vue3.0 尝鲜 -- 摒弃 Object.defineProperty,基于 Proxy 的观察者机制探索
Vue.js 源码:https://github.com/vuejs/vue
Vue技术内幕:http://hcysun.me/vue-design/
源码分析文档:https://ustbhuangyi.github.io/vue-analysis/
1、知识点
2、https://ustbhuangyi.github.io/vue-analysis/prepare/flow.html
Flow 是facebook出品的JavaScript静态类型检查工具。Vue.js的源码就利用Fow做了静态类型检测
为什么用Flow?
因为JavaScript是动态类型语言(弱类型语言),虽然灵活,但是也容易出现隐患代码。
类型检查是当前动态类型语言的发展趋势,所谓类型检查,就是在编译期尽早发现(由类型错误引起的)bug,又不影响代码运行(不需要运行时动态检查类型),使编写 JavaScript 具有和编写 Java 等强类型语言相近的体验。
Flow的工作方式
-
类型推断:通过变量的使用上下文来推断出变量类型,然后根据这些推断来检查类型。
1 /*@flow*/`` 2 3 function split(str) { 4 return str.split(' ') 5 } 6 7 split(11)
Flow 检查上述代码后会报错,因为函数 split 期待的参数是字符串,而我们输入了数字。
类型注释
-
类型注释:事先注释好我们期待的类型,Flow 会基于这些注释来判断
1 /*@flow*/ 2 3 function add(x: number, y: number): number { 4 return x + y 5 } 6 7 add('Hello', 11)
现在 Flow 就能检查出错误,因为函数参数的期待类型为数字,而我们提供了字符串。
Flow还支持一些常见的类型注释:数组、类和对象、Null
3、Vue.js源码目录设计 https://ustbhuangyi.github.io/vue-analysis/prepare/directory.html
Vue.js 的源码都在 src 目录下,其目录结构如下:
1 src 2 ├── compiler # 编译相关 3 ├── core # 核心代码 4 ├── platforms # 不同平台的支持 5 ├── server # 服务端渲染 6 ├── sfc # .vue 文件解析 7 ├── shared # 共享代码
从 Vue.js 的目录设计可以看到,作者把功能模块拆分的非常清楚,相关的逻辑放在一个独立的目录下维护,并且把复用的代码也抽成一个独立目录。
这样的目录设计让代码的阅读性和可维护性都变强,是非常值得学习和推敲的。
4、源码构建 https://ustbhuangyi.github.io/vue-analysis/prepare/build.html#构建脚本
主要包括构建脚本和构建过程
Runtime Only VS Runtime + Compiler的区别
5、new Vue的时候,会把传入的option都绑定到$options上,所以我们可以通过vm.$options或者this.$options获取传入的参数(如:el,data)
6、new Vue()的时候发生了什么?
地址:https://ustbhuangyi.github.io/vue-analysis/data-driven/new-vue.html
new 关键字在 Javascript 语言中代表实例化是一个对象,而 Vue 实际上是一个类,类在 Javascript 中是用 Function 来实现的,来看一下源码,在src/core/instance/index.js 中。
会调用_init函数进行初始化。会初始化生命周期、事件、props、data、methods、computed与watch等。
最主要的是通过Object.defineProperty设置setter与getter函数,用来实现【响应式】与【依赖收集】
7、Vue 实例挂载的实现
Vue 中我们是通过 $mount 实例方法去挂载 vm 的
8、Vue 的 _render 方法是实例的一个私有方法,它用来把实例渲染成一个虚拟 Node。它的定义在 src/core/instance/render.js 文件中:
9、其实 VNode 是对真实 DOM 的一种抽象描述,它的核心定义无非就几个关键属性,标签名、数据、子节点、键值等,其它属性都是都是用来扩展 VNode 的灵活性以及实现一些特殊 feature 的。由于 VNode 只是用来映射到真实 DOM 的渲染,不需要包含操作 DOM 的方法,因此它是非常轻量和简单的。
Virtual DOM 除了它的数据结构的定义,映射到真实的 DOM 实际上要经历 VNode 的 create、diff、patch 等过程。那么在 Vue.js 中,VNode 的 create 是通过之前提到的 createElement 方法创建的
10、Vue.js 利用 createElement 方法创建 VNode,它定义在 src/core/vdom/create-elemenet.js 中:
分为俩部分:children 的规范化和VNode 的创建
那么至此,我们大致了解了 createElement 创建 VNode 的过程,每个 VNode 有 children,children 每个元素也是一个 VNode,这样就形成了一个 VNode Tree,它很好的描述了我们的 DOM Tree。
11、Vue 的 _update 是实例的一个私有方法,它被调用的时机有 2 个,一个是首次渲染,一个是数据更新的时候;由于我们这一章节只分析首次渲染部分,数据更新部分会在之后分析响应式原理的时候涉及。_update 方法的作用是把 VNode 渲染成真实的 DOM,它的定义在 src/core/instance/lifecycle.js 中:
12、初始化 Vue 到最终渲染的整个过程。

