今天有一个朋友发短消息问我说“老师,为什么PE的格式要讲的这么这么细,这可不是一般的系哦”。其实之所以将PE结构放在解密系列继基础篇之后讲并且尽可能细致的讲,不是因为小甲鱼没事找事做,主要原因是因为PE结构非常重要,再说做这个课件的确是很费神的事哈。在这里再次强调一下,只要是windows操作程序,其就要遵循PE格式,再说人家看雪的网址就是www.pediy.com。
简单的讲是可以,但是怕就怕有些朋友知识点遗漏了或者错误理解意思、不能深刻体会等,这样的效果是不好的~所以,小甲鱼尽管这系列视频可能出得比较慢,但 质量一定保证大家都能够接受。建议:如果认为PE不重要,没关系,可以先学其他。小甲鱼的文章永远放在这里,等你需要的时候再回过头来看就行。
小甲鱼PE详解之基址重定位详解(PE详解10)
这一节对于讲来研究病毒原理的研究影响比较大,大家务必要深入理解~
但是吧,咱的权威教材看雪的《加密与解密》在这一节的讲解上实在不给力,很多初学者看得云里雾里的。大家意见一致啵 ?!
为了让大家能够更容易的接受,小甲鱼决定通过自问 - 自答循环渐进的模式给大家讲解基址重定位的原理和应用。
问题一:什么是基址重定位?
答:重定位就是你本来这个程序理论上要占据这个地 址,但是由于某种原因,这个地址现在不能让你霸占,你必须转移到别的地址,这就需要基址重定位。打个比方:例如你现在计划在某某地方建一栋楼,但是有一天 你收到上边的通知,这个地方政府临时要征用建公厕,所以这时候你就没辙,得去别的地方建啦~
问题二:为什么需要基址重定位?
答:其实这个问题看起来跟前边的有点重复不是? 但是有些朋友可能会这么说,小甲鱼老湿你的言论是可以,但是放在程序中,小甲鱼你上节课不是还说每个程序都让Windows 欺骗了吗 —— 每个程序觉得自己都完全占有 4GB的内存空间,何来地址被别的程序占据了呢?!
首先,能够提出问题的朋友都是值得表扬和鼓励的
但是,上节课我们谈了什么内容呢 ? 谈了导出表,为什么会出现导出表呢 ? 正是因为有DLL 这类破坏别人家庭幸福的“小三”的存在~
我们之前谈过,动态链接库它自己是没有占据任何似有空间的,都是寄生在应用程序的私有空间里边。那寄生在别人家里,睡在哪里就肯定不是小三说了算啦,肯定要由主人决定不是? 所以,在小三的眼里,不用说,肯定永远都睡在大房,但客观事实告诉我们,经常只能住卧室~(有点扯远了,其实小甲鱼想说的是,基址重定位就是这么被需求的^_^)
问题三:我们需要对程序中的哪些语句(指令)进行基址重定位呢?
