C++程序设计
之前学过C++课程,但是时间有点久,忘了很多,这里做一个简单的回顾。
网站推荐: C++在线编译器
学习C++之前,您可以先了解C语言。
c++的扩展名一般为cpp(cplusplus)。
补充: 这里介绍了如何编译和执行C++文件,即一般需要下面的步骤:
-
在文件的外面shift + 右键单击,选择cmd打开文件(cpp的外层文件)
-
g++ 文件名.cpp -o test
-
test
通过这三步就可以编译C++文件了。
注意:1. 每次如果修改了文件,都需要在g++ 文件名.cpp -o test来重新编译文件得到文件名.exe可执行文件,然后在执行即可。这时新的可执行文件就可以覆盖旧的可执行文件。
2. 在notepad++中的设置-> 语言设置中将语言设置为C++
第一部分: 面向对象程序设计概述
1 面向过程的程序设计和面向对象的程序设计
面向对象程序设计与面向过程程序设计有着本质的区别。
面向过程程序设计是以功能为中心,数据和操作数据的函数(或过程)相分离,程序的基本构成单位是函数。
而面向对象程序设计是以数据为中心,数据和操作数据的函数被封装成一个对象,与外界向分隔,对象之间通过消息进行通信,使得各对象完成相应的操作,程序的基本构成单位是对象。
简单地说,面向过程的程序设计是以函数为基本构成单位; 而面向对象的程序设计是以对象为基本构成单位。
2. 为什么C++是面向对象的程序设计? 面向过程的程序设计有什么不足呢?
-
面向过程的程序设计是围绕功能进行的,用一个函数实现一个功能。 所有的数据都是公用的,一个函数可以使用任何一组数据,而一组数据又可以被多个函数所使用。 当程序规模较大时、数据很多时,程序设计者往往感到难以应付。 所以面向过程的程序设计往往只适用于规模较小的程序。
-
面向过程的程序设计其数据是公有的,谁也没有办法限制其他的程序员不去修改全局数据,也不能限制其他程序员在函数中定义与全局数据同名的全局变量,故很不安全。
-
由于面向过程程序设计的基本单位是函数,所以代码重用的最大粒度就是函数,对于今天的软件开发来说,程序修改的难度很大。
基于以上面向过程的程序设计的不足,人们提出了面向对象的程序设计。
3. 面向对象的编程思想
(1)客观世界中的事物都是对象(object),对象之间存在一定的关系。
(2)用对象的属性(attribute)描述事物的静态特征,用对象的操作(operation)描述事物的行为(动态特征)。
(3)把对象的属性和操作结为一体,形成一个相对独立、不可分的实体。对象对外屏蔽其内部细节,只留下少量接口,以便和外界联系。
(4)通过抽象对对象进行分类,把具有相同属性和相同操作的对象归为一类,类是这些对象的描述,每个对象是其所属类的一个实例。
(5)复杂的对象可以使用简单的对象作为其构成部分。
(6)通过在不成程度上运用抽象的原则,可以得到一般类和特殊类。特殊类可以继承一般类的属性和操作,从而简化系统的构造过程。
(7)对象之间通过传递消息进行通信,以实现对象之间的动态联系。
(8)通过关联表达类之间的静态关系。
4. 面向对象的基本概念
1. 对象
从现实角度来说, 现实世界中的任何一个事物都可以看做一个对象,如汽车、房屋等,这些都是有形的;又如文章、计划等,这些都是无形的。对象有大有小,如一个军队是一个对象,一个蚂蚁也是一个对象。
任何一个对象都具有两个基本要素:属性和行为。属性是用来描述对象的静态特征。行为是用来描述事物的动态特征。 如一个人是一个对象,其身高、性别就可以看做属性,其可以走路、说话、打球就可以看做其行为。
且在对象之间一定要有联系,如电视这个对象被人这个对象按了一下开机按钮, 电视这个对象就开机了,这就是对象与对象之间的联系。
总结:对象具有表示静态特征的属性和表示动态特征的行为,对象与对象之间需要传递信息来联系。
2. 类
类是对客观世界中具有相同属性和行为的一组对象的抽象,它为属于该类的全部对象提供了统一的对象描述,其内容同样包括对象和属性。
那么什么是抽象呢? 抽象就是指忽略事物的非本质特征,只注意那些和当前目标有关的本质特征,从而找出事物的共性。比如人就可以看做一个类,即人类,其中他是世界上所有实体人如张三、李四、王五的抽象。
总结:类是对象的抽象,而对象则是类的实例,或者说是类的具体表现形式。
3. 封装
日常生活中的封装很多,如录像机,从外面来看他就是一个黑盒子,在他的表面有几个按键,而其内部的电路板和机械控制部件在外面是看不到的。
这样做的好处在于大大降低了人们操作对象的复杂程度,使用对象的人完全不需要知道对象内部的具体细节,只需要了解其外部功能即可自如地操作对象。
在面向对象方法中,所谓“封装”即包括两方面的含义:(1)用对象把属性和操纵这些属性的操作保证起来,形成一个基本单位,各个对象之间相互独立,互不干扰; (2)将对象中某些部分对外影藏,即影藏其内部细节,只留下少量的接口,以便于和外部联系,接受外界的消息。
4. 继承
所谓继承是特殊类自动地拥有或者是隐含地复制其一般类的全部属性和操作。
集继承具有‘是一种’的含义,如卡车“是一种”汽车,“轿车”是一种汽车,二者作为特殊类继承了一般类 --汽车类的所有的属性和操作。
我们也可以一个特殊类继承多个一般类,这就是多继承的概念。如继承了“销售”类和“经理”类就是“销售经理”。
C++提供的继承机制,就可以很方便的在一个已有的类的基础上建立一个新类,这就是常说的“软件重用”的思想。
5. 消息
对象之间通过消息进行通信,实现了对象之间的动态联系。 在C++中,消息就是函数调用。
6. 关联
关联是两个多多个类之间的一种静态关系。 如一个教室类可以管理一个学生类
7. 组合
组合描述的类和类之间的整体和部分之间的关系。如汽车和发动机之间的关系就是组合。 其实,组合是关联的一种。
8. 多态性
如某个董事长出差,他把这个消息告诉了身边的人: 妻子、司机、秘书。 这些人听到之后会有不同的反应:他的妻子给他准备行李、秘书为他确认考察地安排住宿、司机会为他准备车辆。 这就是多态。
