一、介绍
二、编程
练习一(K最近邻算法在单分类任务的应用):
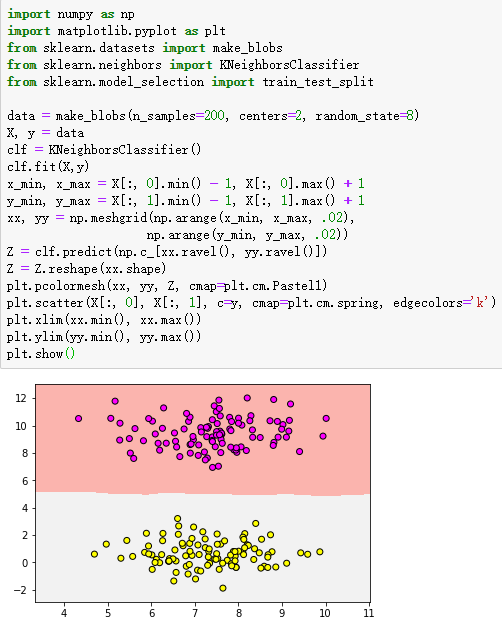
import numpy as np #导入科学计算包
import matplotlib.pyplot as plt #导入画图工具
from sklearn.datasets import make_blobs #导入数据集生成器
from sklearn.neighbors import KNeighborsClassifier #导入KNN分类器(KNN回归树的类)
from sklearn.model_selection import train_test_split #导入数据集拆分工具
data = make_blobs(n_samples=200, centers=2, random_state=8) #生成样本数为200,分类为2的数据集,随机种子数为8
X, y = data
clf = KNeighborsClassifier() #导入KNN分类器函数
clf.fit(X,y) #训练X和y数据进行训练
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, .02),
np.arange(y_min, y_max, .02))
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.pcolormesh(xx, yy, Z, cmap=plt.cm.Pastel1)
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.spring, edgecolors='k')
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.show()
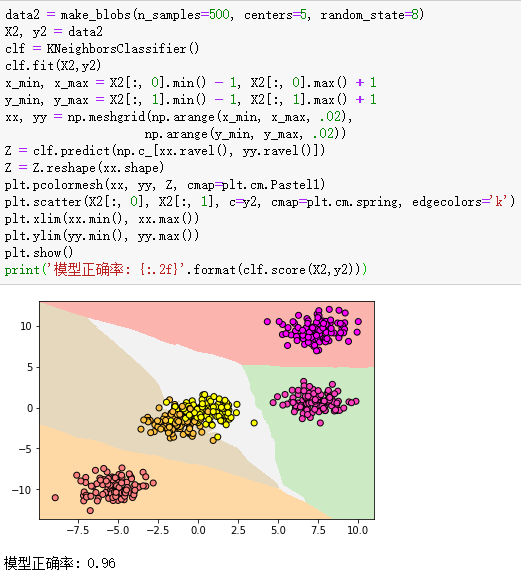
练习二(K最近邻算法处理多元分类):
data2 = make_blobs(n_samples=500, centers=5, random_state=8) #生成样本数为500,分数为5的数据集
X2, y2 = data2
clf = KNeighborsClassifier()
clf.fit(X2,y2)
x_min, x_max = X2[:, 0].min() - 1, X2[:, 0].max() + 1
y_min, y_max = X2[:, 1].min() - 1, X2[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, .02),
np.arange(y_min, y_max, .02))
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.pcolormesh(xx, yy, Z, cmap=plt.cm.Pastel1)
plt.scatter(X2[:, 0], X2[:, 1], c=y2, cmap=plt.cm.spring, edgecolors='k')
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.show()
print('模型正确率: {:.2f}'.format(clf.score(X2,y2)))
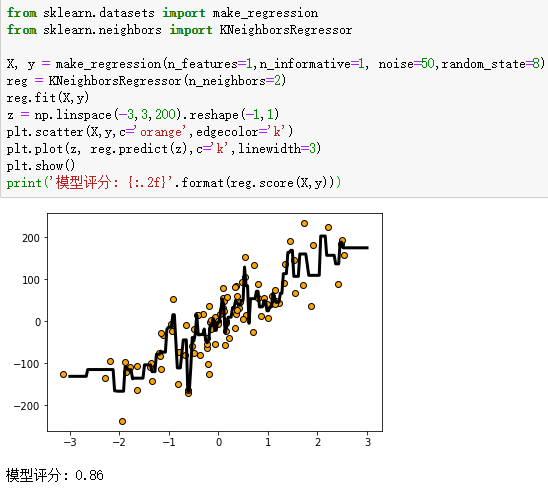
练习三(K最近邻算法用于回归分析):
from sklearn.datasets import make_regression #导入数据集生成器
from sklearn.neighbors import KNeighborsRegressor
X, y = make_regression(n_features=1,n_informative=1, noise=50,random_state=8) #生成特征数量为1,噪音为50的数据集
reg = KNeighborsRegressor(n_neighbors=2)
reg.fit(X,y)
z = np.linspace(-3,3,200).reshape(-1,1)
plt.scatter(X,y,c='orange',edgecolor='k')
plt.plot(z, reg.predict(z),c='k',linewidth=3)
plt.show()
print('模型评分: {:.2f}'.format(reg.score(X,y)))
练习四(K最近邻算法项目用于酒的分类):
from sklearn.datasets import load_wine #导入数据模块
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split #导入数据集拆分工具
wine_dataset = load_wine()
knn = KNeighborsClassifier(n_neighbors=1)
X_train, X_test, y_train, y_test = train_test_split(wine_dataset['data'], wine_dataset['target'], random_state=0) #将数据集拆分为训练集和测试集
knn.fit(X_train, y_train)
print('测试数据得分: {:.2f}'.format(knn.score(X_test, y_test)))
print('####################################')
import numpy as np
X_new = np.array([[13.2,2.77,2.51,18.5,96.6,1.04,2.55,0.57,1.47,6.2,1.05,3.33,820]])
prediction = knn.predict(X_new)
print('预测新红酒的分类为: {}'.format(wine_dataset['target_names'][prediction]))
