众所周知,MANIFEST.MF文件中的空格开头的行是相当于拼接在上一行末尾的。很多又长又乱的Import-Package或者Export-Package,有时候想要搜索某个package却可能被换行截断而搜不到。
这时候咱们可以对它进行格式化重新排列,同时又不影响它的正常运行。再排个序方便查找。
排列前 vs 排列后
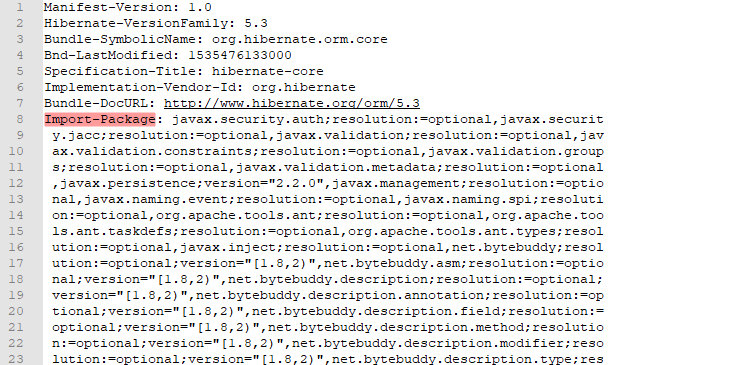
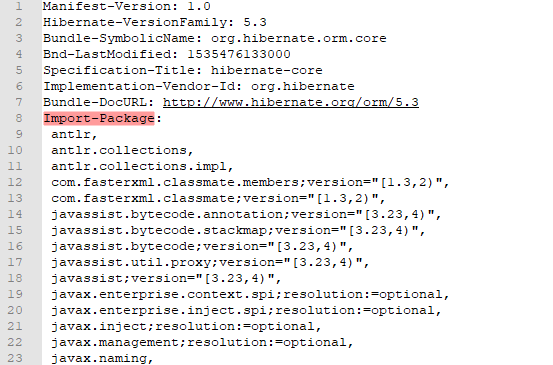
附上干货 !!!
(脚本方式,对于长一点的package慢的一批,待优化;可对jar文件直接执行,免解压读取META-INF/MANIFEST.MF)
#!/bin/bash # MANIFEST.MF文件对Import-Package/Export-Package重排列 function main() { echo $1 | egrep ".jar$|.zip$" &>/dev/null if [ $? -eq 0 ];then MANIFEST=$(unzip -p $1 META-INF/MANIFEST.MF) [ $? -ne 0 ] && echo ${MANIFEST} && exit 1 else MANIFEST=$(cat $1) fi isWindowsDoc="false" # 判断文件格式是windows还是unix [ "" != "$(echo "$MANIFEST" | sed -n ":a;N;/ /p;ba")" ] && isWindowsDoc="true" MANIFEST=$(echo "$MANIFEST" | dos2unix) # 空格开头的行,合并到一行 MANIFEST=$(echo "$MANIFEST" | sed ":a;N;s/ //g;ba") importPackage=$(echo "${MANIFEST}" | egrep "^Import-Package:" | sed 's/^Import-Package: *//g' | sed 's/ //g') exportPackage=$(echo "${MANIFEST}" | egrep "^Export-Package:" | sed 's/^Export-Package: *//g' | sed 's/ //g') output=$(echo "${MANIFEST}") # 引号外的逗号转为特殊分隔符 if [ "" != "${importPackage}" ];then importPackage=$(dealStrByPython ${importPackage}) importPackage="Import-Package: ${importPackage}" len=${#importPackage} importPackage=$(echo -e "${importPackage:0:$((len-1))}") # 去掉最后一个字符 oneLineImport=$(echo "${importPackage}" | sed ":a;N;s/ /#/g;ba") # sed命令不能一行换多行,将换行符转为#号变成一行,替换后#号再转回换行符 output=$(echo "${output}" | sed 's/^Import-Package:.*/'"${oneLineImport}"'/g' | sed "s/#/ /g") fi if [ "" != "${exportPackage}" ];then exportPackage=$(dealStrByPython ${exportPackage}) exportPackage="Export-Package: ${exportPackage}" len=${#exportPackage} exportPackage=$(echo -e "${exportPackage:0:$((len-1))}") oneLineExport=$(echo "${exportPackage}" | sed ":a;N;s/ /#/g;ba") output=$(echo "${output}" | sed 's/^Export-Package:.*/'"${oneLineExport}"'/g' | sed "s/#/ /g") fi if [ "true" == "${isWindowsDoc}" ];then echo "${output}" | unix2dos else echo "${output}" fi } #按逗号分隔字符串,并忽略双引号中的逗号 #逐个字符遍历 #效率贼慢 function dealStr() { str=$1 newStr="" isOpenQuotes="false" splitChar="#" # 遍历字符串的字符 for((i=0; i<${#str}; i++)) do char=${str:$i:1} if [ "$char" == '"' ];then if [ "$isOpenQuotes" == "false" ];then isOpenQuotes="true" else isOpenQuotes="false" fi fi [ "$char" == "," ] && [ "$isOpenQuotes" == "false" ] && char=${splitChar} newStr=${newStr}${char} done # 按特殊分隔符分割、排序 echo "${newStr}" | awk -F '#' '{for(n=1;n<=NF;n++) print " "$n","}' | sort } #按逗号分隔字符串,并忽略双引号中的逗号 #遍历字符串中的双引号和逗号 #效率快了一点点 function dealStrTest() { str=$1 newStr="" isOpenQuotes="false" splitChar="#" while true do indexOfQuotes=`expr index $str '"'` indexOfComma=`expr index $str ','` # 处理引号 if [ $indexOfQuotes -gt 0 ] && [ $indexOfComma -gt 0 ] && [ $indexOfQuotes -lt $indexOfComma ];then if [ "$isOpenQuotes" == "false" ];then isOpenQuotes="true" else isOpenQuotes="false" fi newStr=${newStr}${str:0:$indexOfQuotes} str=${str:$indexOfQuotes} # 处理逗号 elif [ $indexOfQuotes -gt 0 ] && [ $indexOfComma -gt 0 ] && [ $indexOfComma -lt $indexOfQuotes ] || [ $indexOfQuotes -eq 0 ] && [ $indexOfComma -gt 0 ];then [ "$isOpenQuotes" == "false" ] && newStr=${newStr}${str:0:$indexOfComma-1}${splitChar} [ "$isOpenQuotes" != "false" ] && newStr=${newStr}${str:0:$indexOfComma} str=${str:$indexOfComma} # 逗号没了 elif [ $indexOfComma -eq 0 ];then newStr=${newStr}${str} break else break fi done # 按特殊分隔符分割、排序 echo "${newStr}" | awk -F '#' '{for(n=1;n<=NF;n++) print " "$n","}' | sort } #按逗号分隔字符串,并忽略双引号中的逗号 #使用python逐个字符遍历 #效率更快了 function dealStrByPython() { str=$1 newStr=`python -c " str='$str' isOpenQuotes=False splitChar='#' chArr=[] for ch in str.replace(' ',''): if ch == '"' : isOpenQuotes = bool(1-isOpenQuotes) if ch == ',' and isOpenQuotes == False : chArr.append(splitChar) else : chArr.append(ch) print(''.join(chArr)) "` # 按特殊分隔符分割、排序 echo "${newStr}" | awk -F '#' '{for(n=1;n<=NF;n++) print " "$n","}' | sort } main $@
