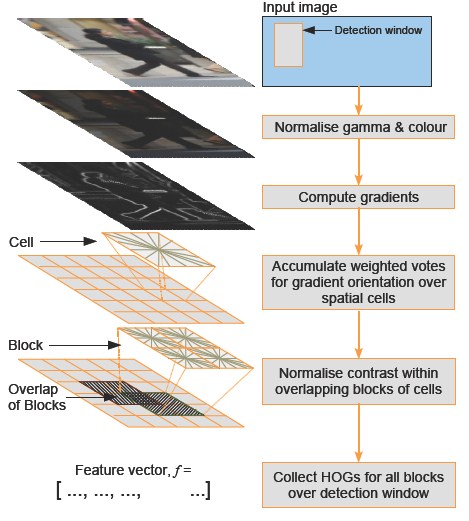
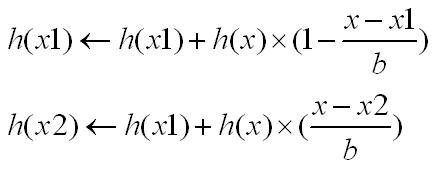一、理论
locally normalised histogram of gradient orientation in dense overlapping grids,即局部归一化的梯度方向直方图,是一种对图像局部重叠区域的密集型描述符, 它通过计算局部区域的梯度方向直方图来构成特征。
2、本质:
Histogram of Oriented Gradient descriptors provide a dense overlapping description of image regions,即统计图像局部区域的梯度方向信息来作为该局部图像区域的表征。
3、OpenCV中的HOG算法来源:
(1)大小:
A、检测窗口:WinSize=128*64像素,在图像中滑动的步长是8像素(水平和垂直都是)
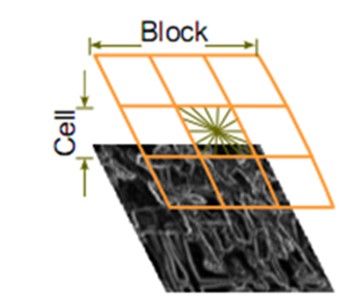
B、块:BlockSize=16*16像素,在检测窗口中滑动的步长是8像素(水平和垂直都是)
C、单元格:CellSize=8*8像素
D、梯度方向:一个Cell的梯度方向分为9个方向,在一个单元格内统计9个方向的梯度直方图
(2)HOG描述子
OpenCV中一个Hog描述子是针对一个检测窗口而言的,一个检测窗口有((128-16)/8+1)*((64-16)/8+1)=105个Block,一个Block有4个Cell,一个Cell的Hog描述子向量的长度是9,所以一个检测窗口的Hog描述子的向量长度是105*4*9=3780维。
HOG特征提取是统计梯度直方图特征。具体来说就是将梯度方向(0->360°)划分为9个区间,将图像化为16x16的若干个block,每个block再化为4个cell(8x8)。对每一个cell,算出每一像素点的梯度方向和模,按梯度方向增加对应bin的值,最终综合N个cell的梯度直方图形成一个高维描述子向量。实际实现的时候会有各种插值。
(1)灰度化
由于颜色信息作用不大,通常转化为灰度图。
(2)标准化gamma空间
为了减少光照因素的影响,首先需要将整个图像进行规范化(归一化),这种处理能够有效地降低图像局部的阴影和光照变化。
比如可以取Gamma=1/2;
(3)计算图像每个像素的梯度(包括大小和方向)
计算图像横坐标和纵坐标方向的梯度,并据此计算每个像素位置的梯度方向值;求导操作不仅能够捕获轮廓,人影和一些纹理信息,还能进一步弱化光照的影响。
梯度算子:水平边缘算子: [-1, 0, 1] ;垂直边缘算子: [-1, 0, 1]T 图像中像素点(x,y)的梯度为:
作者也尝试了其他一些更复杂的模板,如3×3 Sobel 模板,或对角线模板(diagonal masks),但是在这个行人检测的实验中,这些复杂模板的表现都较差,所以作者的结论是:模板越简单,效果反而越好。
作者也尝试了在使用微分模板前加入 一个高斯平滑滤波,但是这个高斯平滑滤波的加入使得检测效果更差,原因是:许多有用的图像信息是来自变化剧烈的边缘,而在计算梯度之前加入高斯滤波会把这些边缘滤除掉。
(4)将图像分割为小的Cell单元格
