一般来说, 增加网络的深度与宽度可以提升网络的性能, 但是这样做也会带来参数量的大幅度增加, 同时较深的网络需要较多的数据, 否则容易产生过拟合现象。 除此之外, 增加神经网络的深度容易带来梯度消失的现象。 在2014年的ImageNet大赛上, 获得冠军的Inception v1(又名GoogLeNet) 网络较好地解决了这个问题。
Inception v1网络是一个精心设计的22层卷积网络, 并提出了具有良好局部特征结构的Inception模块, 即对特征并行地执行多个大小不同的卷积运算与池化, 最后再拼接到一起。 由于1×1、 3×3和5×5的卷积运算对应不同的特征图区域, 因此这样做的好处是可以得到更好的图像表征信息。
Inception模块如图3.13所示, 使用了三个不同大小的卷积核进行卷积运算, 同时还有一个最大值池化, 然后将这4部分级联起来(通道拼接) , 送入下一层。 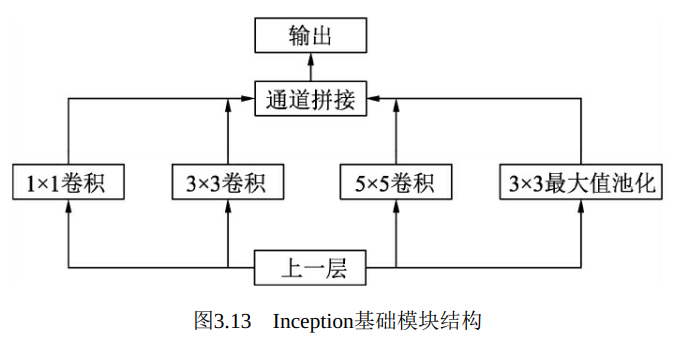
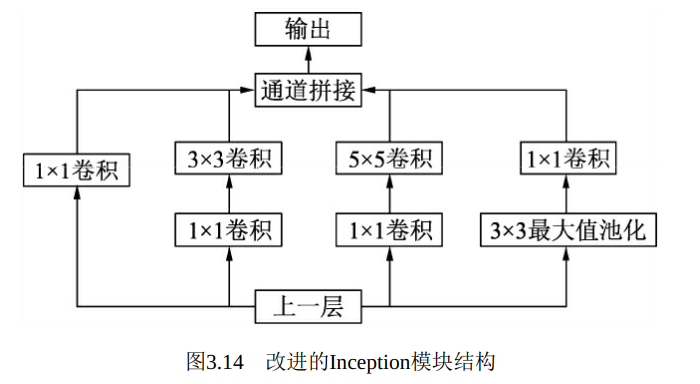
在上述模块的基础上, 为进一步降低网络参数量, Inception又增加了多个1×1的卷积模块。 如图3.14所示, 这种1×1的模块可以先将特征图降维, 再送给3×3和5×5大小的卷积核, 由于通道数的降低, 参数量也有了较大的减少。 值得一提的是, 用1×1卷积核实现降维的思想, 在后面的多个轻量化网络中都会使用到。
Inception v1网络一共有9个上述堆叠的模块, 共有22层, 在最后的Inception模块处使用了全局平均池化。 为了避免深层网络训练时带来的梯度消失问题, 作者还引入了两个辅助的分类器, 在第3个与第6个Inception模块输出后执行Softmax并计算损失, 在训练时和最后的损失一并回传 。
Inception v1的参数量是AlexNet的1/12 , VGGNet的1/3 , 适合处理大规模数据, 尤其是对于计算资源有限的平台。 下面使用PyTorch来搭建一个单独的Inception模块, 新建一个inceptionv1.py文件, 代码如下:


1 import torch 2 from torch import nn 3 import torch.nn.functional as F 4 5 # 首先定义一个包含conv与ReLU的基础卷积类 6 class BasicConv2d(nn.Module): 7 8 def __init__(self, in_channels, out_channels, kernel_size, padding=0): 9 super(BasicConv2d, self).__init__() 10 self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, padding=padding) 11 12 def forward(self, x): 13 x = self.conv(x) 14 return F.relu(x, inplace=True) 15 16 class Inceptionv1(nn.Module): 17 18 def __init__(self, in_dim, hid_1_1, hid_2_1, hid_2_3, hid_3_1, out_3_5, out_4_1): 19 super(Inceptionv1, self).__init__() 20 # 下面分别是4个子模块各自的网络定义 21 self.branch1x1 = BasicConv2d(in_dim, hid_1_1, 1) 22 self.branch3x3 = nn.Sequential( 23 BasicConv2d(in_dim, hid_2_1, 1), 24 BasicConv2d(hid_2_1, hid_2_3, 3, padding=1) 25 ) 26 self.branch5x5 = nn.Sequential( 27 BasicConv2d(in_dim, hid_3_1, 1), 28 BasicConv2d(hid_3_1, out_3_5, 