------------------------------------------------mongodb简述---------------------------------------------------------





----------------------------------------------mongodb编译----------------------------------------------------------
本次课程运行环境介绍


cd mongo-r2.6.5 //进入目录
scons all //编译 , 如果编译失败,自行安装相关扩展如果多次失败,可以直接下载编译好的二进制文件
编译完成,看一下编译后的文件 ls
mongod 数据库执行程序
mongo 连接数据库的客户端
mongoimport mongoexport mongodb的导入导出
mongodump mongorestore 导入导出的二进制数据,不能被直接读取,一般做数据备份和恢复
mongooplog 操作日志回访,复制集会用到
mongostat 查看mongo服务器的各种状态,监控部分会用到
其他的可以查看官方文档
----------------------------------------------------------搭建mongodb服务器-------------------------------------------

mkdir mongodb_simple
cd mongodb_simple
mkdir data
mkdir log
mkdir conf
mkdir bin
cp ../mongo-r2.6.5/mongod bin/ //先将准备好的mongod 程序拷贝到bin目录下
cd conf/
vim mongod.conf 在这个文件中我们将输入mongodb启动的配置参数

port //mongodb启动时要监听的端口
dbpath //mongod数据存储的目录,可以使用相对或者绝对路径
logpath //需要指明一个实际的文件
fork = true //在linux下启动后台进程,win下无效
wq 保存
cd .. 进入上层目录
./bin/mongod -f conf/mongod.conf //指定初始化所使用的配置文件
显示以下信息说明被成功初始化

cd data //查看目录下生成的文件
ls

cd ../log
ls

tail mongod.log //查看日志,mongod已经在正常打印日志

mongo服务就搭建好了
看一下视频中完整的截图

----------------------------------------------用客户端进行连接--------------------------------------------------------------------
cd mongodb_simp/ //进入安装好的mongo文件
cp ../mongo-r2.6.5/mongo bin/ //为方便操作将编译文件中的 mongo 拷贝到 bin 目录下
./bin/mongo --help //查看mongo 的使用说明
版本号, 连接mongo的几种方式。

用户名密码,因为我们没有用户名密码暂时先不输入
![]()
./bin/mongo 127.0.0.1:12345/test
db.shutdownServer() //关闭mongod服务,需要admin权限
-----------------------------------
numactl 服务报出的错误
此处的错误提示意思是,要禁用 numactl 否则将影响性能

db.shutdownServer() //关闭mongo服务 需要使用admin权限,参照下图
(kill命令也可以关闭服务。kill -15。最好不要用kill -9)

numactl --interleave=all bin/mongod -f conf/mongod.conf //重新启动mongod服务
./bin/mongo 127.0.0.1:12345/test //再次连接没有报出警告
---------------------------------------------
---------------------------------------------mongo基本数据库操作-------------------------------------------------------------------
./bin/mongo 127.0.0.1:12345 //连接mongod服务
show dbs //显示mongod 中的数据库
use imooc //使用数据库
show collections //查看当前数据库的集合
db.dropDatabase() //删除当前的数据库
创建数据库, 需要的时候会自己创建。
写入,用的是json格式 db.集合名.动作({json数据})
db.imooc_collection.insert({x:1}) //向imooc_collection插入x:1的文档
db.imooc_collection.find() //默认为空,默认返回所有数据
_id 是mongo生成的字段,不可以重复
db.imooc_collection.insert({_id:1,x:2}) //插入_id为1的数据
error : db.imooc_collection.insert({_id:1,x:3}) //_id重复会报错
db.imooc_collection.find({x:1}) //查询x为1 的数据
for(i=3;i<100;i++)db.imooc_collection.insert({x:1}) //将插入97条数据
db.imooc_collection.count() //查询有多少条数据
db.imooc_collection.find().skip().limit().sort({x:1}) //skip 跳过多少条数据,limit 返回多少条数据, sort 根据“x” 的正序排序 1代表的是正序
db.imooc_collection.update({x:1},{x:999}) //将x为1 的数据 更新城 x为999
db.imooc_collection.update({x:1},$set{x:999}) //如果要更新部分字段,其他字段保持不变。$set 只更新存在的部分,其他字段不变
db.imooc_collection.update({y:100},{y:999}) //更新一条不存在的数据,y:100 并不存在,修改完后find()查询y:999并不存在
db.imooc_collection.update({y:100},{y:999},true) //更新一条不存在的数据,如果不存在则创建使用true , find()查询y:999存在
假设现在有3条{c:1}的数据
db.imooc_collection.update({c;1},{c:2}) //只会更新第一条数据,这么设计是为了放着误操作
db.imooc_collection.update({c:1},{$set{c:2}},false,true) //更新所有{c:1}的数据
db.imooc_collection.remove() //不传递参数,会报错。 remove必须有参数
db.imooc_collection.remove({c:1}) //默认删除所有数据
db.imooc_collection.drop() //删除文档
db.imooc_collection.find({x{$exists:true}}) //查找只存在x字段的记录