由于Cell单元格是HOG特征最小的结构单位,而且其块Block和检测窗口Win的滑动步长就是一个Cell的宽度或高度,所以,先把整个图像分割为一个个的Cell单元格(8*8像素)。
(5)为每个单元格构建梯度方向直方图【重点】
这步的目的是:统计局部图像梯度信息并进行量化(或称为编码),得到局部图像区域的特征描述向量。同时能够保持对图像中人体对象的姿势和外观的弱敏感性。
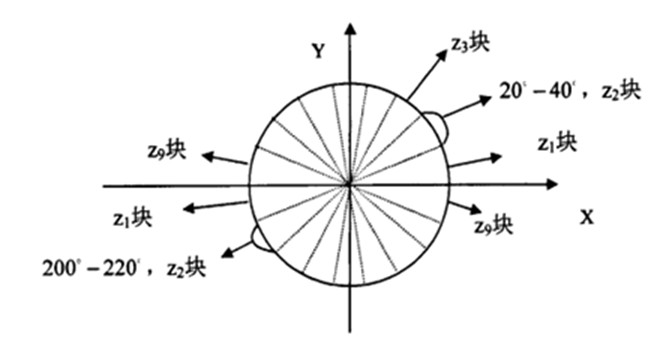
我们将图像分成若干个“单元格cell”,例如每个cell为8*8个像素(可以是矩形的(rectangular),也可以是星形的(radial))。假设我们采用9个bin的直方图来统计这8*8个像素的梯度信息。也就是将cell的梯度方向360度分成9个方向块,如图所示:例如:如果这个像素的梯度方向是20-40度,直方图第2个bin的计数就加一,这样,对cell内每个像素用梯度方向在直方图中进行加权投影(映射到固定的角度范围),就可以得到这个cell的梯度方向直方图了,就是该cell对应的9维特征向量(因为有9个bin)。
像素梯度方向用到了,那么梯度大小呢?梯度大小就是作为投影的权值的。例如说:这个像素的梯度方向是20-40度,然后它的梯度大小是2(假设啊),那么直方图第2个bin的计数就不是加一了,而是加二(假设啊)。
单元格Cell中的每一个像素点都为某个基于方向的直方图通道(orientation-based histogram channel)
投票。投票是采取
加权投票(weighted voting)的方式,即每一票都是带权值的,这个权值是根据该像素点的梯度幅度计算出来。可以采用幅值本身或者它的函数来表示这个权值,实际测试表明: 使用幅值来表示权值能获得最佳的效果,当然,也可以选择幅值的函数来表示,比如幅值的平方根(square root)、幅值的平方(square of the gradient magnitude)、幅值的截断形式(clipped version of the magnitude)等。根据Dalal等人论文的测试结果,采用梯度幅值量级本身得到的检测效果最佳,使用量级的平方根会轻微降低检测结果,而使用二值的边缘权值表示会严重降低效果。
其中,加权采用三线性插值(链接为详细说明的博文)方法,即将当前像素的梯度方向大小、像素在cell中的x坐标与y坐标这三个值来作为插值权重,而被用来插入的值为像素的梯度幅值。采用三线性插值的好处在于:避免了梯度方向直方图在cell边界和梯度方向量化的bin边界处的突然变化。
(6)把单元格组合成大的块(block),块内归一化梯度直方图【重点】
由于局部光照的变化以及前景-背景对比度的变化,使得梯度强度的变化范围非常大。这就需要对梯度强度做归一化。归一化能够进一步地对光照、阴影和边缘进行压缩。
方法:
(6-1)将多个临近的cell组合成一个block块,然后求其梯度方向直方图向量;
(6-2)采用L2-Norm with Hysteresis threshold方式进行归一化,即将直方图向量中bin值的最大值限制为0.2以下,然后再重新归一化一次;
注意:block之间的是“共享”的,也即是说,一个cell会被多个block“共享”。另外,每个“cell”在被归一化时都是“block”independent的,也就是说每个cell在其所属的block中都会被归一化一次,得到一个vector。这就意味着:每一个单元格的特征会以不同的结果多次出现在最后的特征向量中。
