在没有学习函数之前我们的程序是面向过程的,不停的判断,不停的循环,同样的代码重复出现在我们的代码里。函数可以更好的提高我们的 代码质量,避免同样的代码重复出现,而只需要在用的时候调用函数即可执行。此为函数式编程。
函数的定义与执行:
定义函数:def 函数名():
执行函数:函数名()
def func(): #定义函数 print('你好') #函数体 func() #执行函数
#输出结果:
你好
如下需求:
让用户输入年龄,如果小于18岁,打印你好,并打印你是未成年人,否则打印你好,并打印你是未成年人。
无函数实现:
age = input('请输入你的年龄:') age = int(age) if age < 18: print('你好') print('你是未成年人') else: print('你好') print('你是成年人')
有函数实现:
def age1(): print('你好') print('你是未成年人') def age2(): print('你好') print('你是成年人') age = input('请输入你的年龄:') age = int(age) if age < 18: age1() else: age2()
函数的返回值 return
函数在retrun后将终止,后面的内容不执行
def func(): return True print('a') #这里的内容在retru之后,所以兵不执行 print(func())
#输出结果:
True
函数的参数
普通参数:
上例无参数函数:
def age1(): print('你好') print('你是未成年人') def age2(): print('你好') print('你是成年人') age = input('请输入你的年龄:') age = int(age) if age < 18: age1() else: age2()
上例有参数函数:
一个参数
def age(args): print('你好') print('你是%s' %args) age = input('请输入你的年龄:') age = int(age) if age < 18: age('未成年人') else: age(‘成年人')
两个参数:
def func(args1,args2): print(args1) print(args2) func(1,2) #执行此函数是两个参数按照位置对应,第一个是args1,第二个sargs2
#输出结果:
1
2
默认参数:
默认参数只能放在参数的最后面
def func(args1,args2=1111):#args2默认为1111,即如果执行函数时不指定args2则args2的参数值为1111 print(args1) print(args2) func(1) #执行函数时没有指定args2 #输出结果: 1111 func(100,200) #执行函数的时候指定了args2 #输出结果: 100 100
