导读:etcd 是阿里巴巴内部容器云平台用于存储关键元信息的组件。阿里巴巴使用 etcd 已经有 3 年的历史, 在今年 双11 过程中它又一次承担了关键角色,接受了 双11 大压力的检验。为了让更多同学了解到 etcd 的最佳实践和阿里巴巴内部的使用经验,本文作者将和大家分享阿里巴巴是如何把 etcd 升级得更强、更稳、更高效的,希望通过这篇文章让更多人了解 etcd, 享受云原生技术带来的红利。
让 etcd 变得更强
本节主要介绍 etcd 在性能方面的升级工作。首先我们来理解一下 etcd 的性能背景。
性能背景
这里先庖丁解牛,将 etcd 分为如下几个部分,如下图所示:
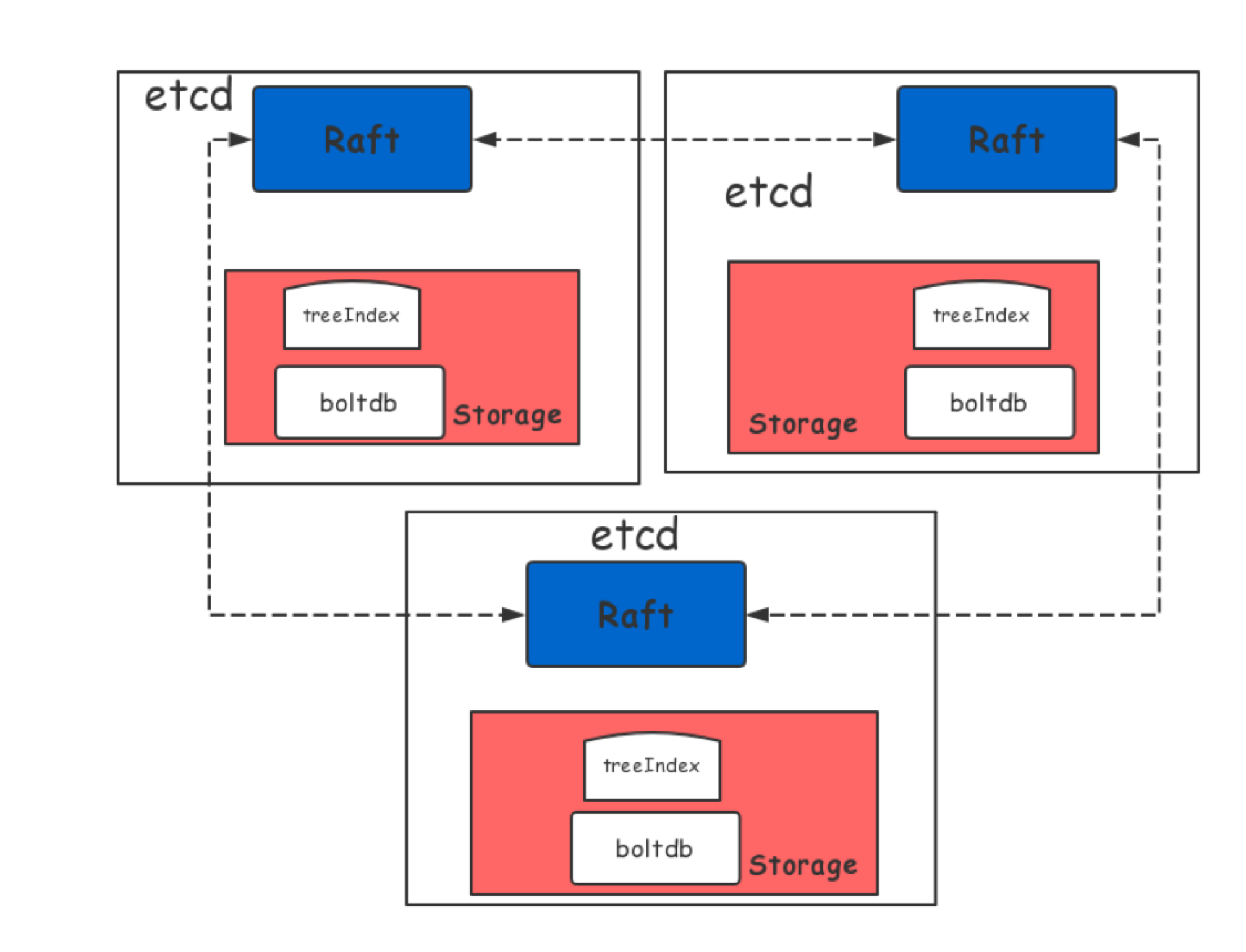
每一部分都有各自的性能影响,让我们逐层分解:
- raft 层:raft 是 etcd 节点之间同步数据的基本机制,它的性能受限于网络 IO、节点之间的 rtt 等, WAL 受到磁盘 IO 写入延迟;
- 存储层:负责持久化存储底层 kv, 它的性能受限于磁盘 IO,例如:fdatasync 延迟、内存 treeIndex 索引层锁的 block、boltdb Tx 锁的 block 以及 boltdb 本身的性能;
- 其他还有诸如宿主机内核参数、grpc api 层等性能影响因子。
服务端优化
了解完背景后,这里介绍一下性能优化手段,主要由服务端和客户端两个方面组成,这里先介绍服务端优化的一些手段。
硬件部署
etcd 是一款对 cpu、内存、磁盘要求较高的软件。随着内部存储数据量的增加和对并发访问量的增大,我们需要使用不同规格的硬件设备。这里我们推荐 etcd 至少使用 4 核 cpu、8GB 内存、SSD 磁盘、高速低延迟网络、独立宿主机部署等(具体硬件的配置信息)。在阿里巴巴,由于有超大规模的容器集群,因此我们运行 etcd 的硬件也较强。
