目标:通过Selenium获取页面元素的某一个属性。一个元素可能有多个属性,例如class,id,name,text,href,value等。
练习场景:找出当前页面的所有超链接。例:打印出百度首页所有包含href的元素的链接。
具体代码:
# coding = utf-8
import time
from selenium import webdriver
driver = webdriver.Chrome()
driver.maximize_window()
driver.implicitly_wait(6)
driver.get("https://www.baidu.com")
time.sleep(1)
for link in driver.find_elements_by_xpath("//*[@href]"):
print(link.get_attribute('href'))
driver.quit()
运行结果:
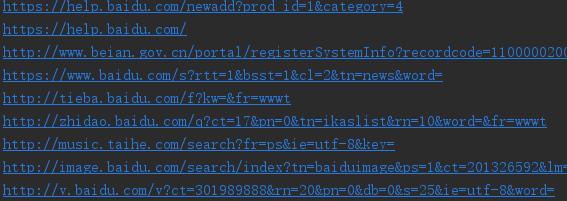
这里只是找元素的href属性,如果你需要其它属性,例如你需要查看页面所有元素具有id值的话,你可以这样写
print (link.get_attribute('id'))
运行结果:
参考文章:https://blog.csdn.net/u011541946/article/details/70140812