5, padding=2) 29 ) 30 self.branch_pool = nn.Sequential( 31 nn.MaxPool2d(3, stride=1, padding=1), 32 BasicConv2d(in_dim, out_4_1, 1) 33 ) 34 35 def forward(self, x): 36 b1 = self.branch1x1(x) 37 b2 = self.branch3x3(x) 38 b3 = self.branch5x5(x) 39 b4 = self.branch_pool(x) 40 # 将这四个子模块沿着通道方向进行拼接 41 output = torch.cat((b1, b2, b3, b4), dim=1) 42 return output
1 import torch 2 from inceptionv1 import Inceptionv1 3 # 网络实例化, 输入模块通道数, 并转移到GPU上 4 net_inception1 = Inceptionv1(3, 64, 32, 64, 64, 96, 32).cuda() 5 print(net_inception1) 6 >> Inceptionv1( 7 # 第一个分支, 使用1×1卷积, 输出通道数为64 8 (branch1x1): BasicConv2d( 9 (conv): Conv2d(3, 64, kernel_size=(1, 1), stride=(1, 1)) 10 ) 11 # 第一个分支, 使用1×1卷积, 输出通道数为64 12 (branch3x3): Sequential( 13 (0): BasicConv2d( 14 (conv): Conv2d(3, 32, kernel_size=(1, 1), stride=(1, 1)) 15 ) 16 (1): BasicConv2d( 17 (conv): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) 18 ) 19 ) 20 # 第三个分支, 使用1×1卷积与5×5卷积, 输出通道数为96 21 (branch5x5): Sequential( 22 (0): BasicConv2d( 23 (conv): Conv2d(3, 64, kernel_size=(1, 1), stride=(1, 1)) 24 ) 25 (1): BasicConv2d( 26 (conv): Conv2d(64, 96, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2)) 27 ) 28 ) 29 # 第四个分支, 使用最大值池化与1×1卷积, 输出通道数为32 30 (branch_pool): Sequential( 31 (0): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=False) 32 (1): BasicConv2d( 33 (conv): Conv2d(3, 32, kernel_size=(1, 1), stride=(1, 1)) 34 ) 35 ) 36 ) 37 input = torch.randn(1, 3, 256, 256).cuda() 38 print(input.shape) 39 >> torch.Size([1, 3, 256, 256]) 40 41 output = net_inception1(input) 42 print(output.shape) 43 # 可以看到输出的通道数是输入通道数的和, 即256=64+64+96+32 44 >> torch.Size([1, 256, 256, 256])
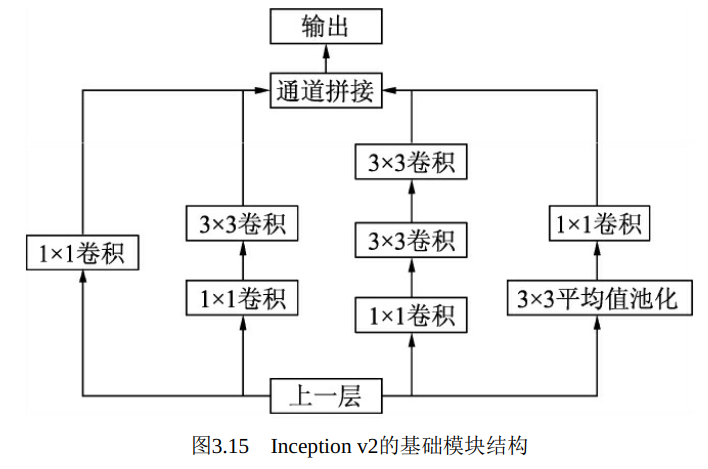
在Inception v1网络的基础上, 随后又出现了多个Inception版本。Inception v2进一步通过卷积分解与正则化实现更高效的计算, 增加了BN层, 同时利用两个级联的3×3卷积取代了Inception v1版本中的5×5卷积, 如图3.15所示, 这种方式既减少了卷积参数量, 也增加了网络的非 线性能力 。
