大端模式与小端模式
大端模式(Big Endian):
基本数据类型(主要是short、int、double)的变量采用高字节(BYTE)和高字(WORD)在低地址存放,低字节和低字在高地址存放,并把最高字节地址作为变量的首地址。
自然对齐
就是基本数据类型(主要是short、int、double)的变量不能简单地存储于内存中的任意地址处,它们的起始地址必须能够被它们的大小整除。
例如:
在32位平台下,int和指针类型变量的地址应能被4整除,而short变量的地址都应该是偶数,bool和char没有特别要求。
例如:short类型变量x和int类型变量y的内存布局及其首地址如图:

小端模式(Little Endian)
基本类型变量按照低字节和低字在低地址存放,高字节和高字在高地址存放(即低字节、低字在前,或地址小的字节结尾),并且把最低字节的地址做为变量的首地址。
例如:short类型变量x和int类型变量y的内存布局及其首地址如图:

复合类型的成员对齐
对于复合类型(一般指结构和类)的对象,如果它的起始地址能够满足其中“要求最严格(或最高)”的那个数据成员的自然对齐要求,那么它就是自然对齐的;如果那个数据成员又是一个复合类型的对象,则依次类推,直到最后都是基本类型的数据成员。
自然对齐要求最严格:
举例最直观:
double变量的地址要能够被8整除,而int变量的地址只需要被4整除即可,一个bool变量的地址则只需要被1整除。所以double类型的自然对齐要求要比int类型严格,int类型的对齐要求又比bool类型严格。
在C++/C的基本数据类型中,如果不考虑enum可能的最大值所需的内存字节数,double就是对齐要求最严格的类型了,其实是int和float,然后是short、bool、char。
typedef unsighed char BYTE;
enum Color {RED = 0x01, BLUE, GREEN, YELLOW, BLACK};
struct Sedan //私家车
{
bool m_hasSkylight; //是否有天窗
Color m_color; //颜色
bool m_isAutoShift; //是否自动挡
double m_price; //价格(元)
BYTE m_seatNum; //座位数量
};
以上面结构体Sedan为例,其在内存中布局如下:
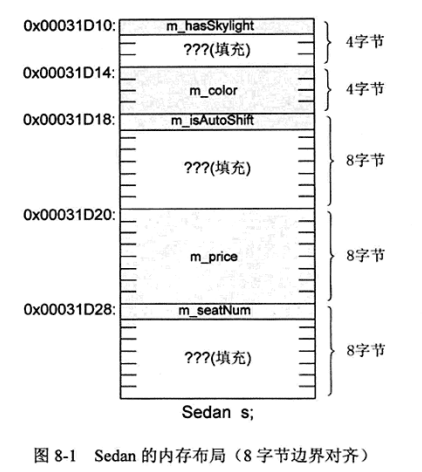
根据上面对“自然对齐要求最严格”的描述,解释上图中Sedan的内存布局:
1、m_price 是double类型的,在这个结构体中要求最严格,所以Sedan的对象地址应该能被8整除。m_price 的偏移量还必须是8的倍数才能确保也总是自然对齐的,在此偏移量8肯定不能满足要求,因为前面有三个变量需要布局,所以这里应该偏移16个字节。
2、其他成员的起始地址也需要满足个自己的自然对齐要求。
3、上图中???(填充)标记是表示为了满足各个成员的对齐要求,各个成员之间甚至对象的末尾可能会插入一定量的填充字节。
4、对象的末尾会插入一定量的填充字符(这里是m_seatNum),是因为编译器在考虑一个类型的大小的时候,不仅要考虑一个对象的对齐要求,还要考虑该类型对象数组的对齐要求,这样才能保证用户在使用对象数组时也具有和单个对象一样的访问效率。假如 这里不补齐,砍掉这7个字节,Sedan的对象大小就是25,因数组的每个元素都是连续的,Sedan数组除了第一个元素是自然对齐的,后面的元素地址都不能被8整除,就有可能无法自然对齐,会影响数组的访问效率。
可以通过以下几个结构体来分析以下它们的内存布局。

自定义成员对齐方式
在MS C++/C 开发环境中,可以使用#pragma 编译指令为复合类型显示指定其成员的对齐方式。可用的对齐方式有1、2、4、8、16。
#ifdef _MSC_VER
#pragma pack(push,8)
//按照8字节边界对齐
#endif
struct Sedan //私家车
{
bool m_hasSkylight; //是否有天窗
Color m_color; //颜色
bool m_isAutoShift; //是否自动挡
double m_price; //价格(元)
BYTE m_seatNum; //座位数量
};
#ifdef _MSC_VER
#pragma pack(pop)
#endif
//****************************************
#ifdef _MSC_VER
