一、第一个python小程序
首先我们要知道python创立的初衷是:Python崇尚优美、清晰、简单。
所以python比起其他的语言需要的工作量少了一半都不止,比如和现在一直霸占语言排行榜 榜首的Java老大哥相比:
public class HelloWorld:{ public static void main(String [] args) { system.out.println("hello world") } }
而伟大的python 只需要那么神奇的一行:
print("hello world")
python代码想输出什么直接print输出就可以了 切记 python文件是以.py结尾的
由此可见 python比起其他语言的冗杂真的有着得天独厚的优势 所以此时不选python 更待何时
二、python的变量
首先我们要知道什么是变量。大家都知道 我们的生活中有很多的我们最开始不知道物体 比如男人最开始我们的祖先也不知道怎么来叫男人 女人 就随便先定义一个词语来代表男人 (我感觉最开始叫男人为人妖也可能),我个人感觉因为不清楚这个事物或者找一个元素来指向代表这个物体的 就是变量
变量是什么? 变量:把程序运行的中间结果临时的存在内存里,以便后续的代码调用。
name = " 红领巾"
上述代码声明了一个变量,变量名为: name,变量name的值为:"红领巾"
其实这在内存中就是有一块内存用来存储红领巾的的内容 如果只定义一个内容你不给一个地址去指向它 也不知道它如何被使用啊 ,就好比
你住在朝阳区长安街116号 但是你要告诉别人你住在这么牛掰的地方啊 不然别人怎么知道你的住址呢 。此时的name就是就是指向内存中开辟的存储“红领巾”的一个变量 name就是红领巾的引用
变量定义规则
- 变量名只能是 字母、数字或下划线的任意组合
- 变量名的第一个字符不能是数字
- 以下关键字不能声明为变量名['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield']
肯定有人为什么这个规定 ,就好比你是男人你要娶妻这是必须要经历的 你如果非要生孩子那么这特么也行不通啊 所以不要违背规则 如果你想 违背规则那么你就要有创建规则的能力
存储的的数据是变量值,变量名和变量值是一种绑定关系,变量名本身并无存储值的功能,
定义方式
驼峰体
AgeOfOldboy = 56
NumberOfStudents = 80
下划线
age_of_oldboy = 56
number_of_students = 80
你觉得哪种更清晰,哪种就是官方推荐的,我想你肯定会先第2种,第一种AgeOfOldboy咋一看以为是AngelaBaby
三、常量
常量即指不变的量,如3.1415926.........,或在程序运行中不会改变的量。程序员约定俗称用变量名全部大写代表常量。
例如:AGE_SD=56 仅仅只是一种提示效果。反正你就记住 全部大写的字母就是常量 除非那个老几 是刚入门的小鸟鸟
四、基本数据类型
我们人类可以很容易的分清数字与字符的区别,但是计算机并不能呀,计算机虽然很强大,但从某些方面有很笨,你得明确的告诉它,“1”是数字,“汗”是文字。否则计算机是分不清的。因此,在每个编程语言中都会有一个叫数据类型的东西,其实就是对常用的各种数据类型进行了明确的划分,你想让计算机进行数值运算,你就传入数字给它,你想让它处理文字,你就传字符串类型给它。python中有很多数据类型,今天我们先了解数字,字符串,布尔类型。
1.数字:int(短整型)
long(长整型)(在python三中没有了)
2.字符串str:
包含在引号(单,双,三)里面,由一串字符组成
用途(描述性的数据):姓名,性别,地址,学历,密码:alex3714
name='egon'
取值:
首先要明确,字符串整体就是一个值,只不过特殊之处在于:
python中没有字符类型,字符串是由一串字符组成,想取出字符串中
的字符,也可以按照下标的方式取得
name:取得是字符串整体的那一个值
name[1]:取得是第二位置的字符
python 字符串的单双引号的使用是一样恩等,只不过有时候使用双引号可以区分这个字符串本身自带的的单引号或者特殊符号而已
字符串拼接:
>>> msg1='hello'
>>> msg2=' world'
>>>
>>> msg1 + msg2
'hello world'
>>> res=msg1 + msg2
>>> print(res)
hello world
>>> msg1*3
'hellohellohello'
五、什么是计算机交互?
name=input("请输入用户名:")
无论输入何种类型的数据,input都会将他存成字符串格式
为什么要有程序交互?
让计算机能够模拟人,让计算机去接受用户的输入信息.
