第一章:编译器介绍
1.1 编译器概述
什么是编译器?
- 计算设备包括个人计算机、大型机、嵌入式系统、智能设备等。
- 核心的问题都是软件的构造
- 而目前绝大部分软件都由高级语言书写
- 成百种高级语言
- 这些语言是如何运行在计算机系统上的?
- 编译器
示例
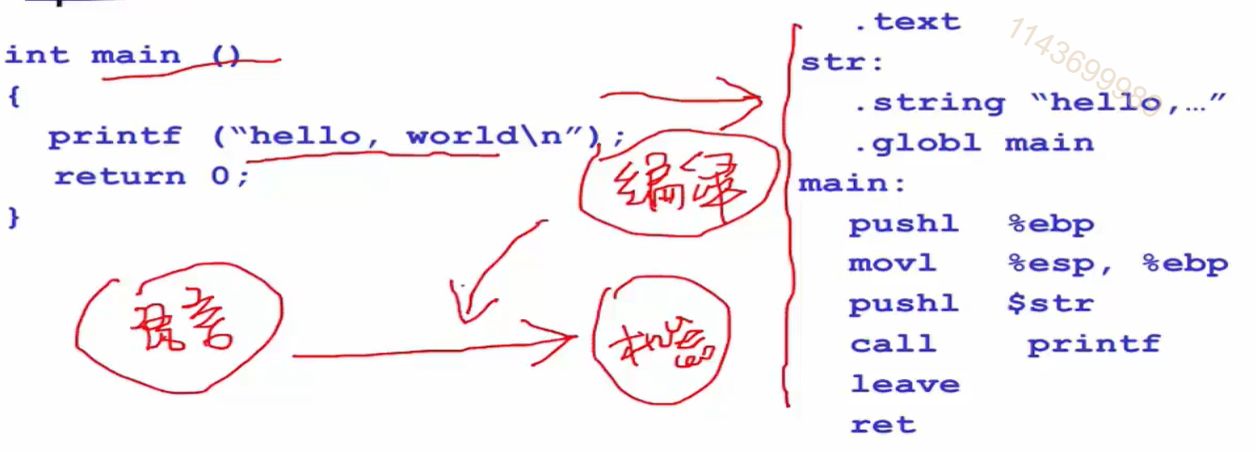
完成高级语言到机器语言的编译的都是编译器
- 编译器是一个程序
- 核心功能是源代码翻译成目标代码
- 源代码:
- C/C++, Java, C#, html, SQL,...
- 目标代码:
- x86,IA64, ARM, MIPS, ...
- 源代码:
也可能是像C++被cfront编译成C再由gcc编译成x86,cfront依然是编译器,即目标代码可以是高级程序语言,而不是一定是机器语言。
编译器的核心功能
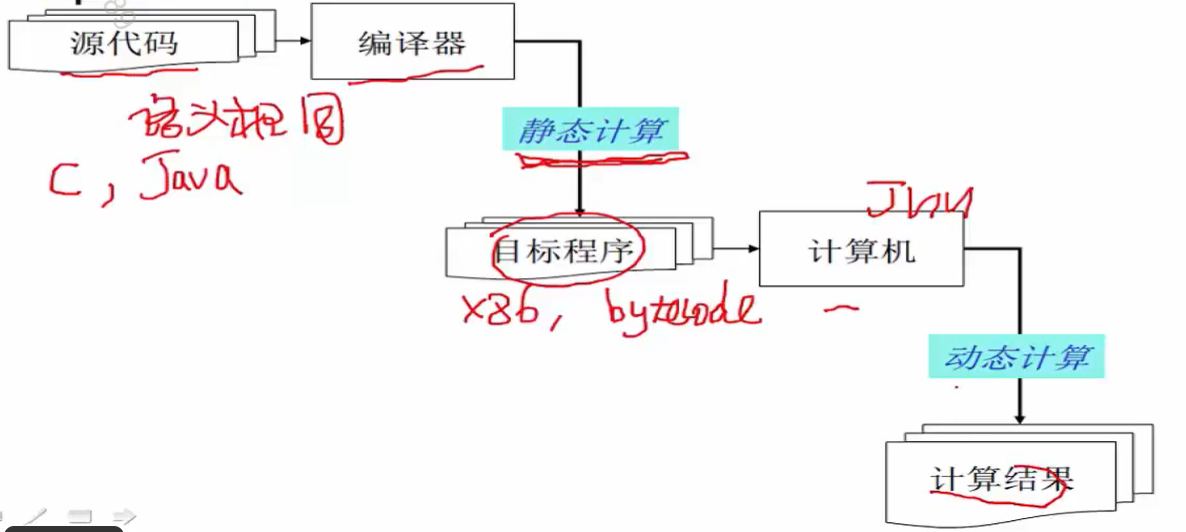
静态计算的意思是编译器在翻译这个源代码的过程中并不去执行这个源代码,而是尝试以一种静态的方式对程序员所写的源代码的意义加以理解。
理解的原因是编译器设计中的一个最基本的要求是所生成的目标程序要和源代码语义相同。
源代码要完成什么样的功能,由编译器所生成的目标代码同样要完成什么样的功能,含义不能有任何改变,即语义相同或语义保持。
为了达到这点,编译器需要做很多静态分析和静态计算。
对于C,可能生成的就是x86可能是在PC上运行(动态计算)出计算结果。
对于Java,可能生成的是bytecode(字节码)是在JVM(虚拟机)上运行(动态计算)出计算结果。
编译器和解释器
- 解释器也是处理程序的一种程序
对于编译器来说,有输出和输出,输出的是一个存放在磁盘上的可执行程序。离线方式(offline)
对于翻译器来说,有输入和输出,输出的是结果。