#pragma pack(push,4)
//按照4字节边界对齐
#endif
struct Sedan //私家车
{
bool m_hasSkylight; //是否有天窗
Color m_color; //颜色
bool m_isAutoShift; //是否自动挡
double m_price; //价格(元)
BYTE m_seatNum; //座位数量
};
#ifdef _MSC_VER
#pragma pack(pop)
#endif
按照 4 字节对齐的时候内存布局如下:
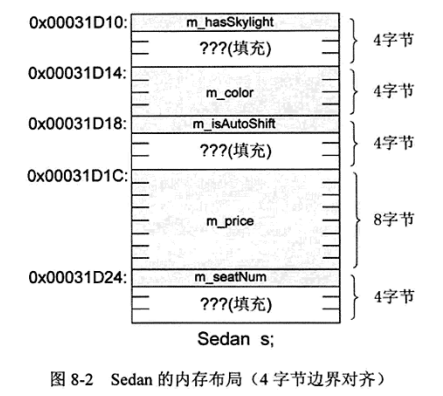
从上图可见,采用 4 字节边界对齐后,Sedan对象的起始地址能够被8整除,但m_price的地址(0x00031D1C)不能被 8 整除。
也可以直接更改IDE的设置,默认是8字节,如下图:

内存优化
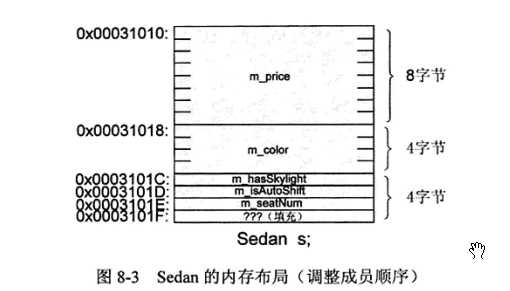
从上面可以看出,如果完全满足Sedan的自然对齐要求,那么将会非常占用内存,优化的方式也非常简单.
按照从大到小的顺序从前到后依次声明每一个数据成员,并且尽量使用较小的成员对齐方式。
还是以Sedan为例。
#ifdef _MSC_VER
#pragma pack(push,8)
//按照8字节边界对齐
#endif
struct Sedan //私家车
{
double m_price; //价格(元)
Color m_color; //颜色
bool m_hasSkylight; //是否有天窗
bool m_isAutoShift; //是否自动挡
BYTE m_seatNum; //座位数量
};
#ifdef _MSC_VER
#pragma pack(pop)
#endif
调整之后Sedan的内存布局如下:
计算复合类型每个数据成员的偏移字节数
方法1:使用offsetof宏
该宏专门用来计算数据成员相对于对象起始地址的真实偏移量 ,它会把所有隐含成员也算进去,比如虚函数表指针vptr。具体可参考MSDN。
std::out<<"offsetof(Sedan,m_hasSkylight)="<<offsetof(Sedan,m_hasSkylight); std::out<<"offsetof(Sedan,m_color)="<<offsetof(Sedan,m_color); std::out<<"offsetof(Sedan,m_isAutoShift)="<<offsetof(Sedan,m_isAutoShift); std::out<<"offsetof(Sedan,m_price)="<<offsetof(Sedan,m_price); std::out<<"offsetof(Sedan,m_seatNum)="<<offsetof(Sedan,m_seatNum);
方法2:随便定义一个对象,依次打印出对象的起始地址及其每一个成员的地址,据此可以计算出每个成员的偏移量,或者直接将两个地址相减。
例如:
Sedan s; std::out<<"Address of s ="<<(void*)&s; std::out<<"offset of m_hasSkylight ="<<((char*)&s.m_hasSkylight - (char*)&s); std::out<<"offset of m_color ="<<((char*)&s.m_color - (char*)&s); std::out<<"offset of m_isAutoShift ="<<((char*)&s.m_isAutoShift - (char*)&s); std::out<<"offset of m_price ="<<((char*)&s.m_price - (char*)&s); std::out<<"offset of m_seatNum ="<<((char*)&s.m_seatNum - (char*)&s);
在一个多模块的应用程序中,可能包含一个可执行程序,若干个静态链接库,若干个动态链接库。不管是静态库还是动态库,一般来说,模块之间除了函数接口外,还会有一些共享的复合数据类型定义,它们也是模块接口的一部分。如果使用不同的对齐方式,这些接口数据的对象在内存中很可能具有不同的布局,某些成员的偏移会发生变化。如果不同模块恰好使用了不同的对齐方式,而模块间共享的复合数据类型没有显示地指定对齐方式,那么程序出错的风险就会增加。
具体的示例见书本《高质量程序设计指南》 P156.