软件优化
etcd 是一款开源的软件,集合了全世界优秀软件开发者的智慧。最近一年在软件上有很多贡献者更新了很多性能优化,这里分别从几个方面来介绍这些优化,最后介绍一个由阿里巴巴贡献的 etcd 存储优化。
- 内存索引层。由于索引层大量使用锁机制同步对性能影响较大,通过优化锁使用,提升了读写性能,具体参考:github pr;
- lease 规模化使用。lease 是 etcd 支持 key 使用 ttl 过期的机制。在之前的版本中 scalability 较差,当有大量 lease 时性能下降的较为严重,通过优化 lease revoke 和过期失效的算法,解决了 lease 规模性的问题,具体参考:github pr;
- 后端 boltdb 使用优化。etcd 使用 boltdb 作为底层数据库存储 kv, 它的使用优化对整体性能影响很大。
通过调节不同的 batch size 和 interval, 使我们可以根据不同硬件和工作负载优化性能,具体参考:github pr。
除此之外,新的完全并发读特性也优化了 boltdb tx 读写锁性能,大幅度地提升了读写性能,具体参考:github pr。
最后介绍一个由阿里巴巴自主研发并贡献开源社区的优化:基于 segregated hashmap 的 etcd 内部存储 freelist 分配回收算法。
下图是一个 etcd 节点的架构,etcd 使用 boltdb 持久化存储所有 kv,它的性能好坏对 etcd 性能起着非常重要的作用。
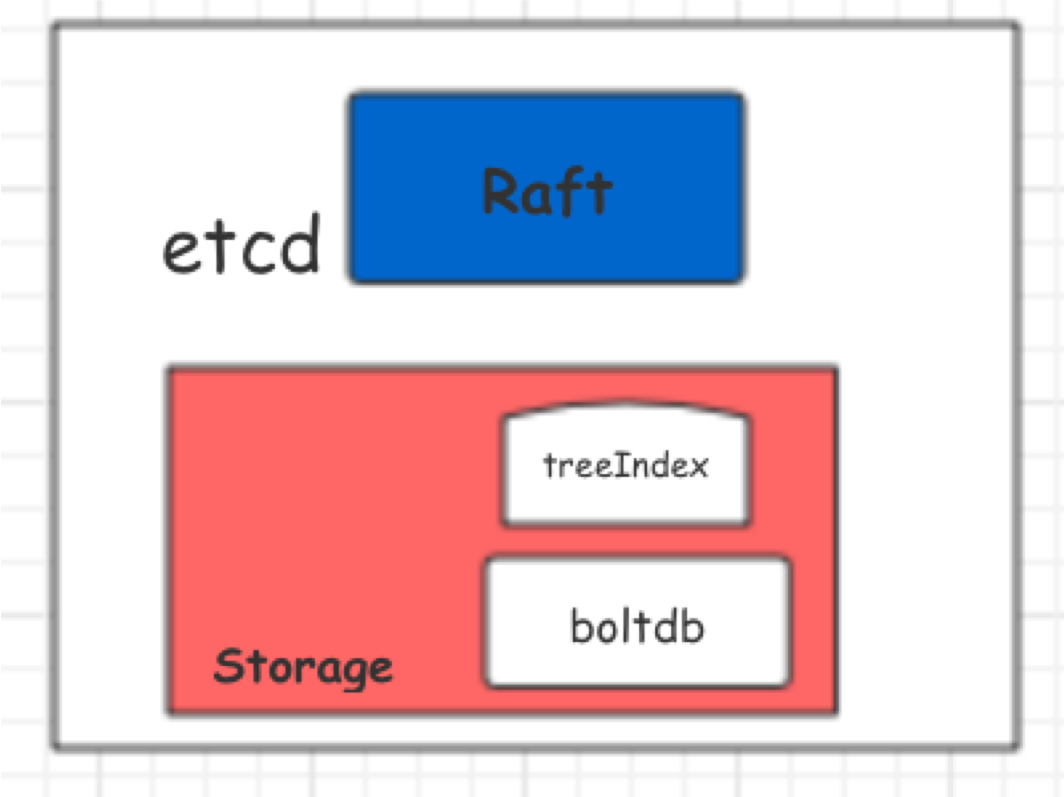
在阿里巴巴内部大规模使用 etcd 用于存储元数据,在使用中我们发现了 boltdb 的性能问题。这里给大家分享一下:
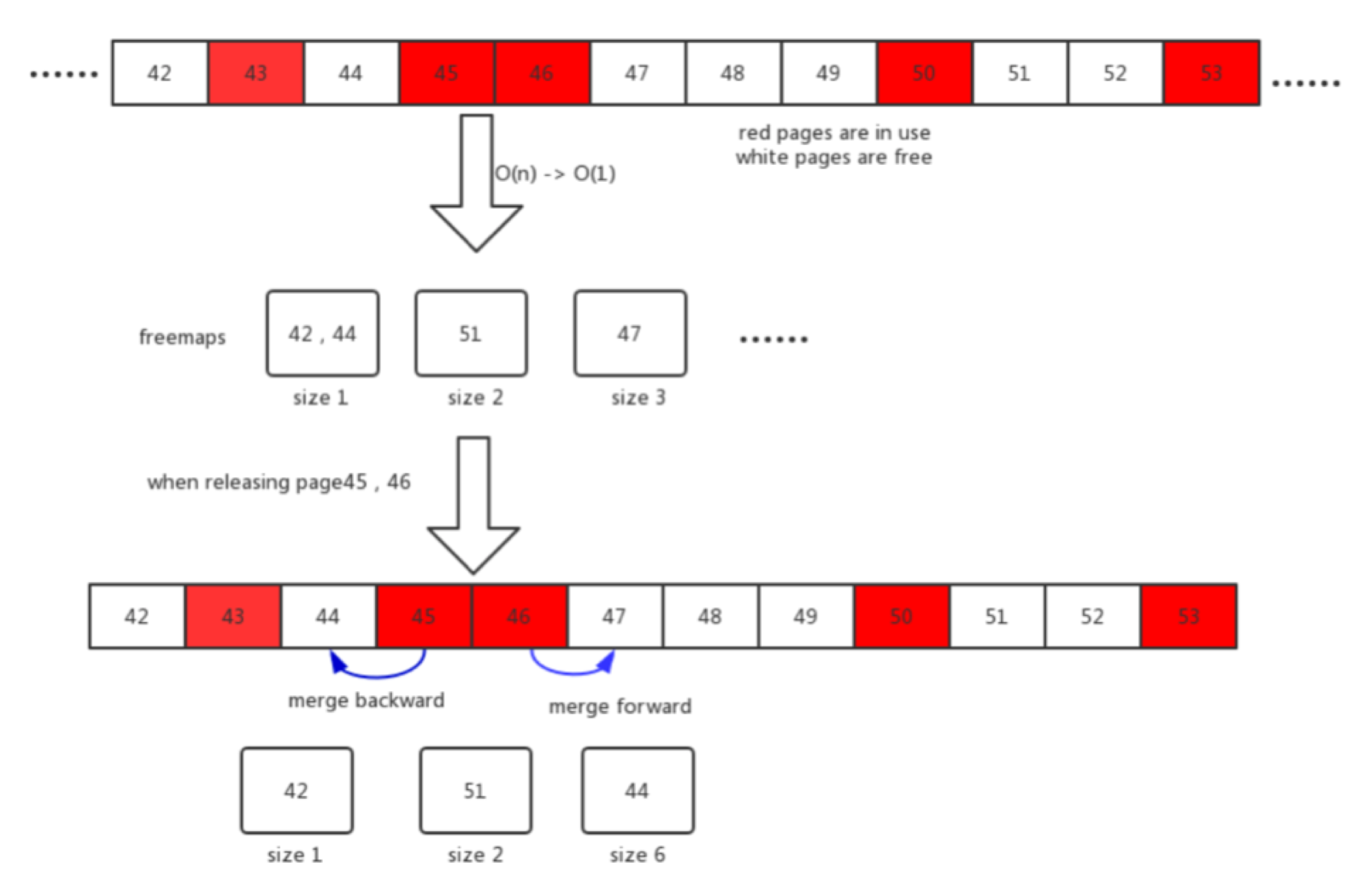
