连接
1. 子查询结果作为查询表
需求:需要查询 城市是Woburn分行的熟练柜员(入职日期在2007-01-01以前的)开设的所有账户的相关信息
sql:
-
一种是内连接branch表,和employee表,全部连接完后,再做where条件过滤。
select a.account_id,a.cust_id,a.open_date,a.product_cd from account a inner join employee e on a.open_emp_id = e.emp_id inner join branch b on a.open_branch_id = b.branch_id where e.start_date<'2007-01-01' and (e.title = 'Teller' or e.title = 'Head Teller') and b.city = 'Woburn';

速度:0.025s
-
另一种是可以连接一次,就进行一次where条件过滤。因为account表要连接employee表,且需要的是
熟练柜员,所以这个时候就可以进行条件过滤,并且让account表和对employee表做子查询后的结果集,
做内连接。(让子查询结果作为查询表,可以在这个临时表里内连接)
select a.account_id,a.cust_id,a.open_date,a.product_cd
from account
inner join
(select )
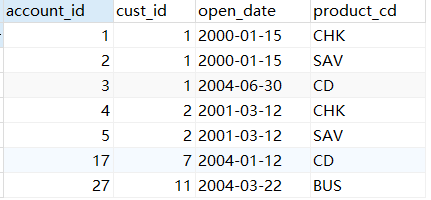
时间: 0.016s
总结:
个人觉得多表查询,把所有的表都连接在一起之后,再做条件过滤,是没有边过滤,边连接快的。
因为先连接所有的相关表,会导致一行非常多。这样检索速度应该也会慢很多,而我的第二种方法,
先做子查询,挑选出这个表符合条件的部分有用(一个id值)数据出来,再连接,这样一行的数据会很少,
按行检索的速度就会很快。
2. 连续俩次使用同一张表
注意:当遇到需要在一个select语句中,连接两次同一张表,这个表的别名一定要不一样!
什么时候:啥时候会遇到这种情况?当多表连接,出现有两张表都需要连接同一张表的情况。
需求:查询账户的开户支行的名称和开户人员的id,以及开户人员现在所在的支行。
(这个查询的目的可能是需要找到当初为我开这个账户的那间银行在哪。还可能需要找出当初为我开这个账户
的那个老员工是谁,现在在哪个银行工作[可能存在跳槽])
分析:account表的open_branch_id是branch表的FK, open_emp_id是employee表的FK,通过open_emp_id去找employee表后还得找出这位员工当前所在的银行,所以还得连接一次branch表
select a.account_id,e.emp_id,b_a.name,b_e.name
from account a
inner join branch b_a
on a.open_branch_id = b_a.branch_id
inner join employee e
on a.open_emp_id = e.emp_id
inner join branch b_e
on e.assigned_branch_id = b_e.branch_id;
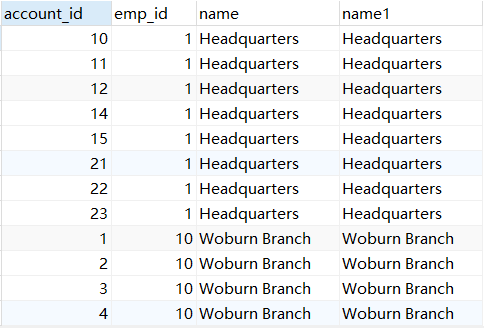
显示:都比较好啊,都没有出现跳槽现象。是一批好员工
3.自连接
需求:列出员工的姓名及 其领导的姓名
select e.fname,e.lname,e_mgr.fname mgr_fname,e_mgr.lname mgr_lname
from employee e
inner join employee e_mgr
where e.superior_emp_id = e_mgr.emp_id;

注意:连接时,默认为内连接。内连接,如果连接字段在某一个表中不存在,则该行直接舍去。
就比如这个查询,最高领导人是没有领导的,所以左边的查询不会出现Michael Smith
额外需求2:找出最高领导人
select e.fname,e.lname
from employee e
where e.superior_emp_id is null;

4. 外连接
4.1 自外连接
就是自连接,但是要连接的表里列出一些不存在的字段出来。
额外需求3:把所有的员工及其领导都列出来,如果有的话,没有也要列出员工
SELECT e.fname,e.lname,e_mgr.fname mgr_fname,e_mgr.lname mgr_lname
FROM employee e
LEFT JOIN employee e_mgr
ON e.superior_emp_id = e_mgr.emp_id;

