一.autohome


import requests from bs4 import BeautifulSoup response = requests.get('http://www.autohome.com.cn/news') response.encoding = 'gbk' soup = BeautifulSoup(response.text,'html.parser') li_list = soup.find(id="auto-channel-lazyload-article").find_all(name='li') for li in li_list: title = li.find('h3') if not title: continue # print(type(title),title) # < class 'bs4.element.Tag'> < h3 > 发力新能源 长城有望2022年推燃料电池 < / h3 > summary = li.find('p').text #新闻概要 #li.find('a').attrs ---字典 # li.find('a').attrs['href'] url = li.find('a').get('href') imgs = li.find('img').get('src') print(imgs) # print(title.text,url,summary,imgs) #标题,url,概要,图片
import requests from bs4 import BeautifulSoup import os import csv #请求 ret = requests.get('https://www.autohome.com.cn/news') ret.encoding = 'gbk' soup = BeautifulSoup(ret.text,'html.parser') li_list = soup.find(id='auto-channel-lazyload-article').find_all('li') #获取数据 content = [] for li in li_list: title = li.find('h3') if not title: continue summary = li.find('p').text u = li.find('a').get('href') url = 'http:'+u content.append([title,url,summary]) #保存.csv def save(con): path = 'F:/D/' if not os.path.exists(path): os.mkdir(path) with open(path+'汽车之家' + '新闻数据.csv','w+') as f: writer = csv.writer(f) writer.writerow(['新闻标题','URl','摘要']) for row in con: writer.writerow(row) if __name__ == '__main__': save(content)
# requests+Beautifulsoup爬取汽车之家新闻 import requests from bs4 import BeautifulSoup response=requests.get('https://www.autohome.com.cn/news/') response.encoding='gbk' with open('a.html','w',encoding='utf-8') as f: f.write(response.text) soup=BeautifulSoup(response.text,'lxml') news=soup.find(id='auto-channel-lazyload-article').select('ul li a') for tag in news: link=tag.attrs['href'] imag=tag.select('.article-pic img')[0].attrs['src'] title=tag.find('h3').get_text() sub_time=tag.find(class_='fn-left').get_text() browsing_num=tag.select('.fn-right em')[0].get_text() comment=tag.find('p').get_text() msg=''' ====================================== 链接:http:%s 图片:http:%s 标题:%s 发布时间:%s 浏览数:%s 介绍:%s ''' %(link,imag,title,sub_time,browsing_num,comment) print(msg)
二.登录github
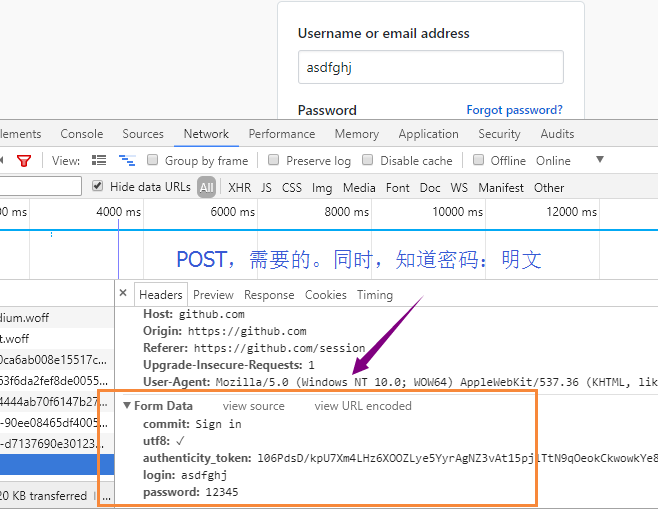
