最近接触一些大数据的测试,有些hadoop/spark任务在服务器测试不太方便,会放到azkaban上跑
简单写下azkaband的使用流程:包括任务的上传和提交任务到hadoop集群
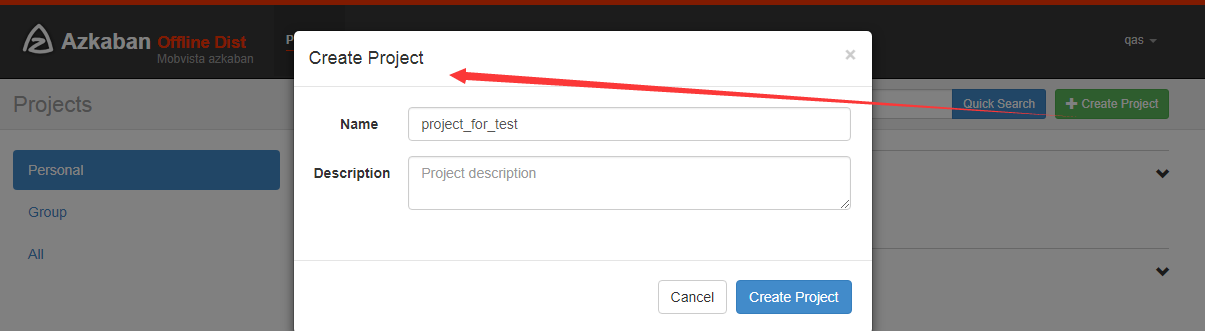
一 登陆azkaban,点击右上角,新建一个project
二 上传测试任务
此处有两种上传方式
1 手动压缩上传
①将自己的任务压缩成zip文件
②进入project,点击右上角的Upload,上传自己的压缩包

2 我偷了一个上传脚本,好吧,贴不过来,当我没说得了= =
三 执行任务
1 上传后在项目的Flow列表就会出现可执行任务,点开
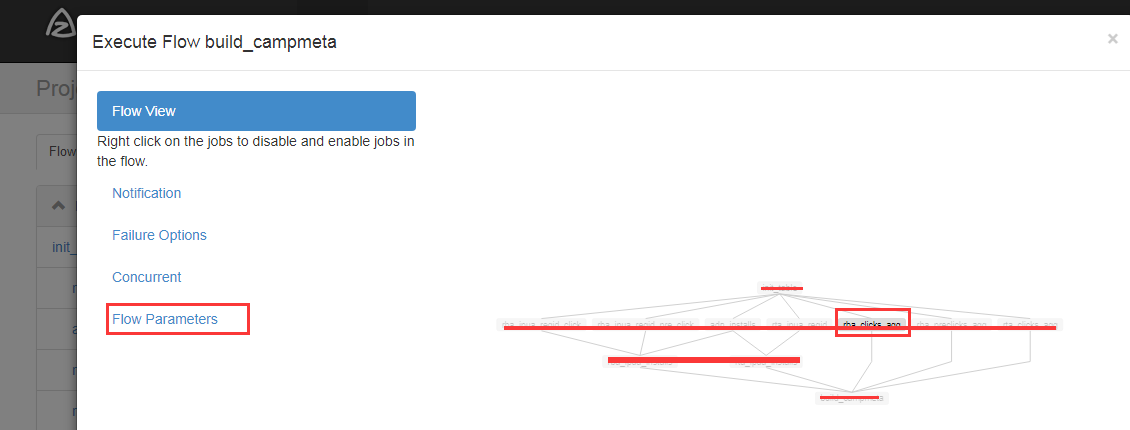
2 点开后可以看到好多job,每个job后有两个参数,一个是Run Job,一个是Run with dependency,选取后者会先执行该任务的依赖任务
3 点击Run Job,可以看到只有要执行的任务是有效状态,点击左侧的Flow Parameters -- > Add Row,添加运行需要的参数
4 执行右下角的Excute,即可成功提交任务到hadoop集群
若任务较为简单,也可以直接在linux服务器上执行sh yourshell.sh,也可以提交到服务器配置的hadoop集群

四 问题与解决
1 不同账号间可以共享同名的project,注意需要配置权限
进入project --> Pemissions --> User & Proxy User权限可以Add
话说我这样不算侵权或者泄密吧,不要有坏人看到哟