使用PyTorch来搭建一个单独的Inception v2模块, 默认输入的通道数为192, 新建一个inceptionv2.py文件, 代码如下 :
1 import torch 2 from torch import nn 3 import torch.nn.functional as F 4 # 构建基础的卷积模块, 与Inception v2的基础模块相比, 增加了BN层 5 class BasicConv2d(nn.Module): 6 7 def __init__(self, in_channels, out_channels, kernel_size, padding=0): 8 super(BasicConv2d, self).__init__() 9 self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, padding=padding) 10 self.bn = nn.BatchNorm2d(out_channels, eps=0.001) 11 12 def forward(self, x): 13 x = self.conv(x) 14 x = self.bn(x) 15 return F.relu(x, inplace=True) 16 class Inceptionv2(nn.Module): 17 def __init__(self): 18 super(Inceptionv2, self).__init__() 19 self.branch1 = BasicConv2d(192, 96, 1, 0) # 对应1x1卷积分支 20 # 对应1x1卷积与3x3卷积分支 21 self.branch2 = nn.Sequential( 22 BasicConv2d(192, 48, 1, 0), 23 BasicConv2d(48, 64, 3, 1) 24 ) 25 #对应1x1卷积、 3x3卷积与3x3卷积分支 26 self.branch3 = nn.Sequential( 27 BasicConv2d(192, 64, 1, 0), 28 BasicConv2d(64, 96, 3, 1), 29 BasicConv2d(96, 96, 3, 1) 30 ) 31 #对应3x3平均池化与1x1卷积分支 32 self.branch4 = nn.Sequential( 33 nn.AvgPool2d(3, stride=1, padding=1, count_include_pad=False), 34 BasicConv2d(192, 64, 1, 0) 35 ) 36 37 # 前向过程, 将4个分支进行torch.cat()拼接起来 38 def forward(self, x): 39 x0 = self.branch1(x) 40 x1 = self.branch2(x) 41 x2 = self.branch3(x) 42 x3 = self.branch4(x) 43 out = torch.cat((x0, x1, x2, x3), 1) 44 return out
1 import torch 2 from inceptionv2 import Inceptionv2 3 4 net_inceptionv2 = Inceptionv2().cuda() 5 print(net_inceptionv2) 6 >> Inceptionv2( 7 # 第1个分支, 使用1×1卷积, 输出通道数为96 8 (branch1): BasicConv2d( 9 (conv): Conv2d(192, 96, kernel_size=(1, 1), stride=(1, 1)) 10 (bn): BatchNorm2d(96, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) 11 ) 12 # 第2个分支, 使用1×1卷积与3×3卷积, 输出通道数为64 13 (branch2): Sequential( 14 (0): BasicConv2d( 15 (conv): Conv2d(192, 48, kernel_size=(1, 1), stride=(1, 1)) 16 (bn): BatchNorm2d(48, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) 17 ) 18 (1): BasicConv2d( 19 (conv): Conv2d(48, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) 20 (bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) 21 ) 22 ) 23 #第3个分支, 使用1×1卷积与两个连续的3×3卷积, 输出通道数为96 24 (branch3): Sequential( 25 (0): BasicConv2d( 26 (conv): Conv2d(192, 64, kernel_size=(1, 1), stride=(1, 1)) 27 (bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) 28 ) 29 (1): BasicConv2d( 30 (conv): Conv2d(64, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) 31 (bn): BatchNorm2d(96, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) 32 ) 33 (2): BasicConv2d( 34 (conv): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) 35 (bn): BatchNorm2d(96, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) 36 ) 37 ) 38 #第4个分支, 使用平均池化与1×1卷积, 输出通道数为64 39 (branch4): Sequential( 40 (0): AvgPool2d(kernel_size=3, stride=1, padding=1) 41 (1): BasicConv2d( 42 (conv): Conv2d(192, 64, kernel_size=(1, 1), stride=(1, 1)) 43 (bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) 44 ) 45 ) 46 ) 47 48 input = torch.randn(1, 192, 32, 32).cuda() 49 print(input.shape) 50 >> torch.Size([1, 192, 32, 32]) 51 52 # 将输入传入实例的网络 53 output = net_inceptionv2(input) 54 print(output.shape) 55 # 输出特征图的通道数为: 96+64+96+64=320 56 >> torch.Size([1, 320, 32, 32])
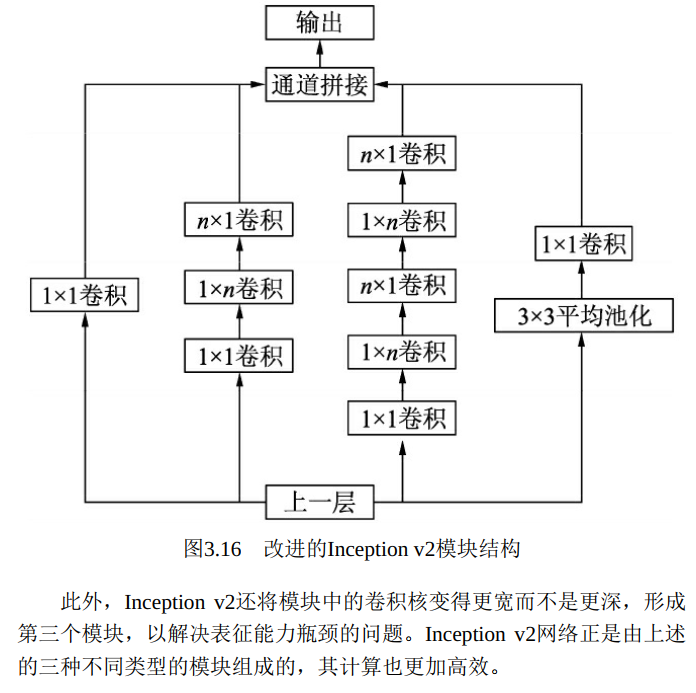
更进一步, Inception v2将n×n的卷积运算分解为1×n与n×1两个卷积, 如图3.16所示, 这种分解的方式可以使计算成本降低33%。
Inception v3在Inception v2的基础上, 使用了RMSProp优化器, 在辅
助的分类器部分增加了7×7的卷积, 并且使用了标签平滑技术。
Inception v3在Inception v2的基础上, 使用了RMSProp优化器, 在辅助的分类器部分增加了7×7的卷积, 并且使用了标签平滑技术。
Inception v4则是将Inception的思想与残差网络进行了结合, 显著提升了训练速度与模型准确率, 这里对于模块细节不再展开讲述。 至于残差网络这一里程碑式的结构, 正是由下一节的网络ResNet引出的。