上图是 etcd 内部存储分配回收的核心算法。etcd 内部默认以 4kB 为一个页面大小存储数据。图中的数字表示页面 id, 红色表示该页面正在使用, 白色表示没有。当用户删除数据时 etcd 不会把存储空间还给系统,而是内部先留存起来维护一个页面池,以提升再次使用的性能,这个页面池专业术语叫 freelist。当 etcd 需要存储新数据时,普通 etcd 会线性扫描内部 freelist,时间复杂度 o(n),当数据量超大或是内部碎片严重的情况下,性能会急剧下降。
因此我们重新设计并实现了基于 segregated hashmap 的 etcd 内部存储 freelist 分配回收新算法,该优化算法将内部存储分配算法时间复杂度从 o(n) 降为 o(1), 回收从 o(nlgn) 也降为 o(1), 使 etcd 性能有了质的飞跃,极大地提高了 etcd 存储数据的能力,使得 etcd 存储容量提升 50 倍,从推荐的 2GB 提升到 100GB;读写性能提升 24 倍。CNCF 官方博客收录了此次更新,感兴趣的读者可以读一下。
客户端优化
性能优化除了服务端要做的事情外,还需要客户端的帮助。保持客户端使用最佳实践将保证 etcd 集群稳定高效地运行,这里我们分享 3 个最佳实践:
- put 数据时避免大的 value, 大的 value 会严重影响 etcd 性能,例如:需要注意 Kubernetes 下 crd 的使用;
- 避免创建频繁变化的 key/value, 例如:Kubernetes 下 node 数据上传更新;
- 避免创建大量 lease 对象,尽量选择复用过期时间接近的 lease, 例如 Kubernetes 下 event 数据的管理。
让 etcd 管理更高效
作为基于 raft 协议的分布式键值数据库,etcd 是一个有状态的应用。管理 etcd 集群状态、运维 etcd 节点、冷热备份、故障恢复等过程均有一定复杂性,且需要具备 etcd 内核相关的专业知识,想高效地运维 etcd 有不小的挑战。