COM要求不得在接口中定义数据成员,其原因之一就是这可能导致不同模块使用不同编译器而出现二进制不兼容。
联合(Union)
联合中不同数据类型之间可以共享内存,同时可以实现不同类型数据成员之间的自动类型转换。联合在同一时间只能存储一个成员的值。
联合的内存大小取决于其中字节数最多的成员,而不是累加,联合也会进行字长对齐。
联合可用来解析一个寄存器或多字节内存变量的高低字节的值,而不需要我们手工使用位运算符来解析它们。
比如:
联合类型KeyCode就可以用来自动获取按键编码的高低字节,当你用键盘敲入一个字符的时候,计算机内部把它转换为一个双字节的整数编码,其中byteArr[1]存放的是高字节的值,而byteArr[0]存放的就是低字节的值。一般的ASCII码就保存在低字节中,而键盘扩展码存在高字节中。
关于联合做为类型自动转换的工具,可参考MFC应用框架中的消息映射表的设计。MFC 消息映射、分派和传递
C++类的内存映像
1、普通的类:
class Rectangle
{
public:
Rectangle():m_length(1),m_width(1) {...}
~Rectangle(){...}
float GetLength() const {return m_length;}
void SetLength(float length) {m_length = length;}
float GetWidth() const {return m_width;}
void Draw() {...}
static unsigned int GetCount() {return m_count;}
protected:
Rectangle(const Rectangle& copy){...}
Rectangle& operator=(const Rectangle& assign){...}
private:
float m_length ; //长
float m_width ; //宽
static unsigned int m_count; //对象计数
}
上面Rectangle类对象在内存中映像如下:
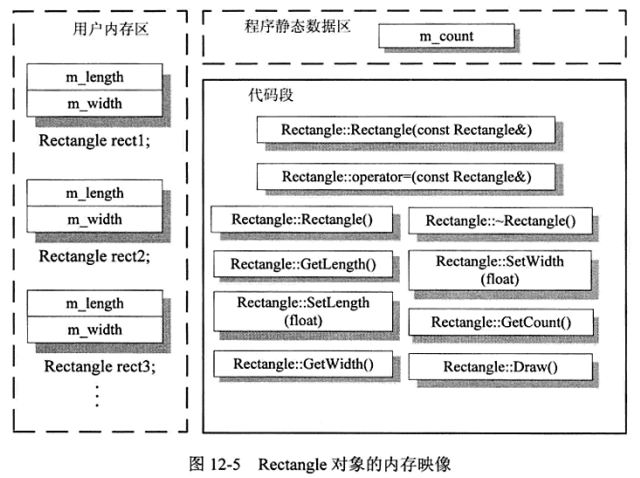
通过上图可以看出,Rectangle这种基本的C++对象模型有下述几个原则:
- 非静态数据成员被放在每一个对象体内做为对象专有的数据成员。
- 静态数据成员被提取出来放在程序的静态数据区域内为该类所有对象共享,因此仅存一份。
- 静态和非静态成员函数最终都在被提取出来放在程序的代码段中并为该类的所有对象共享,因此没一个成员函数也只存在一份代码实体;
- 类内嵌套定义的各种类型(typedef, class, struct, union, enum等)与放在类外面定义的类型除了作用域不同外没有本质区别
因此,构成对象本身的只有数据,任何成员函数都不隶属于任何一个对象,非静态成员函数与对象的关系就是绑定,绑定的中介就是this指针。
2、有派生关系及虚函数
class Shape
{
public:
Shape():m_color(){}
virtual ~Shape(){}
float GetColor() const {return m_color;}
void SetColor(float color) {m_color = color;}
virtual void Draw() = 0;
private:
float m_color;//颜色
};
class Rectangle:public Shape
{
public:
.......