从new Vue开始,先执行init,进行一堆初始化操作;然后进行挂载,执行$mount
$mount的执行过程:如果是带编译版本的(就是template这样的,我们一般写的那种),就执行compile,生成render function;如果直接就是render function
得到render function后,调用render方法,生成vnode,之后通过patch过程,生成真实的DOM
备注:在vue中,会把之前写的真实的dom删掉,然后通过Virtual DOM重新生成真实的dom
13、

14、

知道了 3 种异步组件的实现方式,并且看到高级异步组件的实现是非常巧妙的,它实现了 loading、resolve、reject、timeout 4 种状态。异步组件实现的本质是 2 次渲染,除了 0 delay 的高级异步组件第一次直接渲染成 loading 组件外,其它都是第一次渲染生成一个注释节点,当异步获取组件成功后,再通过 forceRender 强制重新渲染,这样就能正确渲染出我们异步加载的组件了。
15、

defineReactive 函数最开始初始化 Dep 对象的实例,接着拿到 obj 的属性描述符,然后对子对象递归调用 observe 方法,这样就保证了无论 obj 的结构多复杂,它的所有子属性也能变成响应式的对象,这样我们访问或修改 obj 中一个嵌套较深的属性,也能触发 getter 和 setter。
16、 Vue 会把普通对象变成响应式对象,响应式对象 getter 相关的逻辑就是做依赖收集

Vue为数据中的每一个key维护一个订阅者列表。对于生成的数据,通过Object.defineProperty对其中的每一个key进行处理,主要是为每一个key设置get, set方法,以此来为对应的key收集订阅者,并在值改变时通知对应的订阅者。
最开始new Vue(),初始化代码的时候,就会进行依赖收集,之后改变值以后,会再次进行依赖收集
参考网站:https://www.jianshu.com/p/e6e1fa824849



17、计算属性 computed的优化有俩处: 参考:https://ustbhuangyi.github.io/vue-analysis/reactive/computed-watcher.html#computed
(1)、当初始化computed的时候,会先进行收集依赖,但不会触发watch,只有当渲染到computed计算的属性时,就触发了计算属性的 getter,它会拿到计算属性对应的 watcher,然后执行 watcher.depend()
(2)、一旦我们对计算属性依赖的数据做修改,则会触发 setter 过程,通知所有订阅它变化的 watcher 更新,执行 watcher.update() 方法

记住这里:getAndInvoke 函数会重新计算,然后对比新旧值,如果变化了(就算依赖一直变化,只要最终值没有,那就不会触发回调函数)则执行回调函数,那么这里这个回调函数是 this.dep.notify(),在我们这个场景下就是触发了渲染 watcher 重新渲染。