目前在业界里已经有一些 etcd 运维的工具,例如开源的 etcd-operator 等,但是这些工具往往比较零散,功能通用性不强,集成度比较差,学习这些工具的使用也需要一定的时间,关键是这些工具不是很稳定,存在稳定性风险等。
面对这些问题,我们根据阿里巴巴内部场景,基于开源 etcd-operator 进行了一系列修改和加强,开发了 etcd 运维管理平台 Alpha。利用它,运维人员可以高效地运维管理 etcd,之前要前后操作多个工具完成的任务,现在只要操作它就可以完成,一个人就可以管理成百上千的 etcd 集群。
下图展示了 Alpha 的基础功能:
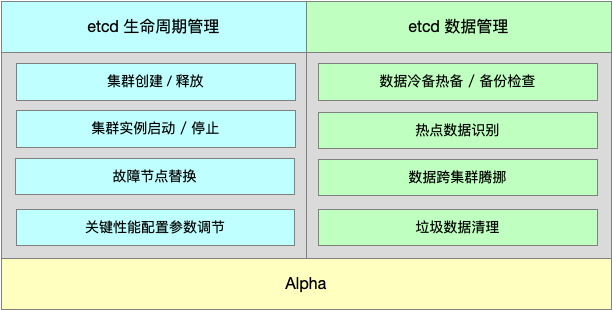
如上图所示,Alpha 分为 etcd 生命周期管理和数据管理两大部分。
其中生命周期管理功能依托于 operator 中声明式的 CustomResource 定义,将 etcd 的集群创建、销毁的过程流程化、透明化,用户不再需要为每个 etcd 成员单独制定繁琐的配置,仅需要指定成员数量、成员版本、性能参数配置等几个简单字段。除此之外,我们还提供了 etcd 版本升级、故障节点替换、集群实例启停等功能,将 etcd 常用的运维操作自动化,同时也在一定程度上保证了 etcd 变更的稳定性。
其次,数据作为 etcd 的核心内容,我们也开发了一系列功能进行重点保障。在备份上,数据管理工具支持定期冷备及实时热备,且保持本地盘和云上 OSS 两类备份,同时也支持从备份上快速恢复出一个新的 etcd 集群。此外,数据管理工具支持对 etcd 进行扫描分析,发现当前集群的热点数据键值数和存储量,弥补了业界无法提供数据管理的空白,同时该拓展也是 etcd 支持多租户的基础。最后,数据管理工具还支持对 etcd 进行垃圾数据清理、跨集群数据腾挪传输等功能。
