */
struct evictionPoolEntry *eviction_pool; /* Eviction pool of keys */
int id; /* Database ID */
long long avg_ttl; /* Average TTL, just for stats */
} redisDb;redis的每一个数据库是一个独立的keyspace,因此,我们理所当然的认为,redis的数据库是一个hash表。但是,从redisDb的定义来看,它并不是一个hash表,而是一个包含了很多hash表的结构。之所以这样做,是因为redis还需要提供除了set、get以外更加丰富的功能(例如:键的超时机制)。我们今天只关注最重要的数据结构:
typedef struct redisDb {
dict *dict; /* The keyspace for this DB */
……
} redisDb;redisDb与redisServer的关系如下所示:
下面再看dict的定义:
typedef struct dict {
……
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
……
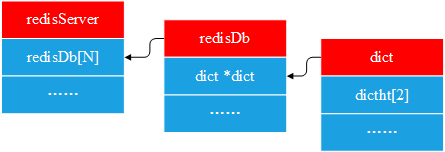
} dict;dict包含了两个hash表,这样做的目的是为了支持渐进式的rehash,即:在大多数情况下,只使用第一个hash表,如果第一个hash表的数据太多,则需要执行rehash。
dict与redisDb、redisServer的关系如下:
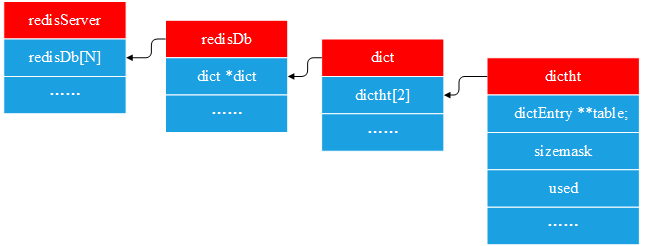
下面看一下dictht的定义,至此,我们总算见到了redis的hash表,与绝大多数的hash表没有什么两样:
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;dictht与dict、redisDb、redisServer之间的关系如下:
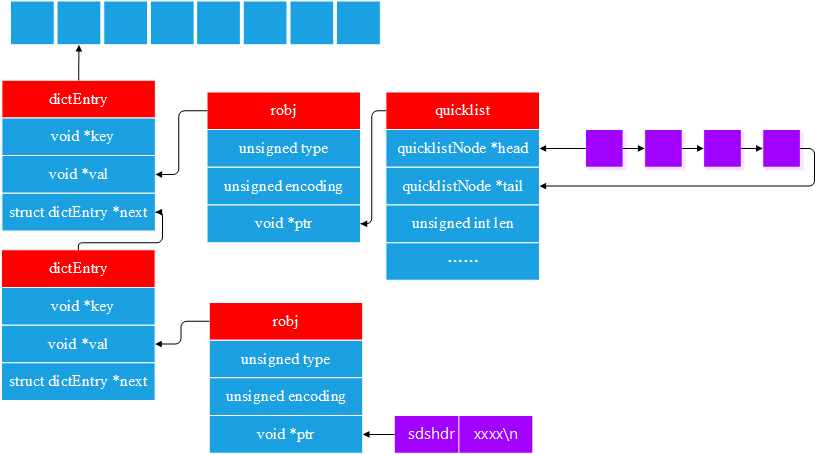
redis对hash表的节点也进行了简单的封装,hash表的每一个节点都是一个dictEntry,redis的hash表看起来是这样:
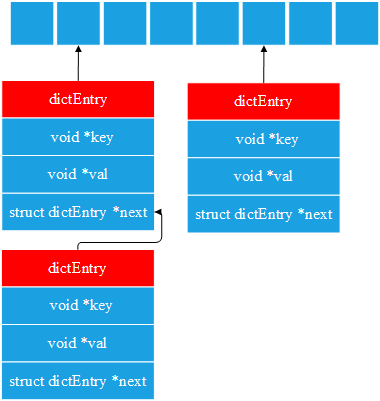
总结: redis内存有一个全局变量redisServer server,该变量包含若干个数据库,每个数据库都用一个redisDb表示,redisDb包含若干个字典,其中,存储数据的是dict* dict,dict内部包含两个hash表,一般情况下面,我们只会使用ht[0],在rehash时,我们会同时使用两个hash表,hash表的每一项,都是一个dictEntry结构体的变量。
从宏观角度来看,redis的数据存储应该是这样的:
3. 存储不同的数据类型
在上一节中,详细介绍了redis的hash表以及核心数据结构之间的关系,至此,以及对redis存储数据有了一个初步的印象,但是,到目前为止还没有回答文章最开始的问题:redis如何存储不同的数据结构?
要理解redis如何存储不同的数据结构,首先来看一下redisObject的定义:
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:REDIS_LRU_BITS; /* lru time (relative to server.lruclock) */
int refcount;
void *ptr;
} robj;其中,type是逻辑数据类型,即redis提供给用户的字符串、列表、hash表等。type的取值如下:
/* Object types */
#define REDIS_STRING 0
#define REDIS_LIST 1
#define REDIS_SET 2
#define REDIS_ZSET 3
#define REDIS_HASH 4type虽然很关键,但是,在我们这篇文章中,更多的需要关注encoding字段,该字段的含义是逻辑数据类型的具体实现。encoding的取值如下:
#define REDIS_ENCODING_RAW 0 /* Raw representation */
#define REDIS_ENCODING_INT 1 /* Encoded as integer */
#define REDIS_ENCODING_HT 2 /* Encoded as hash table */
#define REDIS_ENCODING_ZIPMAP 3 /* Encoded as zipmap */
#define REDIS_ENCODING_LINKEDLIST 4 /* Encoded as regular linked list */
#define REDIS_ENCODING_ZIPLIST 5 /* Encoded as ziplist */
#define REDIS_ENCODING_INTSET 6 /* Encoded as intset */
#define REDIS_ENCODING_SKIPLIST 7 /* Encoded as skiplist */
#define REDIS_ENCODING_EMBSTR 8 /* Embedded sds string encoding */
#define REDIS_ENCODING_QUICKLIST 9 /* Encoded as linked list of ziplists */例如,对于list这种数据类型,在redis内部,可以使用ziplist实现(更加省内存),也可以使用linkedlist实现。
在满足以下两个条件时,使用ziplist实现,否则,使用linkedlist实现。
- 列表对象保存的所有字符串元素的长度都小于64字节
- 列表对象保存的元素数量小于512
再次强调:对于同一种数据类型,redis内部提供了多种实现,不同的实现适用于不同的场景,且用户只能通过redis.conf文件进行有限的控制,具体使用哪一种实现,完全是redis内部决定。可以通过object encoding key查看当前key的内部编码,即内部实现。
这篇文章介绍redis的内存布局,自然更应该关系的是内部的具体实现,而不是逻辑数据类型。不管是逻辑类型(type)还是具体实现(encoding),都保存在redisObject中,redisObject相当于是所有数据结构的父类,redis的hash表的每一个项都是dictEntry,而每一个dictEntry,都指向一个redisObject。
redis在数据的存取时,首先通过key找到对应的dictEntry,接着通过dictEntry获取redisObject对象,然后通过redisObject的encoding的取值,对redisObject的ptr指针进行强制类型转换。
例如: 对于一个简短的list,redis很有可能使用的是quicklist存储,因此,在读取list的数据时,redis首先通过key找到dictEntry,然后通过dictEntry找到redisObject, 通过redisObject的encoding对ptr指针进行强制类型转换,在本例中,将ptr强制转换为quicklist,转换为quicklist以后,就能够获取head和tail指针,可以使用head和tail访问数据。