# -*- coding: utf-8 -*-
"""
Created on Wed Jan 30 23:24:30 2019
@author: Administrator
"""
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
tf.reset_default_graph()
SUMMARY_DIR="log/"
BATCH_SIZE=100
TRAIN_STEPS=3000
#监控信息记入日志
#var:需要记账的张量
#name:图表名称
def variable_summaries(var,name):
with tf.name_scope('summaries'):
#记录张量的取值分布
#记录到buffer中
tf.summary.histogram(name,var)
#求张量的所有元素的平均值
mean=tf.reduce_mean(var)
#日志
#mean/为命名空间
#相同命名空间下的监控指标会被整合到同一栏中。
tf.summary.scalar('mean/'+name, mean)
#标准差
#stddev=tf.sqrt(tf.reduce_mean(tf.square(var-mean)))
#tf.summary.scalar('stddev/'+name,var)
#生成一层全连接神经网络
def nn_layer(input_tensor,input_dim,output_dim,
layer_name,
act=tf.nn.relu):
#将同一层神经网络放在同一命名空间下
with tf.name_scope(layer_name):
#声明神经网络边上的权重,并调用生成权重监控信息日志的函数
with tf.name_scope("weights"):
weights=tf.Variable(tf.truncated_normal(
[input_dim,output_dim],stddev=0.1))
#权重记入日志
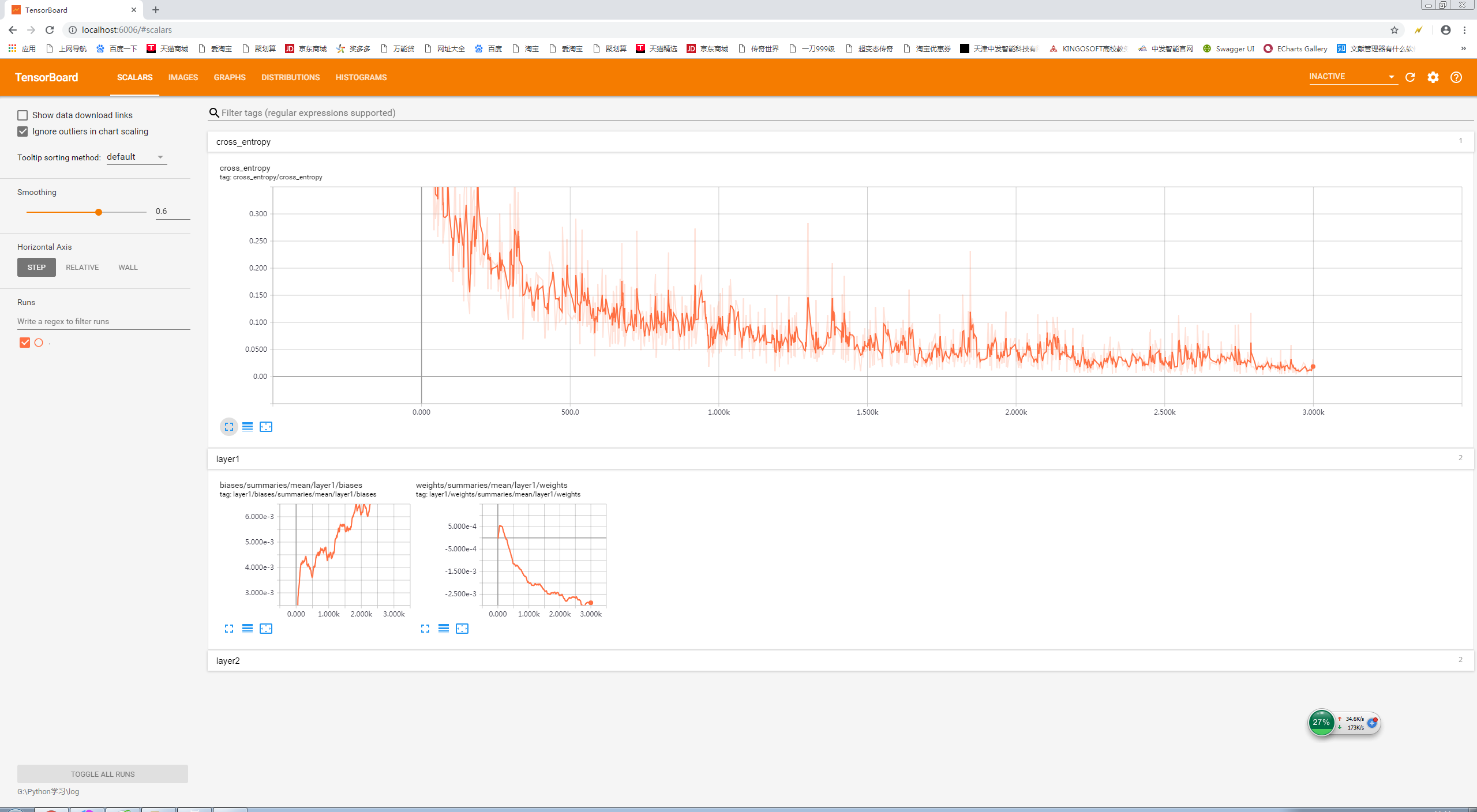
variable_summaries(weights,layer_name+'/weights')
#声明神经网络的偏置项
with tf.name_scope('biases'):
biases=tf.Variable(tf.constant(0.0,shape=[output_dim]))
variable_summaries(biases,layer_name+'/biases')
with tf.name_scope('Wx_plus_b'):
preactivate=tf.matmul(input_tensor,weights)+biases
#记录神经网络输出节点在经过激活函数之前的分布
tf.summary.histogram(layer_name+'/pre_activate',
preactivate)
activations=act(preactivate,name='activation')
#记录神经网络输出节点在经过激活函数之后的分布
#
tf.summary.histogram(layer_name+'/activations',activations)