在面向对象方法中,所谓多态性是指由继承而产生的相关而不同的类,其对象对同一个消息会做出不同的响应。
第二部分:基础知识
1. C++是什么?
C++ 是一种静态类型的、编译式的、通用的、大小写敏感的、不规则的编程语言,支持过程化编程、面向对象编程和泛型编程。
C++ 被认为是一种中级语言,它综合了高级语言和低级语言的特点。
C++ 是由 Bjarne Stroustrup 于 1979 年在新泽西州美利山贝尔实验室开始设计开发的。C++ 进一步扩充和完善了 C 语言,最初命名为带类的C,后来在 1983 年更名为 C++。
C++ 是 C 的一个超集,事实上,任何合法的 C 程序都是合法的 C++ 程序。
注意:使用静态类型的编程语言是在编译时执行类型检查,而不是在运行时执行类型检查。
2. 基本结构

#include <iostream>using namespace std;
// mainint main () { cout << "朱振伟"; return 0; }
-
C++定义了一些有用的头文件,我们必须引入<iostream>, 否则类似cout和cin 的输入输出都是不可用的。
-
using namespace std;这是一个语句,所以一定要用分号结尾。 这是C++中的命名空间,js中是没有的。
-
// main 其中// 表示单行注释,这里所在的语句表示程序开始的地方,我们写代码一般都是要在这里写的。
-
下一行 int main() 是主函数,程序从这里开始执行。
-
cout一定要和<<配合使用,指的是输出。
-
return 0; 表示终止函数,在C++中一般都是这样来写的。当然, return 8; return 45;什么的都是可以的。
-
注意:C++中和js一样,都是使用;分号来表示语句的结束,但是和js不同的是,js某些情况下可以省略,但是C++中永远都不可以。
注意:我们也可以不适用 using namespace std; 但是在程序中我们如果要使用cin和cout就必须在其前面添加 std::如下所示:
#include <iostream>int main()
{ static int zhu = 15;
std::cout << zhu ;
}
最终会输出 15
3. C++中的标识符
在C++中,可以使用字母、下划线作为首字母,而后可以跟字母、下划线和数字。 注意:c++中是不支持$的,这点需要格外注意。 且C++是区分大小写的。
4. 和js一样,C++中也有一些保留字,我们再给变量命名的时候,是不能使用的。
5. C++中的数据类型有哪些?
-
bool 布尔型
-
char 字符型
-
int 整型
-
float 浮点型
-
double 双浮点型
-
void 无类型
-
wchar_t 宽字符型
上面是七种基本类型,每一种基本类型还可以使用一个多多个类型修饰符进行修饰。类型修饰符如下:
-
short
-
long
-
signed
-
unsigned
不同的类型所占的内存是不同的,我们可以使用sizeof()方法来输出,如下所示:
#include <iostream>using namespace std;int main()
{
cout << sizeof(int) << endl << sizeof(char) << endl << sizeof(bool) << endl << sizeof(double); return 0;
}
如上面的代码会得到 4 1 1 8,可以看出double所占的字节数是最多的。
http://www.cnblogs.com/BeyondAnyTime/archive/2012/08/23/2652696.html C++中的四种类型转化方式。
6. typedef
C++中typedef 的作用是将一个已有的类型的名称修改,def即定义的意思,如下所示:
typedef int zhu;
zhu vari;
那么这时的vari就是整型变量。
7. 变量的声明和初始化
int a;
bool b;
char c;
上述都是变量的声明。我们还可以在声明的同时初始化。
int a = 15;
bool b = true;
char c = "good";
int e = 15, f = 45;
我们还可以看到,我们可以一次声明并且初始化多个变量。
注意: 变量的初始化是一个好习惯,我们最好每次再定义变量的时候都要初始化;
看下面的例子:
#include <iostream>using namespace std;
int main ()
{ int zhu = 20;
cout << zhu << endl ;
return 0;
}
最终会输出20。
我们再看一个函数调用的例子。
#include <iostream>using namespace std;int add();int main ()
{
add(); return 0;
}int add()
{ int zhu = 10;
cout << zhu;
}
最终会输出20.