import requests from bs4 import BeautifulSoup import re #获取token r1 = requests.get('https://github.com/login') s1 = BeautifulSoup(r1.text,'html.parser') # token = re.findall('name="authenticity_token".*?value="(.*?)"',r1.text,re.S)[0] token = s1.find(name='input',attrs={'name':'authenticity_token'}).get('value') #将用户名密码totken发送到服务端,post r1_cookie_dict = r1.cookies.get_dict() r2 = requests.post('https://github.com/session', data={ 'commit':'Sign in', 'utf8':'✓', 'authenticity_token':token, 'login':'XXXXX', 'password':'******' }, cookies = r1_cookie_dict ) r2_cookie_dict = r2.cookies.get_dict() # print(r1_cookie_dict) # print(r2_cookie_dict) #有的网站,POST请求成功后,给cookie。有的,发GET请求,就给cookie,但并未授权。登录成功后,再给授权 cookie_dict = {} cookie_dict.update(r1_cookie_dict) cookie_dict.update(r2_cookie_dict) with open('a.html','w',encoding='utf-8') as f: f.write(r2.text) r3 = requests.get( url='https://github.com/settings/emails', cookies=cookie_dict ) #验证是否成功 with open('a.html','w',encoding='utf-8') as f: f.write(r2.text) print('****@qq.com' in r3.text) #True
三.抽屉点赞
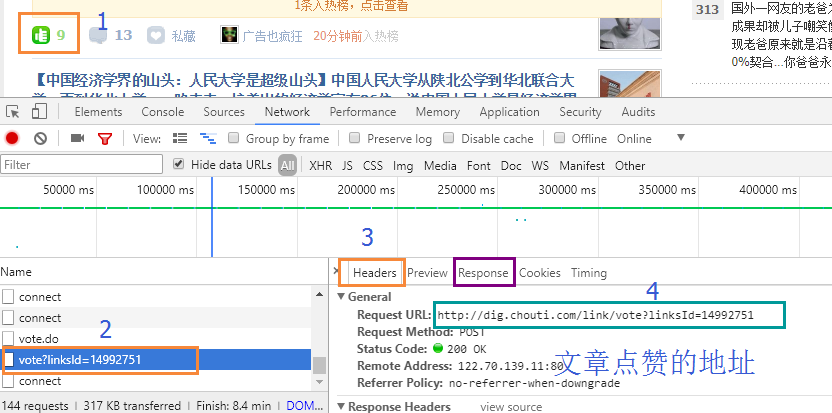
import requests #1.获取cookie r0 = requests.get('http://dig.chouti.com/') r0_cookie_dict = r0.cookies.get_dict() #发送用户名 密码 cookie r1 = requests.post( 'http://dig.chouti.com/login', data={ 'phone': '86xxxxxxx', 'password': '*******', 'oneMonth':1 }, cookies=r0_cookie_dict ) r1_cookie_dict = r1.cookies.get_dict() # cookie_dict = {} # cookie_dict.update(r0_cookie_dict) # cookie_dict.update(r1_cookie_dict) cookie_dict = { #抽屉所用的。上面cookie_dict = {},也可以 'gpsd': r0_cookie_dict['gpsd'] } r2 = requests.post('http://dig.chouti.com/link/vote?linksId=14992751',cookies=cookie_dict) print('r2.text',r2.text) # print(r0_cookie_dict) # 结果:{'gpsd': 'c2c96f08ca07c354d524f282eb91f041', 'JSESSIONID': 'aaarIEgl7p0ka8HCLwR9v', 'route': '249e9500f56e96c9681c6db3bc475cbf'}
import requests session = requests.Session() i1 = session.get(url="http://dig.chouti.com/") i2 = session.post( url="http://dig.chouti.com/login", data={ 'phone': "1234567", 'password': "******", 'oneMonth': "1" } ) i3 = session.post( url="http://dig.chouti.com/link/vote?linksId=14992841", ) print('i3.text', i3.text) """ i3.text {"result":{"code":"9999", "message":"推荐成功", "data":{"jid":"cdu_50950688648", "likedTime":"1509512238409000", "lvCount":"13","nick":"kk123", "uvCount":"1", "voteTime":"小于1分钟前" }}} """
四.爬取xiaohuar