菜菜哥,告诉你一个消息

你有男票啦?

非也非也,我昨天出去偷偷面试,结果又挂了
哦,看来公司是真的不想让你走呀
面试官让我说一下乐观锁和悲观锁,我没回答上来,回来之后我查了,数据库没有这两种锁呀
了解这两种锁之前,我觉得你需要先了解一下数据库的锁机制

开局

我们平时编写程序的时候,有很多情况下需要考虑线程安全问题,一个全局的变量如果有可能会被多个同时执行的线程去修改,那么对于这个变量的修改就需要有一种机制去保证值的正确性和一致性,这种机制普遍的做法就是加锁。其实也很好理解,和现实中一样,多个人同时修改一个东西,必须有一种机制来把多个人进行排队。计算机的世界中也是如此,多个线程乃至多个进程同时修改一个变量,必须要对这些线程或者进程进行排队。数据库的世界亦是如此,多个请求同时修改同一条数据记录,数据库必须需要一种机制去把多个请求来顺序化,或者理解为同一条数据记录同一时间只能被一个请求修改。
锁是数据库中最为重要的机制之一,无论平时写的select语句,还是update语句其实在数据库层面都和锁息息相关。如果没有锁机制,操作数据的时候可能会发生以下情况:
1. 更新丢失:多个用户同时对一个数据资源进行更新,必定会产生被覆盖的数据,造成数据读写异常。
2. 不可重复读:如果一个用户在一个事务中多次读取一条数据,而另外一个用户则同时更新啦这条数据,造成第一个用户多次读取数据不一致。
3. 脏读:第一个事务读取第二个事务正在更新的数据表,如果第二个事务还没有更新完成,那么第一个事务读取的数据将是一半为更新过的,一半还没更新过的数据,这样的数据毫无意义。
4. 幻读:第一个事务读取一个结果集后,第二个事务,对这个结果集经行增删操作,然而第一个事务中再次对这个结果集进行查询时,数据发现丢失或新增。
数据管理角度

