开源地址见Github:https://github.com/datawhalechina/team-learning
此部分为智慧海洋建设竞赛的模型建立模块。在该模块中主要介绍了如何进行模型建立并对模型调优。
学习目标
- 学习如何选择合适的模型以及如何通过模型来进行特征选择
- 掌握随机森林、lightGBM、Xgboost模型的使用。
- 掌握贝叶斯优化方法的具体使用
内容介绍
- 模型训练与预测
- 随机森林
- lightGBM模型 [已学 https://www.cnblogs.com/zhazhaacmer/p/13780827.html]
- Xgboost模型 [已学 https://www.cnblogs.com/zhazhaacmer/p/13759526.html]
- 交叉验证 [已学 https://zzk.cnblogs.com/my/s/blogpost-p?Keywords=交叉验证]
- 模型调参 [已学 https://zzk.cnblogs.com/my/s/blogpost-p?Keywords=模型调参 , 贝叶斯例子 https://www.cnblogs.com/zhazhaacmer/p/14687543.html]
- 智慧海洋数据集模型代码示例
下面只记录教程中一些个人认为比较有意义的内容
随机森林 (集成学习的一种)
随机森林是通过集成学习的思想将多棵树集成的一种算法,基本单元是决策树,而它的本质属于机器学习的一个分支——集成学习。
随机森林模型的主要优点是: 决策树的优点+集成一组决策树后的森林的优点.
- 能够有效地运行在大数据集上;
- 能够处理具有高维特征的输入样本,而且不需要降维;
- 能够评估各个特征在分类问题上的重要性;
- 在生成过程中,能够获取到内部生成误差的一种无偏估计;
- 对于缺省值问题也能够获得很好的结果。
使用sklearn调用随机森林分类树进行预测算法:
from sklearn import datasets
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import f1_score
# 数据集导入
iris = datasets.load_iris()
feature_name = iris.feature_names
X = iris.data
y = iris.target
# 随机森林
clf = RandomForestClassifier(n_estimators=200)
train_X,test_X,train_y,test_y = train_test_split(X,y,test_size=0.1,random_state=2333)
clf.fit(train_X, train_y)
test_pred = clf.predict(test_X)
test_pred
array([0, 2, 0, 0, 0, 0, 2, 2, 1, 2, 1, 2, 1, 1, 2])
#特征的重要性查看
print(str(feature_name)+'
'+str(clf.feature_importances_))
['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
[0.09039989 0.02539155 0.46555911 0.41864945]
采用F1 score进行模型的评价,此为一篇csdn中对该评价方法的简单说明
#F1-score 用于模型评价
#如果是二分类问题则选择参数‘binary’
#如果考虑类别的不平衡性,需要计算类别的加权平均,则使用‘weighted’
#如果不考虑类别的不平衡性,计算宏平均,则使用‘macro’
score=f1_score(test_y,test_pred,average='macro')
print("随机森林-macro:",score)
score=f1_score(test_y,test_pred,average='weighted')
print("随机森林-weighted:",score)
随机森林-macro: 1.0
随机森林-weighted: 1.0
lightGBM模型
lightGBM的学习可参见这篇文章
lightGBM中文文档这个对超参数的讲解较为详细,建议仔细阅读
(lightGBM调参指导)[https://www.cnblogs.com/zhazhaacmer/p/13780827.html#lightgbm调参指导]
绘制训练集vs验证集的学习曲线图
import lightgbm as lgb
from sklearn import datasets
from sklearn.model_selection import train_test_split
import numpy as np
from sklearn.metrics import roc_auc_score, accuracy_score,f1_score
import matplotlib.pyplot as plt