(6-3)四种归一化方法:
作者采用了四中不同的方法对区间进行归一化,并对结果进行了比较。引入v表示一个还没有被归一 化的向量,它包含了给定区间(block)的所有直方图信息。| | vk | |表示v的k阶范数,这里的k去1、2。用e表示一个很小的常数。这时,归一化因子可以表示如下:
L2-norm: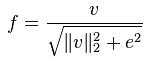
L1-norm: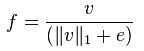
L1-sqrt: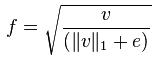
L2-Hys:它可以通过先进行L2-norm,对结果进行截短(clipping)(即值被限制为v - 0.2v之间),然后再重新归一化得到。
作者发现:采用L2- Hys,L2-norm 和 L1-sqrt方式所取得的效果是一样的,L1-norm稍微表现出一点点不可靠性。但是对于没有被归一化的数据来说,这四种方法都表现出来显着的改进。
(6-4)区间(块)有两个主要的几何形状——矩形区间(R-HOG)和环形区间(C-HOG)。
A、R-HOG区间(blocks):大体上是一些方形的格子,它可以有三个参数来表征:每个区间中细胞单元的数目、每个细胞单元中像素点的数目、每个细胞的直方图通道数目。例如:行人检测的最佳参数设置是:3×3细胞/区间、6×6像素/细胞、9个直方图通道。则一块的特征数为:3*3*9;作者还发现,对于R-HOG,在对直方图做处理之前,给每个区间(block)加一个高斯空域窗口(Gaussian spatial window)是非常必要的,因为这样可以降低边缘的周围像素点(pixels around the edge)的权重。R-HOG是各区间被组合起来用于对空域信息进行编码(are used in conjunction to encode spatial form information)。
B、C-HOG区间(blocks):有两种不同的形式,它们的区别在于:一个的中心细胞是完整的,一个的中心细胞是被分割的。如右图所示:
作者发现C-HOG的这两种形式都能取得相同的效果。C-HOG区间(blocks)可以用四个参数来表征:角度盒子的个数(number of angular bins)、半径盒子个数(number of radial bins)、中心盒子的半径(radius of the center bin)、半径的伸展因子(expansion factor for the radius)。通过实验,对于行人检测,最佳的参数设置为:4个角度盒子、2个半径盒子、中心盒子半径为4个像素、伸展因子为2。前面提到过,对于R-HOG,中间加一个高斯空域窗口是非常有必要的,但对于C-HOG,这显得没有必要。C-HOG看起来很像基于形状上下文(Shape Contexts)的方法,但不同之处是:C-HOG的区间中包含的细胞单元有多个方向通道(orientation channels),而基于形状上下文的方法仅仅只用到了一个单一的边缘存在数(edge presence count)。
(6-5)HOG描述符(不同于OpenCV定义):我们将归一化之后的块描述符(向量)就称之为HOG描述符。
(6-6)块划分带来的问题:块与块之间是相互独立的吗?