指定参数:
如果一个函数有多个函数,在执行函数的时候是按照参数顺序分别赋予args1,args2,args3等,指定参数跟参数位置无关。
示例:
def func(args1,args2,args3): print(args1) print(args2) print(args3) func(args3=300,args1=100,args2=200) #输出结果: 100 200 300
动态参数:
类似*args **kwargs,前者会把参数转换为元祖,后者会把函数转换为字典
#传没有事先定义的参数
def s2(*ar,**ar2): print(ar,type(ar)) print(ar2,type(ar2)) s2(a=1) #如果想传字典进去必须用长的方式 s2(1,2,3,4) # 这样的参数将被全部转换成数组 #输出结果: () <class 'tuple'> #传进来的a=2,被转换成字典,因此*ar参数不存在,故为空元祖 {'a': 1} <class 'dict'> #**ar2的参数返回结果 (1, 2, 3, 4) <class 'tuple'> #*ar的返回结果 {} <class 'dict'>
#传一个已经定义好的变量的参数
def s2(*ar,**ar2):
print(ar,type(ar))
print(ar2,type(ar2))
l1 = [1,2,3,45,]
d1 = {'1':'a','2':'b'}
#我们的初衷是想把l1和d1分别赋值给*ar和**ar2
s2(l1,d1)
#输出结果:
([1, 2, 3, 45], {'1': 'a', '2': 'b'}) <class 'tuple'> #但是结果并不是我们预想的那样,函数把所有的参数转换成一个元祖了。
{} <class 'dict'>
因此我们应该这样执行函数
s2(*l1,**d1)
#输出结果:
(1, 2, 3, 45) <class 'tuple'>
{'1': 'a', '2': 'b'} <class 'dict'>
动态参数在字符串格式化方法中的应用体现:
strs = '{0} is {1}' lists = ['a','b'] result = strs.format(*lists) print(result) #输出结果: a is b
lambda 表达式
my = lambda a:a+100 print(my(100)) #输出结果: 200
常用内置函数

map函数
便利整个序列内的元素,并对每个元素进行操作,然后输出。
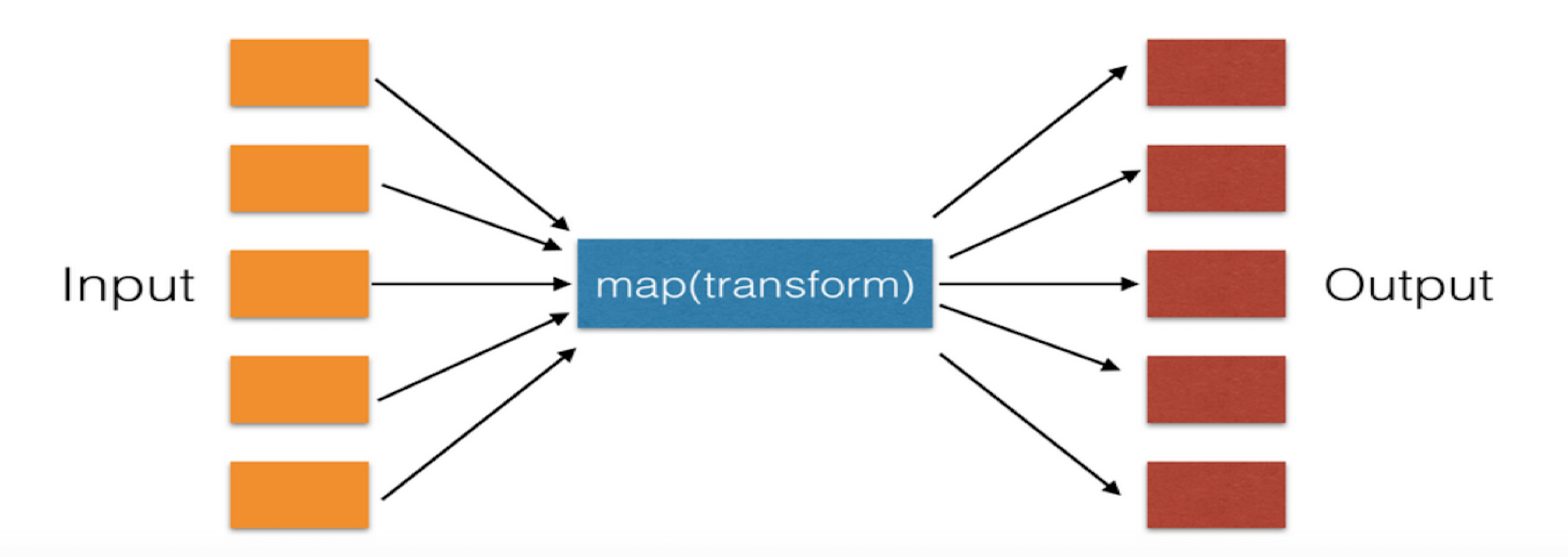
li = [1,2,3,23,42,12,3,56,34,2,3,2,23,23,2,3,4,44,44,4,343,0,] a = list(map(lambda args:args+100,li)) print(a) #输出结果: [101, 102, 103, 123, 142, 112, 103, 156, 134, 102, 103, 102, 123, 123, 102, 103, 104, 144, 144, 104, 443, 100]
filter函数:
对序列内的每个元素过滤,只有返回为True的才会输出,两个参数,args1为函数,args2为序列,args1可以为None,则过滤空值的预算
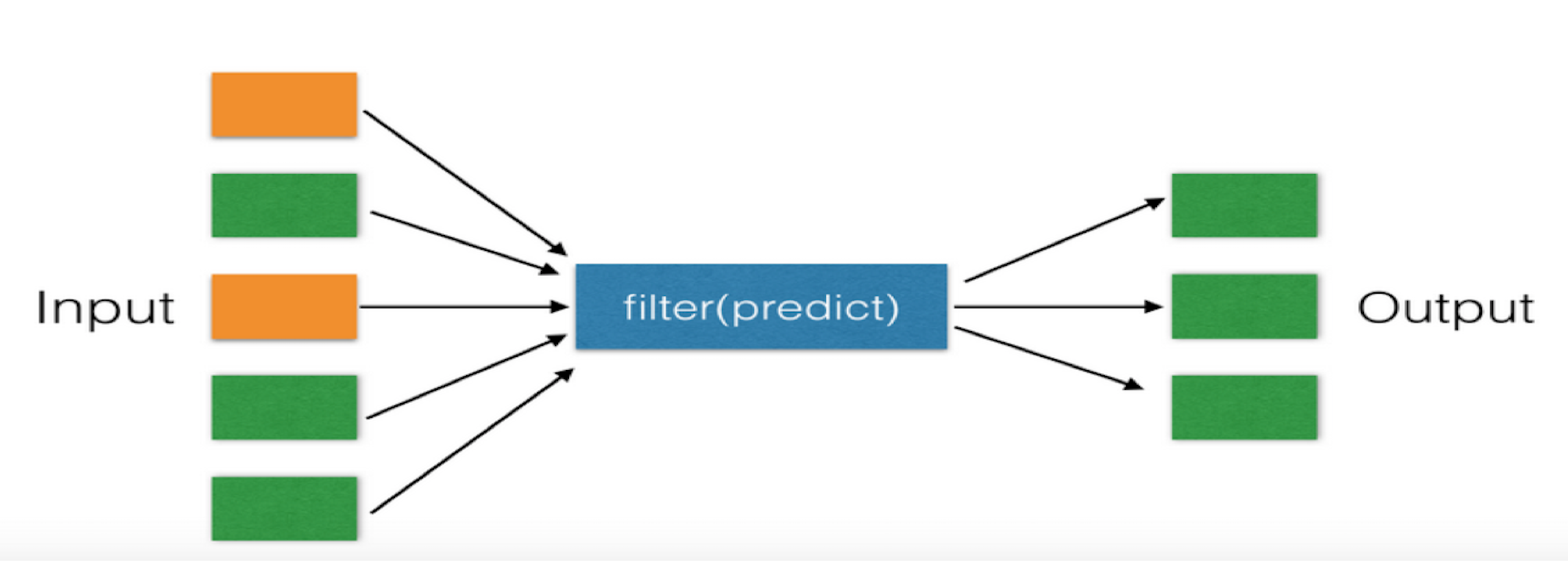
#参数为None,只输出非空元素 li = [1,2,3,23,42,12,3,56,34,2,3,2,23,23,2,3,4,44,44,4,343,0,''] a = list(filter(None,li)) print(a) #输出结果: [1, 2, 3, 23, 42, 12, 3, 56, 34, 2, 3, 2, 23, 23, 2, 3, 4, 44, 44, 4, 343] #参数为lambda函数,输出条件为True的元素 li = [1,2,3,23,42,12,3,56,34,2,3,2,23,23,2,3,4,44,44,4,343,0,] a = list(filter(lambda a:a>20,li)) print(a) #输出结果: [23, 42, 56, 34, 23, 23, 44, 44, 343]
#以自定义函数作为参数
li = [1,2,3,23,42,12,3,56,34,2,3,2,23,23,2,3,4,44,44,4,343,0,]
def func(args):
return args >20 and args <200
a = list(filter(func,li))
print(a)
#输出结果:
[23, 42, 56, 34, 23, 23, 44, 44]
reduce函数
对于序列内所有元素进行累计操作
注意:
在Python 3里,reduce()函数已经被从全局名字空间里移除了,它现在被放置在fucntools模块里
用的话要 先引入
from functools import reduce
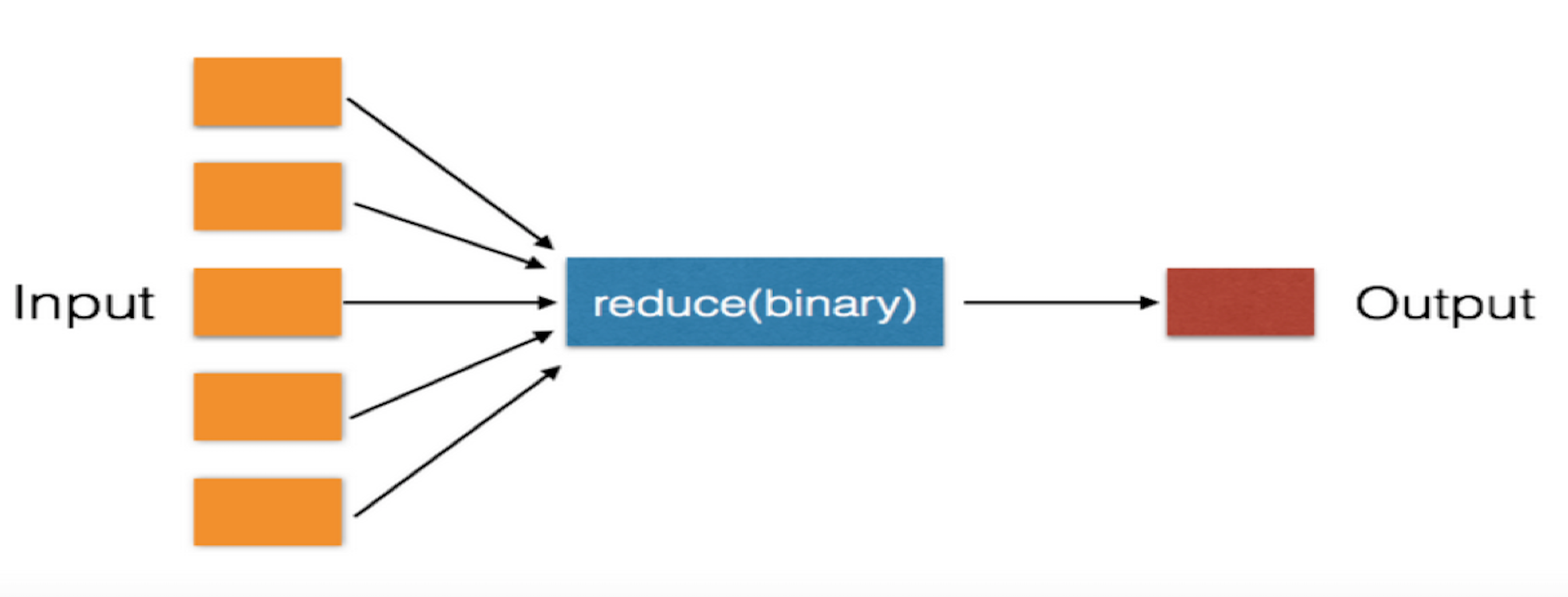
import functools li = [1,2,3,23,42,12,3,56,34,2,3,2,23,23,2,3,4,44,44,4,343,0,] a = functools.reduce(lambda args1,args2:args1+args2,li) print(a) #输出结果: 673