# 加载数据
iris = datasets.load_iris()
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.3)
# 转换为Dataset数据格式
train_data = lgb.Dataset(X_train, label=y_train)
validation_data = lgb.Dataset(X_test, label=y_test)
# 参数
results = {}
params = {
'learning_rate': 0.1,
'lambda_l1': 0.1,
'lambda_l2': 1.0,
'max_depth': 1,
'objective': 'multiclass', # 目标函数
'num_class': 3,
'verbose': -1
}
# 模型训练
gbm = lgb.train(params, train_data, valid_sets=(validation_data,train_data),valid_names=('validate','train'),evals_result= results, verbose_eval=50)
# 模型预测
y_pred_test = gbm.predict(X_test)
y_pred_data = gbm.predict(X_train)
y_pred_data = [list(x).index(max(x)) for x in y_pred_data]
y_pred_test = [list(x).index(max(x)) for x in y_pred_test]
# 模型评估
print(accuracy_score(y_test, y_pred_test))
print('训练集',f1_score(y_train, y_pred_data,average='macro'))
print('验证集',f1_score(y_test, y_pred_test,average='macro'))
[50] train's multi_logloss: 0.0942409 validate's multi_logloss: 0.253985
[100] train's multi_logloss: 0.0566839 validate's multi_logloss: 0.320229
0.8666666666666667
训练集 0.9797235023041475
验证集 0.8819444444444445
# 有以下曲线可知验证集的损失是比训练集的损失要高,所以模型可以判断模型出现了过拟合
lgb.plot_metric(results) # 'lambda_l2': 1.0,
plt.show()
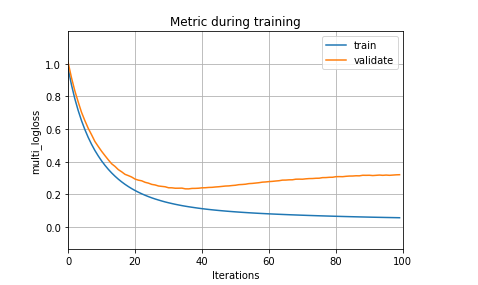
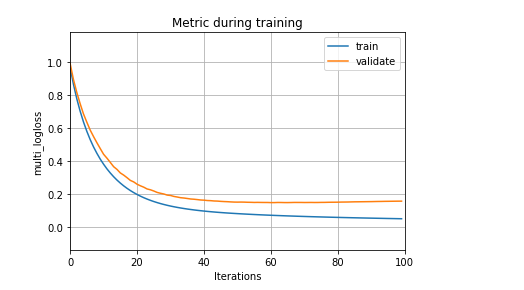
#因此可以尝试将lambda_l2设置为0.9
lgb.plot_metric(results) # 'lambda_l2': 0.9
plt.show()
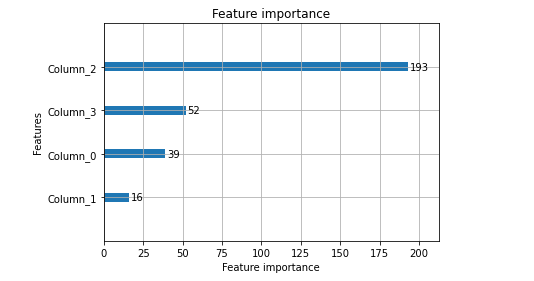
绘制lgb的特征重要性评估图
lgb.plot_importance(gbm, importance_type = "split")
plt.show()
xgboost模型 (看自己的文章)
xgboost下from xgboost import plot_importance可以查看特征重要性
交叉验证
略 https://zzk.cnblogs.com/my/s/blogpost-p?Keywords=交叉验证
模型调参
调参就是对模型的参数进行调整,找到使模型最优的超参数,调参的目标就是尽可能达到整体模型的最优
1. 网格搜索
网格搜索就是一种穷举搜索,在所有候选的参数选择中通过循环遍历去在所有候选参数中寻找表现最好的结果。
2. 学习曲线 (吴恩达版本)
学习曲线是在训练集大小不同时通过绘制模型训练集和交叉验证集上的准确率来观察模型在新数据上的表现,进而来判断模型是否方差偏高或偏差过高,以及增大训练集是否可以减小过拟合。
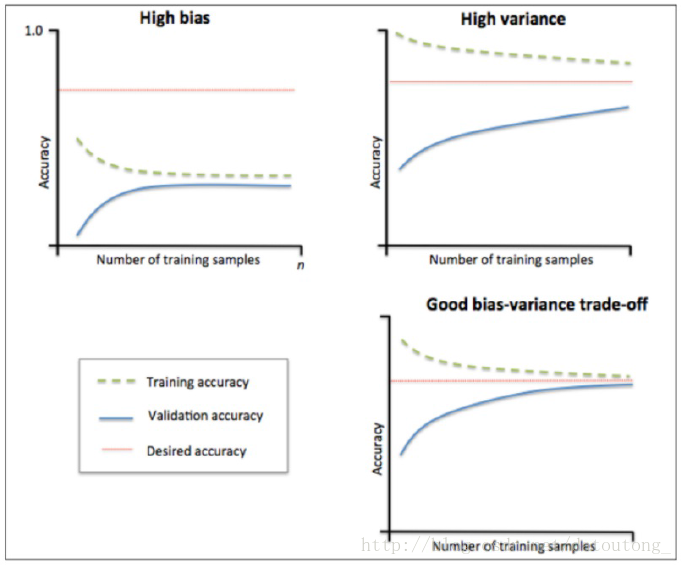
1、当训练集和测试集的误差收敛但却很高时,为高偏差。
左上角的偏差很高,训练集和验证集的准确率都很低,很可能是欠拟合。
我们可以增加模型参数,比如,构建更多的特征,减小正则项。
此时通过增加数据量是不起作用的。
2、当训练集和测试集的误差之间有大的差距时,为高方差。
当训练集的准确率比其他独立数据集上的测试结果的准确率要高时,一般都是过拟合。
右上角方差很高,训练集和验证集的准确率相差太多,应该是过拟合。
我们可以增大训练集,降低模型复杂度,增大正则项,或者通过特征选择减少特征数。
理想情况是是找到偏差和方差都很小的情况,即收敛且误差较小。
3. 验证曲线
scikitlearn 3.5. 验证曲线: 绘制分数以评估模型
