概述
互联网应用发展到今天,从单体应用架构到SOA以及今天的微服务,随着微服务化的不断升级进化,服务和服务之间的稳定性变得越来越重要,分布式系统之所以复杂,主要原因是分布式系统需要考虑到网络的延时和不可靠,微服务很重要的一个特质就是需要保证服务幂等,保证幂等性很重要的前提需要分布式锁控制并发,同时缓存、降级和限流是保护微服务系统运行稳定性的三大利器。
随着业务不断的发展,按业务域的划分子系统越来越多,每个业务系统都需要缓存、限流、分布式锁、幂等工具组件,distributed-tools组件(暂未开源)正式包含了上述分布式系统所需要的基础功能组件。
distributed-tools组件基于tair、redis分别提供了2个springboot starter,使用起来非常简单。
以使用缓存使用redis为例,application.properties添加如下配置
redis.extend.hostName=127.0.0.1
redis.extend.port=6379
redis.extend.password=pwdcode
redis.extend.timeout=10000
redis.idempotent.enabled=true
接下来的篇幅,重点会介绍一下缓存、限流、分布式锁、幂等的使用方式。
缓存
缓存的使用可以说无处不在,从应用请求的访问路径来看,用户user -> 浏览器缓存 -> 反向代理缓存-> WEB服务器缓存 -> 应用程序缓存 -> 数据库缓存等,几乎每条链路都充斥着缓存的使用,缓存最直白的解释就是“用空间换时间”的算法。缓存就是把一些数据暂时存放于某些地方,可能是内存,也有可能硬盘。总之,目的就是为了避免某些耗时的操作。我们常见的耗时的操作,比如数据库的查询、一些数据的计算结果,或者是为了减轻服务器的压力。其实减轻压力也是因查询或计算,虽然短耗时,但操作很频繁,累加起来也很长,造成严重排队等情况,服务器抗不住。
distributed-tools组件提供了一个CacheEngine接口,基于Tair、Redis分别有不同的实现,具体CacheEngine定义如下:
public String get(String key);
/**
* 获取指定的key对应的对象,异常也会返回null
*
* @param key
* @param clazz
* @return
*/
public <T> T get(String key, Class<T> clz);
/**
* 存储缓存数据,忽略过期时间
*
* @param key
* @param value
* @return
*/
public <T extends Serializable> boolean put(String key, T value);
/**
* 存储缓存数据
*
* @param key
* @param value
* @param expiredTime
* @param unit
* @return
*/
public <T extends Serializable> boolean put(String key, T value, int expiredTime, TimeUnit unit);
/**
* 基于key删除缓存数据
*
* @param key
* @return
*/
public boolean invalid(String key);
get方法针对key进行查询,put存储缓存数据,invalid删除缓存数据。
限流
在分布式系统中,尤其面对一些秒杀、瞬时高并发场景,都需要进行一些限流措施,保证系统的高可用。通常来说限流的目的是通过对并发访问/请求进行限速,或者一个时间窗口内的的请求进行限速来保护系统,一旦达到限制速率则可以 拒绝服务(定向到错误页或告知资源没有了)、排队 或 等待(比如秒杀、评论、下单)、降级(返回托底数据或默认数据,如商品详情页库存默认有货)。