重点:一定要记住 input输入的都是字符串类型的 哪怕是数字它打印出来的也是字符串类型的
eg:age = input("请输入你的年龄")
如果你是输入20输出就是:“20” 会加上引号 所以 input输出的都是字符串 如果是数字 它会默认把数字加上引号
六、循环
循环是为了让你的计算更加的高效率更加的便捷化
if循环:
一般的学过其他的语言的小鲜肉们肯定知道都是有什么if...else之类的 这个也差不多 。如果没学过的老腊肉也不要着急 ,因为这个很简单的(虽然我学起来不简单 可能我特么脑子不够吧)
if 判断语句 :
输出语句 (切记判断语句后的:英文输入法的分号 必须要有的)
if 判断语句 :
输出语句
elif 判断语句:
输出语句
if 条件: 满足条件执行代码 elif 条件: 上面的条件不满足就走这个 elif 条件: 上面的条件不满足就走这个 elif 条件: 上面的条件不满足就走这个 else: 上面所有的条件不满足就走
if 条件 :
满足条件执行的代码
else :
不满足条件执行的代码
也可以if elif else 一起使用
if 条件 :
满足条件执行的代码
elif 条件:
满足条件执行的代码
else
不满足执行的代码
建立一个循环小语句 weather = input(“请输入天气”) #使用人机交互模式定义判断一个变量 if weather == "阴天": #当天气不满足时候 就执行这一句 print(“回去找找妈妈”) elif weather == “晴朗” :#天气满足输出这一个 print(“可以出去大保健”) else: print(“滚回去 不许出去”)
while循环
while循环其实也就是比if 循环多那么一点点的小的功能的,毕竟尺有所短寸有所长,所以我们也可以用while来做一些不同的事情的,这个就要视情况而定了
while 条件:
# 循环体 # 如果条件为真,那么循环体则执行 # 如果条件为假,那么循环体不执行while循环还可以和else相结合,不过这种用的比较少 但是 我们还是要了解的
如果whiel循环被break打断了 那么整个循环都不走else的语句
while 判断条件:
满足时候执行的内容
else:
不满足执行的内容
循环中止语句:
大家可以思考下 都有循环 肯定也应该有终止循环的语句,因为不能一直让循环语句一直继续下去啊,所以break和continue就此诞生了。
break是终止使用它的循环,而continue是终止这一个语句 使程序回到起始点开始重新执行
个人小练习:
使用while输出 1 2 3 4 5 6 8 9 10
num = 0 while num < 10 : num +=1 if num == 7 : continue else : print(num)
求 1-100 所有数的和
#首先你肯定要定义两个变量一个用来表示 1-100内的所有的数字 然后再定义一个变量 用来表示 这些数字的总和 num= 1 y = 0
while num <= 100 : y = num +y if num == 100 : break num += 1 print(y)
求 100 以内的所有的奇数
num = 1 while num <= 100 : if num % 2 == 1 : print(num) num += 1
求 100 以内 所有的偶数
num = 1 while num <= 100 : if num % 2 == 0 : print(num) num += 1
求100以内所有的奇数的和
num = 1 y = 0 while num <=100 : if num %2 == 1 : y = y+num num +=1 print (y)
求1-2+3-4+5 ... 99的所有数的和
x = 1 y = 0 while x < 100 : if x %2 == 0: y = y -x elif x %2 != 0 : y = y +x x +=1 print (y)
打印一个三角形
x = 0 while x < 5 : x+=1 print("*"*x)
打印一个矩形
x= 0 while x < 5 : y = 0 while y < 5 : print("*",end = "") y +=1 print("") x += 1
用while 嵌套来做一个 三角形
x = 1 while x <= 5 : y = 1 #这个y等于1 也是循环的画龙点睛之处 while y <= x: #这一步的y小于等于x是很重要的 print ("*",end="") y +=1 print("") x += 1
in ,not in
in 顾名思义就是在其里面的,not in 就是不在其里面 这两个绝大多数是判断是否在其里面 在里面就是in 不在就是not in 在看字面意思也该知道啊(我这么笨也该知道的,不清楚的请出门面壁去)
name = "wag 王" if w in name ; #用in 来判断语句 print("在里面的 是正确的") if e not in : #用not in 来当判断语句 print("没有 需要重新判断")
格式化输出:
大家可以想象下 你如果想打印出一整个区里面的人员的姓和 年龄符不符合领取补助的条件的话 你难道需要把每个人的都自己敲一遍 输出吗 ?NO,这样太low ,这个时候我们可以定义一个模板,输入一个人就打印出一个人的信息,但是这样需要定义一个模板 来让所有人都通用,此时就需要用到了占位符了 格式化输出 : %s 替字符串或者数字占位置,%d替数字占位置 一点记住 %s既可以替换 字符串 也可以替换 数字