在数据库管理的角度或者数据行的角度来说,数据库锁可以分为共享锁和排它锁,这是面试过程中经常被提及的两种类型。本质其实很简单,站在数据的角度来看,如果数据当前正在被访问,下一个访问的请求该如何处理?和计算机二进制一样,无非就是允许被访问和不允许访问两种状态。
共享锁
共享所被称为读锁或者S锁,就像以上所述,共享锁在新请求访问一个数据的时候,如果是读请求则允许,如果是写(删改)请求,则不允许。由于共享锁允许其他的读操作,所以通常情况下共享锁只应用于select操作,如果一个update或者delete操作应用共享锁会发生很严重的数据不一致情况。
独占锁
独占锁也被称为排它锁或者X锁,相对于共享锁,独占锁采用的态度比较坚决,一旦数据被独占锁锁定,其他任何请求(包括读操作)都必须等待独占锁的释放才可以继续,只有当前锁定数据的请求才可以修改读取数据。
更新锁
当数据库准备更新数据时,它首先对数据对象作更新锁锁定,这样数据将不能被修改,但可以读取。等到确定要进行更新数据操作时,他会自动将更新锁换为独占锁,当对象上有其他锁存在时,无法对其加更新锁。
意向锁
简单来说就是给更大一级别的空间示意里面是否已经上过锁。例如表级放置了意向锁,就表示事务要对表的页或行上使用共享锁。在表的某一行上上放置意向锁,可以防止其它事务获取其它不兼容的的锁。意向锁可以提高性能,因为数据引擎不需要检测资源的每一列每一行,就能判断是否可以获取到该资源的兼容锁。意向锁包括三种类型:意向共享锁(IS),意向排他锁(IX),意向排他共享锁(SIX)。
实际应用中,站在数据的角度可以看出,数据只允许同时进行一个写操作
颗粒度角度
锁用来对数据进行锁定,我们可以从锁定对象的粒度大小来对锁进行划分,分别为行锁、页锁和表锁。
1. 行级锁是数据库中锁定粒度最细的一种锁,表示只针对当前操作的行进行加锁。行级锁能大大减少数据库操作的冲突。其加锁粒度最小,但加锁的开销也最大。特点:开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。
2. 表级锁是数据库中锁定粒度最大的一种锁,表示对当前操作的整张表加锁,它实现简单,资源消耗较少。特点:开销小,加锁快;不会出现死锁;锁定粒度大,发出锁冲突的概率最高,并发度最低。
3. 页级锁是数据库中锁定粒度介于行级锁和表级锁中间的一种锁。表级锁速度快,但冲突多,行级冲突少,但速度慢。所以取了折衷的页级,一次锁定相邻的一组记录。特点:开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般
不同数据库支持的锁力度不同,甚至同一种数据库不同的引擎支持的锁力度都不同,如下表所示(来源于网络)
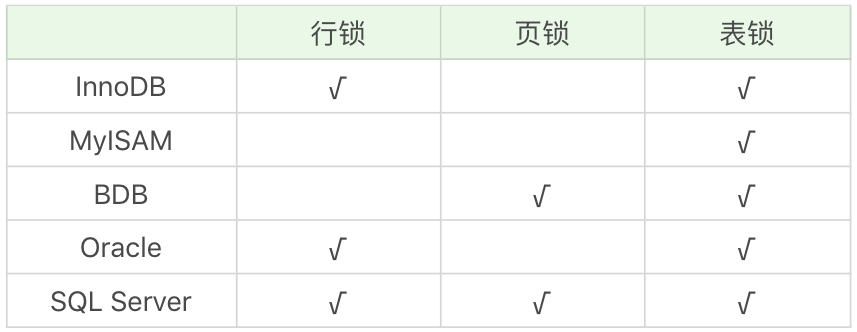
这里要强调一点,无论什么数据库对数据加锁,都需要资源的消耗,因此锁的数量其实是有上限的,当锁数量到达这个上限会自动进行锁力度的升级,用更大力度的锁来代替多个小力度的锁。
乐观锁和悲观锁
乐观锁
乐观锁认为一般情况下数据不会造成冲突,所以在数据进行提交更新时才会对数据的冲突与否进行检测。如果没有冲突那就OK;如果出现冲突了,则返回错误信息并让用户决定如何去做。类似于 SVN、GIt这些版本管理系统,当修改了某个文件需要提交的时候,它会检查文件的当前版本是否与服务器上的一致,如果一致那就可以直接提交,如果不一致,那就必须先更新服务器上的最新代码然后再提交(也就是先将这个文件的版本更新成和服务器一样的版本)
乐观锁是一种程序的设计思想,通过一个标识的对比来决定数据是否可以操作,现在普遍的做法是给数据加一个版本号或者时间戳的方式来实现乐观锁操作过程:
在表中设计一个版本字段 version,第一次读的时候,会获取 version 字段的取值。然后对数据进行更新或删除操作时,会执行UPDATE ... SET version=version+1 WHERE version=version。此时如果已经有事务对这条数据进行了更改,修改就不会成功。
悲观锁
每次获取数据的时候,都会担心数据被修改,所以每次获取数据的时候都会进行加锁,确保在自己使用的过程中数据不会被别人修改,使用完成后进行数据解锁。由于数据进行加锁,期间对该数据进行读写的其他线程都会进行等待。
总结
无论是乐观锁和悲观锁,并非是数据库自身持有的锁类型(虽然悲观锁形式上很像独占锁),而是程序设计的一种思想,是一种类似数据库锁机制保护数据一致性的策略。
1. 悲观锁比较适合写入操作比较频繁的场景,如果出现大量的读取操作,每次读取的时候都会进行加锁,这样会增加大量的锁的开销,降低了系统的吞吐量。
2. 乐观锁比较适合读取操作比较频繁的场景,如果出现大量的写入操作,数据发生冲突的可能性就会增大,为了保证数据的一致性,应用层需要不断的重新获取数据,这样会增加大量的查询操作,降低了系统的吞吐量。
写在最后

程序编写过程中,操作数据无论采用哪个类型的锁,都需要注意死锁的发生,一个死锁有可能对整个应用是致命的。死锁的本质是对资源竞争的一种失败表现,所以sql语句的编写过程中对于多表的操作最好采用一致的顺序来进行,另外一个种极端的方式可以一次性锁定所有资源,而非逐步来锁资源。