(java方式)
import java.io.BufferedReader; import java.io.BufferedWriter; import java.io.ByteArrayInputStream; import java.io.File; import java.io.FileReader; import java.io.FileWriter; import java.io.IOException; import java.util.Arrays; import java.util.Collections; import java.util.List; import java.util.Properties; public class ManifestFormatter { private final static String IMPORT_PACKAGE = "Import-Package"; private final static String EXPORT_PACKAGE = "Export-Package"; private final static char SEPARATOR = '#'; public static void main(String[] args) { File mf = new File(args[0]); File formatMf = new File(mf.getParentFile(), "MANIFEST.MF.FORMAT"); if (!mf.exists()) { System.out.println(mf.getAbsolutePath() + " is format failed: " + mf.getAbsolutePath() + " is not exits"); System.exit(2); } try (BufferedReader br = new BufferedReader(new FileReader(mf)); BufferedWriter bw = new BufferedWriter(new FileWriter(formatMf));) { StringBuilder fileToString = new StringBuilder(); char[] chars = new char[1024]; int len; while ((len = br.read(chars, 0, chars.length)) != -1) { fileToString.append(new String(chars, 0, len)); } // 转换MANIFEST.MF文件中的属性为单行模式,并保持原来的文档格式 String lineSeparator = fileToString.indexOf(" ") != -1 ? " " : " "; String formatStr = fileToString.toString().replaceAll(lineSeparator + " ", ""); ByteArrayInputStream bi = new ByteArrayInputStream(formatStr.getBytes()); Properties properties = new Properties(); properties.load(bi); // 回写MANIFEST.MF文件,重新写入Import-Package与Export-Package String importPackageStr = properties.getProperty(IMPORT_PACKAGE); if (importPackageStr != null && importPackageStr.length() > 0) { List<String> importPackageList = getPackageList(importPackageStr); String newImportPackageStr = createNewPackage(importPackageList, IMPORT_PACKAGE, lineSeparator); formatStr = formatStr.replaceAll("Import-Package:.*" + lineSeparator, newImportPackageStr); } String exportPackageStr = properties.getProperty(EXPORT_PACKAGE); if (exportPackageStr != null && exportPackageStr.length() > 0) { List<String> exportPackageList = getPackageList(exportPackageStr); String newExportPackageStr = createNewPackage(exportPackageList, EXPORT_PACKAGE, lineSeparator); formatStr = formatStr.replaceAll("Export-Package:.*" + lineSeparator, newExportPackageStr); } bw.write(formatStr); } catch (IOException e) { System.out.println(mf.getAbsolutePath() + " is format failed: " + e.getMessage()); e.printStackTrace(); System.exit(1); } System.out.println(mf.getAbsolutePath() + " is format successed"); } /** * 重新创建Import-Package与Export-Package * * @param packageList * @param packageType * @param lineSeparator * @return */ private static String createNewPackage(List<String> packageList, String packageType, String lineSeparator) { StringBuilder newPackageString = new StringBuilder(packageType).append(":").append(lineSeparator); int size = packageList.size(); for (int i = 0; i < size; i++) { newPackageString.append(" "); newPackageString.append(packageList.get(i)); if (i < size - 1) { newPackageString.append(","); } newPackageString.append(lineSeparator); } return newPackageString.toString(); } /** * 单行的Import-Package或Export-Package,转化为list数组 * * @param packageStr 单行的Import-Package或Export-Package * @param packageType "Import-Package"或"Export-Package" * @return */ private static List<String> getPackageList(String packageStr) { boolean isOpenQuotes = false; char[] chArr = packageStr.replaceAll(" ", "").toCharArray(); int len = chArr.length; // 双引号外面的逗号,转为分隔符 for (int i = 0; i < len; i++) { if (chArr[i] == '"') { isOpenQuotes = !isOpenQuotes; } if (chArr[i] == ',' && !isOpenQuotes) { chArr[i] = SEPARATOR; } } List<String> packageList = Arrays.asList(new String(chArr).split(SEPARATOR + "")); Collections.sort(packageList); return packageList; } }