第六章 模型与数据库
Django对各种数据库提供了很好的支持,包括:PostgreSQL、MySQL、SQLite和Oracle,而且为这些数据库提供了统一的调用API,这些API统称为ORM框架。通过使用Django内置的ORM框架可以实现数据库连接和读写操作。
6.1 构建模型
ORM框架是一种程序技术,用于实现面向对象编程语言中不同类型系统的数据之间的转换。从效果上说,其实是创建了一个可在编程语言中使用的"虚拟对象数据库",通过对虚拟对象数据库操作从而实现对目标数控的操作,虚拟对象数据库与模板数据库是相互对应的。在Django中,虚拟对象数据库也成为模型。通过模型先对模板数据库的读写操作,实现如下:
1、配置模板数据库信息,主要在setting.py中设置数据库信息,具体配置步骤可查看2.4节。
2、构建虚拟对象数据库,在App的models.py文件中以类的形式定义模型。
3、通过模型在模板数据库中创建相应的数据表
4、在视图函数中通过对模型操作实现目标数据库的读写操作。
本节主要讲述如何构建模型并通过模型在目标数据中生成相应的数据表。在此之前可以查看2.4节如何配置目标数据库信息。以MyDjangl项目为例,配置信息如下:
DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', 'NAME': 'mydjango', 'USER': 'root', 'PASSWORD': '1234', 'HOST': '127.0.0.1', 'PORT': '3306', }, }
在项目index的models.py文件中定义模型如下:
from django.db import models # Create your models here. #创建产品分类表 class Type(models.Model): id = models.AutoField(primary_key=True) type_name = models.CharField(max_length=20) #创建产品信息表 class Product(models.Model): id = models.IntegerField(primary_key=True) name = models.CharField(max_length=50) weight = models.CharField(max_length=20) size = models.CharField(max_length=20) type = models.CharField(max_length=20)
上述代码分别定义了模型Type和Product,说明如下:
1、模型以类的形式进行定义,并且继承Django的models.Model类。一个类代表模板数据库的一张数据表,类的命名一般以首字母大写开头。
2、模型的字段以类属性进行定义,如id=models.IntegerField(primary_key=True)代表在数据表Type中命名一个名为id的字段,该字段的数据类型为整型并设置为主键。
完成模型的定义后,接着在目标数据库中创建相应的数据表,在模板数据库中创建表是通过Django的管理工具manage.py完成的,创建指令如下:
#根据models.py内容生成相关的py文件,该文件用于创建数据表
python manage.py makemigrations Tracking file by folder pattern: migrations Migrations for 'index': indexmigrations�001_initial.py - Create model Product - Create model Type Following files were affected E: est5MyDjangoindexmigrations�001_initial.py Process finished with exit code 0
#创建数据表
python manage.py migrate
在执行的两次指令makemigrations和migrate过程如下:
makemigrations指令用于将index所定义的模型生成0001_initial.py文件,该文件存放在index的migrations文件夹,打开查看0001_initial.py文件,其文件内容如下:


from django.db import migrations, models class Migration(migrations.Migration): initial = True dependencies = [ ] operations = [ migrations.CreateModel( name='Product', fields=[ ('id', models.IntegerField(primary_key=True, serialize=False)), ('name', models.CharField(max_length=50)), ('weight', models.CharField(max_length=20)), ('size', models.CharField(max_length=20)), ('type', models.CharField(max_length=20)), ], ), migrations.CreateModel( name='Type', fields=[ ('id', models.AutoField(primary_key=True, serialize=False)), ('type_name', models.CharField(max_length=20)), ], ), ]