常见的一些限流算法包括固定窗口、滑动窗口、漏桶、令牌桶,distributed-tools组件目前基于计数器只实现了固定窗口算法,具体使用方式如下:
/**
* 指定过期时间自增计数器,默认每次+1,非滑动窗口
*
* @param key 计数器自增key
* @param expireTime 过期时间
* @param unit 时间单位
* @return
*/
public long incrCount(String key, int expireTime, TimeUnit unit);
/**
* 指定过期时间自增计数器,单位时间内超过最大值rateThreshold返回true,否则返回false
*
* @param key 限流key
* @param rateThreshold 限流阈值
* @param expireTime 固定窗口时间
* @param unit 时间单位
* @return
*/
public boolean rateLimit(final String key, final int rateThreshold, int expireTime, TimeUnit unit);基于CacheEngine的rateLimit方法可以实现限流,expireTime只能设定固定窗口时间,非滑动窗口时间。
另外distributed-tools组件提供了模板RateLimitTemplate可以简化限流的易用性,可以直接调用RateLimitTemplate的execute方法处理限流问题。
/**
* @param limitKey 限流KEY
* @param resultSupplier 回调方法
* @param rateThreshold 限流阈值
* @param limitTime 限制时间段
* @param blockDuration 阻塞时间段
* @param unit 时间单位
* @param errCodeEnum 指定限流错误码
* @return
*/
public <T> T execute(String limitKey, Supplier<T> resultSupplier, long rateThreshold, long limitTime,
long blockDuration, TimeUnit unit, ErrCodeEnum errCodeEnum) {
boolean blocked = tryAcquire(limitKey, rateThreshold, limitTime, blockDuration, unit);
if (errCodeEnum != null) {
AssertUtils.assertTrue(blocked, errCodeEnum);
} else {
AssertUtils.assertTrue(blocked, ExceptionEnumType.ACQUIRE_LOCK_FAIL);
}
return resultSupplier.get();
}另外distributed-tools组件还提供了注解@RateLimit的使用方式,具体注解RateLimit定义如下:
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
@Documented
public @interface RateLimit {
/**
* 限流KEY
*/
String limitKey();
/**
* 允许访问的次数,默认值MAX_VALUE
*/
long limitCount() default Long.MAX_VALUE;
/**
* 时间段
*/
long timeRange();
/**
* 阻塞时间段
*/
long blockDuration();
/**
* 时间单位,默认为秒
*/
TimeUnit timeUnit() default TimeUnit.SECONDS;
}基于注解的方式限流使用代码如下:
@RateLimit(limitKey = "#key", limitCount = 5, timeRange = 2, blockDuration = 3, timeUnit = TimeUnit.MINUTES)
public String testLimit2(String key) {
..........
return key;
}任何方法添加上述注解具备了一定的限流能力(具体方法需要在spring aop指定拦截范围内),如上代码表示以参数key作为限流key,每2分钟请求次数不超过5次,超过限制后阻塞3分钟。
分布式锁
在Java单一进程中通过synchronized关键字和ReentrantLock可重入锁可以实现在多线程环境中控制对资源的并发访问,通常本地的加锁往往不能满足我们的需要,我们更多的面对场景是分布式系统跨进程的锁,简称为分布式锁。分布式锁实现手段通常是将锁标记存在内存中,只是该内存不是某个进程分配的内存而是公共内存如Redis、Tair,至于利用数据库、文件等做锁与单机的实现是一样的,只要保证标记能互斥就行。分布式锁相对单机进程的锁之所以复杂,主要原因是分布式系统需要考虑到网络的延时和不可靠。
distributed-tools组件提供的分布式锁要具备如下特性:
互斥性:同本地锁一样具有互斥性,但是分布式锁需要保证在不同节点进程的不同线程的互斥。
可重入性:同一个节点上的同一个线程如果获取了锁之后那么也可以再次获取这个锁。
锁超时:和本地锁一样支持锁超时,防止死锁,通过异步心跳demon线程刷新过期时间,防止特殊场景(如FGC死锁超时)下死锁。
高性能、高可用:加锁和解锁需要高性能,同时也需要保证高可用防止分布式锁失效,可以增加降级。
支持阻塞和非阻塞:同ReentrantLock一样支持lock和trylock以及tryLock(long timeOut)。
公平锁和非公平锁(不支持):公平锁是按照请求加锁的顺序获得锁,非公平锁就相反是无序的,目前distributed-tools组件提供的分布式锁不支持该特性。
distributed-tools组件提供的分布式锁,使用起来非常简单,提供了一个分布式锁模板:DistributedLockTemplate,可以直接调用模板提供的静态方法(如下):
/**
* 分布式锁处理模板执行器
*
* @param lockKey 分布式锁key
* @param resultSupplier 分布式锁处理回调
* @param waitTime 锁等待时间
* @param unit 时间单位
* @param errCodeEnum 指定特殊错误码返回
* @return
*/
public static <T> T execute(String lockKey, Supplier<T> resultSupplier, long waitTime, TimeUnit unit,
ErrCodeEnum errCodeEnum) {
AssertUtils.assertTrue(StringUtils.isNotBlank(lockKey), ExceptionEnumType.PARAMETER_ILLEGALL);
boolean locked = false;
Lock lock = DistributedReentrantLock.newLock(lockKey);
try {
locked = waitTime > 0 ? lock.tryLock(waitTime, unit) : lock.tryLock();
} catch (InterruptedException e) {
throw new RuntimeException(String.format("lock error,lockResource:%s", lockKey), e);
}
if (errCodeEnum != null) {
AssertUtils.assertTrue(locked, errCodeEnum);