索引
数据量较小时,不使用索引查询是很快的。数据量较大时,不使用索引查询会变得非常缓慢,几千万,几亿条数据,不适用索引,将无法返回相应的结果。
如果文档索引数目较多,创建索引需要消耗一定时间。如果负载较重,不能直接创建索引,需要在使用之前就创建索引。
性能会大幅度提高,常用的查询需要创建索引,影响写入和更新。
对已存在的索引再次进行创建,直接返回成功。
索引的分类
db.imooc_collection.getIndexes() //查询集合的索引情况
db.imooc_collection.ensureIndex({x:1}) // 给 x 建立索引, 1 为正向排序,-1 为逆向排序。




多键索引这个概念不太好理解,仔细阅读下面内容。
创建形式是一样的,都是 db.imooc_collection.ensureIndex({x:1}) 创建索引
但是值如果是数组,就是多键索引
db.imooc_collection.ensureIndex({x:1}) //创建索引
db.imooc_collection.insert({x:[1,2,3,4,5]}) //这里就是多键索引 , 他们只有值类型不相同
当索引的字段是数组时候,才会"自动的给数组内字段的每一个元素"设置索引,这才是多key索引,自动指的是给数组内部的元素自动设置;
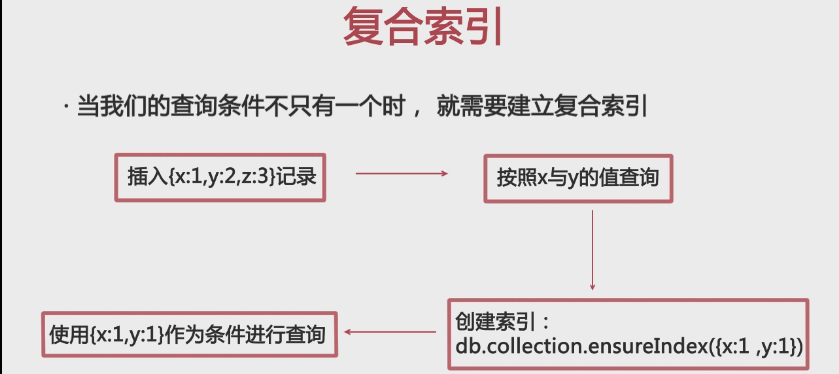
db.imooc_collection.ensureIndex({x:1,y:1}) //创建复合索引,x是字段名,1代表的是顺序,-1代表的是倒序
db.imooc_collection.find({x:1,y:2}) //就可以使用索引了

db.imooc_collection.ensureIndex({time:1},{expireAfterSconds:10}) // 设置10秒后过期,过期后数据自动删除
db.imooc_collection.insert({time:new Date()}) //将当前时间插入到数据库



db.articles.ensureIndex({key:"text"}) //在key这个字段上,创建“text” 全文索引
db.articles.ensureIndex({key_1:"text",key_2:"text"}) //创建多个 全文索引
db.articles.ensureIndex({"$**":"text"}) // $** 对集合中所有字段创建一个大的全文索引,创建“text” 全文索引

db.articles.find({$text:{$search:"coffee"}}) //最简单的使用全文索引
db.articles.find({$text:{$search:"aa bb cc"}}) //包含aa 或者 bb 或者 cc 的全文索引
db.articles.find({$text:{$search:"aa bb -cc"}}) // -cc 表示不包含cc的字符串
db.articles.find({$text:{$search:""aa" "bb" "cc""}}) //加上双引号,表示 即包含 aa 又包含 bb 又包含cc 的字符串,双引号需要转义
有时候百度查询,与你查询越相关的越排在前面。 mongo不仅能告诉你相似的查询文档,还能告诉你有多相似
全文索引相似度

score是相似度,后面是相似度的值

根据相似度排序,用sort来实现


------------------------------------------------索引的属性-------------------------------------------------------------------


名字,name指定
db.imooc_2.ensureIndex({x:1}) //创建一个单键索引
db.imooc_2.getIndexes() //获取索引的名字
名字的格式是 "键" + "_" + "排序方式"
复合索引 ("键" + "_" + "排序方式") + ("_") + ("键" + "_" + "排序方式")例:x_1_y_1
名字的长度最大是125字节
为了避免超限,可以自定义索引名字
db.imooc_2.ensureIndex({x:1,y:1,z:1,m:1},{name:"normal_index"})
删除索引的时候也可以直接使用索引的名字
db.imooc_2.dropIndex("normal_index")