0001_initial.py文件将models.py的内容生成数据表的脚本代码。而migrate指令根据脚本代码在目标数据库中生成相对应的数据表。指令运行完成后,可在数据库看到已创建的数据表,运行如下:
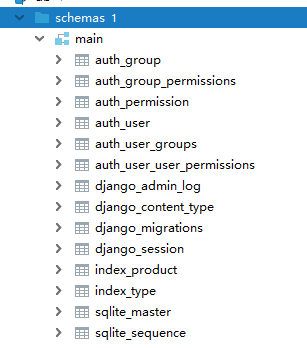
从图中可以看到,数据表index_product和index_type是由index的模型创建的,分别对应模型Product和Type。其他数据表是Django内置功能所使用的数据表,分别是会话session、用户认证管理和Admin日志记录等。
下面是django表字段数据类型及说明:
| 表字段 | 说明 |
| models.AutoFileld | 默认会生成一个名为id的字段并为int类型 |
| models.CharField | 字符串类型 |
| models.BooleanField | 布尔类型 |
| models.ComaSeparatedIntegerField | 用逗号分隔的整数类型 |
| models.DateField | 日期(date)类型 |
| models.DateTimeField | 日期(datetime)类型 |
| models.Decimal | 十进制小数类型 |
| models.EmailField | 字符串类型(正则表达式邮箱) |
| models.FloatField | 浮点类型 |
| models.IntegerField | 整数类型 |
| models.BigIntegerField | 长整数类型 |
| models.IPAddressField | 字符串类型(IPv4正则表达式) |
| models.GenericIPAddressField |
字符串类型,参数protocol可以是:both、IPv4和 ipv6,验证IP地址 |
| models.NullBooleanField | 允许为空的布尔类型 |
| models.PositiveIntegerFiel | 正整数的整数类型 |
| models.PositiveSmallIntegerField | 小正整数类型 |
| models.SlugField | 包含字母、数字、下划线和连字符的字符串。常用于URL |
| models.SmallIntegerField | 小整数类型,取值范围(-32,768~+32,767) |
| models.TextField | 长文本类型 |
| models.TimeField | 时间类型,显示时分秒HH:MM[:ss[.uuuuuu]] |
| models.URLField | 字符串,地址为正则表达式 |
| models.BinaryField | 二进制数据类型 |
从表中可以看到,Django提供的字段类型还会对数据进行正则处理和验证功能等,进一步完善了数据的严谨性。除了表字段类型之外,每个表字段还可以设置相应的参数,使得表字段更加完善。字段参数说明如下:
| 参数 | 说明 |
| Null | 如为True,字段是否可以为空 |
| Blank | 如为True,设置在Admin站点管理中添加数据时可允许空值 |
| Default | 设置默认值 |
| primary_key | 如为True,将字段设置成主键 |
| db_column | 设置数据库中的字段名称 |
| Unique | 如为True,将字段设置成唯一属性,默认为False |
| db_index | 如为True,为字段添加数据库索引 |
| verbose_name | 在Admin站点管理设置字段的显示名称 |
| related_name | 关联对象反向引用描述符,用于多表查询,可解决一个数据表有两个外键同时指向另一个数据表而出现重名的问题 |
6.2 数据表的关系
一个模型对应目标数据库的一个数据表,但我们知道,每个数据表之间是可以存在关联的,表与表之间有三种关系:一对一/一对多和多对多。
一对一存在于在两个数据表中,第一个表的某一行数据只与第二个表的某一行数据相关,同时第二个表的某一行数据也只与第一个表的某一行数据相关,这种表关系被称为一对一关系,以下列为例:
| ID | 姓名 | 国籍 | 参加节目 |
| 1001 | 王大锤 | 中国 | 万万没想到 |
| 1002 | 全智贤 | 韩国 | 蓝色大海的传说 |
| 1003 | 刀锋女王 | 未知 | 计划生育 |
一对一关系的第一个表
| ID | 出生日期 | 逝世日期 |
| 1001 | 1988 | NULL |
| 1002 | 1981 | NULL |
| 1003 | 未知 | 3XXX |
一对一关系的第二个表
在上述两个表中,表一和表二的字段ID分别是一一对应的,并且不会在同一表中有重复ID,使用这种关系通常是一个数据表有太多字段,并且不会在同一表中有重复ID,使用这种关系通常是一个数据表有太多字段,将常用的字段抽取出来并组成一个新的数据表。在模型中可以通过OneToOneField来构建数据表的一对一关系,代码如下:
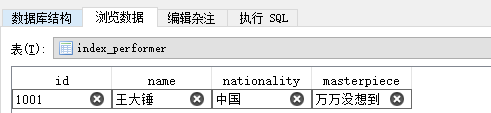
#一对一关系 class Performer(models.Model): id = models.IntegerField(primary_key=True) name = models.CharField(max_length=20) nationality = models.CharField(max_length=20) masterpiece = models.CharField(max_length=50) class Performer_info(models.Model): id = models.IntegerField(primary_key=True) performer = models.OneToOneField(Performer, on_delete=models.CASCADE) birth = models.CharField(max_length=20) elapse = models.CharField(max_length=20)
使用DJango的管理工具manage.py创建数据表Performer和Performer_info,创建数据表前最好先删除0001_initial.py文件并清空数据库里的数据表。数据表的表关系如图:


一对多存在于两个或两个以上的数据表中,第一个表的数据可以与第二个表的一道多行数据进行关联,但是第二个表的每一行数据只能与第一个表的某一行进行管理,以下列表为例:
一对一多关系的第一个表
| ID | 姓名 | 国籍 |
| 1001 | 王大锤 | 中国 |
| 1002 | 全智贤 | 韩国 |
| 1003 | 刀锋女王 | 未知 |
一对一多关系的第二个表
| ID | 节目 |
| 1001 | 万万没想到 |
| 1001 | 报告老板 |
| 1003 | 星际2 |
| 1003 | 英雄联盟 |
在上面一对一多关系的第二个表中,字段ID的数据可以重复并且在第一个表中找到对应的数据,而表1的字段ID是唯一的,这是一种最为常见的表关系。在模型中可以通过ForeignKey来构建数据表的一对多关系,代码如下:
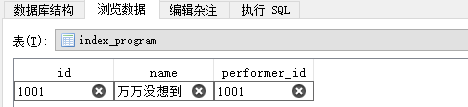
#一对多关系 class Performer(models.Model): id = models.IntegerField(primary_key=True) name = models.CharField(max_length=20) nationality = models.CharField(max_length=20) masterpiece = models.CharField(max_length=50) class Program(models.Model): id = models.IntegerField(primary_key=True) performer = models.ForeignKey(Performer,on_delete=models.CASCADE) name = models.CharField(max_length=20)
使用Django的管理工具manage.py创建数据表Performer和Program,创建数据表前最好先删除0001_initial.py文件并清空数据库里的数据表。数据表的表关系如图:
多对多存在于两个或两个以上的数据表中,第一个表的某一行数据可以与第二个表的一到多行数据进行关联,同时在第二个表中的某一行数据也可以与第一个表的一到多行数据进行关联,以下表为例:
多对多关系的第一个表
| ID | 姓名 | 国籍 |
| 1001 | 王大锤 | 中国 |
| 1002 | 全智贤 | 韩国 |
| 1003 | 刀锋女王 | 未知 |
多对多关系第二个表
| ID | 节目 |
| 10001 | 万万没想到 |
| 10002 | 报告老板 |
| 10003 | 星际2 |
| 10004 | 英雄联盟 |
两个表的数据关系
| ID | 节目ID | 演员ID |
| 1 | 10001 | 1001 |
| 2 | 10001 | 1002 |
| 3 | 10002 | 1001 |
从上面的三个数据表中可以发现,一个演员可以参加多个节目,而一个节目也可以由多个演员来共同演唱。每个表的字段ID都是唯一的,在表中可以发现,节目ID和演员ID出现了重复的数据,分别对应上面两个表,多对多关系需要使用新的数据表来管理两个表的数据关系。在模型中可以通过ManyToManyField来构建数据表多的多对多关系,代码如下:
#多对多 class Performer(models.Model): id = models.IntegerField(primary_key=True) name = models.CharField(max_length=20) nationality = models.CharField(max_length=20) masterpiece = models.CharField(max_length=50) class Manytomany(models.Model): id = models.IntegerField(primary_key=True) name = models.CharField(max_length=20) performer = models.ManyToManyField(Performer)
Django创建多对多关系的时候只需定义两个数据库对象,在创建目标数据表的时候会自动生成三个数据表来建立多对多关系,如下图:

6.3 数据表的读写
数据库的读写操作主要对数据进行增、删、改、查。以数据表index_type和index_product为例,分别在两个数据表中添加如下数据:
表index_type中的数据信息

表index_product中的数据信息

在MyDjango项目中使用shell模式(启动命令行和执行脚本)进行讲述,该模式主要为方便开发人员开发和调式程序。在PyCharm的Terminal下开启shell模式,输入python manage.py shell指令即可开启。如下图:

在shell模式下,若想对数据表index_product插入数据,则可输入以下代码实现:

通过对模型Product进行操作实现数据表index_product的数据插入,插入方式如下:
1、从models.py中导入模型Product
2、对模型Product声明并实例化,生成对象p
3、对对象p的属性进行逐一赋值,对象p的属性来自于模型Product所定义的字段。完成赋值后需要对p进行保存才能作用在目标数据库。
需要注意的是,模型Product的外键命名为type,但在目标数据库中变为type_id,因此对对象p进行赋值的时候,外键的赋值应以目标数据库的字段名为准。
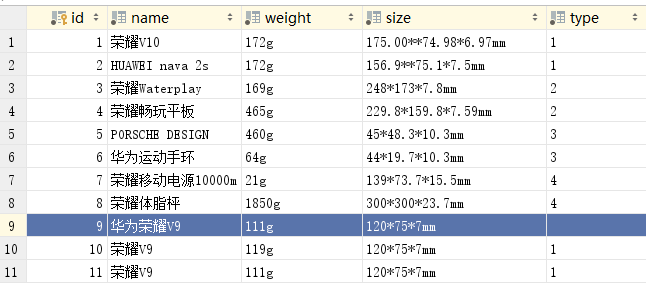
上述代码运行结束后,可以在数据库中查看数据的插入情况,如图:

除了上述方法外,数据的插入还有以下两种方式,代码如下:
#方法一 #通过Django的ORM框架提供的API实现,使用create方法实现数据插入 In [9]: Product.objects.create(name='荣耀V9',weight='119g',size='120*75*7mm',type=1) Out[9]: <Product: Product object (None)> #方法二 #在实例化时直接设置属性值 In [11]: p = Product(name='荣耀V9',weight='111g',size='120*75*7mm',type=1) In [12]: p.save()
如果想对现有的数据进行更新,实现步骤与数据插入的方法大致相同,唯一的区别是在模型实例化之后,要更新数据,需要先进行一次数据查询,将查询结果以对象的形式赋给p,最后对p的属性重新赋值就能实现数据的更新,代码如下:

上述代码运行结束后,在数据库中结果如下:
除此之外,还可以使用update方法实现单条和多条数据的更新,使用方法如下:
#通过Django的ORM框架提供的API实现 #更新单条数据,查询条件filter使用于查询单条数据 Product.objects.filter(id=9).update(name='华为荣耀V10') #更新多条数据,查询条件filter以列表格式返回,查询结果可能是一条或多条数据 Product.objects.filter(name='荣耀V9').update(name='华为荣耀V9') #全表数据更新,不使用查询条件,默认对全表的数据进行更新 Product.objects.update(name='华为荣耀V9')
如果要对数据进行删除处理,有三种方式:删除表中全部数据、删除一条数据和删除多条数据。实现三种删除方式的代码如下:
#删除一条id为1的数据 Product.objects.get(id=1).delete() #删除多条数据 Product.objects.filter(weight='119g').delete() #删除表中全部数据 Product.objects.all().delete()
数据删除有ORM框架的delete方法实现。从数据的删除和更新可以看到这两种数据操作都使用查询条件get和filter,查询条件get和filter的区别如下:
1、查询条件get:查询字段必须是主键或者唯一约束的字段,并且查询的数据必须存在,如果查询的字段有重复值或者查询的数据不存在,程序都会抛出异常信息。
2、查询条件filter:查询字段没有限制,只要该字段是数据表的某一字段即可。查询结果以列表的形式返回,如果查询结果为空(查询的数据在数据库中找不到),就返回空列表。
数据查询是数据库操作中最为复杂并且内容最多的部分,我们以代码的形式来讲述如何通过ORM框架提供的API实现数据查询,代码如下:
In [39]: from index.models import * #全表查询,等同于SQL语句Select * from index_product,数据以类不形式返回 In [40]: p = Product.objects.all() In [41]: p[1].name Out[41]: '华为荣耀V9' #查询前5条数据,等同于SQL语句Select * from index_product LIMIT 5 #SQL语句里面的LIMIT方法,在Django中使用Python的列表截取分解即可实现 In [43]: p = Product.objects.all()[:5] In [44]: p #查询某个字段,等同于SQL语句Select name from index_product #values方法,以列表形式返回数据,列表元素以字典格式表示 In [45]: p = Product.objects.values('name') In [46]: p[1]['name'] Out[46]: '华为荣耀V9' #values_list方法,以列表表示返回数据,列表元素以元组格式表示 In [47]: p = Product.objects.values_list('name')[:3] In [48]: p Out[48]: <QuerySet [('华为荣耀V9',), ('华为荣耀V9',), ('华为荣耀V9',)]> #使用get方法查询数据,等于同SQL语句Select * from index_product where id=2 In [49]: p = Product.objects.get(id = 2) In [50]: p.name Out[50]: '华为荣耀V9' #使用filter方法查询数据,注意区分get和filter的差异 In [51]: p = Product.objects.filter(id = 2) In [52]: p[0].name Out[52]: '华为荣耀V9' #SQL的 and查询主要在filter里面添加多个查询条件 In [53]: p = Product.objects.filter(name='华为荣耀V9',id=9) In [54]: p Out[54]: <QuerySet [<Product: Product object (9)>]> #SQL的or查询,需要引入Q,编写格式Q(field=value)|Q(field=value) #等同于SQL语句Select * from index_product where name='华为荣耀V9‘ or id=9 In [55]: from django.db.models import Q In [57]: p = Product.objects.filter(Q(name='华为荣耀V')|Q(id=9)) In [58]: p Out[58]: <QuerySet [<Product: Product object (9)>]> #使用count方法统计查询数据的数据量 In [63]: p = Product.objects.filter(name='华为荣耀V9').count() In [64]: p Out[64]: 8 #去重查询,distinct方法无需设置参数,去重方式根据values设置的字段执行 #等同SQL语句Select DISTINCT name from index_product where name='华为荣耀V9’ In [65]: p = Product.objects.values('name').filter(name='华为荣耀V9').distinct() In [66]: p Out[66]: <QuerySet [{'name': '华为荣耀V9'}]> #根据字段id降序排列,降序只要在order_by里面的字段前面加"-即可" #order_by可设置多字段排序,如Product.objects.order_by('-id', 'name') In [67]: p = Product.objects.order_by('-id') In [68]: p Out[68]: <QuerySet [<Product: Product object (11)>, <Product: Product object (9)>, <Product: Product object (8)>, <Product: Product object (7)>, <Product: Product object (5)>, <Product: Product object (4)>, <Product: Product object (3)>, <Product: Product object (2)>]> #聚合查询,实现对数据值求和、求平均值等。Django提供annotate和aggregate方法实现 #annotate类似于SQL里面的GROUP BY方法,如果不设置values,就会默认对主键进行GROUP BY分组 #等同于SQL语句Select name,SUM(id) AS 'id_sum' from index_product GROUP BY NAME ORDER BY NULL In [69]: from django.db.models import Sum, Count In [70]: p = Product.objects.values('name').annotate(Sum('id')) In [71]: print(p.query) SELECT "index_product"."name", SUM("index_product"."id") AS "id__sum" FROM "index_product" GROUP BY "index_product"."name" #aggregate是将某个字段的值进行计算并置返回技术结果 #等同于SQL语句Select COUNT(id) AS 'id_count' from index_product In [72]: from django.db.models import Count In [73]: p = Product.objects.aggregate(id_count=Count('id')) In [74]: p Out[74]: {'id_count': 8}