和学习曲线不同,验证曲线的横轴为某个超参数的一系列值,由此比较不同超参数设置下的模型准确值。从下图的验证曲线可以看到,随着超参数设置的改变,模型可能会有从欠拟合到合适再到过拟合的过程,进而可以选择一个合适的超参数设置来提高模型的性能。
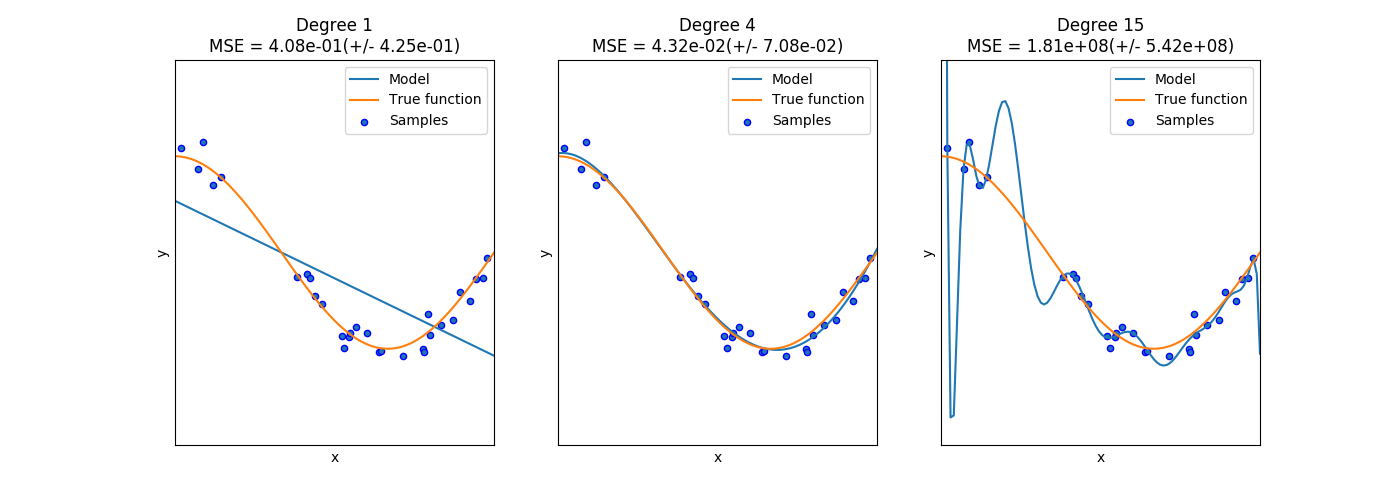
4. 贝叶斯参数优化
贝叶斯优化介绍也是在建模调参过程中常用的一种方法
智慧海洋数据集模型代码示例
lightGBM模型
import pandas as pd
import numpy as np
from tqdm import tqdm
from sklearn.metrics import classification_report, f1_score
from sklearn.model_selection import StratifiedKFold, KFold,train_test_split
import lightgbm as lgb
import os
import warnings
from hyperopt import fmin, tpe, hp, STATUS_OK, Trials
all_df=pd.read_csv('E:/competition-data/017_wisdomOcean/group_df.csv',index_col=0)
use_train = all_df[all_df['label'] != -1]
use_test = all_df[all_df['label'] == -1]#label为-1时是测试集
use_feats = [c for c in use_train.columns if c not in ['ID', 'label']]
X_train,X_verify,y_train,y_verify= train_test_split(use_train[use_feats],use_train['label'],test_size=0.3,random_state=0)
1.根据特征的重要性进行特征选择
##############特征选择参数###################
selectFeatures = 200 # 控制特征数
earlyStopping = 100 # 控制早停
select_num_boost_round = 1000 # 特征选择训练轮次
#首先设置基础参数
selfParam = {
'learning_rate':0.01, # 学习率
'boosting':'dart', # 算法类型, gbdt,dart
'objective':'multiclass', # 多分类
'metric':'None',
'num_leaves':32, #
'feature_fraction':0.7, # 训练特征比例
'bagging_fraction':0.8, # 训练样本比例
'min_data_in_leaf':30, # 叶子最小样本
'num_class': 3,
'max_depth':6, # 树的最大深度
'num_threads':8,#LightGBM 的线程数
'min_data_in_bin':30, # 单箱数据量
'max_bin':256, # 最大分箱数
'is_unbalance':True, # 非平衡样本
'train_metric':True,
'verbose':-1,
}
# 特征选择 ---------------------------------------------------------------------------------
def f1_score_eval(preds, valid_df):
labels = valid_df.get_label()
preds = np.argmax(preds.reshape(3, -1), axis=0)
scores = f1_score(y_true=labels, y_pred=preds, average='macro')
return 'f1_score', scores, True
train_data = lgb.Dataset(data=X_train,label=y_train,feature_name=use_feats)
valid_data = lgb.Dataset(data=X_verify,label=y_verify,reference=train_data,feature_name=use_feats)
sm = lgb.train(params=selfParam,train_set=train_data,num_boost_round=select_num_boost_round,
valid_sets=[valid_data],valid_names=['valid'],
feature_name=use_feats,
# early_stopping_rounds=earlyStopping, warnings.warn('Early stopping is not available in dart mode')
verbose_eval=False,keep_training_booster=True,feval=f1_score_eval)