private:
.......
};
增加了继承和虚函数的类的对象模型变得更加复杂,规则如下:
- 派生类继承基类的非静态数据成员,并作为自己对象的专用数据成员。
- 派生类继承基类的非静态成员函数并可以像自己的成员函数一样访问。
- 为每一个多态类创建一个虚函数指针数组vtable,该类的所有虚函数(继承自基类或者新增的)的地址都保存在这张表里。
- 多态类的每一个对象(如果有)中安插一个指针成员vptr,其类型为指向函数指针的指针,它总是指向所属类的vtable,也就是说:vptr当前所在的对象是什么类型的,那么它就指向这个类型的vtable。vptr是C++对象的隐含数据成员之一(实际上它被安插在多态类的定义中)。
- 如果基类已经插入了vptr,则派生类将继承和重用该vptr。
- 如果派生类是从多个基类继承或者有多个继承分支(从所有根类开始算起),而其中若干个继承分支上出现了多态类,则派生类将从这些分支中的每个分支上继承一个vptr,编译器也 将为它生成多个vtable,有几个vptr就生成几个vtable(每个vptr分别指向其中一个),分别与它的多态基类对应。
- vptr在派生类对象中的相对位置不会随着继承层次的逐渐加深而改变,并且现在的编译器一般都讲vptr放在所有数据成员的最前面;
- 为了支持RTTI,为每一个多态类创建一个type_info对象,并把其地址保存在vtable中固定的位置(一般为第一个位置)(这一条取决于具体编译器的实现技术,标准并没有规定).
现在的Rectangle的对象模型如下:
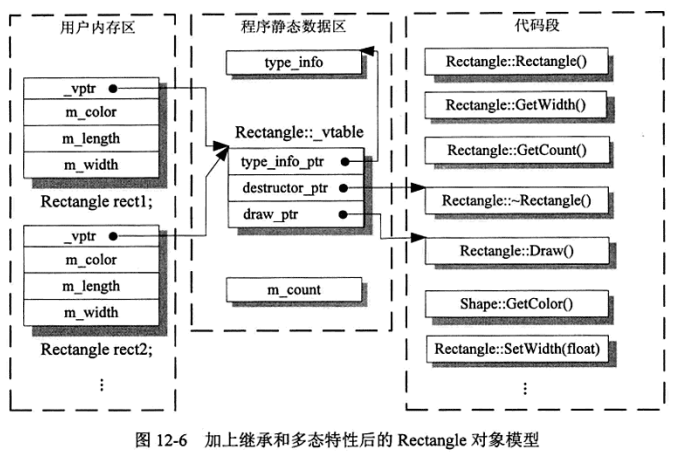
该模型有以下特点:
- 从一个派生类对象入手,可以直接访问到基类的数据成员,因为基类的数据成员被直接嵌入到了派生类对象中(保持基类子对象的完整性)
- 不论派生层次有多深,派生类对象访问基类对象的数据成员和成员函数时,与访问自己的数据成员和成员函数没有任何效率差异
- 由于派生类数据成员和基类数据成员的这种好难过紧密关系,当基类定义发生改变时(例如增加或删除成员时)派生类必须重新编译才能正确使用
- 派生类新增数据成员和继承来的基类数据成员按照对象的构造顺序来组合,并且每层拍摄的新增数据成员要么统一放在基类子对象的前面,要么统一放在后面
- 只有虚函数访问需要经过vptr的间接寻址,增加了一层间接性,因此带来了一些额外的运行时开销