return activations
def main(argv=None):
mnist=input_data.read_data_sets("MNIST_data/",one_hot=True)
#定义输入
with tf.name_scope("input"):
x=tf.placeholder(
tf.float32,[None,784],
name='x-input')
y_=tf.placeholder(
tf.float32,[None,10],
name='y-input')
#将输入向量还原成图片的像素矩阵,并写入日志
with tf.name_scope('input_reshape'):
image_shaped_input=tf.reshape(x,[-1,28,28,1])
tf.summary.image('input',image_shaped_input,10)
hidden1=nn_layer(x,784,500,'layer1')
y=nn_layer(hidden1,500,10,'layer2',act=tf.identity)
#计算交叉熵,并记录日志
with tf.name_scope('cross_entropy'):
cross_entropy=tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(
labels=y_, logits=y)
)
tf.summary.scalar('cross_entropy',cross_entropy)
with tf.name_scope('train'):
train_step=tf.train.AdamOptimizer(0.001).minimize(cross_entropy)
#计算模型在当前给定数据上的正确率
#并日志
with tf.name_scope('accuracy'):
with tf.name_scope('correct_prediction'):
correct_prediction=tf.equal(tf.argmax(y,1),tf.argmax(y_,1))
with tf.name_scope('accuracy'):
accuracy=tf.reduce_mean(
tf.cast(correct_prediction,tf.float32))
#合并所有的日志操作
merged=tf.summary.merge_all()
with tf.Session() as sess:
summary_writer=tf.summary.FileWriter('log/',sess.graph)
tf.global_variables_initializer().run()
for i in range(TRAIN_STEPS):
xs,ys=mnist.train.next_batch(BATCH_SIZE)
#调用训练
summary,_=sess.run([merged,train_step],
feed_dict={x:xs, y_:ys})
summary_writer.add_summary(summary,i)
summary_writer.close()
if __name__=='__main__':
tf.app.run()