注意:
-
函数如何要调用,就一定要先声明,如 int add(); 或者之间在前面定义好。
-
另外可以看到C++中定义函数直接使用 int 变量名(); 即比一般的变量多了一个()即可。 且由于C++是自上而下执行的,所以我们必须提前声明,这样,会自动找到处于下方的函数定义。
8. c++中的变量
一般,在c++中可以有三个地方声明变量,一个是 代码块内部声明变量,此即局部变量。 还可以在函数的参数中声明变量,这是形式参数。 也可以在函数外面声明变量,这是全局变量。
其中局部变量只能在代码块中使用,全局变量可以在函数内也可以在函数外,即全局变量一旦声明,在整个程序中都是可用的。且和js一样,可以在代码块中声明和全局变量相同的名字,只是在代码块中使用会覆盖全局变量。
如下:
#include <iostream>using namespace std;
// 全局变量声明int g = 20;
int main ()
{ // 局部变量声明
int g = 10;
cout << g;
return 0;
}
最后输出的是 10。
9. 定义常量
在C++中,定义常量有两种方式,一种是使用 #define 常量名 常量值 显然使用这种方式常量值的类型是不确定的。 还有一种可以确定常量值的类型的,就是使用 const 类型 变量名 = 变量值; 举例如下:
#include <iostream>using namespace std;#define zhu 100int main() { const int he = 99;
cout << zhu << endl << he;
}
此代码最终就会输出 100 99。
10. C++存储类
C++中的存储类用于定义其变量(函数)的声明周期和范围(可见性)。下面主要介绍几种:
-
自 C++ 11 以来,auto 关键字用于两种情况:声明变量时根据初始化表达式自动推断该变量的类型、声明函数时函数返回值的占位符。 这种方式似乎和js中的var是一样的,我们看看下面的例子:
#include <iostream>using namespace std;int main()
{
auto zhu = 15;
auto z = 'h';
cout << zhu << endl << z;
}
最终输出 15(int类型)和 h(字符)
-
register 存储类用于定义存储在寄存器中而不是 RAM 中的局部变量。这意味着变量的最大尺寸等于寄存器的大小(通常是一个词),且不能对它应用一元的 '&' 运算符(因为它没有内存位置)。使用register要声明类型,如下:
#include <iostream>using namespace std;int main()
{
register int zhu = 15;
cout << zhu ;
}
-
static我们知道一般情况下全局变量会始终存在,但是局部变量一旦被调用过后就会被销毁。但是如果我们使用 static 关键字。那么这个变量即使是局部变量也可以恒久存在,也就是说 static既可以用在局部变量也可以用在全局变量上。
#include <iostream>using namespace std;int main()
{ static int zhu = 15;
cout << zhu ;
}
最终会输出 15
11. C++中的运算符
在C++中,和其他语言一样,都有自己的运算符,如 + - / * 等等,指的注意的是,判断是否相等,使用 == 即可,不像js中使用 === 的情况。
想要了解更多,点击这里。
12. C++函数
什么是函数? 函数就是很多语句组合在一起可以做某一件事情的东西。 这就是函数。每个 C++ 程序都至少有一个函数,即主函数 main() ,所有简单的程序都可以定义其他额外的函数。
另外:C++标准库还提供了大量的我们可以直接使用的内置函数, 如 strcat()用于拼接两个字符串等等。
和js的函数不同的是,C++的函数直接使用 int 即可,当然最后在函数内部你也要返回相应的int值,如return 0; 另外就是在传递参数的时候要使用 int类似的类型确定其类型,举例如下:
int max(int num1, int num2)
{ // 局部变量声明
int result;
if (num1 > num2)
result = num1; else
result = num2;
return result;
}
这就是一个很常见的函数了, int确定函数的类型, max为函数名,我们调用函数的时候就使用该函数名。 传入两个参数,必须使用 类型声明。 最后返回一个int类型的值。
当然这个是函数定义,我们也可以在前面先声明,即 int max(int, int); 可以发现这里省略了 num1和num2,因为这些都是不重要的, 类型正确即可。
13. 函数参数
c++中的函数参数是形式参数,其和函数内的其他局部变量实际上是一样的。即在进入时被创建, 执行结束被销毁。
如下所示:

即一般情况下我们使用的是传值调用,即这是把实际值复制给了函数的形式参数,所以,在这种情况下,修改函数内部的形式参数对实际值没有影响。
#include <iostream>using namespace std;int a = 15;int b = 20;int modify(int, int);int main()
{
modify(a, b);
cout << "主函数的a:" <<a << endl << "主函数的b:" << b;
}int modify(int a, int b)
{
a = a + 85;
b = b + 20;
cout << "函数内部的a:" <<a << endl << "函数内部的b:" << b << endl ;
}
结果如下:
函数内部的a:100函数内部的b:40主函数的a:15主函数的b:20
可以看到: 在函数内部修改了传进来的参数,只是修改了clone版本,并没有修改真正的a和b。 这也就是传值调用。
在C++的函数中,我们也可以使用 参数的默认值,即如果传入了该参数,那么就是用; 如果没有传入,就是用默认值,如下所示:
int sum(int a, int b=20)
{ int result;
result = a + b;
return (result);
}
14. C++中的数字运算
我们可以引入 cmath库,然后使用C++自带的数字运算的函数,举例如下:
#include <iostream>
#include <cmath>using namespace std;int main()
{int a = -10;double b = 4.54;float c = 45.2;
cout << abs(a) << endl << sqrt(b) <<endl << pow(c, 2);
}
注意:这里必须引用 cmath库,即 #include <cmath> 然后就可以使用诸如 sqrt() abs() pow() floor() sin() cos() tan()之类的函数了。
15. 数组
在C++中声明数组的方法很简单,即:
int numbers[10];
其中int也可以换成其他你需要的类型,如 double等 。 在变量名后面的数字一定要大于0,这里为10表示这个数组中可以放下长度为10的数。
我们还可以初始化数组,只是这里初始化数组使用的是{},在数组的定义和初始化方面C++和js的差别较大。如下所示:
#include <iostream>
using namespace std;
int main()
{
int numbers[8] = {45, 12, 85, 56};
cout << numbers[0] << endl<< numbers[1] << endl<< numbers[2] << endl<< numbers[3] << endl;}
最终的输出结果: 45, 12, 85, 56
我们也可以不限制数组的长度: 如 int numbers[] = {45, 12, 85, 56};
16. C++字符串
在C++中,由于字符串的特殊性,一般情况下,我们是需要单独来将字符串的。在C++中有两种方式表示,一种是引入的C语言风格的,另一种是C++特有的。
char str[] = {'h', 'e', 'l', 'l','o', '�'};
字符串实际上是使用 null 字符 '�' 终止的一维字符数组。因此,一个以 null 结尾的字符串,包含了组成字符串的字符。 可以看出,这里字符串的写法与数组非常相似。
还可以写成下面这种形式:
char str[] = "hello";
上面两种方式的字符串的效果是一样的。
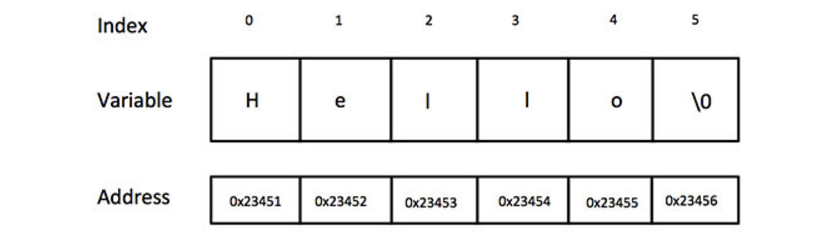
最终的存储形式就是这样,最后一位是使用null占位表示结束。
在C++中,有大量的处理字符串的内置函数,如果希望使用这样函数,需要引入cstring(正如数学运算引入了cmath一样)举例如下所示:
#include <iostream>
#include <cstring>using namespace std;int main()
{ char str1[] = "zhuzhenwei"; char str2[] = "hetingting";
cout << strlen(str1) << endl << strlen(str2) << endl;
cout << strcat(str1, str2) << endl;
}
最终输出:10 10 zhuzhenweihetingting
上面所说的都是C语言中字符串的实现,下面的是C++的。
C++ 标准库提供了 string 类类型,支持上述所有的操作,另外还增加了其他更多的功能。
看下面的例子:
#include <iostream>
#include <string>using namespace std;int main ()
{ string str1 = "Hello"; string str2 = "World"; string str3; int len ; // 复制 str1 到 str3
str3 = str1;
cout << "str3 : " << str3 << endl; // 连接 str1 和 str2
str3 = str1 + str2;
cout << "str1 + str2 : " << str3 << endl; // 连接后,str3 的总长度
len = str3.size();
cout << "str3.size() : " << len << endl; return 0;
}
值得注意的是: 这里引入的是:#include <string> 而不再是 #include <cstring>, 两者的区别在哪呢?
显然,cstring是c语言中的string,而string就是C++中类string,所以这里我们用到了链式调用,可以看出面向对象的C++使用起来多么方便,如果js也可以这样随便引入,就太好了。
17. C++指针
C++中比较有特色的当然就是指针了。这也是我复习C++的一个理由~ 看完这个就要睡觉啦~ 好困啊
哈哈,让我们先来看一看教程的说法:
学习 C++ 的指针既简单又有趣。通过指针,可以简化一些 C++ 编程任务的执行,还有一些任务,如动态内存分配,没有指针是无法执行的。所以,想要成为一名优秀的 C++ 程序员,学习指针是很有必要的。
恩,加油吧,捡起来这一部分内容,先看看下面的代码:
#include <iostream>using namespace std;int main ()
{ int var1; char var2[10];
cout << "var1 变量的地址: ";
cout << &var1 << endl;
cout << "var2 变量的地址: ";
cout << &var2 << endl; return 0;
}
这和之前的有什么区别的? 恩,就是多了个&, 这在C++中是用来取地址的,即你这个变量住在哪?(变量的内存地址) 看看输出的结果:
var1 变量的地址: 0x7fff9d7403ec
var2 变量的地址: 0x7fff9d7403f0
0X是指16进制的数字。
那么什么是指针呢?
