一直以来, 如何从‘视觉稿’精确的还原出 对应的UI侧代码 一直是端侧开发同学工作里消耗比较大的部分,一方面这部分的工作 比较确定缺少技术深度,另一方面视觉设计师也需要投入大量的走查时间,有大量无谓的沟通和消耗。
闲鱼团队 在去年做了一个很特别的黑科技 基于图片直接翻译成对应的UI侧代码,具体完成的部分,我们有一个演示的视频
很多人会比较好奇,为什么我会坚持使用图片做为输入源,一方面基于 sketch 或者 photoshop 等插件 相对容易拿到确定性的信息,图片在某些方面容易丢失一些特征;另外基于图片的分析其实挑战更大。我们做 这个选择 有以下原因,首先图片作为最终的产出物,更直观和确定性,另外这个链路里对上游不会有约束性。最后也是最重要的一点 基于图片的应用场景会更普适,类似场景 例如自动化测试能力的支持,基于竟品直接截图来套用我们自己的数据源找体感,等场景是其他的方案做不到的。
上面我们在讲项目本身的意义和选型上的一些判断,后面我们会简单介绍下项目的基本流程
首先我们会使用深度学习的方式,来找到对应的 UI单元,包括基础的UI组件,例如 imgview textview 等,接下来是自定义的BI组件例如 price 等, 最后我们会寻找已经被实现过的业务组件。下面是一个 常见的业务场景,我们框选了每个对应的部分,演示上面的业务逻辑
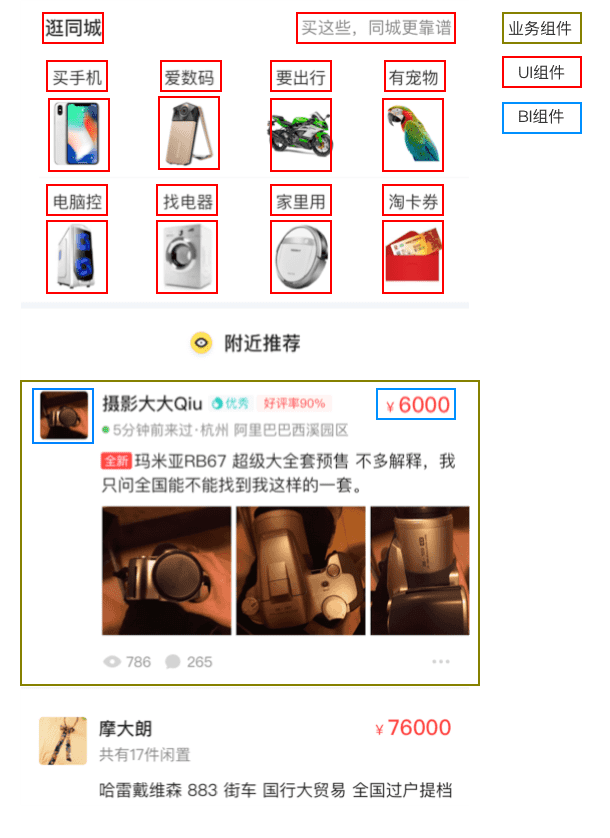
接下来我们会基于已经检测出的元素,来做对应的元素提取,这个部分我们会去分析系统渲染的原理 并使用 opencv 的方法来做对应的功能
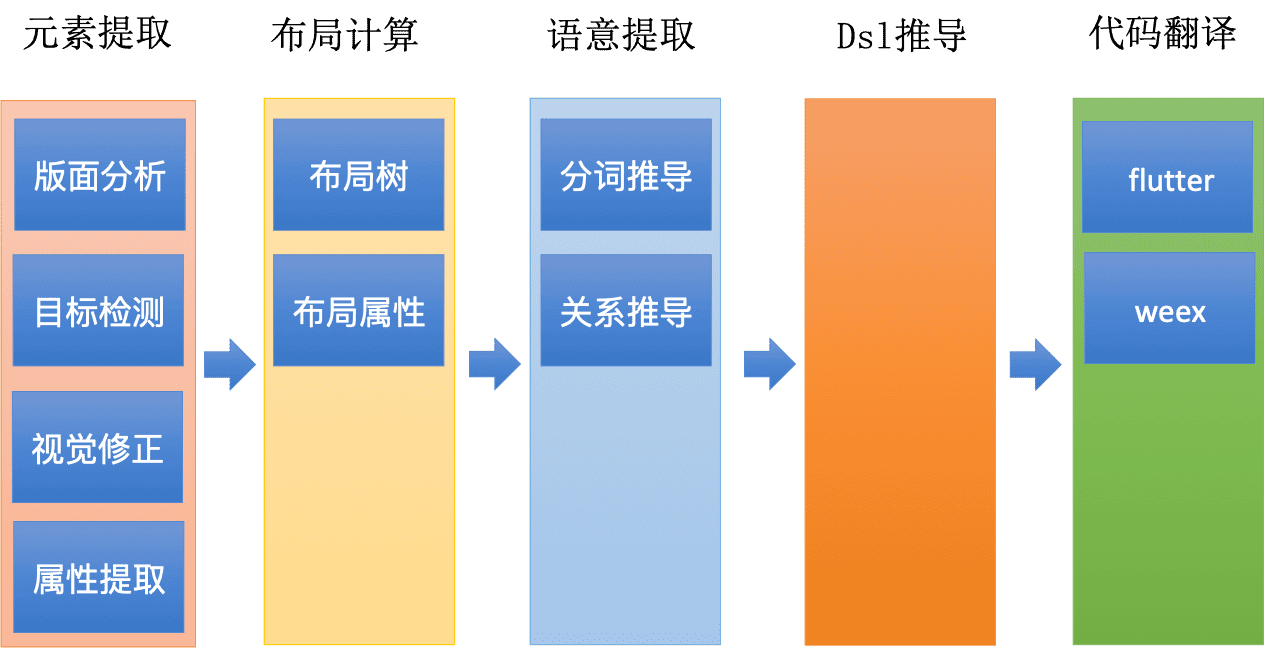