18、

响应式原理图
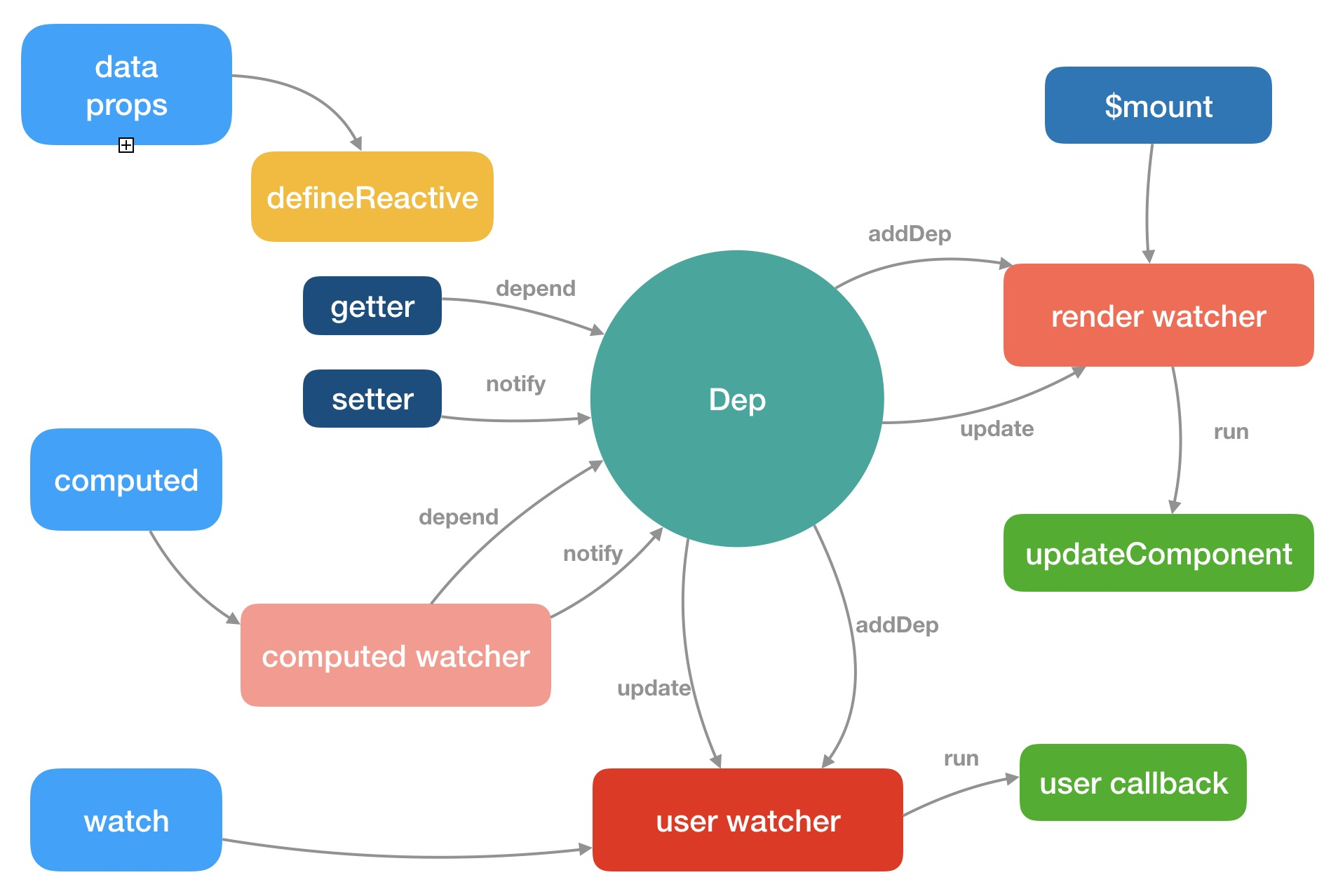
参考:https://segmentfault.com/q/1010000010977528
对上面的理解:页面中所用到的数据data,渲染的时候就会触发Object.defineReactive的getter方法
getter方法会将window.target(watch,每个用到这个数据的地方,都会生成一个watch)保存到subs数组中
subs数组抽取出来,封装到Dep类中,getter中要new Dep(),调用Dep类中的addSub,将watch保存到subs数组中
数据改变的时候,就会触发setter方法==》触发Dep类中的notify方法==》遍历subs数组==》触发watch中的update方法
综合:每一个使用的数据都有一个单独的Dep类,每个Dep类中有多个watch(根据使用此数据来生成,一个地方使用就生成一个watch)
19、编译入口逻辑之所以这么绕,是因为 Vue.js 在不同的平台下都会有编译的过程,因此编译过程中的依赖的配置 baseOptions 会有所不同。而编译过程会多次执行,但这同一个平台下每一次的编译过程配置又是相同的,为了不让这些配置在每次编译过程都通过参数传入,Vue.js 利用了函数柯里化的技巧很好的实现了 baseOptions 的参数保留。同样,Vue.js 也是利用函数柯里化技巧把基础的编译过程函数抽出来,通过 createCompilerCreator(baseCompile) 的方式把真正编译的过程和其它逻辑如对编译配置处理、缓存处理等剥离开,这样的设计还是非常巧妙的。
parse 的目标是把 template 模板字符串转换成 AST 树,它是一种用 JavaScript 对象的形式来描述整个模板。那么整个 parse 的过程是利用正则表达式顺序解析模板,当解析到开始标签、闭合标签、文本的时候都会分别执行对应的回调函数,来达到构造 AST 树的目的。
AST 元素节点总共有 3 种类型,type 为 1 表示是普通元素,为 2 表示是表达式,为 3 表示是纯文本。
optimize 的过程,就是深度遍历这个 AST 树,去检测它的每一颗子树是不是静态节点,如果是静态节点则它们生成 DOM 永远不需要改变,这对运行时对模板的更新起到极大的优化作用。
我们通过 optimize 我们把整个 AST 树中的每一个 AST 元素节点标记了 static 和 staticRoot,它会影响我们接下来执行代码生成的过程。
20、event事件
注意:vm.$emit 是给当前的 vm 上派发的实例,之所以我们常用它做父子组件通讯,是因为它的回调函数的定义是在父组件中,对于我们这个例子而言,当子组件的 button 被点击了,它通过 this.$emit('select') 派发事件,那么子组件的实例就监听到了这个 select 事件,并执行它的回调函数——定义在父组件中的 selectHandler 方法,这样就相当于完成了一次父子组件的通讯。
21、v-model实际是一个语法糖
<input v-model="message">
<input :value="message" @input="message=$event.target.value">
这是一回事