倒序

复合索引

索引自定义命名


删除索引

唯一性,unique指定
db.imooc_2.ensureIndex({m:1,n:1},{unique:true}) //这个索引是唯一索引,不可以在同一个集合插入两条具有同一唯一索引的字段。
稀疏性,sparse指定
什么是稀疏:mongodb在处理索引中存在在,文档中不存在的两种方法。
例如: x字段创建了索引,但是插入了一条数据中并没有x字段,默认mongodb会为这个不存在的字段创建索引
如果你不想这件事情发生,就设置sparse:true来避免。
不必为不存在的数据创建索引,如果文档中这个字段很多都没有值,可以减少磁盘占用,会加快插入速度。
sparse:true是稀疏 false 不是稀疏 。 默认是不稀疏的,自行创建的索引都是不稀疏的
过期索引:会在一段时间后删除(参照上文的过期索引讲解)
-----------------------------------------地理位置索引-----------------------------------------------------------------------

区别:计算距离时。是计算平面距离,还是计算球面距离
创建方式,查询方式,支持的参数都有些不同

例如:打车软件查找附近的出租车, 或者查找附近的餐馆,都可以用距离某个点来查找
或者包含在哪个区域内的所有店铺
2D索引的创建方式
db.collection.ensureIndex({w:"2d"}) //创建2d索引
创建2d索引,字段的值一旦超过取值范围是不会报错的,但是会引起其他的错误,避免这样做
db.location.find({w:{$near:[1,1]}}) //$near 默认会返回100条距离最近的数据
db.location.find({w:{$near:[1,1]},$maxDistence:10}) //限制最远的距离 (通常会想到 $minDistence,但是这里并不起作用)
goWithin //查询形状内的点
db.location.find(w:{$goWithin:{$box[[0,0],[3,3]]}}) //goWithin 查询形状内的某个点。 $box 矩形[坐标] 。查询矩形中0,0 到3,3 的点
db.location.find(w:{$goWithin:{$center[[0,0],5]}}) //$center查找圆形中的某个点,0.0 是圆心的位置,5 是半径
db.location.find(w:{$goWithin:{$polygon[[0,0],[0,1],[2,5],[6,1]]}}) //查找多边形中的某个点
插入示例



geoNear返回了更多的数据,比如一些团购网


使用方式可以去查看文档
因为他支持多边形保存方式,查询某个性状中的点,或者某个多边形内交叉的点

---------------------------------------------------------索引构建评判分析---------------------------------------------------



mongostat --help
第一部分是参数
第二部分是返回值说明 Fields

mongostat 输出部分字段的含义: inserts/query/update/delete: 分别指当前mongodb插入、查询、更新、删除 数量,以每秒计; getmore: MongoDB返回结果时,每次只会返回一定量;当我们继续用find()查询更多数据时,系统就会自动用getmore来获取之后的数据; command: 执行的命令数量; flushes: MongoDB使用虚拟内存映射的方式管理数据,我们在向MongoDB写入或查询数据时,MongoDB会做一次虚拟内存映射,有些数据其实是在硬盘上的;每隔一段时间,MongoDB会把我们写到内存的数据flush到硬盘上;这个数据大的话,会导致mongodb的性能较差; mapped/vsize/res: 与磁盘空间大小有关,申请的内存大小; faults:如果我们查询的数据,没有提前被MongoDB加载到内存中,我们就必须到硬盘上读取,叫做“换页”;如果faults比较高,也会造成性能下降; idx miss: 表示我们的查询没有命中索引的比率;如果很高,说明索引构建有问题,索引不合适或者索引数量不够; qr|qw: 说明MongoDB的写队列或者读队列的情况。我们向MongoDB读写时,这些请求会被放到队列中等待。数量大(几百上千)说明MongoDB处理速度慢或者读写请求太多,性能会下降。 ar|aw: 当前活跃的读写客户端的个数。
示例:

性能分析工具mongostat -h ip地址:端口
查询结果中需要注意的表列值 qr/qw 表示读队列和写队列值,较高时数据库存在性能问题 idx miss 表示查询时索引命中情况,较高时影响查询效率
profile集合

查看当前数据库的profile状态
db.getProfilingStatus()
{ "was" : 0, "slowms" : 100 }
查看当前数据库的记录级别
db.getProfilingLevel()
0|1|2
设置当前数据库的profile记录级别
db.setProfilingLevel(0|1|2)
was --profile记录级别,0关闭,1记录所有超过slowms的慢查询,2记录所有操作
slowms --慢查询阀值
查看profile文件
如果profile数据量非差大,会影响数据库性能,一般是在上线前,或者刚上线的时候使用。
上线环境不建议运行
show tables //会多出两个集合
![]()
db.system.profile.find()