指针是一个变量,其值为另一个变量的地址,即,内存位置的直接地址。声明指针的方式如下:
type *name;
如 int *p; 这里就声明了一个p指针,注意:这里带有*, 是说我声明了一个指针,但是并不是说*p是指针,因为p才是真正的指针,而*p是指这个p指针所指向地址的值。 *和指针是密切相关的。如下面的声明方式都是有效的指针声明:
int *ip; /* 一个整型的指针 */double *dp; /* 一个 double 型的指针 */float *fp; /* 一个浮点型的指针 */char *ch /* 一个字符型的指针 */
看看这个在C++中使用指针的例子:
#include <iostream>
using namespace std;int main ()
{ int var = 20; // 实际变量的声明
int *ip; // 指针变量的声明
ip = &var; // 在指针变量中存储 var 的地址,因为指针的值是地址!!!!!!!!!! 而&var 就是在取变量var 的地址。
cout << "Value of var variable: ";
cout << var << endl; // 输出在指针变量中存储的地址
cout << "Address stored in ip variable: ";
cout << ip << endl; // 访问指针中地址的值
cout << "Value of *ip variable: ";
cout << *ip << endl; // 这里ip是指针,它的值就是地址,而*ip是地址所在的值,故最终是20
return 0;
}
结果如下:
Value of var variable: 20
Address stored in ip variable: 0x7fff99a46294
Value of *ip variable: 20
18. C++引用
引用变量是一个别名,也就是说,它是某个已存在变量的另一个名字。一旦把引用初始化为某个变量,就可以使用该引用名称或变量名称来指向变量。
首先需要明白的是:引用不同于指针。
通俗的讲(个人理解),引用就是一个人的小名。看,比如指明了我这个大名:
int zzw = 8;
即8是我的身体,而zzw是代表我这个身体的大名 。
但是我还可以起一个小名,如下:
int& pig = zzw;
也就是说无论是大名zzw还是小名pig都指得是我自己, 叫我什么我都答应。
实例如下:
#include <iostream>
using namespace std;int main ()
{ int zzw = 8; int& pig = zzw;
cout << zzw << endl << pig << endl;
cout << "对引用进行修改" <<endl;
pig = 20;
cout << zzw << endl << pig;
return 0;
}
最终的结果如下所示:
88对引用进行修改2020
可以看到叫我小名我也答应你了(修改一个变量的引用,实际上就是修改它自己)。
19. C++数据结构
在C和C++的数组中可以定义存储相同数据类型的变量。 但是在C++中还提供了数据结构,在这个数据结构里我们可以定义不同类型的变量。

具体应用举例如下:
#include <iostream>
#include <cstring>
using namespace std;
// 声明一个结构体类型 Books struct Books
{ char title[50]; char author[50]; char subject[100]; int book_id;
};
int main( )
{
Books Book1; // 定义结构体类型 Books 的变量 Book1
Books Book2; // 定义结构体类型 Books 的变量 Book2
// Book1 详述
strcpy( Book1.title, "C++ 教程");
strcpy( Book1.author, "Runoob");
strcpy( Book1.subject, "编程语言");
Book1.book_id = 12345;
// Book2 详述
strcpy( Book2.title, "CSS 教程");
strcpy( Book2.author, "Runoob");
strcpy( Book2.subject, "前端技术");
Book2.book_id = 12346;
// 输出 Book1 信息
cout << "第一本书标题 : " << Book1.title <<endl;
cout << "第一本书作者 : " << Book1.author <<endl;
cout << "第一本书类目 : " << Book1.subject <<endl;
cout << "第一本书 ID : " << Book1.book_id <<endl;
// 输出 Book2 信息
cout << "第二本书标题 : " << Book2.title <<endl;
cout << "第二本书作者 : " << Book2.author <<endl;
cout << "第二本书类目 : " << Book2.subject <<endl;
cout << "第二本书 ID : " << Book2.book_id <<endl;
return 0;
}
另外,数据结构也可以作为参数传递进去,如下所示:
#include <iostream>
#include <cstring>
using namespace std;
void printBook( struct Books book );
// 声明一个结构体类型 Books struct Books
{ char title[50]; char author[50]; char subject[100]; int book_id;
};
int main( )
{
Books Book1; // 定义结构体类型 Books 的变量 Book1
Books Book2; // 定义结构体类型 Books 的变量 Book2
// Book1 详述
strcpy( Book1.title, "C++ 教程");
strcpy( Book1.author, "Runoob");
strcpy( Book1.subject, "编程语言");
Book1.book_id = 12345;
// Book2 详述
strcpy( Book2.title, "CSS 教程");
strcpy( Book2.author, "Runoob");
strcpy( Book2.subject, "前端技术");
Book2.book_id = 12346;
// 输出 Book1 信息
printBook( Book1 );
// 输出 Book2 信息
printBook( Book2 );
return 0;
}
void printBook( struct Books book )
{
cout << "书标题 : " << book.title <<endl;
cout << "书作者 : " << book.author <<endl;
cout << "书类目 : " << book.subject <<endl;
cout << "书 ID : " << book.book_id <<endl;
}
20. C++中的函数重载
文章C++的函数重载无疑是非常棒的,这里仅仅摘录一部分做一个简单的了解,日后必定深入。
1. 什么是函数重载?