features_importance = {k:v for k,v in zip(sm.feature_name(),sm.feature_importance(iteration=sm.best_iteration))}
sort_feature_importance = sorted(features_importance.items(),key=lambda x:x[1],reverse=True)
print('total feature best score:', sm.best_score)
print('total feature importance:',sort_feature_importance)
print('select forward {} features:{}'.format(selectFeatures,sort_feature_importance[:selectFeatures]))
#model_feature是选择的超参数
model_feature = [k[0] for k in sort_feature_importance[:selectFeatures]]
model_feature[:3]
total feature best score: defaultdict(<class 'collections.OrderedDict'>, {'valid': OrderedDict([('f1_score', 0.9035980735540531)])})
total feature importance: [('pos_neq_zero_speed_q_40', 1831), ('lat_lon_countvec_1_x', 1793), ('rank2_mode_lat', 1728), ('pos_neq_zero_speed_median', 1350), ('pos_neq_zero_speed_q_60', 1343), ('lat_lon_tfidf_0_x', 1270), ('pos_neq_zero_speed_q_80', 1195), ('w2v_9_mean', 1125), ('sample_tfidf_0_x', 1123), ('lat_lon_tfidf_11_x', 926), ('rank3_mode_lat', 922), ('w2v_16_mean', 900), ('pos_neq_zero_speed_q_70', 882), ('w2v_5_mean', 857), ('pos_neq_zero_speed_q_30', 846), ('w2v_12_mean', 809) # 后续手动删除一部分]
['pos_neq_zero_speed_q_40', 'lat_lon_countvec_1_x', 'rank2_mode_lat']
贝叶斯优化介绍也是在建模调参过程中常用的一种方法,下面是通过贝叶斯优化进行超参数选择的代码
##############超参数优化的超参域###################
spaceParam = {
'boosting': hp.choice('boosting',['gbdt','dart']),
'learning_rate':hp.loguniform('learning_rate', np.log(0.01), np.log(0.05)),
'num_leaves': hp.quniform('num_leaves', 3, 66, 3),
'feature_fraction': hp.uniform('feature_fraction', 0.7,1),
'min_data_in_leaf': hp.quniform('min_data_in_leaf', 10, 50,5),
'num_boost_round':hp.quniform('num_boost_round',500,2000,100),
'bagging_fraction':hp.uniform('bagging_fraction',0.6,1)
}
def getParam(param):
for k in ['num_leaves', 'min_data_in_leaf','num_boost_round']:
param[k] = int(float(param[k]))
for k in ['learning_rate', 'feature_fraction','bagging_fraction']:
param[k] = float(param[k])
if param['boosting'] == 0:
param['boosting'] = 'gbdt'
elif param['boosting'] == 1:
param['boosting'] = 'dart'
# 添加固定参数
param['objective'] = 'multiclass'