{ "op" : "query",--操作类型
"ns" : "imooc.system.profile", --集合的名字 // --查询的命名空间,;databasename.collectionname'
"query" : { "query" : { }, --查询条件
"orderby" : { "$natural" : -1 } }, --约束条件
"ntoreturn" : 1, --返回数据数目
"ntoskip" : 0, --跳过数条目
"nscanned" : 1, --扫描的数目 索引+实体
"nscannedObjects" : 1, --扫描的 实体 数据数目。如果扫描索引就能得到数据就不会扫描实体
"keyUpdates" : 0, --
"numYield" : 0, --其他情况
"lockStats" : { --锁状态
"timeLockedMicros" : { --锁占用时间(微秒)
"r" : NumberLong(82), --读锁
"w" : NumberLong(0) --写锁
},
"timeAcquiringMicros" : {
"r" : NumberLong(2), "w" : NumberLong(2)
}
},
"nreturned" : 1,
"responseLength" : 651, --返回长度
"millis" : 0, --查询时间
mongo日志设置,配置文件berbose参数,"v" 越多,详细度越高1-5个 "v"

vim conf/mongod.conf
verbose = vvvvv 日志记录级别
explain分析
会查询此次查询的详细信息

db.colltction.find({x:1}).explain()
{
"cursor" : "BasicCursor", --使用的索引
"isMultiKey" : false,
"n" : 1,
"nscannedObjects" : 100000, --扫描的数据量
"nscanned" : 100000, --包含索引的扫描量
"nscannedObjectsAllPlans" : 100000,
"nscannedAllPlans" : 100000,
"scanAndOrder" : false,
"indexOnly" : false,
"nYields" : 781,
"nChunkSkips" : 0,
"millis" : 25, --查询消耗时间(毫秒)
"server" : "XXX",
"filterSet" : false
}
cursor 如果使用索引会在后面显示 "BasicCursor" 就是没有使用索引 "BasicCursor x_1" 使用了x字段正序索引
millis 消耗时间越高,性能越差。
nscanned 扫描 索引+实体的 条数。 扫描的越高,性能越差

------------------------------------------------------------mongodb 安全------------------------------------------------------

物理隔离
物理隔离: 最安全的是物理隔离,任何手段都不能链接到我们的主机,这样是不现实的
网络隔离:开发及测试及都在自己的内网中,是比较安全的。
防火墙隔离: 配置只允许某些IP链接我的主机
用户名密码:安全机制比较弱,如果密码设计的不负责,可能会被别人尝试出来。我们还是大多是用用户名密码
默认mongodb并没有开启权限认证
开启认证的两种方法

vim conf/mongo.conf
auth = true //开启权限认证
ps -ef|grep mongod|grep 12345

kill 9528
./bin/mongod //重启mongod服务
创建用户

mame : 用户名
pwd:密码
customData :说明,对中文支持不太好
roles:[{role:角色类型,db:作用在哪个数据库上}]
角色类型可以设置为
read: 对指定的db,读取操作,
readWrite:读写操作,不可操作索引,不能删除数据库等;
dbAdmin:可对数据库类型进行操作,
dbOwner:具有前三个的权限;
userAdmin:可以管理其他用户权限
db.createUser({user:"imooc",pwd:"imooc",roles:[{role:"userAdmin",db:"admin"},{role:"read",db:"test"}]})
无密码还是可以登陆mongod 的。但是不能进行任何操作
./bin/mongo 127.0.0.1:12345 -u imooc -p imooc

1. 数据库用户角色:read、readWrite;
2. 数据库管理角色:dbAdmin、dbOwner、userAdmin;
3. 集群管理角色:clusterAdmin、clusterManager、clusterMonitor、hostManager;
4. 备份恢复角色:backup、restore;
5. 所有数据库角色:readAnyDatabase、readWriteAnyDatabase、userAdminAnyDatabase、dbAdminAnyDatabase
6. 超级用户角色:root
// 这里还有几个角色间接或直接提供了系统超级用户的访问(dbOwner 、userAdmin、userAdminAnyDatabase)
7. 内部角色:__system

createRole 来创建权限
_id: 唯一的id
role: 用户的权限名字
db:数据库的名字
privileges :在这个数据库中的权限操作
图中的第一个resource 解释
数据库myApp上, 任意集合 ,具有find...
logs 具有 insert 权限