Model进阶用法
回顾
Django中的model层主要和数据库进行交互,使用数据库API对数据库进行增删改查的操作。
下面将介绍关于model层更深入的用法。
下面是之前创建model的代码:
from django.db import models
class Publisher(models.Model):
name = models.CharField(max_length=30)
address = models.CharField(max_length=50)
city = models.CharField(max_length=60)
state_province = models.CharField(max_length=30)
country = models.CharField(max_length=50)
website = models.URLField()
def __unicode__(self):
return self.name
class Author(models.Model):
first_name = models.CharField(max_length=30)
last_name = models.CharField(max_length=40)
email = models.EmailField()
def __unicode__(self):
return u'%s %s' % (self.first_name, self.last_name)
class Book(models.Model):
title = models.CharField(max_length=100)
authors = models.ManyToManyField(Author)
publisher = models.ForeignKey(Publisher)
publication_date = models.DateField()
def __unicode__(self):
return self.title
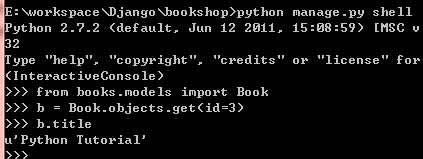
但是有一点我们没有进行介绍,那就是有关外键和多对多字段的查询。
访问外键
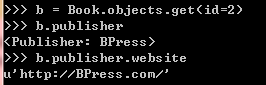
因为对于一本书来说,只有一个出版商,而对于一个出版商来说,可以出很多书,这是一个
一对多的关系。因为代码中在Book类中定义了和Publisher的一对多的关系,而Publiser没
有定义和Book。所以,从"一"中查询"多"的有所不同:

book_set是一个QuerySet类型,也可进行filter,slice操作。Django中支持一对多关系中,从
"一"的属性访问"多"属性+"_set",来获得相应的"多属性"的记录信息,返回的是QuerySet类型。
访问多对多关系
和访问外键相似,因为在Book类中定义和Author的多对多的关系,所以直接操作的是QuerySet的值,
对于书和作者的多对多的关系,可以进行filter等操作,操作如下:

而在Author类中没有定义和Book的关系,也需要_set进行操作:

更改数据库结构
之前介绍过可以使用python manage.py syncdb去根据model定义创建数据库中不存在的表。
但它对model中的字段的改变或者是删除操作都不会同步到数据库中,只能手动去更改数据库的
结构。在MySQL数据中,你就需要ALTER操作。
当处理数据库结构改变时,需要注意到几点:
1. 当model中含有数据库表中没有的字段时,比如在model中添加了某个字段,没有对数据库表进行
相应的改变,Django会在你第一次使用API访问该表时会报错。
2. 当数据库表中含有model中没有的字段时,比如在model中删除了某个字段,没有对数据库表进行
相应的改变时,Django可以正常运行。
3. 当数据库中含有没有和model对应的表时,比如删除了某个model,没有对数据库进行相应的改变时,
Django可以正常运行。
所以在改变model和数据库的时候,注意按照正确的顺序,以免报错。
增加字段
当你在准备在表和model中加入新的字段的时候,参考上面的第2点,为了不报错,策略就是
先在数据库中进行表结构更改,再在你的model代码中进行更改。
然而当你先使用SQL语句对数据库表进行操作的时候,最好采用和sync命令时Django对数据库
进行的一样的操作,这样可以保证你的SQL和Django的SQL操作的一致性。查看Django的创建
表时的SQL的命令是python manage.py sqlall [app name]。但如果先在model中加新的字段,
用命令去查看Django的SQL语句,Django在运行的时候又会报错。怎样去解决这一矛盾问题呢?
解决这一矛盾的方法就是你需要使用的是开发服务器和产品服务器,两个环境。
首先在开发环境中:
1. 在model中加入新的字段
2. 运行python manage.py sqlall,查看Django的SQL语句,确认新字段在SQL的定义写法
3. 按照第2步查看到的定义写法,对数据库进行Alter table的操作。
4. 运行python manage.py shell,导入重新定义的model,确认各种API操作不报错。
再到产品环境中:
1. 首先按照上面的查看到的SQL对数据库进行Alter table操作。
2. 再在你的model中加入新的字段
3. 重启server,让代码生效。
比如我们现在向Book类中进行更改。
1. 在model中新加入一个num_pages的属性:
class Book(models.Model):
title = models.CharField(max_length=100)
authors = models.ManyToManyField(Author)
publisher = models.ForeignKey(Publisher)
publication_date = models.DateField(blank=True, null=True)
num_pages = models.IntegerField(blank=True, null=True)
def __unicode__(self):
return self.title
2.运行python manage.py sqlall books, 查看Django的SQL语句
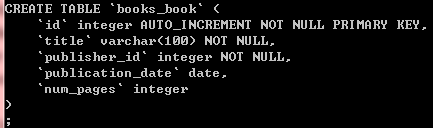
3.改变数据库表结构