} else {
AssertUtils.assertTrue(locked, ExceptionEnumType.ACQUIRE_LOCK_FAIL);
}
try {
return resultSupplier.get();
} finally {
lock.unlock();
}
}幂等
在分布式系统设计中幂等性设计中十分重要的,尤其在复杂的微服务中一套系统中包含了多个子系统服务,而一个子系统服务往往会去调用另一个服务,而服务调用服务无非就是使用RPC通信或者restful,分布式系统中的网络延时或中断是避免不了的,通常会导致服务的调用层触发重试。具有这一性质的接口在设计时总是秉持这样的一种理念:调用接口发生异常并且重复尝试时,总是会造成系统所无法承受的损失,所以必须阻止这种现象的发生。
幂等通常会有两个维度:
1. 空间维度上的幂等,即幂等对象的范围,是个人还是机构,是某一次交易还是某种类型的交易。
2. 时间维度上的幂等,即幂等的保证时间,是几个小时、几天还是永久性的。
在实际系统中有很多操作,不管操作多少次,都应该产生一样的效果或返回相同的结果。以下这些应用场景也是通常比较常见的应用场景:
1. 前端重复提交请求,且请求数据相同时,后台需要返回对应这个请求的相同结果。
2. 发起一次支付请求,支付中心应该只扣用户账户一次钱,当遇到网络中断或系统异常时,也应该只扣一次钱。
3. 发送消息,同样内容的短信发给用户只发一次。
4. 创建业务订单,一次业务请求只能创建一个,重试请求创建多个就会出大问题。
5. 基于msgId的消息幂等处理
在正式使用distributed-tools组件提供的幂等之前,我们先看下distributed-tools幂等组件的设计。
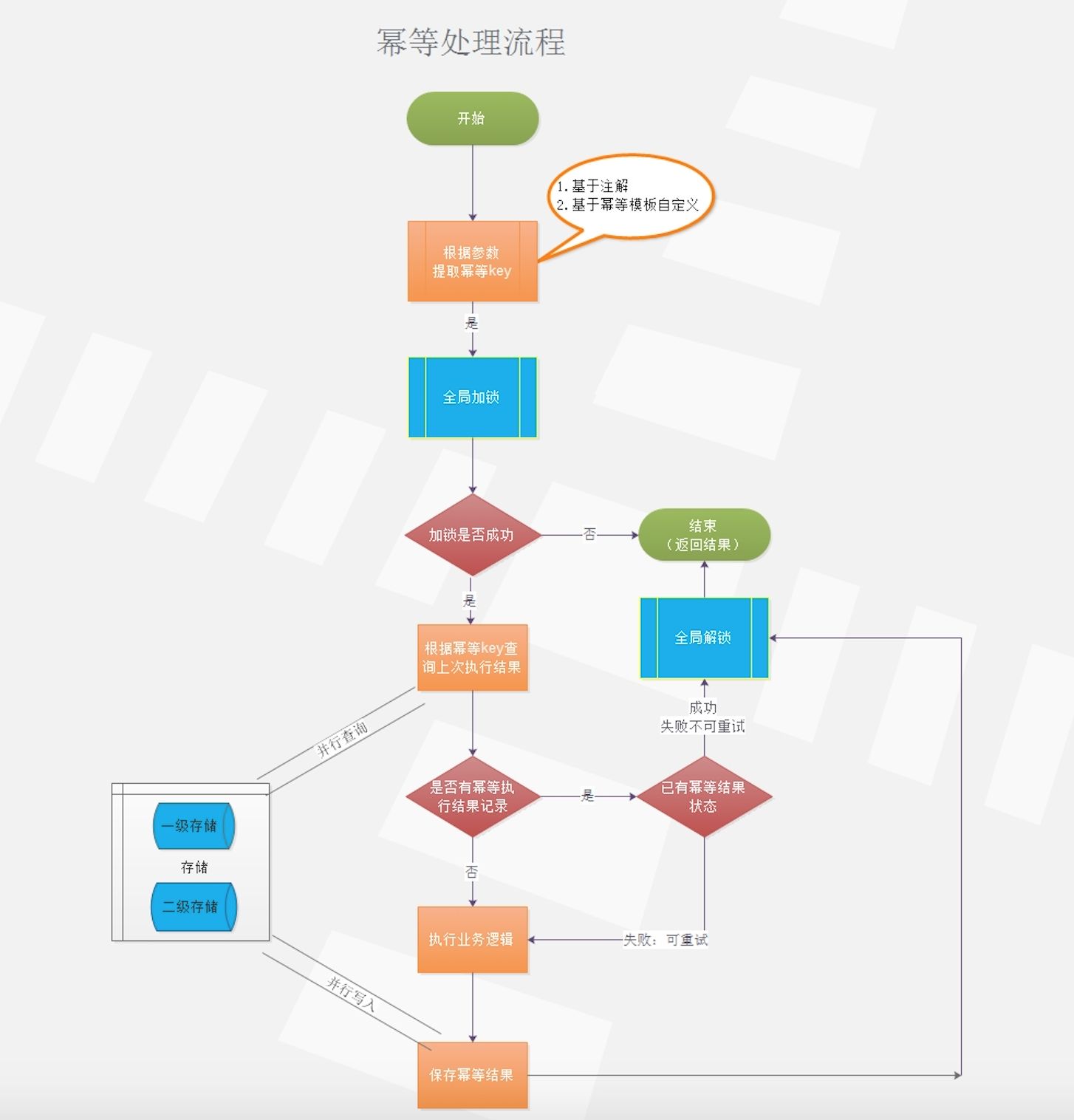
- 幂等key提取能力:获取唯一幂等key
幂等key的提取支持2中注解:IdempotentTxId、IdempotentTxIdGetter,任意方法添加以上2注解,即可提取到相关幂等key,前提条件是需要将Idempotent注解添加相关需要幂等的方法上。
如果单纯使用幂等模板进行业务处理,需要自己设置相关幂等key,且要保证其唯一性。
- 分布式锁服务能力:提供全局加锁、解锁的能力
distributed-tools幂等组件需要使用自身提供的分布式锁功能,保证其并发唯一性,distributed-tools提供的分布式锁能够提供其可靠、稳定的加锁、解锁能力。
- 高性能的写入、查询能力:针对幂等结果查询与存储
distributed-tools幂等组件提供了基于tair、redis的存储实现,同时支持自定义一级、二级存储通过spring依赖注入到IdempotentService,建议distributed-tools幂等存储结果一级存储tair mdb,二级存储ldb或者tablestore,一级存储保证其高性能,二级存储保证其可靠性。
二级存储并行查询会返回查询最快的幂等结果。
二级存储并行异步写入,进一步提高性能。
- 高可用的幂等写入、查询能力:幂等存储出现异常,不影响业务正常流程,增加容错
distributed-tools幂等组件支持二级存储,为了保证其高可用,毕竟二级存储出现故障的概率太低,不会导致业务上不可用,如果二级存储同时出现故障,业务上做了一定的容错,针对不确定性的异常采取重试策略,会执行具体幂等方法。
一级存储与二级存储的写入与查询处理进行隔离,任何一级存储的异常不会影响整体业务执行。
在了解了distributed-tools组件幂等之后,接下来我们来看下如何去使用幂等组件,首先了解下common-api提供的幂等注解,具体幂等注解使用方式如下:
| 注解定义 | 使用范围 | 使用描述 |
|---|---|---|
| Idempotent | 方法 | Idempotent需要定义到具体Method上。Idempotent有个属性定义: expireDate表示幂等有效期,默认30天。 spelKey表示可以使用spring表达式生成幂等唯一ID,比如直接获取到对象属性或者方法或者其他表达式。 |