额外需求4: 把所有的主管列出来,及其管理的员工,如果该主管旗下没有员工,也就表示这个比不是主管,只是普通的员工。也得列出这个普通员工的信息
SELECT e.fname,e.lname,e_mgr.fname mgr_fname,e_mgr.lname mgr_lname
FROM employee e
RIGHT JOIN employee e_mgr
ON e.superior_emp_id = e_mgr.emp_id;
总结:连接查询,不是先查出这个值不为NULL的行出来,再做连接。而是一行一行的检索,如果这个JOIN左侧的连接字段为null, 是内连接的话,则该行直接舍去,不放入结果集。如果是左外连接,那么JOIN左侧的表保留,右侧的连接字段 为NULL。右外连接,就是JOIN右侧的表保留,左侧为NULL。
清晰总结:
左连接,结果集包括LEFT OUTER JOIN左边指定的表的所有行,而不仅仅是连接列所匹配到的行,如果在JOIN右表中,匹配不到(比如左边的连接列的字段在右边确实找不到,又或者左边连接列的字段为NULL),这时候,右表的字段全部赋予NULL值,并输出。
右连接,结果集包括RIGHT OUTER JOIN 右边指定的表的所有行,而不仅仅是连接列所匹配到的行,如果在JOIN的左表中,这些在右表中没有被左表匹配到的行也会进行输出,只不过该行的左表字段全部赋予NULL。
额外需求5:列出所有的普通员工 (没有管理任何人)
思路:当在superior_emp_id列检索,发现找了一圈,都没有发现某个id的身影,就表示这个Id是普通员工,
未曾出现在主管列中。
注意:下面这个版本的sql语句是错的,会查出空值,但思路是对的
SELECT e.fname,e.lname
FROM employee e
WHERE e.emp_id not in
(SELECT e_self.superior_emp_id
FROM employee e_self);
总结:当not in 后的范围中存在null值,则一条都不返回。
正解:
SELECT e.fname,e.lname
FROM employee e
WHERE e.emp_id not in
(SELECT e_self.superior_emp_id
FROM employee e_self
WHERE e_self.superior_emp_id IS NOT NULL);
作业:构建查询,查找所有主管位于另一个部门的雇员,需要获取该雇员的ID,姓氏和名字
思路:自连接
SELECT e.emp_id,e.fname,e.lname
FROM employee e
INNER JOIN employee e_self
ON e.superior_emp_id = e_self.emp_id
WHERE e.dept_id <> e_self.dept_id;

5. 事务
需求:生成一个事务,它从Frank Tucker 的货币市场账户存款转账 $50到他的支票账户,要求插入两行到transaction
分析:
- Frank Tucker这是从个体表里才知道的名字,然后根据账户类型, 找到对应的account
首先tansaction表是需要很多字段值的,比如account_id,这里的account_id要和account表连接,也就是要利用到查询出来的id,然后把这个Id插入到transaction表里去。要用到select into的语法,
然后操作account表,需要cust_id才找得到Frank Tucker 的账户是哪个
START TRANSACTION;
SELECT i.cust_id,
(SELECT a.account_id
FROM account a
WHERE a.product_cd = 'MM' AND a.cust_id = i.cust_id) mm_id,
(SELECT a.account_id
FROM account a
WHERE a.product_cd = 'chk' AND a.cust_id = i.cust_id) chk_id
INTO @cst_id,@mm_id,@chk_id
FROM individual i
WHERE i.fname = 'Frank' AND i.lname = 'Tucker';
INSERT INTO transaction
(txn_date,account_id,txn_type_cd,amount)
VALUES(now(),@mm_id,'CDT',50);
INSERT INTO transaction
(txn_date,account_id,txn_type_cd,amount)
VALUES(now(),@chk_id,'DBT',50);
UPDATE account
SET last_activity_date = now(),
avail_balance = avail_balance - 50
WHERE account_id = @mm_id;
UPDATE account
SET last_activity_date = now(),
avail_balance = avail_balance + 50
WHERE account_id = @chk_id;
commit;
transaction表

下面是account表
