今天老师课上突然坐我旁边神秘地给我布置了一个任务:帮他把华为应用市场中的应用按类别选择100多个应用,把应用名、类别、url、下载次数放到excel中
((;¬_¬)难道是我今天上课迟到的惩罚?)
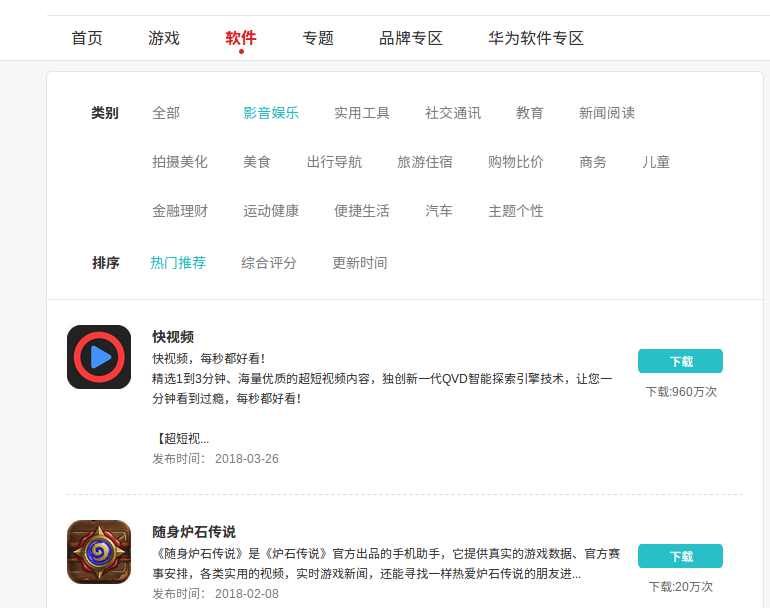
大概是图里的这些信息
答应下来以后,想想Ctrl+C Ctrl+V这么多信息还是有点麻烦的,回去的路上想到这事儿可以写个爬虫解决_(・ω・」 ∠)_
F12后可以看到相应标签的class等属性,不过下载次数直接就是个span标签,所以我用的text正则匹配
代码如下:(..•˘_˘•..)
import xlsxwriter from bs4 import BeautifulSoup import re from urllib import request #把应用名、类别、url、下载次数写入excel,因为只需要打开一次文件,所以把file和sheet定义为全局变量 def write_excel(name, type_name, url, download): # 全局变量row代表行号 0-4代表列数 global row sheet.write(row, 0, row) sheet.write(row, 1, name) sheet.write(row, 2, type_name) sheet.write(row, 3, url) sheet.write(row, 4, download) row += 1 def get_list(url): # 请求url req = request.Request(url) # 设置请求头 req.add_header("User-Agent", "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:57.0) Gecko/20100101 Firefox/57.0") # 得到响应对象 response = request.urlopen(req) # 得到Beautiful对象 soup = BeautifulSoup(response, "html.parser") # 找到第一个class为key-select txt-sml的标签 type_name = soup.find(attrs={"class": "key-select txt-sml"}) # 找到所有应用名title所在的标签 title_divs = soup.find_all(attrs={"class": "title"}) for title_div in title_divs: if title_div.a is not None: name = title_div.a.text # a['href']得到a的herf属性内容 url = "http://app.hicloud.com" + title_div.a['href'] # string[3:]截取从第三个字符开始到末尾 download = title_div.parent.find(text=re.compile("下载:"))[3:] write_excel(name, type_name.text, url, download) #全局变量:row用来定义行数,方便写入excel行数一直累加,file和sheet因为创建一次就可以 row = 1 # 新建一个excel文件 file = xlsxwriter.Workbook('applist.xlsx') # 新建一个sheet sheet = file.add_worksheet() if __name__ == '__main__': #暂时列出两个类型 url_1 = "http://app.hicloud.com/soft/list_23" url_2 = "http://app.hicloud.com/soft/list_24" get_list(url_1) get_list(url_2) file.close()
实现效果部分截图如下:ヾ(*´▽‘*)ノ