答:通常的将某个变量范围固定划分为几个区域,由于边界变量与相邻区域也有相关性,所以变量只对一个区域进行投影而对相邻区域完全无关时会对其他区域产生混叠效应。
分块之间的相关性问题的解决:
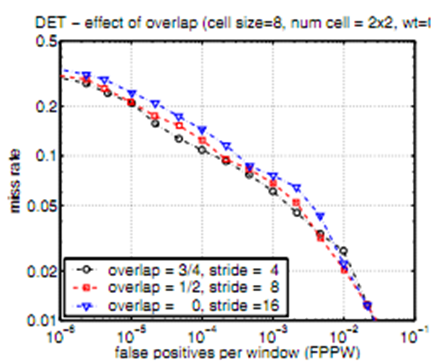
方案一:块重叠,重复统计计算
在重叠方式中,块与块之间的边缘点被重复根据权重投影到各自相邻块(block)中,从而一定模糊了块与块之间的边界,处于块边缘部分的像素点也能够给相邻块中的方向梯度直方图提供一定贡献,从而达到关联块与块之间的关系的作用。Datal对于块和块之间相互重叠程度对人体目标检测识别率影响也做了实验分析。
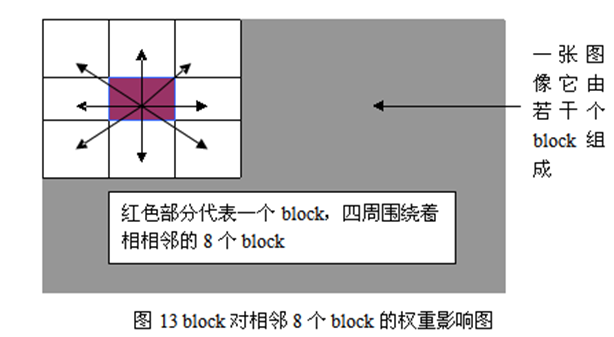
方案二:线性插值权重分配
有些文献采用的不是块与块重叠的方法,而是采用线性插值的方法来削弱混叠效应。这种方法的主要思想是每个Block都对临近的Block都有影响,这种影响,我们可以以一种加权方式附加上去。
基于线性插值的基本思想,对于上图四个方向(横纵两个45度斜角方向)个进行一次线性插值就可以达到权重分配目的。下面介绍一维线性插值。假设x1和x2是x块相邻两块的中心,且x1<x<x2。对w(即权重,一般可直接采用该block的直方图值即h(x))进行线性插值的方法如下式:
其中b在横纵方向取块间隔,而在斜45度方向则可采用sqrt(2)倍的块间隔。
将所有“block”的HOG描述符组合在一起,形成最终的feature vector,该feature vector就描述了detect window的图像内容。
二、OpenCV中HOG的参数与函数说明(HOG链接为OpenCV英文,这里为网友翻译)
注:HOG在OpenCV中的几个模块中都有,略有差别,可做参考,OpenCV的官方文档中只有对GPU模块的HOG,这里前面几个函数说明是GPU中的,后面两个objedetect模块中。其实我们在使用时用的是objedetect模块中的HOG。
0、HOGDescriptor结构体
HOGDescriptor结构体的注释点击
这里(里面包括hog.cpp的详细注释)。
1、构造函数
(1)作用:创造一个HOG描述子和检测器
(2)函数原型:
C++: gpu::HOGDescriptor::
HOGDescriptor(Size
win_size=Size(64, 128),
Size
block_size=Size(16, 16),
Size block_stride=Size(8, 8),
Size cell_size=Size(8, 8),
int nbins=9,
double win_sigma=DEFAULT_WIN_SIGMA,
double threshold_L2hys=0.2,
bool gamma_correction=true,
int nlevels=DEFAULT_NLEVELS
)
(3)参数注释
<1>win_size:检测窗口大小。
<2>block_size:块大小,目前只支持Size(16, 16)。
<3>block_stride:块的滑动步长,大小只支持是单元格cell_size大小的倍数。
<4>cell_size:单元格的大小,目前只支持Size(8, 8)。
<5>nbins:直方图bin的数量(投票箱的个数),目前每个单元格Cell只支持9个。
<6>win_sigma:高斯滤波窗口的参数。
<7>threshold_L2hys:块内直方图归一化类型L2-Hys的归一化收缩率
<8>gamma_correction:是否gamma校正
<9>nlevels:检测窗口的最大数量
2、getDescriptorSize函数
(1)作用:获取一个检测窗口的HOG特征向量的维数
(2)函数原型:
C++:
size_t gpu::HOGDescriptor::
getDescriptorSize() const
3、getBlockHistogramSize函数
C++:
size_t gpu::HOGDescriptor::
getBlockHistogramSize() const
C++:
void gpu::HOGDescriptor::
setSVMDetector(const vector<float>&
detector)
5、getDefaultPeopleDetector 函数
C++:
static vector<float> gpu::HOGDescriptor::
getDefaultPeopleDetector()
6、getPeopleDetector48x96 函数
(1)作用:获取行人分类器(48*96检测窗口大小)的系数
C++:
static vector<float> gpu::HOGDescriptor::
getPeopleDetector48x96()
7、getPeopleDetector64x128 函数
(1)作用:获取行人分类器(64*128检测窗口大小)的系数
C++:
static vector<float> gpu::HOGDescriptor::
getPeopleDetector64x128()
C++:
void gpu::HOGDescriptor::
detect(const GpuMat&
img,
vector<Point>&
found_locations,
double hit_threshold=0,
Size win_stride=Size(),
Size padding=Size()
)
(3)参数注释
<1>img:源图像。只支持CV_8UC1和CV_8UC4数据类型。
<2>found_locations:检测出的物体的边缘。
<3>hit_threshold:特征向量和SVM划分超平面的阀值距离。通常它为0,并应由检测器系数决定。但是,当系数被省略时,可以手动指定它。
<4>win_stride:窗口步长,必须是块步长的整数倍。
<5>padding:模拟参数,使得CUP能兼容。目前必须是(0,0)。
9、detectMultiScale 函数(需有setSVMDetector)
C++:
void gpu::HOGDescriptor::
detectMultiScale(const GpuMat&
img,
vector<Rect>&
found_locations,
double hit_threshold=0,
Size win_stride=Size(),
Size padding=Size(),
double scale0=1.05,
int group_threshold=2
)
(3)参数注释
<1>img:源图像。只支持CV_8UC1和CV_8UC4数据类型。
<2>found_locations:检测出的物体的边缘。
<3>hit_threshold:特征向量和SVM划分超平面的阀值距离。通常它为0,并应由检测器系数决定。但是,当系数被省略时,可以手动指定它。
<4>win_stride:窗口步长,必须是块步长的整数倍。
<5>padding:模拟参数,使得CUP能兼容。目前必须是(0,0)。
<6>scale0:检测窗口增长参数。
<7>group_threshold:调节相似性系数的阈值。检测到时,某些对象可以由许多矩形覆盖。 0表示不进行分组。
<1> 得到层数levels
某图片(530,402)为例,lg(402/128)/lg1.05=23.4 则得到层数为24
<2>循环levels次,每次执行内容如下
HOGThreadData& tdata = threadData[getThreadNum()];
Mat smallerImg(sz, img.type(), tdata.smallerImgBuf.data);
<3>循环中调用以下核心函数
detect(smallerImg, tdata.locations, hitThreshold, winStride, padding);
其参数分别为,该比例下图像、返回结果列表、门槛值、步长、margin
该函数内容如下:
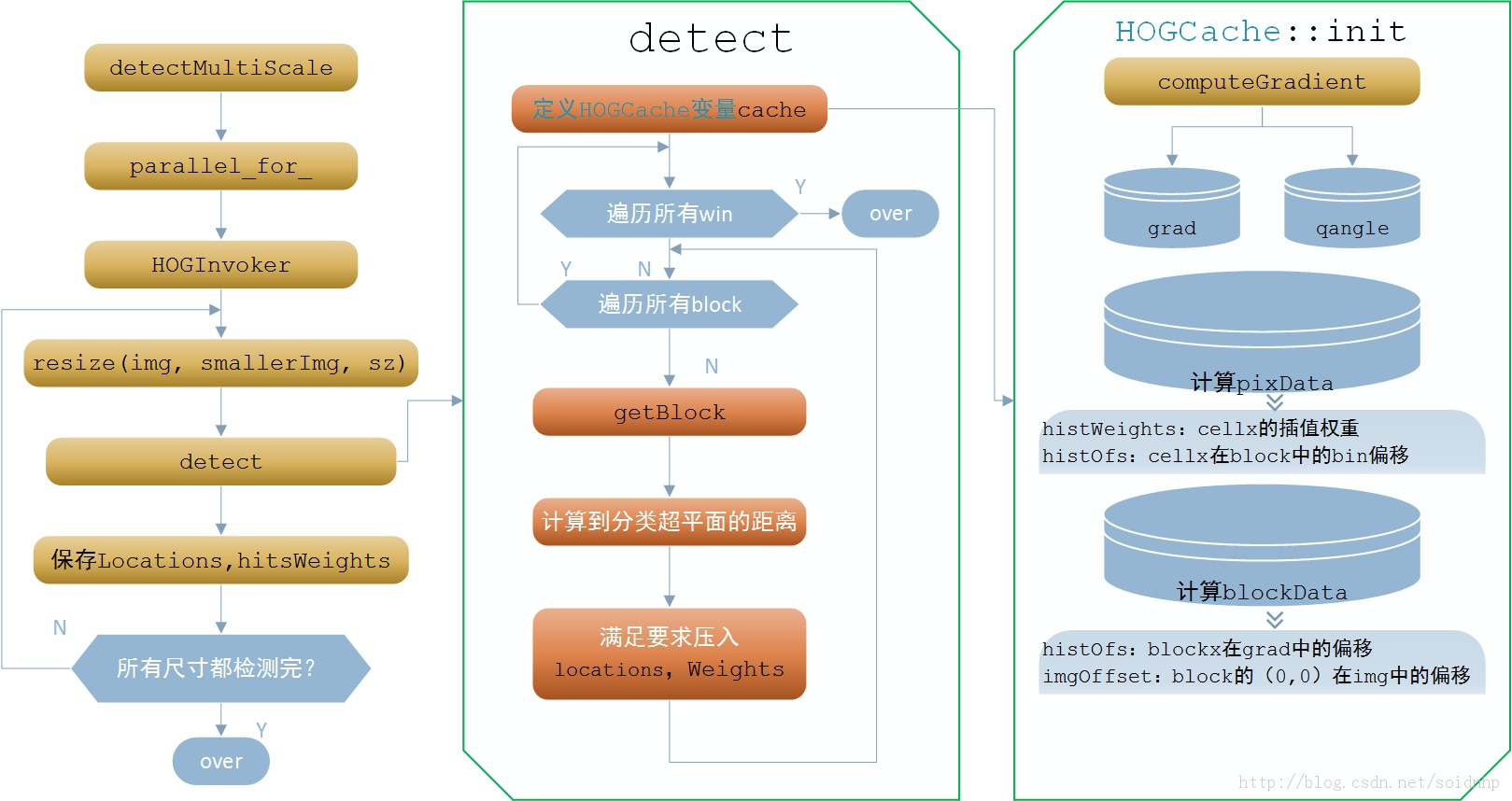
(a)得到补齐图像尺寸paddedImgSize
(b)创建类的对象HOGCache cache(this, img, padding, padding, nwindows == 0, cacheStride); 在创建过程中,首先初始化HOGCache::init,包括:计算梯度descriptor->computeGradient、得到块的个数105、每块参数个数36。
(c)获得窗口个数nwindows,以第一层为例,其窗口数为(530+32*2-64)/8+ (402+32*2-128)/8+1 =67*43=2881,其中(32,32)为winStride参数, 也可用(24,16)
(d)在每个窗口执行循环,内容如下:
在105个块中执行循环,每个块内容为:通过getblock函数计算HOG特征并 归一化,36个数分别与算子中对应数进行相应运算;判断105个块的总和 s >= hitThreshold 则认为检测到目标
10、getDescriptors 函数
(1)作用:返回整个图片的块描述符 (主要用于分类学习)。
C++:
void gpu::HOGDescriptor::
getDescriptors(const GpuMat& img,
Size
win_stride,
GpuMat& descriptors,
int descr_format=DESCR_FORMAT_COL_BY_COL
)
(3)参数注释
<1>img:源图像。只支持CV_8UC1和CV_8UC4数据类型。
<2>win_stride:窗口步长,必须是块步长的整数倍。
<3>descriptors:描述符的2D数组。
<4>descr_format:描述符存储格式:
DESCR_FORMAT_ROW_BY_ROW - 行存储。
DESCR_FORMAT_COL_BY_COL - 列存储。
11、computeGradient 函数
(1)作用:计算img经扩张后的图像中每个像素的梯度和角度
(2)函数原型:
void HOGDescriptor::computeGradient(const Mat& img,
Mat& grad,
Mat& qangle,
Size paddingTL,
Size paddingBR
) const
(3)参数注释
<1>img:源图像。只支持CV_8UC1和CV_8UC4数据类型。
<2>grad:输出梯度(两通道),记录每个像素所属bin对应的权重的矩阵,为幅值乘以权值。这个权值是关键,也很复杂:包括高斯权重,三次插值的权重,在本函数中先值考虑幅值和相邻bin间的插值权重。
<3>qangle:输入弧度(两通道),记录每个像素角度所属的bin序号的矩阵,均为2通道,为了线性插值。
<4>paddingTL:Top和Left扩充像素数。
<5>paddingBR:Bottom和Right扩充像素数。
12、compute 函数
HOGDescriptor::
compute(const Mat&
img,
vector<float>&
descriptors,
Size winStride,
Size padding,
const vector<Point>& locations
) const
(3)参数注释
<1>img:源图像。只支持CV_8UC1和CV_8UC4数据类型。
<2>descriptors:返回的HOG特征向量,descriptors.size是HOG特征的维数。
<3>winStride:窗口移动步长。
<4>padding:扩充像素数。
<5>locations:对于正样本可以直接取(0,0),负样本为随机产生合理坐标范围内的点坐标。
三、HOG算法OpenCV实现流程