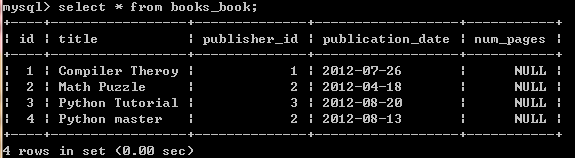
因为在model中设定的num_pages属性是可以为NULL,如果你在添加NOT NULL的字段时,
你需要遵循的步骤是:
a. 首先创建可以为NULL的字段
b. 修改字段的默认值为某非空值
c. 最后再修改字段的属性为NOT NULL
4. 运行python manage.py shell,验证Django的数据库操作正确。
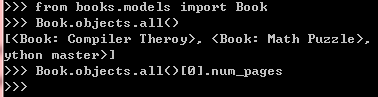
无报错,说明添加字段正确。
删除字段
比添加字段简单,步骤是:
1. 首先从model中删除一个字段,并重启服务器
2. 再在数据库表中删除该字段
mysql>ALTER TABLE book DROP COLUMN num_pages;
需要注意的是,如果先在数据库中删除字段的话,Django会报错。
删除多对多字段
步骤和删除一般的字段有所不同:
1. 从model删除该字段,并重启server
2. 从数据库中删除多对多的那张关系表
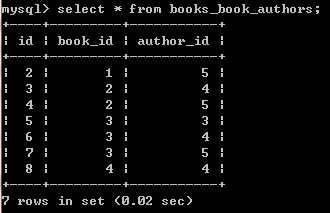
mysql>DROP TABLE books_book_authors;
对于多对多的关系,一般在数据库设计中,就会使用一张针对多对多关系的表,来
减少数据冗余问题,Django也会根据这个原则,创建这张有关系表:
删除model
步骤和删除一般字段一样:
1. 删除model.py文件,并重启server
2. 删除数据库表,要注意的需要先删除和该表的外键关系字段
mysql>DROP TABLE books_book;
Manager管理器
管理器是Django查询数据库时会使用到的一个特别的对象,在Book.objects.all()语法中,
objects就是管理器,每一个model至少有一个管理器,而且,你也可以创建自己的管理器来
自定义你的数据库访问操作。一方面可以增加额外的管理器方法,另一方面可以根据你的需求来
修改管理器返回的QuerySet。
给管理器添加新的方法
这是一种"表级别"的操作,下面我们给之前的Book类增加一个方法title_count(),它根据关键字,
返回标题中包括这个关键字的书的个数。
class BookManager(models.Manager):
def title_count(self, keyword):
return self.filter(title__icontains=keyword).count()
class Book(models.Model):
title = models.CharField(max_length=100)
authors = models.ManyToManyField(Author)
publisher = models.ForeignKey(Publisher)
publication_date = models.DateField()
num_pages = models.IntegerField(blank=True, null=True)
#可以直接赋值替换掉默认的objects管理器,也可以定义一个新的管理器变量
#调用时,直接使用这个新变量就可以了,一旦定义了新的管理器,默认管理器
#需要显示声明出来才可以使用
# objects = models.Manger()
objects = BookManager()
def __unicode__(self):
return self.title
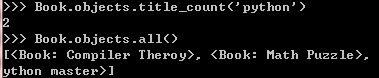
上面的代码可以看到,创建自定义的Manager的步骤:
1. 继承models.Manager,定义新的管理器方法,在方法中使用self,也就是manager本身来
进行操作
2. 把自定义的管理器对象赋值给objects属性来代替默认的管理器。
为什么不直接创建个title_count函数来实现这个功能呢?
因为创建管理器类,可以更好地进行封装功能和重用代码。
修改返回的QuerySet
Book.objects.all()返回的是所有记录对象,可以重写Manager.get_query_set()方法,它返回的是
你自定义的QuerySet,你之后的filter,slice等操作都是基于这个自定义的QuerySet。
from django.db import models
class RogerBookManager(models.Manager):
def get_query_set(self):
#调用父类的方法,在原来返回的QuerySet的基础上返回新的QuerySet
return super(RogerBookManager, self).get_query_set().filter(title__icontains='python')
class Book(models.Model):
title = models.CharField(max_length=100)
author = models.CharField(max_length=50)
#objects默认管理器需要显示声明,才能使用
objects = models.Manager() # 默认的管理器
roger_objects = RogerBookManager() # 自定义的管理器,用新变量