翻译器直接把程序的结果输出,没有先生成可执行程序再由计算机执行出结果这一步。在线方式(online)
编译器的简史
-
计算机科学史上出现的第一个编译器是Fortran语言的编译器
- 1954-1957年,John Backus
-
Fortran编译器的成功给计算机科学发展产生巨大影响
-
理论上:形式语言、自动机技术
-
实践上:算法、数据结构
-
编译器架构
-
为什么学习编译原理?
- 编译原理集中体现了计算机科学的很多核心思想
- 算法、数据结构、软件工程等
- 编译器是其他领域的重要研究基础
- 编译器本身就是非常重要的研究领域
- 新的语言设计
- 大型软件的构造和维护
如何学好编译原理?
- 编译器设计是理论和实践高度结合的一个领域,学习处理好二者的关系。
- 理论:深入学习掌握各种算法和数据结构
- 实践:切实提高将理论应用于解决实际问题的能力
1.2 编译器结构
编译器的高层结构
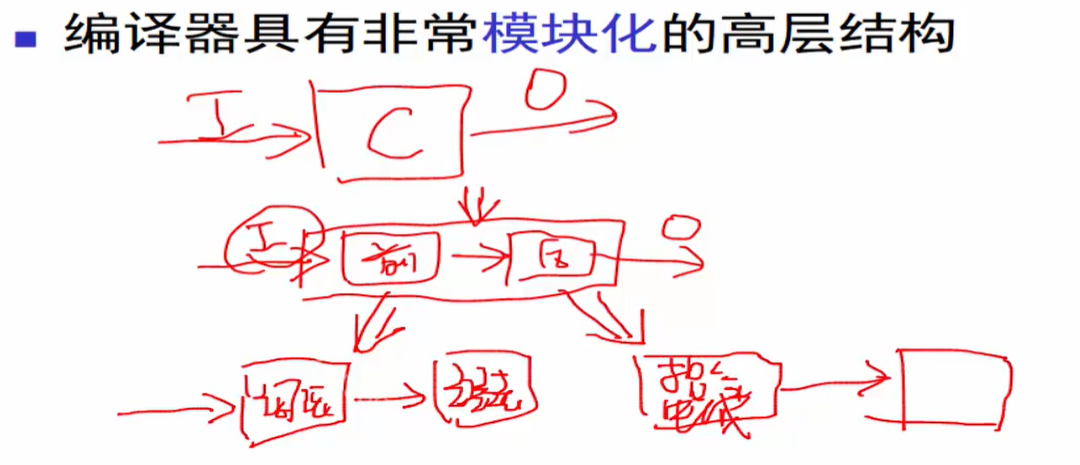
编译器作为一个软件,具有输入和输出。输入一般来说是某一种程序设计语言。输出可能是某个体系结构上的一个机器语言。
从内部结构上开说,编译器有一个前端和后端。
分成前后端的原因很简单,因为编译器是把一个源程序翻译成目标程序。
所以对前端来说,它主要处理和输入相关的部分,比如这是一个什么语言、什么语法规则、要满足哪些约束条件等等。
对后端来所,所要翻译到的目标机器有哪些指令集,这些指令集有哪些约束。
然后前端的语法结构怎么映射到后端的指令集上来。
通过把编译器内部结构分散成前后端这样的两个结构,有助于把相关的任务进行隔离,从而使得编译器的设计更容易,更具模块性。
对编译器内部进一步做分解,对于前端具有词法分析、语法分析的部分,对于后端具有指令生成、指令优化的部分。