param['max_depth'] = 7
param['num_threads'] = 8
param['is_unbalance'] = True
param['metric'] = 'None'
param['train_metric'] = True
param['verbose'] = -1
param['bagging_freq']=5
param['num_class']=3
param['feature_pre_filter']=False
return param
def f1_score_eval(preds, valid_df):
labels = valid_df.get_label()
preds = np.argmax(preds.reshape(3, -1), axis=0)
scores = f1_score(y_true=labels, y_pred=preds, average='macro')
return 'f1_score', scores, True
def lossFun(param):
param = getParam(param)
m = lgb.train(params=param,train_set=train_data,num_boost_round=param['num_boost_round'],
valid_sets=[train_data,valid_data],valid_names=['train','valid'],
feature_name=features,feval=f1_score_eval,
# early_stopping_rounds=earlyStopping,
verbose_eval=False,keep_training_booster=True)
train_f1_score = m.best_score['train']['f1_score']
valid_f1_score = m.best_score['valid']['f1_score']
loss_f1_score = 1 - valid_f1_score
print('训练集f1_score:{},测试集f1_score:{},loss_f1_score:{}'.format(train_f1_score, valid_f1_score, loss_f1_score))
return {'loss': loss_f1_score, 'params': param, 'status': STATUS_OK}
features = model_feature
train_data = lgb.Dataset(data=X_train[model_feature],label=y_train,feature_name=features)
valid_data = lgb.Dataset(data=X_verify[features],label=y_verify,reference=train_data,feature_name=features)
best_param = fmin(fn=lossFun, space=spaceParam, algo=tpe.suggest, max_evals=100, trials=Trials())
best_param = getParam(best_param)
print('Search best param:',best_param)
经过特征选择和超参数优化后,最终的模型使用为将参数设置为贝叶斯优化之后的超参数,然后进行5折交叉,对测试集进行叠加求平均。
def f1_score_eval(preds, valid_df):
labels = valid_df.get_label()
preds = np.argmax(preds.reshape(3, -1), axis=0)
scores = f1_score(y_true=labels, y_pred=preds, average='macro')
return 'f1_score', scores, True
def sub_on_line_lgb(train_, test_, pred, label, cate_cols, split,
is_shuffle=True,
use_cart=False,
get_prob=False):
n_class = 3
train_pred = np.zeros((train_.shape[0], n_class))
test_pred = np.zeros((test_.shape[0], n_class))
n_splits = 5
assert split in ['kf', 'skf'
], '{} Not Support this type of split way'.format(split)
if split == 'kf':
folds = KFold(n_splits=n_splits, shuffle=is_shuffle, random_state=1024)