函数重载是指在同一作用域内,可以有一组具有相同函数名,不同参数列表的函数,这组函数被称为重载函数。重载函数通常用来命名一组功能相似的函数,这样做减少了函数名的数量,避免了名字空间的污染,对于程序的可读性有很大的好处。
下面就是函数重在的例子,即实现一个打印函数:
#include<iostream>using namespace std;void print(int i)
{
cout<<"print a integer :"<<i<<endl;
}void print(string str)
{
cout<<"print a string :"<<str<<endl;
}int main()
{
print(12);
print("hello world!"); return 0;
}
最终的输出如下:
print a integer :12print a string :hello world!
即我们调用函数名相同的函数(实现的功能也大抵相似)返回的值确实不同的。
2.为 什么要函数重载?
-
试想如果没有函数重载机制,如在C中,你必须要这样去做:为这个print函数取不同的名字,如print_int、print_string。这里还只是两个的情况,如果是很多个的话,就需要为实现同一个功能的函数取很多个名字,如加入打印long型、char*、各种类型的数组等等。这样做很不友好!
-
类的构造函数跟类名相同,也就是说:构造函数都同名。如果没有函数重载机制,要想实例化不同的对象,那是相当的麻烦!
-
操作符重载,本质上就是函数重载,它大大丰富了已有操作符的含义,方便使用,如+可用于连接字符串等。
补充:
http://www.cnblogs.com/lzjsky/archive/2011/01/24/1943199.html
静态数据成员介绍
结束,有时间了再继续...
2017年3月31日更新(C++进阶)
今天刚刚使用MinGW 和 nodepad++ 来编译和执行文件了,和visual C++ 6.0是一样的可以cin也可以cout,还是非常激动的,趁此就多复习一些知识吧。
1. 下面这是一个含有类和对象的最简单的例子:
#include <iostream>using namespace std;class Person // L类的定义{public: void SetInfo()
{
cout<<"Input info to name,sex,age"<<endl;
cin>>name>>sex>>age;
} void Show()
{
cout<<"name:"<<name;
cout<<"sex:"<<sex;
cout<<"age:"<<age<<endl;
}private: char name[20]; char sex[2]; int age;
}; // 类声明结束,必须要有分号int main()
{
Person person1,person2;
person1.SetInfo();
person2.SetInfo();
person1.Show();
person2.Show(); return 0;
}
其中class Person用来定义一个名为Person的类,可以把类看做一个模子,然后我们用这个模子就可以创造形形色色的对象来了。值得注意的是,在class定义了之后,需要使用分号作为结束。
另外,使用public是说其中的内容是公有的,可以被调用的,而privite是私有的,只能在内部被调用。这就体现了著名的封装性的特点。
这就是面向对象,它引入了类和对象的概念,类是用户自定义的数据类型,对象是该数据类型的变量。
2. 注意使用#define 定义常变量时,只是将变量进行了简单的替换,如下所示:
int x=1; int y=2; #define R x+y #define PI 3.1415926 cout<<PI*R*R; 最后实际输出的是 PI*1+2*1+2 而不是PI*(1+2)*(1+2)
而如果我们使用const float PI = 3.14;也是类似的作用,也可以写成 float const PI = 3.14; 两者是等效的。
3、空指针和野指针
int *p = 0; 或者是 int *p = NULL; 那么这里的p就是空指针。
而int *q; 仅仅声明了这个指针q,但是不知道它指向了哪里,所以说是野的,即野指针。
两者是不同的,引入空指针的目的是为了防止使用指针出错,如果出现了空指针就会报错,情况:动态分配内存malloc()函数或new运算符的成功使用不会返回空指针,但是失败了就会返回空指针。
如果定义了一个野指针,我们就不知道它到底会指向何处,为了避免不知指针指向了何处,在C++中一般习惯是定义了指针变量后立即初始化为空指针,然后在使用指针之前再给指针变量赋值,使指针有了具体指向之后再使用指针。
4. 指针与const
-
const int *p;(int const *p; 和前者是一样的) 这个的意思p是常量,即我们不能通过 *p 来修改p所指向的值,但是可以直接修改p所指向的值, 也可以修改p的指向。
#include <iostream>using namespace std;int main()
{ const int *p = NULL; int a = 20; int b = 30;
p = &a;
p = &b;
*p = 50; // error: assignment of read-only location "*p"
cout<<*p;
}我们可以修改b的值,这样*p会改变,也可以修改p的指向,但是如果通过*p来修改指向的值就报错,提示*p是只读的。
-
int *const p; 这里是指p指针是const的,一旦定义了,就不能修改p的指向。
#include <iostream>using namespace std;int main()
{ int *const p = NULL; int a = 20; int b = 30;
p = &a; // 报错