抽象的多个阶段(phase)
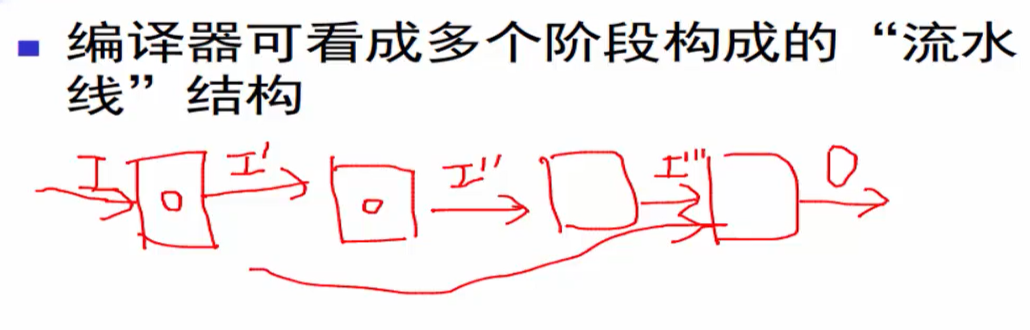
由一个一个的中间语言到最后的输出,每一个中间语言完成相应的任务。
把第一个输出\(I\)经过第一个中间语言输出\(I'\)到第二个中间语言,一直到最后的\(I'''\)输出最终的可执行语言。
设计流水线模式来一步一步逐渐靠近最终输出的原因:
- 现在的高级语言都比较高层、抽象,如果通过一次性的编译到达最终的输出难度比较大,通过把编译过程切分成一个一个的阶段,可以把编译难度一层一层降低,逐步靠近目标体系结构。
- 从软件工程的角度来说,任何的编译器都可能是规模庞大且复杂的,如果把所有功能都写在一个模块中,从工程上不可取。通过阶段划分,可以使得每一个模块容易实现、而且容易维护。
一种没有优化的编译器结构
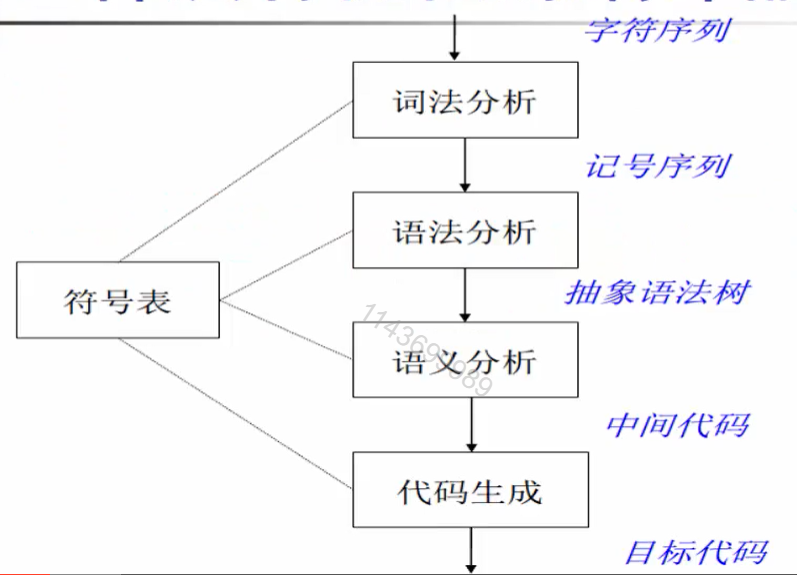
最开始的输入是一个字符序列,也就是说是一个程序代码存放在程序文本里面,表现的形式是一个字符序列。
然后进入编译器之后,进行处理的第一个阶段是词法分析,输出一个记号序列,作为下一个阶段的输入。
语法分析检查记号序列是否符合语言的语法和规则,然后会在内存建立抽象语法树,这样一个数据结构。
抽象语法树是对程序语法的抽象表示。
语义分析试图对语法树的合法性做处理,例如变量在使用之前是否被定义,所调用的函数是否有相对应的函数的定义。这些规则对于语言来说也许是不一样的。
经过语义分析之后,可以保证程序之中语法语义是正确的。
中间代码的形式多样:三地址代码、SSA、控制流图
中间代码的选择取决于编译器的特性,后续是否需要优化,或者注重性能还是速度。
由目标代码可能经过汇编器或链接器的处理生成最终可以在机器上实现的可执行文件。