这些丰富的功能为上层 Kubernetes 集群的管理提供了很多灵活的帮助,例如用户 A 原来在某云厂商或自建 Kubernetes 集群,我们可以通过迁移 etcd 内部的账本数据的功能,将用户的核心数据搬移至另外一个集群,方便地实现用户的 K8s 集群跨云迁移。
利用 Alpha,我们可以做到透明化、自动化、白屏化,减少人肉黑屏操作,让 etcd 运维管理更高效。
让 etcd 变得更稳
本节主要介绍一些 etcd 稳定建设的技巧。大家知道 etcd 是容器云平台的底层依赖核心,它的服务质量、稳定程度决定了整个容器云的稳定程度,其重要性无需赘述。这里先介绍一下 etcd 常见的问题和风险分析,如下图所示,主要分三个方面:
- etcd 自身:例如 OOM、代码 bug、panic 等;
- 宿主机环境:例如宿主机故障、网络故障、同一台宿主机其他进程干扰;
- 客户端:例如客户端 bug、运维误操作、客户端滥用 ddos 等。
针对这些风险点,我们从以下几方面入手:
- 建立完善的监控告警机制,覆盖客户端输入,etcd 自身以及宿主机环境状态;
- 客户操作审计,高危操作如删除数据做风控限流;
- 数据治理,分析客户端滥用,引导最佳实践;
- 定期数据冷备,通过热备实现异地多活,保证数据安全;
- 常态化故障演练,做好故障恢复预案。
总结展望:让 etcd 变得更智能
本文分别从性能、稳定性、生态工具三个部分享了 etcd 变得更强、更快、更高效的技巧。在未来我们还将为让 etcd 变得更智能而努力。如何让 etcd 变得更智能是一个比较高级的话题,这里简单做一下展望。更智能的意思是指可以使 etcd 的管理更加地聪明,更少的人为干预,例如遇到一些故障,系统可以自行修复等。
本文作者:陈星宇(宇慕)
本文为云栖社区原创内容,未经允许不得转载。