项目整体的流程,我们用下面的这个图来表示
在整个项目落地的过程中,我们遇到很多的技术困难的点,下面我会讲2个有意思的点
第一个我们会发现 autoui 的整个流程结构是一个非常典型的上下游的流形式,每个关键的单元都会依赖上游的输出,并且为下游提供标准的输入,我们在项目的开始时候,因为没有特别好的去定义切分的关系,经常会出现当一个同学调整和PUSH代码后,会对整个链路造成很大的影响,所以我们对架构设计做了一个关键的升级我们定义叫流式的架构,我们用一个图让大家更好的来理解这一块
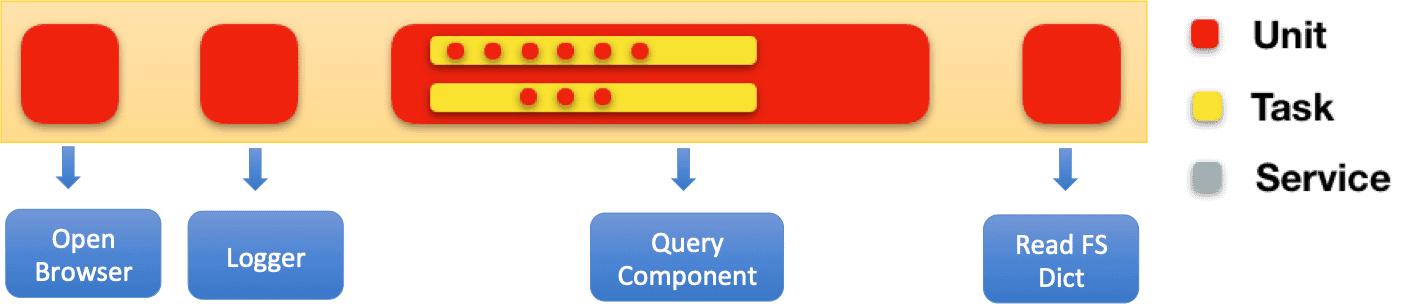
在这个单元里 我们定义了 unti,tasks,server三个单元,unit本身是最小粒度的功能切分,tasks是unit的组合,server 会提供具体的服务,每个部分都会为上下游 提供输入和输出,架构切分的好处是,所有的模块都有标准的输入和输出的部分,我们可以通过对模块的MOCK来解决标准化调试的问题,另外当一些基础的功能完成后,我们可以通过搭积木的方式来组合自己想要的 tasks 和 server ,在我们做了架构调整后,因为整体的切分更合理,也减少了上下游的依赖,对项目的快速迭代产生了很大的帮助。
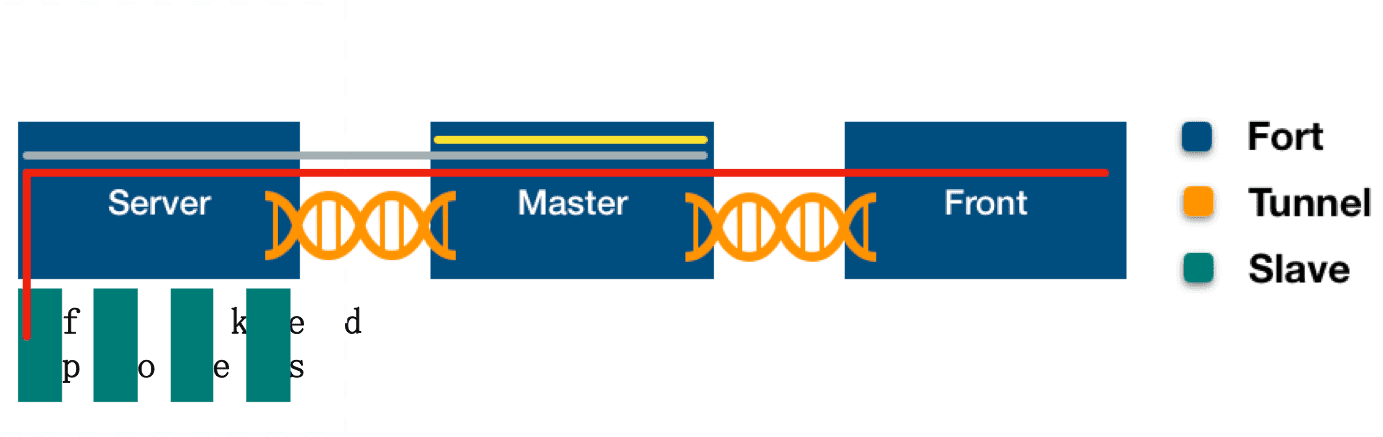
后续 在架构侧我们还做了一个有意思的点,因为 我们的服务有些是需要跑在服务端,有些是需要跑在客户端上,所以我们设计了一个可以在客户端和服务端同构的场景,目的是希望开发的人员只需要关系界面和服务的通信,但并不需要关注具体服务的部署关系
上面我们讲了一个架构的设计,后面我们希望讲一个具体的布局问题具体解法,把静态的DSL转成一个合适的布局属性的TREE,在这个部分我们还是分析了能产生布局的因素,如下图所示