答:请先看下图
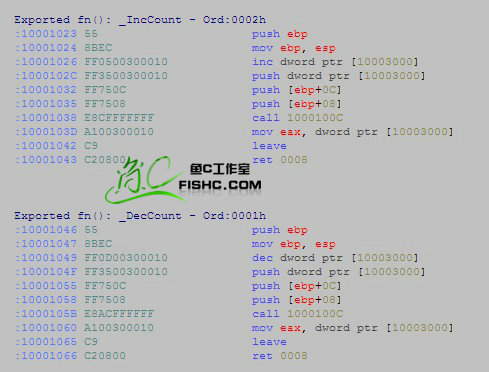
这 是上节课我们用到的动态链接库 Counter.dll 文件,对其用W32Dasm 进行反汇编的截图。我们分析下,有哪些语句是需要我们来进行基址重定位的呢 ?(温馨提示:以下内容涉及一些汇编基础和windows基础,不懂的朋友可以参照视频教程。因为一般说话比打字容易,信息量也比较大~)
答案是——但凡涉及到直接寻址的指令都需要进行重定位处理!(那什么是直接寻址? 咱在零基础入门学习汇编里边讲得很清楚啦,只要在机器码中看到有地址的,那就叫直接寻址……那有没有间接的? 肯定哈,间接的就是地址被间接的保存起来,例如存放在寄存器eax, 然后通过访问寄存器来获取地址,那就叫间接~)
那么我们再过头来看下图片,一眼就能扫出以下指令需要对其进行重定位:
:10001026 FF0500300010 inc dword ptr [10003000]
:1000102C FF3500300010 push dword ptr [10003000]
:1000103D A100300010 mov eax, dword ptr [10003000]
:10001049 FF0D00300010 dec dword ptr [10003000]
:1000104F FF3500300010 push dword ptr [10003000]
:10001060 A100300010 mov eax, dword ptr [10003000]
:1000106A FF2500200010 Jmp dword ptr [10002000]
那有些朋友可能会问了,类似于“:10001038 E8CFFFFFFF call 1000100C” 的指令,为什么后边显示的是call + 地址,而机器码却不包含地址信息呢? CPU神了? 莫非地址信息被加密了? 其实不是的,学过汇编的朋友不知道还记不记得,小甲鱼在讲call 原理的时候用了大部分时间在谈几种跳转,其中经常遇到的就是“地址+偏移”的形式。那这就能有个说得通的解释了:CFFFFFFFh 事实上就是一个偏移地址,记得咱这是little-edition,转换过来就是FFFF FFCFh,也就是等于-31h。那么1000103Dh - 31h == 1000100Ch,Perfect! ^_^
问题四:系统对一条指令进行重定位需要哪些信息?
答:我们还是拿上边那张图片来说事儿,我们说了上边的那些指令需要重定位,现在就假设重定位后的基地址由原来的10000000h 变为 20000000h了,那么类似这样的语句:inc dword ptr [10003000] 应该改成 inc dword ptr [20003000] 。
注意,重定位的算法我们可以总结为:将直接寻址指令中的双字地址加上模块的实际装入地址与模块建议装入地址之差。
从上边的信息中我们看到,需要进行重定位需要三个因素:
1. 需要修正的地址(10003000h)
2. 建议装入的地址(10003000h)
3. 实际装入的地址(20003000h)
问题五:这些信息哪些应该被保存在重定位表中?
聪明的我们可以发现:
1. 建议装入的地址在PE 文件头中已经定义了
2. 实际装入的地址在没有被装载器装入我们根本无从得知,也就是说这事天不知地不知我们不知只有装载器知道……
因此,我们可以得到的结论是:PE 文件的重定位表(Base Relocation Table)中保存的就是文件中所有需要进行重定位修正的代码的地址。
基址重定位结构表
IMAGE_BASE_RELOCATION STRUC
IMAGE_BASE_RELOCATION ENDS
VirtualAddress 是 Base Relocation Table 的位置它是一个 RVA 值;
SizeOfBlock 是 Base Relocation Table 的大小;
TypeOffset 是一个数组,数组每项大小为两个字节(16位),它由高 4位和低 12位组成,高 4位代表重定位类型,低 12位是重定位地址,它与 VirtualAddress 相加即是指向PE 映像中需要修改的那个代码的地址。
IMAGE_REL_BASED_ABSOLUTE (0) 使块按照32位对齐,位置为0。
IMAGE_REL_BASED_HIGH (1) 高16位必须应用于偏移量所指高字16位。
IMAGE_REL_BASED_LOW (2) 低16位必须应用于偏移量所指低字16位。
IMAGE_REL_BASED_HIGHLOW (3) 全部32位应用于所有32位。
IMAGE_REL_BASED_HIGHADJ (4) 需要32位,高16位位于偏移量,低16位位于下一个偏移量数组元素,组合为一个带符号数,加上32位的一个数,然后加上8000然后把高16位保存在偏移量的16位域内。
IMAGE_REL_BASED_MIPS_JMPADDR (5) Unknown
IMAGE_REL_BASED_SECTION (6) Unknown
IMAGE_REL_BASED_REL32 (7) Unknown
输出表结构实例分析(具体过程将在视频中演示,这里不啰嗦啦~)
工具:PEinfo.exe, UltraEdit, W32DasmV10.0
解剖对象:Counter.dll
简单的讲是可以,但是怕就怕有些朋友知识点遗漏了或者错误理解意思、不能深刻体会等,这样的效果是不好的~所以,小甲鱼尽管这系列视频可能出得比较慢,但 质量一定保证大家都能够接受。建议:如果认为PE不重要,没关系,可以先学其他。小甲鱼的文章永远放在这里,等你需要的时候再回过头来看就行。
小甲鱼PE详解之基址重定位详解(PE详解10)
这一节对于讲来研究病毒原理的研究影响比较大,大家务必要深入理解~
但是吧,咱的权威教材看雪的《加密与解密》在这一节的讲解上实在不给力,很多初学者看得云里雾里的。大家意见一致啵 ?!