name = input("请输入你的姓") age = int(input("输入您的年龄")) if name == "李" and age > 40 : msg = "您符号条件,您的姓名是:%s , 年龄是:%d" % (name , age ) #这个时候的%s就是为之前的字符串占位置 %d就是为数字占位置 为了方便大家的输出 print(msg) else : print("对不起 您的条件不符合 ")
练习2:
while True : name = input("name:") age = input("age:") sex = input("sex:") height = input("height:") msg = ''' --------%s info ------ name:%s age:%s sex:%s height:%s ------------------------- '''%(name,name,age,sex,height) print(msg)
如果想在打印中输出单纯的%符号 那么需要输入两个%%
#在格式化输出的中淡出的显示% 用%%解决 name = input('请输入您的姓名') age = input("请输入您的年龄") msg = '我叫 %s ,今年:%d岁 , 学习进度为1%%' % (name , int(age) ) #因为想打印出两个%%必须用%%来表示 print(msg)
%s既可以替换 字符串 也可以替换 数字:
name = "老王" age = 16 msg = "姓名:%s, 年龄:%s" % (name , age ) #此时就可以看出%s不仅仅只可以替代字符串 还可以替代数字 print(msg)
还有一个%r是把后面指向输出原样输出 连引号到打印出来:
也就是你定义的是字符串那么用了%r当作占位符的话 那么输出的也是 字符串类型的

逻辑运算符:( ) and or
运算顺序:()>not> and > or 先算()内的比较 再进行and的比较 再进行 or的比较
比较and 如果两边的结果都是True 就都是True 如果只有一个是True那么就是Flase

比较or 如果两边有一个是True那么就是True
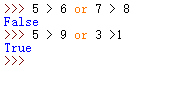
x or y if x True 则 return x 否则 return y 细细品味这段话真的很有味道 体会完成 你就全部理解这个运算符and 和or 的比较了
大家还要记得 所有的数字中只有0代表Flase 除了0哪怕负数 也都是True
如果or的比较 如果前面发现了是True那么后面的几乎不用看了就是True
 可以理解为因为0是Flase 但是3是True所以就是输出true就是输出3,第二个因为1就是True所以直接就输出1不看后面的了
可以理解为因为0是Flase 但是3是True所以就是输出true就是输出3,第二个因为1就是True所以直接就输出1不看后面的了
数据类型的转换:
int -----> bool 非0既True 0为False
bool-----> int True为 1 ,False 为0
什么是字符编码
因为计算机是外国人创造的所以计算机最开始只能识别最开始的基本数字(毕竟是外国人创造的所以最开始是不支持伟大的汉语 ,所以everybody努力学习吧 创造 我们自己的伟大的技术)
计算机要想工作必须通电,也就是说‘电’驱使计算机干活,而‘电’的特性,就是高低电平(高低平即二进制数1,低电平即二进制数0),也就是说计算机只认识数字
很明显,我们平时在使用计算机时,用的都是人类能读懂的字符(用高级语言编程的结果也无非是在文件内写了一堆字符),如何能让计算机读懂人类的字符?
必须经过一个过程:
字符--------(翻译过程)------->数字
这个过程实际就是一个字符如何对应一个特定数字的标准,这个标准称之为字符编码
以下两个场景下涉及到字符编码的问题:
1:一个python文件中的内容是由一堆字符组成的(python文件未执行的时候)
2:python 中的数据类型,字符串是由一串字符组成的(python文件执行的时候)
字符编码的发展史
阶段一:现代计算机起源于美国,最早诞生也是基于英文考虑的ASCII
ASCII:一个Bytes代表一个字符(英文字符/键盘上的所有其他字符),1Bytes=8bit,8bit可以表示0-2**8-1种变化,即可以表示256个字符
ASCII最初只用了后七位,127个数字,已经完全能够代表键盘上所有的字符了(英文字符/键盘的所有其他字符)
后来为了将拉丁文也编码进了ASCII表,将最高位也占用了
阶段二:为了满足中文,中国人定制了GBK
GBK:2Bytes代表一个字符
为了满足其他国家,各个国家纷纷定制了自己的编码
日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里
阶段三:各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。
于是产生了unicode, 统一用2Bytes代表一个字符, 2**16-1=65535,可代表6万多个字符,因而兼容万国语言
但对于通篇都是英文的文本来说,这种编码方式无疑是多了一倍的存储空间(二进制最终都是以电或者磁的方式存储到存储介质中的)
于是产生了UTF-8,对英文字符只用1Bytes表示,对中文字符用3Bytes
需要强调的一点是:
unicode:简单粗暴,所有字符都是2Bytes,优点是字符->数字的转换速度快,缺点是占用空间大
utf-8:精准,对不同的字符用不同的长度表示,优点是节省空间,缺点是:字符->数字的转换速度慢,因为每次都需要计算出字符需要多长的Bytes才能够准确表示