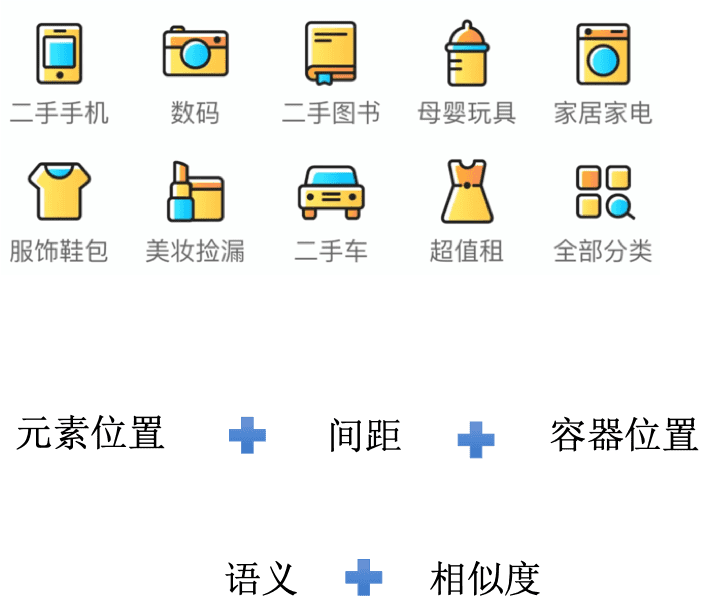
这样一个非常常见的布局,我们拆分出了影响布局的部分,通过元素位置、间距、容器位置分析,我们参考了 flex 布局的标准,也参考了 新的 grid 的布局标准,通过枚举元素在位置中站位的比例,来得出对应的关系。
但是我们最后还是遇到一些Bad Case,如何写出更贴近人写出的UI侧代码,我们还是需要去参考类似语意的部分,相似度的部分 我们才能得到真正合理的布局,例如上面的 这个例子,如果按照枚举的布局去推断的话,我们很容易得到 一个四个横列的布局关系,但是通过语意和相似度的部分,我们会很容易的推断出一个 gridview 的布局关系。
去年整体 我们已经比较好的 让整个工程在业务侧 开始跑起来 开始让大家能解放出来 做一些更需要思考的事情,并把我们的项目 展示给了 google团队,也得到了很多的关注。
未来,我们还是希望通过更好的分析能力(包括 容器识别、复杂的背景识别、精确的语意理解能力),产生出更接近开发人员手写的代码,从而完全取代 ‘切图’ 这个工作,另外我们也在看在这个阶段我们已经能够 让机器来解放开发链路的最前面一段,后面 在一些弱交互、强展示的部分,例如导购或者营销这样的场景,我们其实通过数据模型的抽象和识别、甚至固定的PRD的识别 有可能我们是能真正的解放整段的人力投入,让大家从偏确定性的需求实现中解放出来。另外 我们也开始和 D2C 这样的项目 一起共建,希望在闲鱼里已经实现的部分,能够解决更多人的问题,解放更多的生产力。
本文作者:闲鱼技术-青页
本文为云栖社区原创内容,未经允许不得转载。