v-model总结:
v-model是一个语法糖
在input中 这俩个是相等的
<input v-model="searchText">
等价于
<input :value="searchText" @input="searchText = $event.target.value">
当然,Vue还做了一些优化
在组件中
https://cn.vuejs.org/v2/guide/components.html#在组件上使用-v-model
<test v-model="searchText"></test>
等价于
<test :value="searchText" @input="searchText = $event"></test>
在test组件里,要这样写
<template> <div class="test"> <input type="checkbox" :checked="value" @change="$emit('input', $event.target.checked)"> // 使用$emit向父组件传回input事件 </div> </template> <script> export default { name: 'test', props: ['value'] // 这个必须有,而且默认传过来的就是value } </script>
在实际中,我们传递value和input有可能会照成歧义,这是我们可以自定义父组件传过来的值和向父组件传递的事件
<template> <div class="test"> <input type="checkbox" :checked="checked" @change="$emit('changeChecked', $event.target.checked)"> </div> </template> <script> export default { name: 'test', model: { prop: 'checked', event: 'changeChecked' }, props: ['checked'] // 这个必须有,值就是我们上面定义的prop } </script>
22、slot

普通插槽是在父组件编译和渲染阶段生成 vnodes,作为当前组件渲染vnode的children,所以数据的作用域是父组件实例,子组件渲染的时候直接拿到这些渲染好的 vnodes
作用域插槽,父组件在编译和渲染阶段并不会直接生成 vnodes,而是在父节点 vnode 的 data 中保留一个 scopedSlots 对象,存储着不同名称的插槽以及它们对应的渲染函数,只有在编译和渲染子组件阶段才会执行这个渲染函数生成 vnodes,由于是在子组件环境执行的,所以对应的数据作用域是子组件实例。
两种插槽的目的都是让子组件 slot 占位符生成的内容由父组件来决定,但数据的作用域会根据它们 vnodes 渲染时机不同而不同。
23、keep-alive
<keep-alive> 组件是一个抽象组件,它的实现通过自定义 render 函数并且利用了插槽,并且知道了 <keep-alive> 缓存 vnode,了解组件包裹的子元素——也就是插槽是如何做更新的。且在 patch 过程中对于已缓存的组件不会执行 mounted,所以不会有一般的组件的生命周期函数但是又提供了 activated 和 deactivated 钩子函数。另外我们还知道了 <keep-alive> 的 props 除了 include 和 exclude 还有文档中没有提到的 max,它能控制我们缓存的个数。
24、


25、vue-touter
参考网站:https://github.com/DDFE/DDFE-blog/issues/9



导航守卫的参考:https://www.cnblogs.com/le220/p/10162689.html
完整的导航解析流程
- 导航被触发。
- 在失活的组件里调用离开守卫。
- 调用全局的
beforeEach守卫。 - 在重用的组件里调用
beforeRouteUpdate守卫 (2.2+)。 - 在路由配置里调用
beforeEnter。 - 解析异步路由组件。
- 在被激活的组件里调用
beforeRouteEnter。 - 调用全局的
beforeResolve守卫 (2.5+)。 - 导航被确认。
- 调用全局的
afterEach钩子。 - 触发 DOM 更新。
- 用创建好的实例调用
beforeRouteEnter守卫中传给next的回调函数。
Vue-Router 内置了一个组件 <router-view>
Vue-Router 还内置了另一个组件 <router-link>
<router-link> 比起<a href="..."> 会好一些,理由如下:
无论是 HTML5 history 模式还是 hash 模式,它的表现行为一致,所以,当你要切换路由模式,或者在 IE9 降级使用 hash 模式,无须作任何变动。
在 HTML5 history 模式下,router-link 会守卫点击事件,让浏览器不再重新加载页面。
当你在 HTML5 history 模式下使用 base 选项之后,所有的 to 属性都不需要写(基路径)了。
路径变化是路由中最重要的功能,我们要记住以下内容:路由始终会维护当前的线路,路由切换的时候会把当前线路切换到目标线路,切换过程中会执行一系列的导航守卫钩子函数,会更改 url,同样也会渲染对应的组件,切换完毕后会把目标线路更新替换当前线路,这样就会作为下一次的路径切换的依据。

26、Vuex
Vuex 的初始化过程就分析完毕了,除了安装部分,我们重点分析了 Store 的实例化过程。我们要把 store 想象成一个数据仓库,初始化Vuex,就是在实例化Vuex,为了更方便的管理仓库,我们把一个大的 store 拆成一些 modules,整个 modules 是一个树型结构。每个 module 又分别定义了 state,getters,mutations、actions,我们也通过递归遍历模块的方式都完成了它们的初始化。为了 module 具有更高的封装度和复用性,还定义了 namespace 的概念。最后我们还定义了一个内部的 Vue 实例,用来建立 state 到 getters 的联系,并且可以在严格模式下监测 state 的变化是不是来自外部,确保改变 state 的唯一途径就是显式地提交 mutation。
Vuex 提供的一些常用 API 我们就分析完了,包括数据的存取、语法糖、模块的动态更新等。要理解 Vuex 提供这些 API 都是方便我们在对 store 做各种操作来完成各种能力,尤其是 mapXXX 的设计,让我们在使用 API 的时候更加方便,这也是我们今后在设计一些 JavaScript 库的时候,从 API 设计角度中应该学习的方向。