kf_way = folds.split(train_[pred])
else:
#与KFold最大的差异在于,他是分层采样,确保训练集,测试集中各类别样本的比例与原始数据集中相同。
folds = StratifiedKFold(n_splits=n_splits,
shuffle=is_shuffle,
random_state=1024)
kf_way = folds.split(train_[pred], train_[label])
print('Use {} features ...'.format(len(pred)))
#将以下参数改为贝叶斯优化之后的参数
params = {
'learning_rate': 0.05,
'boosting_type': 'gbdt',
'objective': 'multiclass',
'metric': 'None',
'num_leaves': 60,
'feature_fraction':0.86,
'bagging_fraction': 0.73,
'bagging_freq': 5,
'seed': 1,
'bagging_seed': 1,
'feature_fraction_seed': 7,
'min_data_in_leaf': 15,
'num_class': n_class,
'nthread': 8,
'verbose': -1,
'num_boost_round': 1100,
'max_depth': 7,
}
for n_fold, (train_idx, valid_idx) in enumerate(kf_way, start=1):
print('the {} training start ...'.format(n_fold))
train_x, train_y = train_[pred].iloc[train_idx
], train_[label].iloc[train_idx]
valid_x, valid_y = train_[pred].iloc[valid_idx
], train_[label].iloc[valid_idx]
if use_cart:
dtrain = lgb.Dataset(train_x,
label=train_y,
categorical_feature=cate_cols)
dvalid = lgb.Dataset(valid_x,
label=valid_y,
categorical_feature=cate_cols)
else:
dtrain = lgb.Dataset(train_x, label=train_y)
dvalid = lgb.Dataset(valid_x, label=valid_y)
clf = lgb.train(params=params,
train_set=dtrain,
# num_boost_round=3000,
valid_sets=[dvalid],
early_stopping_rounds=100,
verbose_eval=100,
feval=f1_score_eval)
train_pred[valid_idx] = clf.predict(valid_x,
num_iteration=clf.best_iteration)
test_pred += clf.predict(test_[pred],
num_iteration=clf.best_iteration) / folds.n_splits
print(classification_report(train_[label], np.argmax(train_pred,
axis=1),
digits=4))
if get_prob:
sub_probs = ['qyxs_prob_{}'.format(q) for q in ['围网', '刺网', '拖网']]
prob_df = pd.DataFrame(test_pred, columns=sub_probs)
prob_df['ID'] = test_['ID'].values
return prob_df
else:
test_['label'] = np.argmax(test_pred, axis=1)
return test_[['ID', 'label']]
use_train = all_df[all_df['label'] != -1]
use_test = all_df[all_df['label'] == -1]
# use_feats = [c for c in use_train.columns if c not in ['ID', 'label']]
use_feats=model_feature
sub = sub_on_line_lgb(use_train, use_test, use_feats, 'label', [], 'kf',is_shuffle=True,use_cart=False,get_prob=False)
Use 200 features ...
the 1 training start ...