四、OpenCV的简单例子
1、HOG行人检测
(1)代码:
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/gpu/gpu.hpp>
#include <stdio.h>
using namespace cv;
int main(int argc, char** argv)
{
Mat img;
vector<Rect> found;
img = imread(argv[1]);
if(argc != 2 || !img.data)
{
printf("没有图片
");
return -1;
}
HOGDescriptor defaultHog;
defaultHog.setSVMDetector(HOGDescriptor::getDefaultPeopleDetector());
//进行检测
defaultHog.detectMultiScale(img, found);
//画长方形,框出行人
for(int i = 0; i < found.size(); i++)
{
Rect r = found[i];
rectangle(img, r.tl(), r.br(), Scalar(0, 0, 255), 3);
}
namedWindow("检测行人", CV_WINDOW_AUTOSIZE);
imshow("检测行人", img);
waitKey(0);
return 0;
}
上述过程并没有像人脸检测Demo里有Load训练好的模型的步骤,这个
getDefaultPeopleDetector是默认模型,这个模型数据在OpenCV源码中是一堆常量数字,这些数字是通过原作者提供的行人样本
INRIAPerson.tar训练得到的。
这里只是用到了HOG的识别模块,OpenCV把HOG包的内容比较多,既有HOG的特征提取,也有结合SVM的识别,这里的识别只有检测部分,OpenCV提供默认模型,如果使用新的模型,需要重新训练。
(2)将样本图像的名称写到一个TXT文件,方便程序调用。
(3)依次提取每张图像的HOG特征向量。
hog.compute(img, descriptors,Size(8,8), Size(0,0));
可以生成hog descriptors,把它保存到文件中
for(int j=0;j<3780;j++)
fprintf(f,"%f,",descriptors[j]);
(5)得到XML文件。
这里识别有两种用法:
B、另一种采用
hog.setSVMDetector+训练的模型和hog.detectMultiScale(参考
利用Hog特征和SVM分类器进行行人检测 )
五、总结
1、HOG与SIFT的区别
HOG和SIFT都是描述子,以及由于在具体操作上有很多相似的步骤,所以致使很多人误认为HOG是SIFT的一种,其实两者在使用目的和具体处理细节上是有很大的区别的。HOG与SIFT的主要区别如下:
(1)SIFT是基于关键点特征向量的描述。
(2)HOG是将图像均匀的分成相邻的小块,然后在所有的小块内统计梯度直方图。
(3)SIFT需要对图像尺度空间下对像素求极值点,而HOG中不需要。
(4)SIFT一般有两大步骤,第一个步骤对图像提取特征点,而HOG不会对图像提取特征点。
2、HOG的优缺点
优点:
(1)HOG表示的是边缘(梯度)的结构特征,因此可以描述局部的形状信息;
(2)位置和方向空间的量化一定程度上可以抑制平移和旋转带来的影响;
(3)采取在局部区域归一化直方图,可以部分抵消光照变化带来的影响;
(4)由于一定程度忽略了光照颜色对图像造成的影响,使得图像所需要的表征数据的维度降低了;
(5)而且由于这种分块分单元的处理方法,也使得图像局部像素点之间的关系可以很好得到表征。
缺点:
(1)描述子生成过程冗长,导致速度慢,实时性差;
(2)很难处理遮挡问题;
(3)由于梯度的性质,该描述子对噪点相当敏感。