上述代码将是了日常开发中常用的数据查询方法,但又时候需要设置不同的查询条件来满足多方面的查询要求。上述例子中,查询条件filter和get使用等值的方法来匹配结果。若想使用大于、不等于和模糊查询的匹配方法,则可以使用如下表所以的匹配附实现:
| 匹配符 | 使用 | 说明 |
| __exact | filter(name__exact='荣耀') | 精确等于,如SQL的like‘荣耀’ |
| __iexact | filter(name__iexact='荣耀') | 精确等于并忽略大小写 |
| __contains | filter(name__contains='荣耀') | 模糊匹配,如SQL的like '%荣耀%' |
| __icontains | filter(name__icontains='荣耀') | 模糊匹配,忽略大小写 |
| __gt | filter(id__gt=5) | 大于 |
| __gte | filter(id__gte=5) | 大于等于 |
| __lt | filter(id__lt=5) | 小于 |
| __lte | filter(id__lte=5) | 小于等于 |
| __in | filter(id__in=[1,2,3]) | 判断是否在列表内 |
| __startswith | filter(name__startswith='荣耀') | 以...开头 |
| __istartswith | filter(name__istartswith='荣耀') | 以...开头并忽略大小写 |
| __endswith | filter(name__endswith='荣耀') | 以...结尾 |
| __iendswith | filter(name__iendswith='荣耀') | 以...结尾并忽略大小写 |
| __range | filter(name__range='荣耀') | 在...范围内 |
| __year | filter(date__year=2018) | 日期字段的年份 |
| __month | filter(date__month=12) | 日期字段的月份 |
| __day | filter(date__day='') | 日期字段的天数 |
| __isnull | filter(name__isnull=True/False) | 判断是否为空 |
从表中可以看到,只要在查询的字段后添加相应的匹配符,就能实现多种不同的数据查询,如filter(id__gt=9)用于获取字段id大于9的数据,在shell模式下使用该匹配符进行数据查询,代码如下:
In [75]: from index.models import * In [76]: p = Product.objects.filter(id__gt=9) In [77]: p Out[77]: <QuerySet [<Product: Product object (11)>]>
6.4 多表查询
一对多或一对一的表关系是通过外键实现关联的,而多表查询分为正向查询和反向查询。以模型Product和Type为例:
1、如果查询对象的主体是模型Type,要查询模型Type的数据,那么该查询成为正向查询。
2、如果查询对象的主体是模型Type,要通过模型Type查询模型Product的数据,那么该查询称为反向查询。
无论是正向查询还是反向查询,两者的实现方法大致相同,代码如下:
In [4]: t = Product.objects.filter(type_id=3) #正向查询 In [5]: t Out[5]: <QuerySet [<Product: Product object (4)>, <Product: Product object (5)>]> In [7]: t[0].name Out[7]: '荣耀畅玩平板' #反向查询 Out[8]:t[0].product_set.values('name')
从上面的代码分析,因为正向查询的查询对象主体和查询的数据都来自于模型Type,因此正向查询在数据库中只执行了一次SQL查询。而反向查询通过t[0].product_set.values('name')来获取模型Product的数据,因此反向查询执行了两次SQL查询,首先查询模型Type的数据,然后根据第一次查询的结果再查询与模型Product相互关联的数据。
为了减少反向查询的查询次数,我们可以使用select_related方法实现,该方法只执行一次SQL查询就能达到反向查询的效果。select_related使用方法如下:
书里面的实例没找到方向,汗
select_related的使用说明如下:
1、以模型Product作为查询对象主体,当然也可以使用模型Type,只要两表之间有外键关联即可。