cout<<*p;
}这里我已经定义p为空指针了,那么后面p又指向a就会报错。
-
const int *const p; 这里就是上述的综合,即不能修改p的指向也不能通过*p来修改p所指向的值。
5. void和void指针
先说void , 函数 int func(void){return 0;} 和int func(){return 0;}在C++中都表示不接受任何参数,如果使用func(2)就会报错。但是在c语言中,如果我们使用func(2)就不会报错,所以,为了更加严谨,最好使用void表示不接受参数。 另外我们不能使用void a;这种形式来声明变量,因为void表示无类型的,如果你声明了这个变量,那么分配多少内存呢? 对吧。
但是void是可以声明一个指针的。 答案是可以的。使用void声明一个指针,我们就称为“无类型指针”,或者就称为void指针。 我们知道,一个类型的指针必须指向相同类型的变量,但是void指针就厉害了,它可以指向任意类型的变量。但是void类型的指针在读取值和指针的赋值过程中需要进行强制类型转换,原因如下:
不难想象,无论是什么类型的指针,它指向一个变量的首地址总是一样的,所以我们才可以使用void指针,但问题是: 如果我们希望通过这个指针来访问他所指向的变量,就得知道这个变量的类型啊,因为不同类型的变量的内存大小是不一样的,所以得强制类型转化,告诉它这个变量的大小是多少,才可以读取。
#include <iostream>using namespace std;int main()
{ void *p; int a = 5; double b = 10;
p = &a;
cout<< *(int *)p;
}
如上,必须进行强制类型转换才能正确的输出p所指向的变量,注意:强制类型转换是(int *)因为这是一个指针。
6. 使用new和delete动态管理内存单元
和声明一个变量不同,使用new一般是用来申请指针的内存单元的,并且前者是在编译过程中分配的内存,而后者是在程序的执行过程中才分配的内存,所以是动态分配内存。 另外,new之后一定要delete,因为声明的方式可以自动地清除内存,但是new的方式只能使用delete来清除内存。
#include <iostream>using namespace std;int main()
{ int *p = NULL;
p = new int;
delete p;
cout<<*p;
}
最终输出的是16323288, 注意这是new到的一个内存,所以这是一个随机数。 且new和delete必须要成对存在。我们还可以在new的时候初始化,即p = new int(20); 那么*p就是20了。
那我们怎么申请连续空间的内存呢? 方法也很简单,就是p = new int[20]; 这样就可以申请到长度为20的连续空间了。
7. 引用,如 int &a = b;这就是a对b的引用,可以看做a是b的另外一个名字,但是他们指向的同一个内存单元,所以对他们任意一个的修改都是有效的。 下面我们看三个典型的例子,分别是值传递、指针传递和引用传递。
#include <iostream>using namespace std;int fun(int a, int b)
{ int temp;
temp = a;
a = b;
b = temp;
}int main()
{ int x = 5, y = 10;
cout<<" x:"<<x<<" y:"<<y<<endl;
fun(x,y);
cout<<" x:"<<x<<" y:"<<y<<endl;
}
最后的结果都是x为5,y为10。这就是典型的值传递,即穿进去之后,内部的改变不会影响外面的。
#include <iostream>using namespace std;int fun(int *a, int *b)
{ int temp;
temp = *a;
*a = *b;
*b = temp;
}int main()
{ int x = 5, y = 10;
cout<<" x:"<<x<<" y:"<<y<<endl;
fun(&x,&y);
cout<<" x:"<<x<<" y:"<<y<<endl;
}
最后的结果是: x:5,y:10 后面是x:10,y:5 可以发现这个交换就完成了。 这就是典型的指针传递或地址传递。这样,在内部修改的*a和*b实际上就在修改x和y。
#include <iostream>using namespace std;int fun(int &a, int &b)
{ int temp;
temp = a;
a = b;
b = temp;
}int main()
{ int x = 5, y = 10;
cout<<" x:"<<x<<" y:"<<y<<endl;
fun(x,y);
cout<<" x:"<<x<<" y:"<<y<<endl;
}
最后的结果是: x:5,y:10 后面是x:10,y:5 可以发现这个交换就完成了。 这就是典型的引用传递,两者都是指向同样的内存,所以可以完成修改。
值得注意的是,在引用中,还是有const的,如const int &a = b;表示a这个引用是不能被修改的,即不能通过a来修改他和b共有的内存,即a的权利只是读。如下:
#include <iostream>using namespace std;int main()
{ int x=10; const int &b = a;
b = 20;
cout<<a;
}
编译过程中就会提示b是只读的。
8. 函数的相关问题
在c++中,无论你写了多少,总是从main函数中开始执行,并且在调用一个函数之前,我们必须进行函数声明(函数声明和函数定义不同,所以说需要用分号作为结尾),另外,main函数是最重要的,我们强烈建议将函数定义写在main函数之后,另外, 在函数声明的时候我们只需要将函数的类型声明即可, 名称不重要,编译时不会检查。