| IdempotentTxId | 参数、对象属性 | IdempotentTxId可以直接定义到方法参数或者参数对象属性上,直接获取幂等ID |
| IdempotentTxIdGetter | 方法 | IdempotentTxIdGetter可以直接定义参数对象的方法上,调用该方法获取幂等ID |
幂等拦截器获取幂等ID的优先级:
- 首先判断Idempotent的spelKey的属性是否为空,如果不为空会根据spelKey定义的spring表达式生成幂等ID。
- 其次判断参数是否包含IdempotentTxId注解,如果有IdempotentTxId,会直接获取参数值生成幂等ID。
- 再次通过反射获取参数对象属性是否包含IdempotentTxId注解,如果对象属性包含IdempotentTxId注解会获取该参数对象属性生成幂等ID。
- 最后以上三种情况仍未获取到幂等ID,会进一步通过反射获取参数对象的Method是否定义IdempotentTxIdGetter注解,如果包含该注解则通过反射生成幂等ID。
代码使用示例:
@Idempotent(spelKey = "#request.requestId", firstLevelExpireDate = 7,secondLevelExpireDate = 30)
public void execute(BizFlowRequest request) {
..................
}如上述代码表示从request获取requestId作为幂等key,一级存储有效期7天,二级存储有效期30天。
distributed-tools除了可以使用幂等注解外,幂等组件还提供了一个通用幂等模板IdempotentTemplate,使用幂等模板的前提必须设置tair.idempotent.enabled=true或者redis.idempotent.enabled=true,默认为false,同时需要指定幂等结果一级存储,幂等结果存储为可选项配置。
具体使用幂等模板IdempotentTemplate的方法如下:
/**
* 幂等模板处理器
*
* @param request 幂等Request信息
* @param executeSupplier 幂等处理回调function
* @param resultPreprocessConsumer 幂等结果回调function 可以对结果做些预处理
* @param ifResultNeedIdempotence 除了根据异常还需要根据结果判定是否需要幂等性的场景可以提供此参数
* @return
*/
public R execute(IdempotentRequest<P> request, Supplier<R> executeSupplier,
Consumer<IdempotentResult<P, R>> resultPreprocessConsumer, Predicate<R> ifResultNeedIdempotence) {
........
}request:
幂等参数IdempotentRequest组装,可以设置幂等参数和幂等唯一ID
executeSupplier:
具体幂等的方法逻辑,比如针对支付、下单接口,可以通过JDK8函数式接口Supplier Callback进行处理。
resultBiConsumer:
幂等返回结果的处理,该参数可以为空,如果为空采取默认的处理,根据幂等结果,如果成功、不可重试的异常错误码,直接返回结果,如果失败可重试异常错误码,会进行重试处理。
如果该参数值不为空,可以针对返回幂等结果进行特殊逻辑处理设置ResultStatus(ResultStatus包含三种状态包括成功、失败可重试、失败不可重试)。
本文作者:中间件小哥
本文为云栖社区原创内容,未经允许不得转载。