在整个过程中,这些模块可能都需要和一个模块表来进行交互,符号表是存取了程序编译过程中相关的重要信息,可以给每个阶段提供支持。
更复杂的一种编译器结构
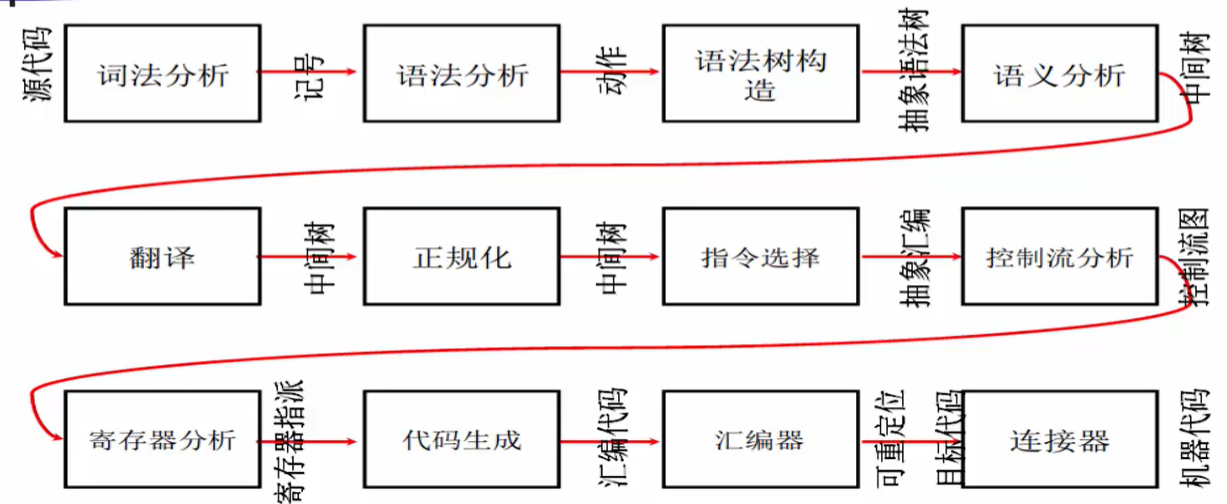
源代码经过词法分析得到了一组记号,记号又通过语法分析生成了相关的语法动作,这些动作用来构造语法树,即可输出抽象语法树(在内存当中重要的数据结构),被语义分析进一步检查语义,同时生成中间树,中间树经过翻译可能得到了一个优化版的中间树,再经过正规化继续进行中间树的优化,后续经过指令选择,在最终优化得到的中间树上对每个高层的语法结构选择合适的汇编指令来对其进行实现,即完成语法结构到汇编的映射,那么映射完成之后,即可得到一个抽象的汇编,这个抽象的汇编里面的可能已经指定了部分的寄存器的使用,后续都是对汇编的优化,经过控制流分析得到另外的中间表示,控制流图(后续重点),然后经过寄存器分析模块得到寄存器指派,即哪些变量放到哪些寄存器,之后在代码生成模块即可生成汇编代码,汇编代码经过汇编器和链接器最终生成可以执行的机器代码。
小结
- 编译器由多个阶段组成,每个阶段都要处理不同的问题
- 使用不同的理论、数据结构和算法
- 因此,编译器设计中的重要问题是如何合理的划分组织各个阶段
- 接口清晰
- 编译器容易实现、维护
示例
-
源语言:加法表达式语言Sum
- 两种语法形式:
- 整型数字n
- 加法e1+e2
- 两种语法形式:
-
目标机器:栈式计算机Stack
- 两条指令:
- push n
- add
- 两条指令:
-
任务:编译程序1+2+3到栈式计算机
1.3 编译器示例
阶段一:词法分析
阶段二:语法树构建
阶段三:代码生成
#include <stdio.h>
#include <stdlib.h>
// Data structures for the Sum language.