为了让大家能够更容易的接受,小甲鱼决定通过自问 - 自答循环渐进的模式给大家讲解基址重定位的原理和应用。
问题一:什么是基址重定位?
答:重定位就是你本来这个程序理论上要占据这个地 址,但是由于某种原因,这个地址现在不能让你霸占,你必须转移到别的地址,这就需要基址重定位。打个比方:例如你现在计划在某某地方建一栋楼,但是有一天 你收到上边的通知,这个地方政府临时要征用建公厕,所以这时候你就没辙,得去别的地方建啦~
问题二:为什么需要基址重定位?
答:其实这个问题看起来跟前边的有点重复不是? 但是有些朋友可能会这么说,小甲鱼老湿你的言论是可以,但是放在程序中,小甲鱼你上节课不是还说每个程序都让Windows 欺骗了吗 —— 每个程序觉得自己都完全占有 4GB的内存空间,何来地址被别的程序占据了呢?!
首先,能够提出问题的朋友都是值得表扬和鼓励的
但是,上节课我们谈了什么内容呢 ? 谈了导出表,为什么会出现导出表呢 ? 正是因为有DLL 这类破坏别人家庭幸福的“小三”的存在~
我们之前谈过,动态链接库它自己是没有占据任何似有空间的,都是寄生在应用程序的私有空间里边。那寄生在别人家里,睡在哪里就肯定不是小三说了算啦,肯定要由主人决定不是? 所以,在小三的眼里,不用说,肯定永远都睡在大房,但客观事实告诉我们,经常只能住卧室~(有点扯远了,其实小甲鱼想说的是,基址重定位就是这么被需求的^_^)
问题三:我们需要对程序中的哪些语句(指令)进行基址重定位呢?
答:请先看下图
这 是上节课我们用到的动态链接库 Counter.dll 文件,对其用W32Dasm 进行反汇编的截图。我们分析下,有哪些语句是需要我们来进行基址重定位的呢 ?(温馨提示:以下内容涉及一些汇编基础和windows基础,不懂的朋友可以参照视频教程。因为一般说话比打字容易,信息量也比较大~)
答案是——但凡涉及到直接寻址的指令都需要进行重定位处理!(那什么是直接寻址? 咱在零基础入门学习汇编里边讲得很清楚啦,只要在机器码中看到有地址的,那就叫直接寻址……那有没有间接的? 肯定哈,间接的就是地址被间接的保存起来,例如存放在寄存器eax, 然后通过访问寄存器来获取地址,那就叫间接~)
那么我们再过头来看下图片,一眼就能扫出以下指令需要对其进行重定位:
:10001026 FF0500300010 inc dword ptr [10003000]
:1000102C FF3500300010 push dword ptr [10003000]
:1000103D A100300010 mov eax, dword ptr [10003000]
:10001049 FF0D00300010 dec dword ptr [10003000]
:1000104F FF3500300010 push dword ptr [10003000]
:10001060 A100300010 mov eax, dword ptr [10003000]
:1000106A FF2500200010 Jmp dword ptr [10002000]
那有些朋友可能会问了,类似于“:10001038 E8CFFFFFFF call 1000100C” 的指令,为什么后边显示的是call + 地址,而机器码却不包含地址信息呢? CPU神了? 莫非地址信息被加密了? 其实不是的,学过汇编的朋友不知道还记不记得,小甲鱼在讲call 原理的时候用了大部分时间在谈几种跳转,其中经常遇到的就是“地址+偏移”的形式。那这就能有个说得通的解释了:CFFFFFFFh 事实上就是一个偏移地址,记得咱这是little-edition,转换过来就是FFFF FFCFh,也就是等于-31h。那么1000103Dh - 31h == 1000100Ch,Perfect! ^_^
问题四:系统对一条指令进行重定位需要哪些信息?