除此之外,我们还可以提供默认的参数,即如果没有传递该参数,我们就使用默认的。且默认的参数可以使其中的一个或几个(当然可以使全部),但是如果不是全部时, 默认的参数需从最右边开始。
#include <iostream>using namespace std;int main()
{ int add(int,int,int =50); //int add(int,int,int c=50); // 这个也是有效的,在函数什么声明的过程中,不需要制定名字。
cout<<add(5,10,15)<<endl; // 30
cout<<add(5,10);
}int add(int a,int b,int c = 50)
{ return a + b + c;
}
值得注意的是,如果使用默认参数,那么定义和声明都需要指明默认的值,否则就会报错。 虽然我们可以直接写在int main()的上面,这样就不需要声明了,但是这并不是我们所推荐的。
函数重载: 即函数参数的类型不同或个数不同或函数参数的类型和个数都不相同。函数的返回值可以相同也可以不同,但是绝不能函数的参数形同而只有返回值不同,这不是函数的重载。如下:
#include <iostream>using namespace std;int main()
{ int add(int,int); int add(int,int,int); int a = 5,b = 8; int x = 14,y = 15, z =45;
cout<<add(a,b)<<endl<<add(x,y,z);
}int add(int a, int b, int c)
{ return a+b+c;
}int add(int a, int b)
{ return a+b;
}
一个输出的是13,另一个输出的是74。
9. 详解名字空间
我之前所写的所有代码中都包括: using namespace std; 不难理解,这一定和命名空间是由关系的。下面我将从头说起。。。
(1)为什么要使用名字空间?
简单的说,使用名字空间是为了解决程序中名字冲突的问题,即在程序运行过程中遇到相同名字的变量,系统不能正确的区分它们。
在一个小型系统里,只要我们注意一下变量就不会重复,但是对于一个大型的系统,由多人合作完成,我们通过#include的方式来引入不同的开发人员所编写的程序,那就难免会遇到重名的情况,这样就导致类全局名字空间污染。
正是为了避免这样的问题,后来引入了名字空间的机制。(在早期的C++中,也是没有名字空间的概念的)。
(2)什么是名字空间?
所谓名字空间就是一个由程序设计者命名的内存区域。他可以根据需要建立一些有名字的命名空间域,把一些全局标识符分别放在不同的名字空间中,这样就可以解决变量冲突的问题了。 就向一个文件下有一个目录,每个子目录又有一堆文件,那么各个目录下的文件是可以重名的,于是就解决了问题。
(3)如何使用名字空间?
语法如下:
namespace 名字空间名
{
定义成员
}
其中成员的类型包括:常量、变量、函数、结构体、类、模板等,还可以是名字空间,即名字空间的嵌套。如下:
namespace ns
{ const int RATE = 0.08; double money; double tax()
{ return money * RATE;
}
namespace ns2
{ int count;
}
}
如果要访问名字空间ns中的成员,就可以采用“名字空间::成员名”的方法,如ns::RATE、ns::money、ns::tax()、ns2::count等等。
我们还可以给ns起一个别名,即namespace anotherns = ns; 那么就是anotherns::money就和 ns::money的效果是一样的了。
技巧: 使用using 名字空间的成员名,如using ns::tax 后面再访问tax()的时候就相当于ns::tax(),这样可以避免在每一次访问名字空间的成员时用名字空间限定,来简化名字空间的使用。
技巧: 使用using 名字空间名, 如果在一段程序中经常访问一个名字空间中的多个成员,就要多次使用using名字空间成员名,这是很不方便的,所以C++提供了using namespace 语句,一次就能声明一个名字空间中的全部成员,格式为:
using namespace 名字空间名;
注意1: 该声明下使用变量只在该声明的作用域内有效。
注意2: 如果同时使用using namespace引入了多个命名空间,那么要保证它们没有相同的变量名,否则还是会有命名冲突。
(4)标准名字空间 std
即standard,标准的名字空间,系统预定义的头文件中的函数、类、对象和类模板都是在std中定义的。
所以,第二行都有一个using namespace std; 这就在全局中起作用了,如果不用的话,我们就要使用std::来访问了,如下所示:
#include <iostream>int main()
{
std::cout << "Hello world";
}
如果引入了大量的系统的函数、类等,我们就需要添加没玩没了的std::,然后这是很不方便的。
9. 字符串变量
我们知道在c中使用char来定义字符串和字符串数组都是十分麻烦的。而在c++中,由于有了类的概念,并且系统自带的就有string类,我们只要在开头引入即可,即#include <string>然后我们就可以使用string类了。
如 string str = "hello"; 这样就定义了一个字符串变量,我们可以对这个变量进行大量的操作,如strcat、strcopy等等。另外,还可以赋值,并且不需要考虑内存的问题。
和c中的最大的不同是,在c中的字符串,最后自动添加'�'作为结尾,而string实例化的对象不需要使用'�'作为结尾。且可以使用str[0]等来访问到每一个字符。
在c++中,还支持数组,如 string str = {"hello", "world", "hhahha"}; 即我们不需要考虑每一个元素的长度是否一致等。 就是这个方便。