2、设置select_related的参数值为"type",该参数值是模型Product定义的type字段。
3、如果在查询过程中需要使用另一个数据表的字段,可以使用"外键__字段名"来指向该表的字段。如type__type_name代表由模型Product的外键type指向模型Type的字段type_name,type代表模型Product的外键type,双下划线"_"代表连接符,type_name是模型Type的字段
除此之外,select_related还可以支持三个或三个以上的数据表同时查询,以下面为例:
#models.py定义 fromdjango.db import models #省份信息表 class Province(models.Model): name = models.CharField(max_length=10) #城市信息表 class City(models.Model): name = models.CharField(max_length=5) province = models.ForeignKey(Province, on_delete=models.CASCADE) #人物信息表 class Person(models.Model): name = models.CharField(max_length=10) living = models.ForeignKey(City, on_delete=models.CASCADE)
在上述模型中,模型Person通过外键living关联模型City,模型City通过外键province关联模型Province,从而使三个模型形成一种递进关系。
例如查询张三现在所居住的省份,首先通过模型Person和模型City查出张三所居住的城市,然后通过模型City和模型Province查询当前城市所属的省份。因此,select_related的实现方法如下:
p = Person.objects.select_related('living_province').get(name='张三') p.living.province
在上述例子可以发现,通过设置select_related的参数值即可实现三个或三个以上的多表查询。例子中的参数值为living__province,参数值说明如下:
1、living是模型Person的字段,该字段指向模型City。
2、province是模型City的字段,该字段指向模型Province
3、两个字段之间使用双下划线连接并且两个字段都是指向另一个模型的,这说明在查询过程中,模型Person的字段living指向模型City,再从模型City的字段province指向模型Province,从而实现两个或三个以上的多表查询。
6.5 本章小结
Django对各种数据库提供了很好的支持,包括:PostgreSQL、MySQL、SQLite和Oracle,而且为这些数据库提供了统一的调用API,这些API统称为ORM框架。通过使用Django内置的ORM框架可以实现数据库连接和读写操作。
在Django中,虚拟对象数据库也成为模型。通过模型实现对目标数据库的读写操作,实现方法如下:
1、配置目标数据库信息,主要在settings.py设置数据库信息
2、构建虚拟对象数据库,在App的models.py文件以类的形式定义模型
3、通过模型在目标数据库中创建相应的数据表
4、在视图函数中通过对模型操作实现目标数据库的读写操作
一个模型对于目标数据库的一个数据表,但我们知道,每个数据表之间是可以存在关联的,表与表之间有三种关系:一对一、一对多和多对多,说明如下:
1、一对一存在于两个数据表中,第一个表的某一行数据只与第二个表的某一行数据相关,同时第二个表的某一行数据也只与第一个表的某一行数据相关,这种表关系被称为一对一关系。
2、一对多存在于两个或两个以上的数据表中,第一个表的数据可以与第二个表的一道多行数据进行关联,但是第二个表的每一行数据只能在第一个表的某一行进行关联。
3、多对多存在于两个或两个以上的数据表中,第一个表的某一行数据可以与第二个表的一到多行数据进行关联,同时在第二个表中的某一行数据也可以与第一个表的一到多行数据进行关联。
区分查询条件get和filter的差异,两者区别如下:
1、查询条件get:查询字段必须是主键或者唯一约束的字段,并且查询的数据必须存在,如果查询的字段有重复值或者查询的数据不存在,程序都会抛出异常信息。
2、查询条件filter:查询字段没有限制,只要该字段是数据表的某一个字段即可。查询结果以列表的形式返回,如果查询结果为空(查询的数据在数据库中找不到),就返回空列表。
在多表查询中,应掌握select_related的使用方法。以模型Product和Type为例,说明如下:
1、以模型Product作为查询对象主体,当然也可以使用模型Type,只要两表之间有外键关联即可。
2、设置select_related的参数值为"type",该参数值是模型Product定义的type字段。
3、如果在查询过程中需要使用另一个数据表的字段,可以使用"外键__字段名"来指向该表的字段。如type__type_name代表由模型Product的外键type指向模型Type的字段type_name,type代表模型Product的外键type,双下划线"__"代表连接符,type_name是模型Type的字段。