答:我们还是拿上边那张图片来说事儿,我们说了上边的那些指令需要重定位,现在就假设重定位后的基地址由原来的10000000h 变为 20000000h了,那么类似这样的语句:inc dword ptr [10003000] 应该改成 inc dword ptr [20003000] 。
注意,重定位的算法我们可以总结为:将直接寻址指令中的双字地址加上模块的实际装入地址与模块建议装入地址之差。
从上边的信息中我们看到,需要进行重定位需要三个因素:
1. 需要修正的地址(10003000h)
2. 建议装入的地址(10003000h)
3. 实际装入的地址(20003000h)
问题五:这些信息哪些应该被保存在重定位表中?
聪明的我们可以发现:
1. 建议装入的地址在PE 文件头中已经定义了
2. 实际装入的地址在没有被装载器装入我们根本无从得知,也就是说这事天不知地不知我们不知只有装载器知道……
因此,我们可以得到的结论是:PE 文件的重定位表(Base Relocation Table)中保存的就是文件中所有需要进行重定位修正的代码的地址。
基址重定位结构表
IMAGE_BASE_RELOCATION STRUC
VirtualAddress DWORD ? ; 重定位数据开始的RVA 地址
SizeOfBlock DWORD ? ; 重定位块得长度
TypeOffset WORD ? ; 重定项位数组
SizeOfBlock DWORD ? ; 重定位块得长度
TypeOffset WORD ? ; 重定项位数组
IMAGE_BASE_RELOCATION ENDS
VirtualAddress 是 Base Relocation Table 的位置它是一个 RVA 值;
SizeOfBlock 是 Base Relocation Table 的大小;
TypeOffset 是一个数组,数组每项大小为两个字节(16位),它由高 4位和低 12位组成,高 4位代表重定位类型,低 12位是重定位地址,它与 VirtualAddress 相加即是指向PE 映像中需要修改的那个代码的地址。
IMAGE_REL_BASED_ABSOLUTE (0) 使块按照32位对齐,位置为0。
IMAGE_REL_BASED_HIGH (1) 高16位必须应用于偏移量所指高字16位。
IMAGE_REL_BASED_LOW (2) 低16位必须应用于偏移量所指低字16位。
IMAGE_REL_BASED_HIGHLOW (3) 全部32位应用于所有32位。
IMAGE_REL_BASED_HIGHADJ (4) 需要32位,高16位位于偏移量,低16位位于下一个偏移量数组元素,组合为一个带符号数,加上32位的一个数,然后加上8000然后把高16位保存在偏移量的16位域内。
IMAGE_REL_BASED_MIPS_JMPADDR (5) Unknown
IMAGE_REL_BASED_SECTION (6) Unknown
IMAGE_REL_BASED_REL32 (7) Unknown
输出表结构实例分析(具体过程将在视频中演示,这里不啰嗦啦~)
工具:PEinfo.exe, UltraEdit, W32DasmV10.0
解剖对象:Counter.dll