Training until validation scores don't improve for 100 rounds
[100] valid_0's f1_score: 0.897089
[200] valid_0's f1_score: 0.910724
[300] valid_0's f1_score: 0.91349
[400] valid_0's f1_score: 0.916062
[500] valid_0's f1_score: 0.918183
Early stopping, best iteration is:
[428] valid_0's f1_score: 0.920029
the 2 training start ...
Training until validation scores don't improve for 100 rounds
[100] valid_0's f1_score: 0.918009
[200] valid_0's f1_score: 0.921866
[300] valid_0's f1_score: 0.92656
[400] valid_0's f1_score: 0.929741
[500] valid_0's f1_score: 0.929409
Early stopping, best iteration is:
[427] valid_0's f1_score: 0.931762
the 3 training start ...
Training until validation scores don't improve for 100 rounds
[100] valid_0's f1_score: 0.920599
[200] valid_0's f1_score: 0.931391
[300] valid_0's f1_score: 0.932421
Early stopping, best iteration is:
[225] valid_0's f1_score: 0.93549
the 4 training start ...
Training until validation scores don't improve for 100 rounds
[100] valid_0's f1_score: 0.898798
[200] valid_0's f1_score: 0.913924
[300] valid_0's f1_score: 0.920644
[400] valid_0's f1_score: 0.921482
Early stopping, best iteration is:
[386] valid_0's f1_score: 0.922848
the 5 training start ...
Training until validation scores don't improve for 100 rounds
[100] valid_0's f1_score: 0.89997
[200] valid_0's f1_score: 0.911747
[300] valid_0's f1_score: 0.913802
[400] valid_0's f1_score: 0.923308
[500] valid_0's f1_score: 0.923616
Early stopping, best iteration is:
[483] valid_0's f1_score: 0.927273
precision recall f1-score support
0 0.8794 0.9001 0.8896 1621
1 0.9584 0.9057 0.9313 1018
2 0.9600 0.9640 0.9620 4361
accuracy 0.9407 7000
macro avg 0.9326 0.9233 0.9277 7000
weighted avg 0.9411 0.9407 0.9408 7000
D:Anaconda3libsite-packageslightgbmengine.py:148: UserWarning: Found `num_boost_round` in params. Will use it instead of argument
warnings.warn("Found `{}` in params. Will use it instead of argument".format(alias))
D:Anaconda3libsite-packageslightgbmengine.py:148: UserWarning: Found `num_boost_round` in params. Will use it instead of argument
warnings.warn("Found `{}` in params. Will use it instead of argument".format(alias))
D:Anaconda3libsite-packageslightgbmengine.py:148: UserWarning: Found `num_boost_round` in params. Will use it instead of argument
warnings.warn("Found `{}` in params. Will use it instead of argument".format(alias))
D:Anaconda3libsite-packageslightgbmengine.py:148: UserWarning: Found `num_boost_round` in params. Will use it instead of argument
warnings.warn("Found `{}` in params. Will use it instead of argument".format(alias))
D:Anaconda3libsite-packageslightgbmengine.py:148: UserWarning: Found `num_boost_round` in params. Will use it instead of argument
warnings.warn("Found `{}` in params. Will use it instead of argument".format(alias))
D:Anaconda3libsite-packagesipykernel_launcher.py:88: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
sub
ID label
6670 7000 0
6671 7001 2
6672 7002 0
6673 7003 2
6674 7004 0
... ... ...
8884 8995 0
8885 8996 0
8886 8997 1
8887 8998 2
8888 8999 0
2000 rows × 2 columns