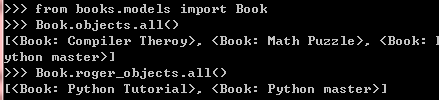
你可以为model定义多个不同的管理器来返回不同的QuerySet,不过要注意一点的是Django
会把你第一个定义的管理器当作是默认的管理器,也就是代码行中最上面定义的管理器。Django
有些其它的功能会使用到默认的管理器,为了能让它正常的工作,一种比较好的做法就是把原始默认
的管理器放在第一个定义。
Model的方法
和管理器的"表级别"操作相比,model的方法更像是"记录级别"的操作,不过,model的主要设计是用来
用"表级别"操作的,"记录级别"的操作往往是用来表示记录的状态的,是那些没有放在数据库表中,但是也
有意义的数据。举例说明:
from django.db import models
class Person(models.Model):
first_name = models.CharField(max_length=50)
last_name = models.CharField(max_length=50)
birth_date = models.DateField()
address = models.CharField(max_length=100)
city = models.CharField(max_length=50)
# 用来判读是否在baby boomer出生,可以不用放在数据库表中
def baby_boomer_status(self):
"Returns the person's baby-boomer status."
import datetime
if datetime.date(1945, 8, 1) <= self.birth_date <= datetime.date(1964, 12, 31):
return "Baby boomer"
if self.birth_date < datetime.date(1945, 8, 1):
return "Pre-boomer"
return "Post-boomer"
# 用来返回全名,这个可以不被插入到数据库表中
def get_full_name(self):
"Returns the person's full name."
return u'%s %s' % (self.first_name, self.last_name)
>>> p = Person.objects.get(first_name='Barack', last_name='Obama')
>>> p.birth_date
datetime.date(1961, 8, 4)
>>> p.baby_boomer_status()
'Baby boomer'
>>> p.get_full_name()
u'Barack Obama'
>>> p.birth_date
datetime.date(1961, 8, 4)
>>> p.baby_boomer_status()
'Baby boomer'
>>> p.get_full_name()
u'Barack Obama'
执行自定义SQL语句
如果你想执行自定义的SQL语句查询,可以使用django.db.connection对象:
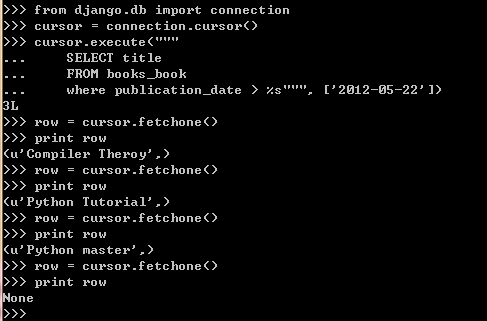
可以使用SQL对数据库中所有的表进行操作,而不用引用特定的model类。
需要注意的是execute()函数使用的SQL语句需要使用到%s这样的格式符,而
不是直接写在里面。
这样的操作比较自由,比较好的做法是把它放在自定义管理器中:
from django.db import connection, models
class PythonBookManager(models.Manager):
def books_titles_after_publication(self, date_string):
cursor = connection.cursor()
cursor.execute("""
SELECT title
FROM books_book
WHERE publication_date > %s""", [date_string])
#fetchall()返回的是元组的列表
return [row[0] for row in cursor.fetchall()]
class Book(models.Model):
title = models.CharField(max_length=100)
authors = models.ManyToManyField(Author)
publisher = models.ForeignKey(Publisher)
publication_date = models.DateField(blank=True, null=True)
num_pages = models.IntegerField(blank=True, null=True)
objects = models.Manager()
python_objects = PythonBookManager()

具体的Python DB API在这里:
作者:btchenguang
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利.