enum Exp_Kind_t { EXP_INT, EXP_SUM }; //表达式的类型
struct Exp_t //作为指针,既可以指向数,也可以指向加法
{
enum Exp_Kind_t kind;
};
struct Exp_Int //表达式是一个数
{
enum Exp_Kind_t kind;
int i;
};
struct Exp_Sum //表达式是加法
{
enum Exp_Kind_t kind;
struct Exp_t* left;
struct Exp_t* right;
};
// "constructors"
struct Exp_t* Exp_Int_new(int i) //构造一个数节点
{
struct Exp_Int* p = (struct Exp_Int *)malloc(sizeof(*p));
p->kind = EXP_INT;
p->i = i;
return (struct Exp_t*)p;
}
struct Exp_t* Exp_Sum_new(struct Exp_t* left, struct Exp_t* right) //构造一个加法节点
{
struct Exp_Sum* p = (struct Exp_Sum *)malloc(sizeof(*p));
p->kind = EXP_SUM;
p->left = left;
p->right = right;
return (struct Exp_t*)p;
}
// "printer"
void Exp_print(struct Exp_t* exp) //根据构造出的语法树,将表达式输出
{
switch (exp->kind) {
case EXP_INT: {
struct Exp_Int* p = (struct Exp_Int*)exp;
printf("%d", p->i);
break;
}
case EXP_SUM: {
struct Exp_Sum* p = (struct Exp_Sum*)exp;
Exp_print(p->left);
printf("+");
Exp_print(p->right);
break;
}
default:
break;
}
}
// Data structures for the Stack language.
enum Stack_Kind_t { STACK_ADD, STACK_PUSH };
struct Stack_t
{
enum Stack_Kind_t kind;
};
struct Stack_Add
{
enum Stack_Kind_t kind;
};
struct Stack_Push
{
enum Stack_Kind_t kind;
int i;
};
// "constructors"
struct Stack_t* Stack_Add_new()
{
struct Stack_Add* p = (struct Stack_Add *)malloc(sizeof(*p));
p->kind = STACK_ADD;
return (struct Stack_t*)p;
}
struct Stack_t* Stack_Push_new(int i)
{
struct Stack_Push* p = (struct Stack_Push *)malloc(sizeof(*p));
p->kind = STACK_PUSH;
p->i = i;
return (struct Stack_t*)p;
}
// instruction list
struct List_t
{
struct Stack_t* instr; //指令
struct List_t* next; //下一条指令
};
struct List_t* List_new(struct Stack_t* instr, struct List_t* next) //生成一个指令节点
{
struct List_t* p = (struct List_t *)malloc(sizeof(*p));
p->instr = instr;
p->next = next;
return p;
}
// "printer"
void List_reverse_print(struct List_t* list) //逆序输出
{
//TODO();
if (list == NULL)
return;
List_reverse_print(list->next);
if (list->instr->kind == STACK_ADD)
printf("ADD\n");
else {
struct Stack_Push* p = (struct Stack_Push*) list->instr;
printf("PUSH %d\n", p->i);
}
}
// a compiler from Sum to Stack
struct List_t* all = 0;
void emit(struct Stack_t* instr)
{
all = List_new(instr, all);
}
void compile(struct Exp_t* exp)
{
switch (exp->kind) {
case EXP_INT: {
struct Exp_Int* p = (struct Exp_Int*)exp;
emit(Stack_Push_new(p->i));
break;
}
case EXP_SUM: {
//TODO();
struct Exp_Sum* p = (struct Exp_Sum*)exp;
compile(p->left);
compile(p->right);
emit(Stack_Add_new());
break;
}
default:
break;
}
}
// program entry
int main()
{
printf("Compile starting\n");
// build an expression tree:
// +
// / \
// + 3
// / \
// 1 2
struct Exp_t* exp = Exp_Sum_new(Exp_Int_new(1),
Exp_Sum_new(Exp_Int_new(2),Exp_Int_new(3)));
// print out this tree:
printf("the expression is:\n");
Exp_print(exp);
// compile this tree to Stack machine instructions
compile(exp);
printf("\n\nThe Stack Instrction\n");
// print out the generated Stack instructons:
List_reverse_print(all);
printf("\nCompile finished\n");
return 0;
}
输出:
