目录
1.1.3、Command and Control:命令化的批量完成 3
7.6、Boolean operators 布尔运算符 24
7.7、Arithmetic operators 算数运算符 24
8.4.2、CONTROL_EXPRESSION(控制表达式) 26
8.5.2、CONTROL_VARIABLE的给定方法 27
一、puppet的作用
Puppet是一个基础设施自动化管理工具,它能够帮助系统管理员管理基础设施的整个生命周期:供应(provisioning)、配置(configuration)、联动(orchestration)及报告(reporting);
Provisioning:指的是对操作系统之上的应用程序包的供应和安装;
Configuration:并不是puppet来配置,而是提供配置文件;
Orchestration:叫编排更合适,比如要部署一个lnmt;我们先要去部署mariadb,然后再去部署tomcat,而后前端加一个反代,反代用户请求到tomcat;那这个过程到底谁先谁后,以及在此次应用中装什么样的程序包,提供什么样的配置文件,要不要启动服务,如何启动,要不要开机自动启动,我们都可以在一个文件中定义好;这个文件定义完成后,可以让puppet一次读取,按照我们定义好的顺序依次执行;
Reporting:当联动完成后,agent要报告给puppet任务是否完成;
基于puppet,可实现自动化重复任务、快速部署关键性应用以及在本地或云端完成主动管理变更和快速扩展架构规模等;
遵循GPL协议(2.7.0-),基于ruby语言开发;2.7.0以后使用apache 2.0 license;
对于系统管理员是抽象的;只依赖于ruby与facter;
能管理多大40多种资源,例如:file、user、group、host、package、service、cron、exec、yum、repo等。适合整个软件生命周期管理;
1.1、系统运维的三个层面
1.1.1、OS Provision:操作系统安装层
两种不同的状态:
(1)bare metal(在裸机上部署操作系统):
部署工具:pxe, cobbler
(2)virutal machine(在虚拟机上部署操作系统):
部署方式:image file template(映像文件模板)
1.1.2、Configuration:配置层面
工具:
ansible(agentless):无agent的部署工具,适用于节点规模在几十台服务器的时
候;
puppet(master/agent):需要对每一个被管控主机之上部署一个agent才能实现
对主机的管控;agent无需依赖于本地操作系统上的系统
用户的权限,让agent以管理员的身份运行;基于ruby
语言研发;
saltstack(python):属于轻量级的puppet;同时也可以灵活的像ansable一样
工作;基于Python语言研发;
1.1.3、Command and Control:命令化的批量完成
工具:
ansible(playbook)
fabric(fab)
func
...
二、Puppet工作方式

Puppet本身就是一个配置管理库,并联合了一个配置管理系统;事先定义好各种各样的模块,每一个模块可以定义一个类似ansible的角色;随后可以在一台主机之上整合多个模块,从而让一台主机快速完成多种配置,一旦配置完成后将配置完成的状态结果报告给puppet,puppet可以将状态信息保存在database中;
事先要编排好许多模块,然后将模块与主机建立关联,定义主机的目标状态;随后,puppet会每隔一段时间就会检测一下,通知agent主机,检查目标主机是否符合puppet定义的目标状态,如果不符合,就开始编排好任务让agent代表master的指令在本地一步一步执行,并将执行结果报告给master,由master存储于database;
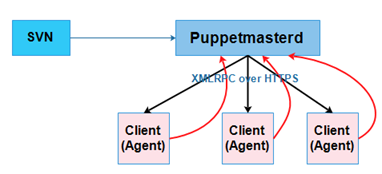
有一个节点叫puppetmasterd;其他节点都称之为client或agent;clinet上面运行agent进程,注意:agent进程每隔30分钟会主动向master请求一次自己目标端口的定义,并且拿到与自己相关的定义以后,在定义之前还要向master报告自己当前的状态;让master来检查是否匹配,如果不匹配就将对应的client的配置发送给client,由client本地完成应用;
对于puppet而言,master和agent之间的通信是基于https来通信的;puppetmasterd将自己的各种API(应用程序编程接口)功能向外输出;client端去调用puppetmasterd的功能来完成二者的互相交互通信,这就是RPC(远程过程调用协议),该RPC为了使在通信双方更加明晰,不至于误解,他们基于XML(可扩展标记语言)标记的方式来完成数据交换;为了避免数据的泄露,我们要基于HTTPS信道来传递数据;
三、Puppet的工作机制
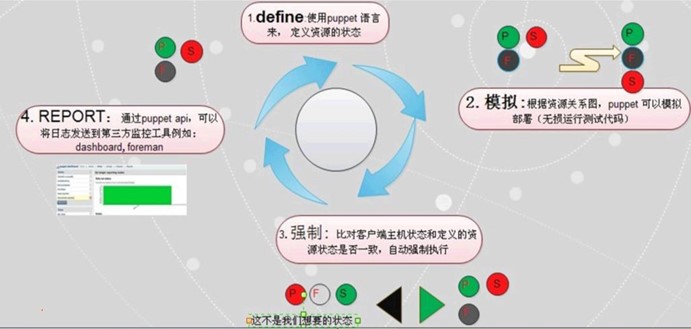
定义
使用puppet语言定义资源目标的状态;当一个主机来请求与自己相关的状态时
puppet会找到与之相对应的主机的定义,将其编译成二进制。
模拟
根据资源关系图,puppet可以模拟部署;
强制
将模拟成功的状态结果在目标主机上真正运行一遍;比对客户端主机状态和定义的
资源状态是否一致,不一致则强制执行;
报告
不管强制执行的结果是否成功还是失败,都会将状态通过puppet API报告给master,
Master将其发送给第三方工具,如mysql、foreman(专业的puppet前端展示工具);
四、Puppet 的三层模型
1、资源抽象层 resource abseraction layer
指puppet将每一个被管控的对象都抽象成资源,例如安装nginx程序包,它
告诉你抽象出来一个程序包,只需要告诉client安装nginx,至于怎么安装client则
不用管,puppet会自行判断对方是什么操作系统,要用什么方式来安装;puppet
实现了对于不同操作系统来调用不同的包管理器来安装程序包的方式;
2、事务层 transactional layer
允许用户定义安装包的依赖关系和通知关系,以触发更新;
3、配置语言层configuration language
用来描述,资源抽象层和事务层所提供给我们的功能;
五、puppet的工作模型
5.1、单机模型介绍
手动应用清单;
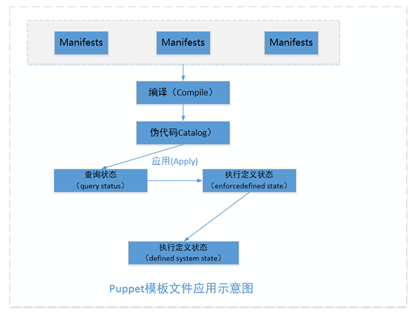
如果将不同的资源清单应用到一个主机上,那么我们要将各资源清单进行编译,编译后的结果称之为catalog(伪二进制格式的代码);编译完成后就发送给目标主机或者是检查本机的应用,第一步是先模拟,做状态查询,看一看与我们在catalog中定义的结果是否一致,对于不一致的地方我们开始在本地应用,执行目标状态;
Puppet有一个特点,就是可以单机应用也可以master/agent模型应用,意思就是说将来我们要想完成对主机的快速配置,在你写成清单以后,puppet在本机管理一台主机都非常高效;
5.2、master/agent介绍
由agent周期性地向Master请求清单并自动应用于本地;
Manifests:资源清单,一个服务一个清单,例如,nginx一个清单,mysql定义一个清单;
下图大体上描述了puppet的master/agent模型是如何工作的;
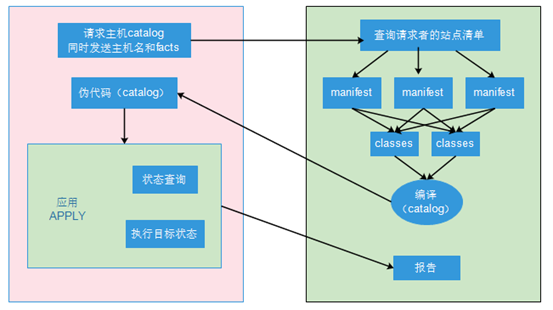
右侧是master,左侧是其中的一个agent,一个agent每隔30分钟向master发送查询请求。因此假如到了一次周期,agent会去请求自己相关的catalog,并且在请求的同时会发送主机名和facts(agent各种各样的状态信息通过一个变量向服务端报告),配置管理系统主要是靠主机名来识别主机角色的。
当master收到请求以后会查询请求者的站点清单;(所谓站点清单其实指的就是一个主机相关的资源清单的列表有哪些;每一个模块都是在一个或一组文件中定义的,因此这就是一个资源清单,里面定义了mariadb程序的的安装、服务的启动、用户的创建等;对于一个主机web servers来讲,他应用的就是webserver 的资源清单和security的资源清单;对于web servers中的某一个主机来讲,我们需要关联上来两个资源清单,webserver和security。而对这一个主机来讲它就叫这个主机的站点清单,也叫主机清单;所以说主机清单是让资源清单能给一个主机产生直接关系的非常重要的接口;一个主机到底应该安装哪些程序包提供哪些资源呢?就是靠站点清单把资源关联到主机上来实现的;)从而把资源清单抽取出来后在master端编译成catalog,编译完成后发送给agent端;所以agent端就获得了catalog,当收到以后在本地开始应用,先做状态查询,再执行目标状态;把执行结果报告给master端;
Yum repolist 查看是否支持epel仓库
对于puppet而言绝大多数的程序包都整合在puppet当中,并且依赖于ruby环境;puppet-server daemon包只是提供了简单的unit file,所以在单机模型中不必要安装puppet-server;只有一个puppet agent就够了;
六、单机模型的具体应用
6.1、安装程序包
CentOS 6.8配置环境:
Puppet官方yum源:
wget http://yum.puppetlabs.com/el/6x/products/x86_64/puppetlabs-release-6-10.noarch.rpm
CentOS6系列阿里云yum源不带puppet安装包,因此需要手动指定puppet官方yum源或者下载puppet安装包;
facter-2.4.4-1.el6.x86_64.rpm puppet-3.8.1-1.el6.noarch.rpm
puppet-server-3.8.1-1.el6.noarch.rpm(master安装) ruby-shadow-1.4.1-13.el6.x86_64.rpm
CentOS 7.2配置环境:
CentOS7以上可直接使用阿里云yum源即可安装puppet;
Yum install puppet-3.8.4-1.el7.noarch.rpm facter-2.4.4-1.el7.x86_64.rpm -y
当为master/agent模型时,还需要安装:puppet-server-3.8.1-1.el6.noarch.rpm
6.2、程序环境
配置文件:/etc/puppet/
puppet.conf 它可以同时为agent server提供配置还可以通过公共配置同时能生
效在agent、server两侧;
主程序:/usr/bin/puppet
在单机模型的环境下,不需要启动服务,只有在puppet master/agent环境下才启
用puppetagent.service服务;
puppet程序命令使用格式:
Usage: puppet <subcommand> [options] <action> [options]
子命令
help Display Puppet help.获取puppet帮助信息
apply Apply Puppet manifests locally 手动应用本地的资源配置清单
describe Display help about resource types显示每一个资源类型的帮助信息
agent The puppet agent daemon运行agent端的守护进程
master The puppet master daemon运行服务端的守护进程
module Creates, installs and searches for modules on the Puppet Forge
用来创建、安装、管理、搜索模块的;
……
'puppet help <subcommand>' for help on a specific subcommand.获取子命令的帮助信息;
'puppet help <subcommand> <action>' for help on a specific subcommand action.获取子
命令的子命令的帮助信息;
6.3、puppet apply
Applies a standalone Puppet manifest to the local system.
手动在本地应用资源清单中的配置
puppet apply [-d|--debug] [-v|--verbose] [-e|--execute] [--noop] <file>
-d:显示调试信息;事无巨细,统统输出;debug
-v:输出详细信息;
-e:真正执行操作;
--noop:不做真正的操作;no opecation
6.4、puppet资源
资源抽象的维度(RAL如何抽象资源的?不同的操作系统的安装方式是不一样的,为了避免用户还得描述整个过程,puppet将资源完全抽象出来,将实现方式和我们要求的目标状态完全分离出来,底层如何实现,puppet给隐藏了,用户只要告诉puppet只要安装程序包就可以了,至于什么样的操作系统该调用什么样的程序包管理器来安装由puppet来自行决定,用户无需参与,所以这整个过程称之为资源的抽象维度;):
通过三个维度来进行抽象:
1、类型:具有类似属性的组件,例如package、service、file;
对每一个资源来讲,类型就是类,给属性赋值就是实例化创建出对
象的过程;
2、将资源的属性或状态与其实现方式分离;
一个资源的底层到底是如何实现的,我们无需关心,由puppet自行
决定;所以puppet将自己的实现过程给隐藏了;
3、我们要想定义一个资源时,仅描述资源的目标状态,也即期望其实现的结果状
态,而不是具体过程;
定义时使用其配置语言,只需要定义资源的目标状态,而不是具体过程。
RAL(资源抽象层)在定义资源时要由"类型"和提供者(provider)共同来决定;
6.5、puppet describe
Prints help about Puppet resource types, providers, and metaparameters.
打印关于资源的类型、供应商、元参数。
元参数:定义依赖关系和通知关系的参数;
puppet describe [-h|--help] [-s|--short] [-p|--providers] [-l|--list] [-m|--meta] [type]
-l:列出所有资源类型;
-s:显示指定类型的简要帮助信息;直接跟类型名称可以获取详细的帮助信息
-m:显示指定类型的元参数,一般与-s一同使用;
资源定义:向资源类型的属性赋值来实现,一个类型可实例化出来n个资源;可称为资源类型实例化;
定义了资源实例的文件即清单,即manifest;在manifest当中定义资源的语法;
定义资源的语法:
type {'title':(定义实例化资源的名称)
attribute1(属性) => value1,
atrribute2 => value2,
……彼此之间要用逗号分隔;
}
Value:可以使字符串、数值、布尔型、数组,甚至还可以是映射;所以,可
以想象成属性就是变量。属性可以有多个;
注意:type必须使用小写字符;title是一个字符串,要用引号引起来;在同一
类型中必须惟一;
6.6、资源引用
那什么时候服务会重启呢?只有在配置文件修改后才会重启;那当配置文件被修改后怎么才能让服务重启呢?通过触发来实现,一旦配置文件被修改,我们就不必要再去启动服务脚本,而是触发做restart;怎么触发呢?也就意味着刚才的restart属性所定义的-s reload操作得需要额外的机制去触发,那要触发得靠他内建的触发机制来实现,这个就要用到元参数了,nginx的元参数机制;而此处还得用到一个概念叫做引用;
比如说,nginx服务要想启动必须先将nginx包安装上,这是前提,这就是一种依赖关系,不能上来就先启动服务,我们先得判断这个包的安装状态是稳定的;同样的,user要属于某一组,那么该组必须要先存在;
如果说某一个service的配置文件发生了改变,它不是要依赖于service而是要通知service说你得要从起一下服务或重载服务,这种叫通知关系;而当只有一种参数实现,另一种参数才能实现的关系称之为依赖关系;而这两种关系都可以通过元参数来定义,此时还得引用别的资源才能实现;
我们要依赖于一个资源或通知一个资源,说白了我们要对另一个资源产生关系的时候就要做资源引用;
6.6.1、资源引用的语法
Type['title']
注意:类型的首字母必须大写;
当我们要表达引用关系的时候,就用到了资源的元参数,也就是资源的特殊属性;
资源的特殊属性:
1、名称变量(name var):
name可省略,此时将由title表示;
2、ensure:
定义资源的目标状态;
3、元参数:metaparameters
6.7、资源之间的两种关系
6.7.1、依赖关系
before:自己被谁所依赖;
示例、mygrp被CentOS所依赖,也就是说,要先创建mygrp再创建CentOS;
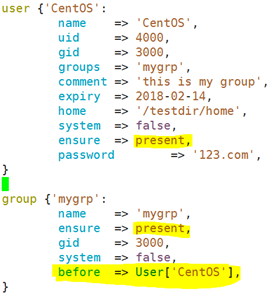
删除组和用户
当需要删除组mygrp的时候,不能直接删除该组,因为当组内有成员时是不允许删除组的,需要先删除该组内的成员,才能删除该组;所以当需要删除组时,成员CentOS要被组mygrp所依赖,也就是要先删除CentOS;
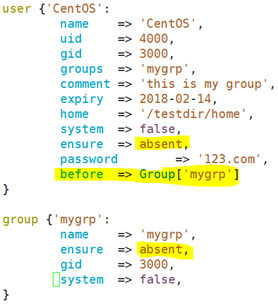
示例二、安装包被启动服务所依赖,也就是说,要先安装程序包才能启动服务;

require:自己依赖于谁;
示例、表示CentOS依赖于,mygrp,
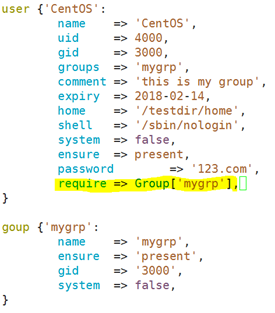
表示CentOS依赖于mygrp这个资源;
通过依赖链来定义依赖关系
示例:表示先执行Package后执行Service;这种表示方式称之为依赖链;

6.7.2、通知关系
通知相关的其它资源进行"刷新"操作;
notify:通知
示例:表示通知,一旦文件发生改变就通知service刷新,也可以触发restart;
1、创建文件来源路径
mkdir -pv /root/manifests/
2、提供httpd的配置文件,放入/root/manifests/目录下;
3、编辑httpd.pp文件;
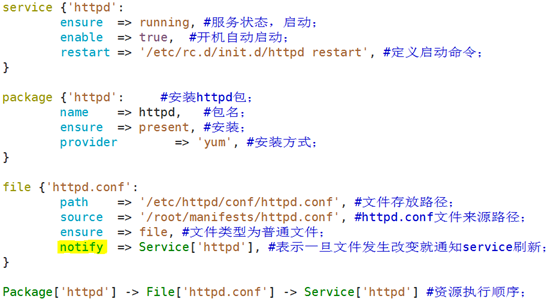
4、执行puppet apply -v --noop httpd.pp测试;没问题后真正执行puppet命令;
5、修改/root/manifests/路径下的httpd.conf文件的默认监听端口;再次执行puppet命令,ss -ntlp查看默认端口是否被修改;
subscribe:订阅;
A通知B,跟B订阅A是一样的效果;A自己发生改变就通知给B,B订阅A表示,B要始终关注A的状态,A要变化B就自动变化;
示例:
表示service资源订阅了该配置文件,所以只要该配置文件发生改变,就会自动触发restart;这个操作对service资源来讲叫refresh刷新;
1、创建文件来源路径
mkdir -pv /root/manifests/
2、提供httpd的配置文件,放入/root/manifests/目录下;
3、编辑httpd.pp文件;
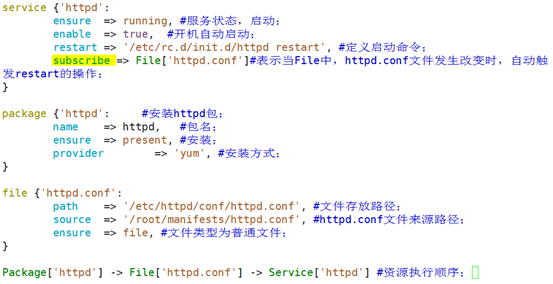
4、执行puppet apply -v --noop httpd.pp测试;没问题后真正执行puppet命令;
5、修改/root/manifests/路径下的httpd.conf文件的默认监听端口;再次执行puppet命令,ss -ntlp查看默认端口是否被修改;
通过"~"波浪线来表示通知;
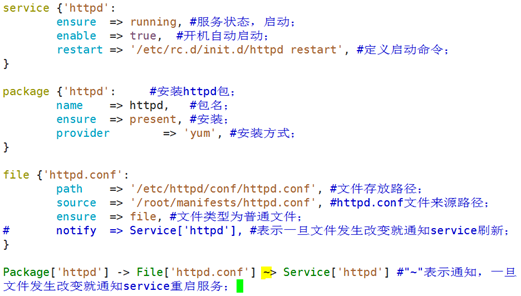
6.8、常用资源类型
6.8.1、group
Puppet describe -s group 查看帮助信息
Manage groups;定义用户组
属性:
name:组名;name可以省略;如果title和name不一样,以name为准;
gid:GID;
system:是否为系统组;true/false;
ensure:目标状态,present/absent;该组到底是创建还是删除;
members:成员用户列表;
示例:
Vim group.pp
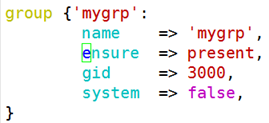
1、先编译,成为catalog(目录),并且要识别当前主机的主机名和系统环境;
在工作中,系统环境有三个版本:
01、开发
02、测试
03、线上生产,production就指生产环境;
如果不指定,则默认都是production;
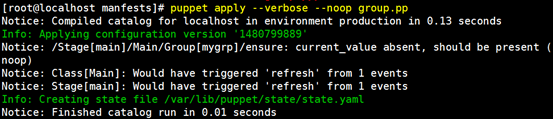
Current_value absent 当前状态是absent;
Should be present (noop):目标状态是present,但是(noop)表示并没有真正执行;
2、创建目标状态文件:create state file /var/lib/puppet/state/state.yaml

"ensure:created "表示真正执行完成;所以该组已经创建完成;

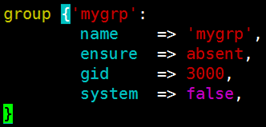
删除组:

6.8.2、user
Manage users.
属性:
name:用户名;
uid: UID;
gid:基于组ID;
groups:附加组,不能包含基本组;
comment:注释;
expiry:过期时间 ;
home:家目录;
shell:默认shell类型;
system:是否为系统用户 ;
ensure:present/absent;目标状态;(存在/缺席)
password:加密后的密码串;
示例:
Vim user.pp

6.8.3、package
Manage packages.
属性:
ensure:
installed/ present/ latest 安装/目前/最新,都表示安装;
absent 缺席的,表示卸载;
name:包名;这个名称可以通过变量来获取;
source:程序包来源,仅对不会自动下载相关程序包的provider有用,例如rpm
或dpkg;
示例:Vim package.pp
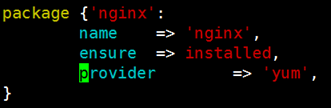
该配置写法要依赖于本地的yum仓库才能安装完成;
或是指定安装包,nginx-1.10.noarch.rpm;

6.8.4、service
Manage running services.管理运行的服务;
属性:
ensure:Whether a service should be running. Valid values are `stopped` (also called
`false`), `running` (also called `true`).启动还是停止;
enable:Whether a service should be enabled to start at boot. Valid values are
`true`,`false`, `manual`.是否开机自动启动,(true、false、手动);
name:服务名称;
path:The search path for finding init scripts. Multiple values should be separated by
colons or provided as an array. 脚本的搜索路径,默认为/etc/init.d/;
hasrestart:该脚本定义的服务有没有restart命令,如果没有,则在需要让服务
启动时,先停止,再启动。
hasstatus:判断该脚本定义的服务有没有status命令,如果没有,则有可能获
取指定的进程;
restart:Specify a *restart* command manually. If left unspecified, the service will
be stopped and then started. 通常用于定义reload操作;
示例:Vim service.pp service对package有依赖关系;
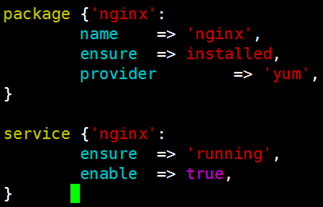
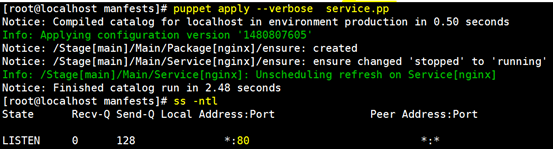
测试:

执行并测试;
手动定义启动命令:
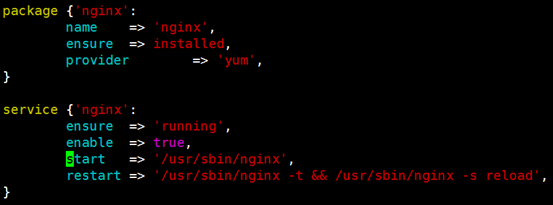
启动状态有所不同;
6.8.5、file
用来实现文件复制、创建等功能的;
Manages files, including their content, ownership, and permissions.
管理文件,包括内容、所有权和权限。
ensure:Whether the file should exist, and if so what kind of file it should be. Possible values are `present`, `absent`, `file`, `directory`, and `link`.
文件是否应该存在,如果是这样的文件应该是什么样的。可能的值是"present","absent","文件","目录"和"链接"。
file:类型为普通文件,其内容由content属性生成或复制由source属性指向的文件路径来创建;
link:类型为符号链接文件,必须由target属性指明其链接的目标文件;
directory:类型为目录,可通过source指向的路径复制生成,recurse属性指明是否递归复制;
path:文件路径;
source:源文件;
content:文件内容;
target:符号链接的目标文件;
owner:属主
group:属组
mode:权限;
atime/ctime/mtime:时间戳;
示例1

示例2
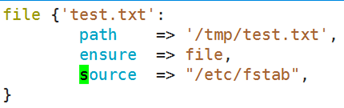
示例3

当执行这条指令时,会在/tmp下生成一个关于test.txt的软链接;
示例4 
当执行这条指令的时候,会在/tmp生成一个test.dir的目录,然后将/etc/yum.repos.d/目录下的所有内容复制到test.dir目录下;
6.8.6、exec
Executes external commands. Any command in an `exec` resource **must** be able to run multiple times without causing harm --- that is, it must be *idempotent*.
用来执行外部命令,并且要确保这个命令是幂等的;
**command** (*namevar*名称变量):要运行的命令;当exec直接写成命令时,command是可以省略的;
cwd:The directory from which to run the command.运行命令的目录
**creates**:文件路径,仅此路径表示的文件不存在时,command方才执行;表示创建;在命令运行之前先去找creates所指向的文件路径,只有这个文件不存在时,才会被执行;这是一种确保幂等的方法;
当不加creates时,第二次执行该模板时就会报错;
user/group:运行命令的用户身份;
path:The search path used for command execution. Commands must be fully qualified if no path is specified.用于命令执行的搜索路径。如果没有指定路径,命令必须使用决对路径;
onlyif:此属性指定一个命令,此命令正常(退出码为0)运行时,当前command才会运行;指在什么状态下执行
只有onlyif后面的这个命令成功执行了,exec所指向的命令才会运行;
unless:此属性指定一个命令,此命令非正常(退出码为非0)运行时,当前command才会运行;表示如果----不---。跟onlyif相反;

refresh:重新执行当前command的替代命令;如果有其他资源调用exec的时候,exec会执行好几次,加上refresh后就只会执行一次了,refresh作用就是不管有通知没通知,有多少次通知,都只执行一次。
refreshonly:仅接收到订阅的资源的通知时方才运行;仅在其他资源被改变时,当前资源才被触发;否则默认情况下不会被执行; 如果没有refreshonly时,即使没有事件通知它,exec也会执行;如果加上refreshonly时,exec仅在其他资源用notify或subscribe事件通知时才会执行。refreshonly作用是让exec只在通知时执行,如果被通知多次就执行多次。
6.8.7、cron
定义计划任务
Puppet describe cron
Installs and manages cron jobs. Every cron resource created by Puppet requires a command and at least one periodic attribute (hour, minute, month, monthday, weekday, or special).
command:要执行的任务;
ensure:present/absent;
hour:
minute:
monthday:
month:
weekday:
user:添加在哪个用户之上;
name:cron job的名称;
示例:

crontab -l验证;

6.8.8、notify
:通知Sends an arbitrary message to the agent run-time log.
属性:
message:信息内容
name:信息名称;

七、puppet variable
7.1、基本格式
Puppet的变量名称必须以"$"开头,赋值操作符为"=";
任何正常数据类型(非正则)的值都可以赋予puppet中的变量,如字符串、数值、布尔值、数组、hash以及特殊的undef值(即变量未被赋值);
Puppet的每个变量都有两个名字,简短名称和长格式完全限定名称(FQN),完全限定名称的格式为"$scope::variable"。
$variable_name=value
7.2、数据类型
Puppet语言支持多种数据类型以用于变量和属性的值,以及函数的参数;
7.2.1、字符型
非结构化的文本字符串,引号可有可无;但单引号为强引用,双引号为弱引用;
7.2.2、数值型
可以为整数或浮点数,不过,puppet只有在数值上下文才把数值当数值型对待,其他情况下一律以字符型处理;默认均识别为字符串,仅在数值上下文才以数值对待;
7.2.3、数组
数组值为中括号"[]"中的以逗号分隔的元素列表;最后一个元素后面可以有逗号;数组中的元素可以为任意可用数据类型,包括hash或其他数组;数组索引为从0开始的整数,也可以使用负数索引;
7.2.4、布尔型值
true, false;一定不能加引号;if语句的测试条件和比较表达书都会返回布尔型值;另外其他数据类型也可自动转换为布尔型,如空字符串为false等;
7.2.5、hash
表示关联数组,不使用0、1、2等数值型索引,而使用自定义的字符串索引;{}中以逗号分隔k/v数据列表; 键为字符型,值为任意puppet支持的类型;{ 'mon' => 'Monday', 'tue' => 'Tuesday', };即为键/值数据类型,键和值之间使用"=>"分隔,键值对定义在"{}"中,彼此间用逗号分隔;其键为字符型数据,而值可以为puppet支持的任意数据类型;访问hash类型的数据元素要使用"键"当做索引进行;
7.2.6、undef
未赋值型 ,从未被声明的变量的值类型即为undef;也可手动为某变量赋予undef值,即直接使用不加引号的undef字符串;
7.2.7、正则表达式
正则表达式只是一种特殊的数据类型,只能用在特殊场景当中而不能赋值给变量;
(?<ENABLED OPTION>:<PATTERN>)
(?-<DISABLED OPTION>:<PATTERN>)
使用"?"来引导"<>"表示必给的,"enabled option"表示要启用的选项
OPTIONS:
i:忽略字符大小写;-i 不忽略字符大小写
m:把"."当换行符; -m表示不把"."当换行符用;
x:忽略<PATTERN>中的空白字符 -x表示不忽略
注意:不能赋值给变量 ,仅能用在接受=~或!~操作符的位置;
7.3、puppet的变量类型
7.3.1、facts
puppet使用了一个称作facter的工具来收集系统信息,规范化之后将其放进一系列变量中并传递给puppet;
fact的各变量是top scope的变量,这意味着,可以在各manifest中直接通过$(fact name)访问所需的fact变量;
facter -p 获取本地所有可用的内建facts变量;
例如:操作系统类型,版本号;等各种系统信息;
architecture => x86_64 操作系统架构
augeasversion => 1.0.0 版本号
kernel => Linux 内核名称
kernelmajversion => 2.6 内核版本
osfamily => RedHat 操作系统属于什么系列
7.3.2、内建变量
master端变量
$servername 服务器名称
$serverip 服务器ip
$serverversion 服务器版本
agent端变量
$environment 保存当前agent端所属的环境类型
开发 测试 线上
$clientcert 表示客户端的证书
$clientversion 客户端的版本号
parser变量
$module_name 当前应用的模块名称
7.3.3、用户自定义变量
7.4、变量的作用域
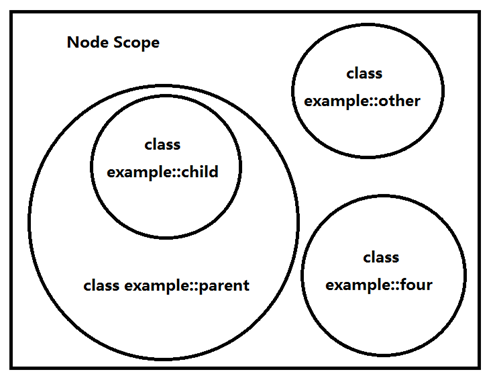
称为Scope;Scope是一个特定的代码区域,用于同程序中的其他代码隔离开来;
在puppet中,scope可用于限定变量以及资源默认属性的作用范围,但不能用于限定资源名称以及资源引用的生效范围;
当我们在定义puppet的many fasts的时候,遇到更为复杂的格式时我们是可以使用类的,而且类还可以被组织成模块,类主要从属于模块。Puppet中有类,类还有子类,子类可以直接继承类的变量,但是同等级的子类之间的变量不可以继承,在puppet级别定义一个变量,各种类也是可以继承的;所以变量是有其作用域的;
top scope:全局作用域 $::var_name
node scope 节点级别的作用域,相当于整个agent领域,也就是说puppet上所定义的模块最终要被应用到某个或某些节点上去的;也就是编译好的catalog的生效范围是应用的所在主机节点;
class scope 三级作用域,类,类还可以有子类;
在top scope中的变量在所有node scope中都可以用,所有类也都可以用;在一个node scope上定义的变量,只有属于该node节点的类可以引用,其他node节点就不可以引用;
如果要访问非当前scope中的变量,则需要通过完全限制名称进行,如:
$vhostdir = $apache::parames::vhostdir
需要注意的是,top scope的名称为空,因此,如若要引用其变量,则需要使用类似"$::osfamily"的方式进行;
7.5、Operators 操作符
==(equality)
!=(non-equality)
< (less than)
> (greater than)
<= (less than or equal to)
>= (greater than or equal to)
=~ (regex match)左侧的字符串能够被右侧的模式所匹配;
!~ (regex non-match) 正则表达式不匹配
In 表示列表表达式判断机制 例如A这个变量的值in后面跟一个列表,就表示A的值在这个列表当中属于其某一个元素;
7.6、Boolean operators 布尔运算符
And 当有多个表达式时,可以做逻辑操作;与或非;
Or
! (not)
7.7、Arithmetic operators 算数运算符
+ (addition)
- (subtraction)
/ (division)
* (multiplication)
<< (left shift)
>> (right shift)
八、puppet流程控制语句
8.1、语句结构
8.1.1、单分支
if CONDITION {
statement
...........
}
8.1.2、双分支
if CONDITION {
statement
............
}
8.1.3、多分支
if CONDITION {
statement
................
}
elsif CONDITION {
Statement
..............
}
else {
Statement
.................
}
8.2、Conditions 条件
The condition(s) of an "if" statement may be any fragment of puppet code that resolves to a boolean value;
Variables condition可以是一个变量;如果这个变量是个字符串,非空就为真,空则为假,如果是数值,0则为假,非0则为真;如果是一个数组,有一个元素就为真,没有任何元素则为假;
Expressions,including arbitrarily nested and or expressions;也可以是一个表达式,
Functions that return values,支持函数,但是函数得有返回值;空串则为假,非空串则为真;
8.3、if语句
8.3.1、语句结构
if CONDITION {
...
} else {
...
}
8.3.2、CONDITION的给定方式
(1) 变量
(2) 比较表达式
(3) 有返回值的函数
8.3.3、示例

if $osfamily =~ /(?i-mx:(centos|redhat|fedora))/ { 如果这个变量的值能够被右侧的模式所匹配,"?"号为起始字符,"i"表示忽略字符大小写,"-mx"表示不把点号当换行符,不(centos|redhat|fedora)忽略模式中的空白字符;意思就是说:如果操作系统类型能够被centos或redhat或fedora能匹配,那么我们就把$pkgname这个变量的值设定为httpd;
否则,如果$operatingsystem变量能够被debian或bubntu所匹配,那么就将$pkgname的值设定为apache2;
剩余其他的,都赋值给httpd;
}
8.4、case语句
8.4.1、语句结构
case CONTROL_EXPRESSION {
case1: { ... }
case2: { ... }
case3: { ... }
...
default: { ... }否则定义默认分支;
}
语句含义:如果control-expression(控制表达式)的值为第一种case;就执行第一个分支,依次类推;如果所有case都不匹配,则执行default分支;
8.4.2、CONTROL_EXPRESSION(控制表达式)
可以有多重表示形式;
(1) 变量
(2) 表达式
(3) 有返回值的函数
8.4.3、各case的给定方式
(1) 直接字串;
(2) 变量
(3) 有返回值的函数
(4) 正则表达式模式;
(5) default
8.4.3、示例

8.5、selector语句
8.5.1、selector的语句结构
CONTROL_VARIABLE ? {
case1 => value1,直接返回一个值,不执行任何操作;
case2 => value2,
...
default => valueN,
}
判断control_variable变量的值符合哪个分支就执行哪个分支的值;然后直接返回一个值,并不执行任何操作;
8.5.2、CONTROL_VARIABLE的给定方法
(1) 变量
(2) 有返回值的函数
8.5.3、各case的给定方式
(1) 直接字串;
(2) 变量
(3) 有返回值的函数
(4) 正则表达式模式;
(5) default
注意:不能使用列表格式;但可以是其它的selecor;
8.5.4、示例

九、puppet的类
9.1、类的定义
puppet中命名的代码模块,常用于定义一组通用目标的资源,可在puppet全局调用;类可以被继承,也可以包含子类;
9.2、语法格式
class NAME { #class关键字,取一个类名;
...puppet code...
}
class NAME(parameter1, parameter2) { #类向类传递参数;
...puppet code...
}
各种puppet代码,如条件判断、select、case语句等,各种各样的资源申明都可以放在同一个类当中,将来一调用这个类,就表示这个代码被执行;
类也可以向类传递参数;然后在puppet代码中调用参数,相当于能接受参数的函数;
9.3、代码调用方式
类的代码只有声明后才会执行,声明就是调用方式;
两种调用方式:
(1) include CLASS_NAME1, CLASS_NAME2, ...
使用include加上类名,表示调用一个类;所以调用类的地方,则是类代码执行的
地方;不需要传递参数时使用;
(2) class{'CLASS_NAME':
attribute => value, #属性
}
也可以像声明一个资源一样,调用类;
9.4、示例
示例1、


Puppet apply help
-e 可以直接去写要执行的代码;
Puppet apply -v -e "include apache2" --noop class1.pp 表示执行include apache2这个代码;执行完成后会报错,是因为,这个类真正要基于这种方式来定义时必须按固定格式放在指定的模块路径下才能够调用;
示例2、

9.3、类继承的方式
类是可以被继承的,一个类如果定义了多个资源以后,但还是资源不够用,那么可以在继承这个类的基础之上再额外加一些资源进来,所以,当我们拥有了父类所有的资源之上,可以新增或修改部分代码,这就是类继承;
9.3.1、语法格式
class SUB_CLASS_NAME inherits PARENT_CLASS_NAME {
...puppet code...
}
声明一个子类SUB_NAME去inherits(继承)一个基类,也叫父类;
示例:
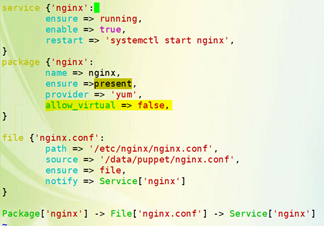
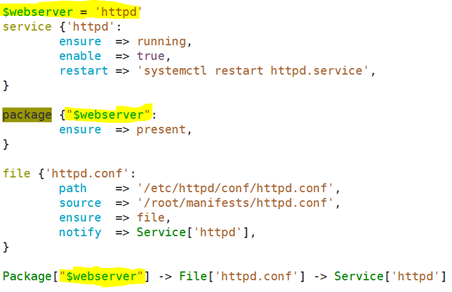
class nginx { 定义基类
package{'nginx':
ensure => installed,
}
service{'nginx':
ensure => running,
enable => true,
restart => '/usr/sbin/nginx -s reload',
}
}
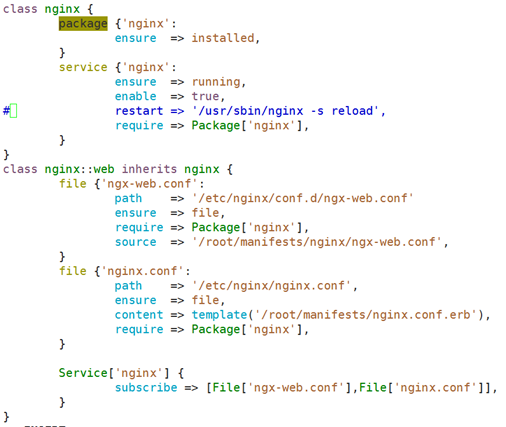
class nginx::web inherits nginx { 这种命名子类名称的方式明确能看出来当我们调用这一类的时候就知道nginx基类的子类是web,这是完全限定格式的名称;
Service['nginx'] {
subscribe => File['ngx-web.conf'],
}
file{'ngx-web.conf':
path => '/etc/nginx/conf.d/ngx-web.conf',
ensure => file,
source => '/root/manifests/ngx-web.conf',
}
}
class nginx::proxy inherits nginx { 第二个子类 做反代服务器使用
Service['nginx'] { 在父类当中的service又重新做了一次赋值;这能够实现将父类中的功能做重新的增强;在原有的属性ensure、enable、restart的基础上又多加了一个subcribe,这表示将原有的父类中的service[nginx]这个资源新增一个属性,订阅File['ngx-proxy.conf'],而订阅的这个资源就是在自己的子类当中额外定义的;所以我们既能继承父类的属性,也可以新增一些属性做为扩展;如果将"+>"换成"=>"表示继承覆盖;
subscribe +> File['ngx-proxy.conf'],
}
file{'ngx-proxy.conf':
path => '/etc/nginx/conf.d/ngx-proxy.conf',
ensure => file,
source => '/root/manifests/ngx-proxy.conf',
}
}
include nginx::proxy
十、puppet模板
所谓模板,就是基于某种内建的比如在html中内嵌的php代码或jsp代码一样格式的代码,只有那段代码才会被执行,剩下的内容都会被原封不动的输出;所以所谓的模板,他是一种编程语言,这种编程语言可以内嵌在一个文本文件中,然后我的模板引擎在处理这个模板中的内容时,如果是文本信息就原样输出,如果是代码标签内的代码,他要把这个代码执行以后将结果放置在代码所在的位置;
erb:模板语言,embedded ruby;
puppet兼容的erb语法:
https://docs.puppet.com/puppet/latest/reference/lang_template_erb.html
10.1、语法格式
利用模板来生成文件内容
file{'title':
ensure => file,
content => template('/PATH/TO/ERB_FILE'), 指明模板文件路径
}
指明模板文件路径,并将该模板文件做简单处理,处理的方式就是文本信息原样输出,代码标签内的内容做执行,将执行结果替换在代码所执行的位置;
template:puppet内建函数;
文本文件中内嵌变量替换机制:
<%= @VARIABLE_NAME %>
在erb语言当中,我们要替换或调用一个变量值,用@+变量名的方式;
示例:
class nginx {
package{'nginx':
ensure => installed,
}
service{'nginx':
ensure => running,
enable => true,
require => Package['nginx'],
}
}
class nginx::web inherits nginx {
file{'ngx-web.conf':
path => '/etc/nginx/conf.d/ngx-web.conf',
ensure => file,
require => Package['nginx'],
source => '/root/manifests/nginx/ngx-web.conf',
}
file{'nginx.conf':
path => '/etc/nginx/nginx.conf',
ensure => file,
content => template('/root/manifests/nginx.conf.erb'),
require => Package['nginx'],
}
Service['nginx'] {
subscribe => [ File['ngx-web.conf'], File['nginx.conf'] ],
}
}
include nginx::web
erb:模板语言,embedded ruby;
puppet兼容erb语法;
官方站点:www.docs.puppet.com/
file {'title':
ensure => file,
content => template('/PATH/TO/ERB_FILE'),
}
使用puppet内建的函数template,指明模板文件的路径;对该模板文件做一个简单的处理,处理方式就是,文本信息原样输出,代码标签内的内容做执行;将执行结果替换在代码所在位置;没有结果则直接结束;
10.2、文本文件中内嵌变量替换机制
<%=@VARIABLE_NAME %>
在erb当中我们要调用或替换一个变量的值,得使用@加变量名的方式
示例1:
1、定义puppet执行文件;vim temp.pp

- 在/root/manifests路径下创建模板文件;
vim test.erb

- 执行puppet apply -v temp.pp,然后去/tmp/template.txt文件中验证;
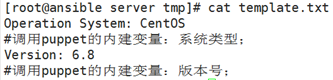
示例2:为nginx生成配置文件,并且配置文件中process的值是其当前主机cpu的核心数;
1、编辑puppet的可执行文件,vim nginx01.pp
- 生成nginx的模板文件;
cp /etc/nginx/nginx.conf /root/manifests/nginx.conf.erb
vim nginx.conf.erb
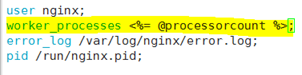
将worker_precesses这一项改为:worker_process <%= @processorcount %>;
3、执行puppet apply -v --noop nginx01.pp,再查看配置文件看worker_processes 进程数是否修改;
puppet模块:
模块就是一个按约定的、预定义的结构存放了多个文件或子目录的目录,目录里的这些文件或子目录必须遵循一定格式的命名规范;
puppet会在配置的路径下查找所需要的模块;
MODULES_NAME:
manifests/
init.pp
files/
templates/
lib/
spec/
tests/
模块名只能以小写字母开头,可以包含小写字母、数字和下划线;但不能使用"main"和"settings";
manifests/ 存放清单文件
init.pp:必须一个类定义,类名称必须与模块名称相同;
files/:静态文件;
puppet URL:
puppet:///modules(固定格式)/MODULE_NAME/FILE_NAME
不需要带files/这么个路径,会自己到files目录下找;
templates/:存放模板文件
tempate('MOD_NAME/TEMPLATE_FILE_NAME')
lib/:插件目录,常用于存储自定义的facts以及自定义类型;
spec/:类似于tests目录,存储lib/目录下插件的使用帮助和范例;
tests/:当前模块的使用帮助或使用范例文件;
mariadb模块中的清单文件示例:
class mariadb($datadir='/var/lib/mysql') { 指明数据目录
package{'mariadb-server':
ensure => installed,
}
file{"$datadir": 指明datadir目录
ensure => directory,
owner => mysql,
group => mysql,
require => [ Package['mariadb-server'], Exec['createdir'], ],
}
exec{'createdir':
command => "mkdir -pv $datadir",
require => Package['mariadb-server'],
path => '/bin:/sbin:/usr/bin:/usr/sbin',
}
file{'my.cnf':
path => '/etc/my.cnf',
content => template('mariadb/my.cnf.erb'),
require => Package['mariadb-server'],
notify => Service['mariadb'],
}
service{'mariadb':
ensure => running,
enable => true,
require => [ Exec['createdir'], File["$datadir"], ],
}
}
puppet help module
ACTIONS:
build Build a module release package.
changes Show modified files of an installed module.
generate Generate boilerplate for a new module.
install Install a module from the Puppet Forge or a release archive.
list List installed modules
search Search the Puppet Forge for a module. 搜索模块,去哪搜索呢?在puppet官方站点上有一个puppet forge的站点,全球各地的puppet爱好者上传的各种模块,我们可以通过关键字来搜索,如:puppet module search nginx,所有在模块名称中带nignx字样的都会列出来;前提是要能上互联网;搜索出来后,找到自己想要的就可以直接puppet install,安装该模块;
uninstall Uninstall a puppet module.
upgrade Upgrade a puppet module.
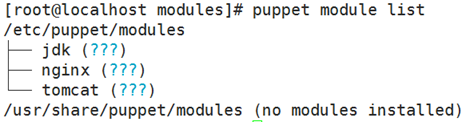
puppet module list 列出所有模块

固定格式创建init.pp文件;
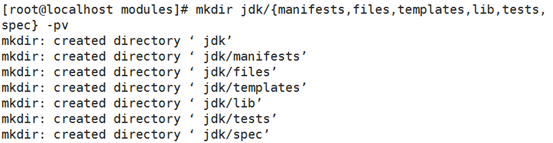
1、创建目录:
mkdir -pv /etc/puppet/modules/mysqld/{manifests,files,templates,lib,tests,spec}
- 创建init.pp文件
vim /etc/puppet/modules/mysqld/manifests/init.pp

然后用命令puppet module list 查看会多出一个模块;如果在mysqld上使用固定语法加一个注释,会将括号中的问号显示为注释信息;
然后就可以代码调用了:puppet apply --verbose --noop -e 'include mysqld' ,甚至可以不用写清单文件,因为我们调用mysqld这个类,puppet会自动去到模块目录寻找某一个模块下的类,所以后面连清单文件名都可以不用写他会自动去调用/etc/puppet/modules目录下某一个模块中的叫做mysqld的类;
示例一:
1、创建目录:
mkdir -pv /etc/puppet/modules/mariadb/{manifests,files,templates,tests,spec}
- 编辑清单
cd /etc/puppet/moules/mariadb/manifests/
vim init.pp

3、创建erb文件
cd /etc/puppet/modules/mariadb/templates
cp /etc/my.cnf my.cnf.erb
vim my.cnf.erb
修改数据目录:datadir=<%= @mysqldatadir %>
- puppet module list 验证
- 执行调用;
puppet apply -v --debug --noop -e "include mariadb"
或者:
mkdir /data

puppet apply -v --noop --debug -e "class {'mariadb': mysqldatadir => '/data/mydata'}" 直接传递参数,更改配置文件的路径;
这时真正执行后,服务启动失败,但是模块调用是成功的,可以手动启动,不必在意小细节;可能是puppet调用systemctl start mariadb命令有问题,需要exec手动执行一次;对于nginx来讲应该没问题;
实践作业:
开发模块:
memcached
nginx(反代动态请求至httpd,work_process的值随主机CPU数量而变化)
jdk(输出JAVA_HOME环境变量)
tomcat
mariadb
httpd(反代请求至tomcat,ajp连接器;mpm允许用户通过参数指定)
puppet module list
获取或设定puppet的配置参数
puppet help config

print 列出所有配置参数或指定的配置参数
set 设定某一个指定的参数的值
puppet config print 显示puppet自己的默认配置项
eg:puppet config set modulepath= 修改modulepath的默认路径
eg:puppet config print modulepath 只显示指定参数modulepath的值
master/agent:agent每隔30分钟到master端请求与自己相关的catalog;在此之前要先报告自己的hostname和facts
vim templates/init.pp
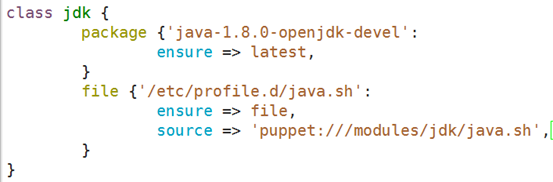
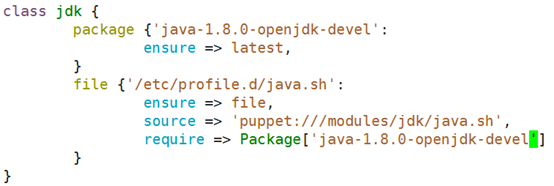
Vim jdk/files/java.sh

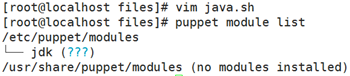
puppet apply --verbose --noop --debug -e 'include jdk'

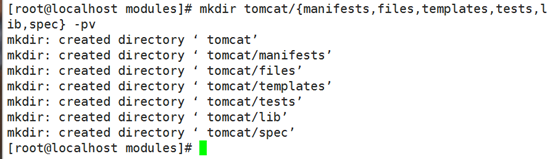
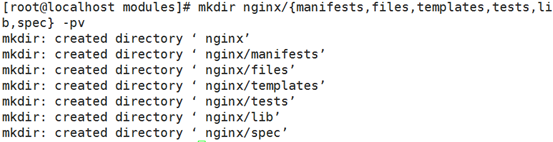
cd tomcat/manifests/
vim init.pp

puppet apply --verbose --noop --debug -e 'include tomcat'

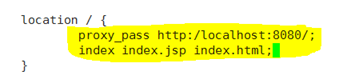
nginx反代用户请求至tomcat
cp /etc/nginx/nginx.conf /etc/puppet/modules/nginx/templates/nginx.conf.erb
vim nginx.conf.erb
vim nginx/manifests/init.pp

puppet apply --verbose --debug --noop -e 'include nginx::proxy'

master/agent模型
puppet识别各客户端,是靠主机名来识别的,master与agent之间的通信是基于https的xmlrpc来实现的,那也就意味着他们每一个彼此之间在通信之前为了确保信息不被窃取,为了避免这样的问题,任何一个想从master端获取配置的客户端主机都得被认证,双向基于CA来认证,也就是说客户端要验证服务端的身份,同样服务端也要验证客户端的身份;
为了能够基于CA的方式通信,首先master端首先是一台CA服务器。因此,每一个agent端在连接master端的时候,agent端会自动生成一个持有者的名称是当前主机主机名的证书颁发请求,并且能自动将请求发给所指定的master端;master收到一看,这是个证书签署请求,因此将该申请转给CA服务器;那么,证书是否要签,这取决于管理员;如果管理员能确保你的网络没有外来主机来申请证书,也可以让CA自动签署;
如果认证这关通过了,在通过master/agent模型的时候,也就意味这master端要启动一个daemon(守护进程),监听在某个套接字上;同时,agent端要每隔30分钟周期性的启动一次,必要的情况下agent也要监听在某个套接字上;
在部署master/agent模型时,master端将自己自动初始化成一个CA,对于agent端而言,第一次启动之前要编辑配置文件,告诉agent谁是server,因此在agent第一次启动时它会向server发起一个证书签署请求,所有生成的过程都是自动进行的;由于其证书主体的名字是当前主机的主机名,这时候master端必须要能够解析客户端主机名,并且解析结果还要跟IP地址相对应,这也就意味着,在生产环境中,要想使用puppet的master/agent模型,得有自己本地的DNS服务器,并且对每一个agent主机的主机名称解析都得做到位;
安装配置master
puppet-server-VERSION.ARCH.rpm
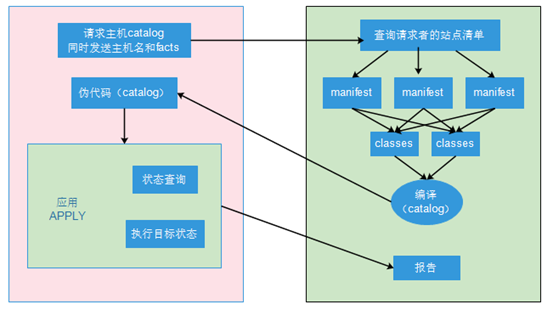
agent端向master端发送自己的主机名和facts,master端要查询请求者的站点清单;在master端有许多的模块定义,但是哪个模块是应用在第一台主机上?哪个模块是应用在第二台主机上?这就需要站点清单;在master主机上有一个目录,在这个目录当中有许许多多的文件,也可以只有一个,在这个文件当中明确定义好每一个node它应该执行的代码有哪些;这些代码通常就是include一个类,例如:node w1{include tomcat、include nginx};node w2{include mariadb-server};所以当第一台主机请求时,就会安装tomcat、nginx;第二台主机请求时,就会安装mariadb-server;所以站点清单就是为了指明哪个节点调用哪个模块,应用在该节点的主机上;
那么站点清单放置在何处呢?这个安装puppet-server后会自动生成;
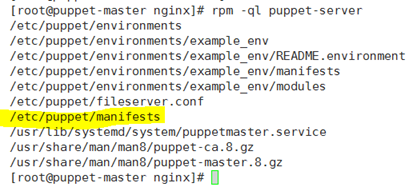
站点清单目录;
puppetmaster.service 是作为daemon来运行的;
master在第一次启动时是要先初始化的,所谓初始化就是要master先建立好一个CA,给CA一个自签证书,并且给当前server一个自签证书,但是这些步骤puppet都能自行完成,等这些都完成之后开始监听在套接字上,等待客户端请求;
puppet help master
puppet master命令就是用来启动daemon守护进程的;
puppet master [-D|--daemonize|--no-daemonize] [-d|--debug] [-h|--help]
[-l|--logdest syslog|<FILE>|console] [-v|--verbose] [-V|--version]
[--compile <NODE-NAME>]
--daemonize 表示工作在后台
--no-daemonize 表示工作在前台
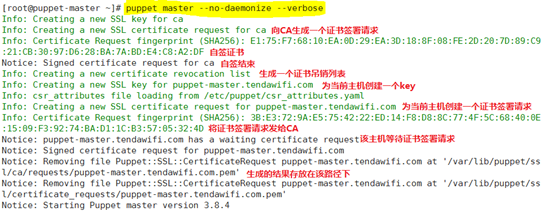
master运行之后,监听在8140端口上;

正常启动时:systemctl start puppetmaster.service
puppet的配置文件路径:/etc/puppet/puppet.conf
该配置文件依然是main和agent,没有什么别的配置,所有的都是默认配置;我们可以使用puppet master --genconfig命令,利用已有的配置文件来生成一个puppet完整的配置文件;我们可把这些完整的配置信息保存在配置文件当中,但是如果不打算修改参数的值,我们可以不用动,保持默认即可;
我们在生成完整的配置文件的时候千万不能删除之前的配置文件;因为这个是根据已有的配置文件才能生成,我们可以利用输出重定向的方式写入配置文件中,只适用于master端;
安装配置agent:
对于agent端而言,这事就简单多了,我们不需要安装server包,其他内容跟此前的apply是一样的,只不过此前的apply是手动运行的,而在agent端运行,是要运行一个守护进程,指向server是谁,这事就完成了;
创建站点清单文件
路径:/etc/puppet/manifests目录下;站点清单的名字必须叫site.pp;

修改master端的hosts文件,将agent端的IP地址和主机名添加进去;

在agent端安装puppet-3.8.4-1.el7.noarch.rpm facter-2.4.4-1.el7.x86_64.rpm包;
安装完成后会生成一个puppetagent.service的守护进程;

puppet help agent
puppet agent [--certname <NAME>] [-D|--daemonize|--no-daemonize]
[-d|--debug] [--detailed-exitcodes] [--digest <DIGEST>] [--disable [MESSAGE]] [--enable]
[--fingerprint] [-h|--help] [-l|--logdest syslog|eventlog|<FILE>|console]
[--masterport <PORT>] [--no-client] [--noop] [-o|--onetime] [-t|--test]
[-v|--verbose] [-V|--version] [-w|--waitforcert <SECONDS>]
-t|--test: 只是做测试不真正运行
--server 指定master
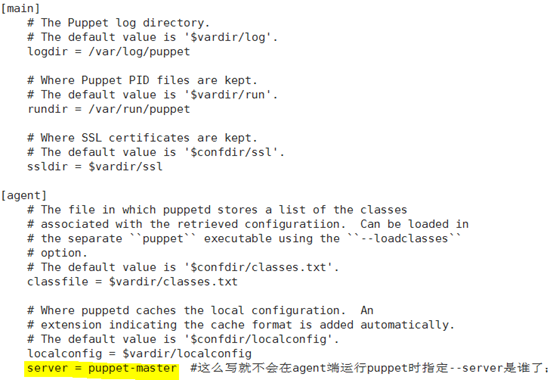
初始化:puppet agent --no


这时候请求已经发给server端了;
master端
puppet help
ca Local Puppet Certificate Authority management.
用来管理本地CA机构
cert Manage certificates and requests
master端管理agent端的请求及证书
certificate Provide access to the CA for certificate management.
用来认证master能够管理的CA的证书;
puppet help cert
puppet cert <action> [-h|--help] [-V|--version] [-d|--debug] [-v|--verbose]
[--digest <digest>] [<host>]
<action>
list List outstanding certificate requests. 列出证书
--all 列出所有证书请求,包括签和未签的;

sign sign an outstanding certificate request 签署证书
--all 将所有待签的证书都签了;
revoke Revoke the certificate of a client; 吊销客户端的证书
clean Revoke a host's certificate (if applicable) and remove all files related to that
host from puppet cert's storage. 在服务端删除此前给某一个客户端签署过
的证书;这时候客户端是要重新发请求;
--all 删除所有证书

这个地方很奇怪,在给agent签署证书的时候,用agent的主机名"agent"不可以;但是用puppet自动分配的主机名"agent.tendawifi.com"就可以签署成功;

主机名命名
master/agent模型要基于https通信,其证书中的主体为主机名,所以主机名要能够基于内部专用的DNS服务进行解析;我们的主机有可能随时上下线,当一台主机上线时,很有可能基于各种各样的方式都能够保证这个主机能够被管理,那我们可以把配置管理系统和监控系统联合起来使用;例如:zabbix能够实现自动发现,自动发现以后可以出发一些脚本,这个脚本可以调用DNS的API接口,想DNS的配置文件注入新的主机名和IP地址进去,然后出发DNS端重载配置文件;或者是DNS服务把它的解析记录放在SQL数据库当中去,基于SQL的接口直接往里注入相关的资源记录;在DNS中bind的资源记录是放在一个文本文件中的,大家可以想象一下,当这个bind文件变得非常庞大而且更新非常频繁时怎么办?这个文本文件是在DNS启动时直接被装入内存中服务的,性能非常好;但是一旦更改,就得重载DNS服务,其重载过程是将所有的记录做成哈希格式以后装入内存的,如果有上万条记录,那这个时候为了能够快速修改立即生效,我们可以实现让DNS查询一个资源记录的解析的记录值时通过查mysql数据库或MongDB来实现,DNS中bind默认就支持把数据放在mysql当中;这时候我们可以写一个脚本,一旦一个主机上线了,zabbix监控到了,让zabbix触发该脚本,想mysql中插入一条记录就可以了;
还有一种机制,虽然不是特别安全,但是能解决问题,叫DDNS,dynamic DNS,DDNS的工作逻辑是是什么呢?就是让DNS服务器bind与DHCP服务器联动,DHCP在获得一个客户端请求的时候,它就能得到这个主机的主机名,并给其分配一个地址,然后DHCP可以把这个结果发给DNS服务器,去触发DNS服务器更新自己的资源记录,但是这有一个很大的风险,万一有一个主机的主机名是你的主栈名称,没准你自己对外的DNS服务就被更新成这台主机的IP地址。所以,DDNS必须要设置强有力的安全认证机制,否则会给别人有可乘之机;
站点清单
我们的master端要想能够为agent端提供专用配置,我们靠的就是站点清单;
/etc/puppet/manifests/site.pp
node 'HOSTNAME' {
...puppet code.....
}
在大多数情况下我们都不会在站点清单中写具体的详细代码,而是调用模块模块中已经定义好的类;
大家可以想象一下,我们同一类主机通常需要执行的代码都一样,比如现在就有10个web服务器或10个tomcat主机,大体上这10台主机安装的程序包和启动的服务都是一样的,这时候我们如何定义这一堆主机呢?我们可以通过"node /PATTERN/"来匹配主机名,意思为:"能够被这个模式所匹配到的主机的主机名都能适用这个node"。所以客户端请求时报告自己的主机名,master就会自上而下的检查,如果能够被这个模式所匹配,就适用相应的node;
node /PATTERN/ {
...puppet code...
}
节点也可以被继承:
当然也可以有第三种方式,节点跟类一样也可以被继承,在我们内部局域网当中几乎每一个主机按照规模化来理解都有可能是分布式的,那么有可能它们都要用到时间服务的相关定义,那么每一个节点点都要用一个include,这时候就会出现大量的代码重复,那为了不重复,就定义一个节点的基类,然后每一个节点都先从这个节点的基类开始继承,然后再添加自己的专用代码,同样的道理,nginx也可能有一堆,nginx都要去include nginx的类,无非就是安装各种包,但是我们有些nginx的主机时用来做web的,有些是用来做反代的,那么大家都从nginx基类来继承,我们再额外添加一些子类,这样也能保证代码不被重复写;所以任何代码可重复时,都可以用继承来定义,而定义代码继承的方式为:
node 'NODE_NAME' inherits 'PAR_NODE' { PAR_NODE表示:此前定义的基类;
...puppet code...
}
eg:
node 'base_jdk' {
include jdk
}
node 'CM-BJ-CY-001' inherits 'base_jdk' {
include elasticsearch
}
表示:主机CM-BJ-CY-001拥有了安装jdk和elesticsearch的功能;
站点清单文件模块化
但是如果将来我们管理的主机实在是太多了,导致我们在一个站点清单中去定义这些主机的内容不方便做模块化管理,我们可以在/etc/puppet/manifests/hosts.d/*.pp下定义一个hosts.d的文件,总之就是定义主机的,然后呢这里面定义了很多很多文件,一大堆的.pp的文件,只要不重名就行,但是我们至少在/etc/puppet/manifests/site.pp目录下有一个site.pp的文件,这是入口,在site.pp当中可以使用import指令,意思是导入;
/etc/puppet/manifests/site.pp
import 'host.d'/*.pp
表示:将/etc/puppet/manifests/hosts.d/*.pp下的所有的以.pp结尾的文件都包
含进来,比如webservers.pp、tomcatservice.pp;这样就可以实现站点清单
文件模块化;
/etc/puppet/manifests/hosts.d/*.pp
示例:
1、在/etc/puppet/manifests/目录下创建maker hosts.d目录;
2、进入hosts.d目录创建tomcat.pp

这时候,将tomcat.pp放在hosts.d目录下是没法生效的,所有的站点清单只能够通过site.pp来生效,所以要编辑site.pp

4、systemctl restart puppetmaster.service 重启服务让其生效;
5、进入3和4主机,安装puppet agent端需要的软件包;
puppet agent --verbose --no-daemonize --noop --test --server node1.magedu.com
- 在puppet master上查看证书状态:puppet cert list
- 签署证书:puppet cert sign node3.magedu.com或者 加--all签署所有未签署的证书;
- agent端再次跑一遍:
puppet agent --verbose --no-daemonize --noop --test --server node1.magedu.com
就会安装上jdk和tomcat;
9、在agent端:vim /etc/puppet/puppet.conf
[agent]
........
server = node1.magedu.com
- systemctl start puppetagent.service
过一会儿jdk和tomcat就会安装成功;
多环境配置
什么是多环境配置呢?我们将来公司的运维环境大体上能够分成3种环境,线上环境,比如:调度器、tomcat服务器、缓存服务器、web服务器、主站服务器甚至还有分布式文件系统,而这套系统是在线向客户端提供服务的,当然这里还有一个puppet服务器,为了能够完成主动配置。我们的puppet服务器为线上的每一台主机都提供了他们的站点清单文件;但是我们任何的配置要想修改的话,我们都要修改puppet的站点清单和模块然后使用puppet master reload一下或restart一下;但是如果我们修改的配置一旦上线,新配置导致服务中断了怎么办?那么这就有一个测试环境和开发环境;
三种环境,作为puppet来讲,为每一个环境来提供配置是主要关联到我们为了一种环境提供配置主要关联到有两种清单,第一是我们的模块第二是我们的站点清单文件,那么三种环境可能需要各自的模块文件和目录,因为你的模块中设定了文件的配置或设定了每一个应用程序的配置文件;所以说这么一来就意味着在puppet主机上你需要设定三组工作目录,每一组工作目录都有许多子目录,分别用于为一种环境提供站点清单文件和模块文件,第二种第三种环境也一样;那我们要把它隔离开来,这种形式就叫做puppet的多环境配置;
其实这样对我们来说就很头疼了,将来我们要开发的代码到底属于哪个环境呢?久而久之就会乱套,更重要的是我今天改版一次,明天改版一次,那这个新参数一上线,挂了;怎么办?那我们就要把配置恢复到原始配置,然后再重新调,怎么恢复的原始配置呢?原始配置到底是什么呢?改来改去早已经乱成一锅粥了;这时候就需要一个版本控制系统,在这个版本控制系统上每一次修改参数之后我们都可以定义一个版本节点,它给我们提供了一个
时间机器;你可以随时回到过去的任何一个版本;那么我们所有的改动和此前的版本就像一个定了一个又一个的快照一样可以随时检出过去的某一时刻的状态,然后让你的主机进行恢复;版本控制系统有很多种,像CVS、SVN、Git等;git就是这么一个组件,那么定义一个git服务器或者我们使用git hub,在git hub(全球代码托管公共站点)上注册一个账号,但是在git hub上托管的配置都是公开的;不管怎么样我们将代码放在互联网上总是有风险的,那么我们可以在公司自建一个git仓库;假如说我们是puppet开发人员,写了各种各样的代码适用于各种服务器的,写完以后就直接托管到git仓库中,每改一版,就保存一下,将来当我们需要去测试时,就将代码拖到测试环境,跑起来如果没有问题则将测试过的代码部署到线上环境中去;
那么接下来我们就可以让puppet至少要能适用于三种环境,分别提供不同的配置;那该怎么搞呢?首先,agent端得说明自己是来自于哪个环境的,因此在agent端我们使用puppet config print environment命令显示自己是production(生产),如果我们没有指定环境的话,默认所有agent主机都是生产环境;
但是如果要让我们的puppet master支持多环境配置,那么我们就需要额外的提供不同的环境配置了;在 cd /etc/puppet目录下,当我们安装完server包以后,它就生成了一个专门的目录叫environments,我们通常在这个environments目录下来组织各自的环境,因此我们要模拟三种环境我们就需要在environments目录下创建各自的modules和manifests目录;
mkdir -pv /etc/puppet/environments/{production,development,testing}/{modules,manifests}。这三种环境下各自有自己的模块文件目录和站点清单目录,当agent端报告自己是production时,我们就找production下面的站点清单和模块;而不再是默认的/etc/puppet/modules和manifests目录;但是我们怎么能实现多环境支持呢?
那我们需要这么做,编辑master端的/etc/puppet/puppet.conf。添加如下内容:
(这种多环境匹配置方式在3.7.5之前的版本是支持的。到3.8之后就迁移到另外一种多环境配置机制了)
[master]
environment = producation, development, testing
#这里是要指明我们的environment支持这三种环境;
[production]
modulepath=/etc/puppet/environments/production/modules
#指明production的模块文件路径,而不再使用默认路径;
manifest=/etc/puppet/environments/production/manifests/site.pp
#指明站点清单文件的入口是什么,而不再使用默认的;
[development]
modulepath=/etc/puppet/environments/development/modules
manifest=/etc/puppet/environments/development/manifests/site.pp
[testing]
modulepath=/etc/puppet/environments/testing/modules
manifest=/etc/puppet/environments/testing/manifests/site.pp
agent端配置所在的环境:
[agent]
enviroment = production或development或testing (这三个中的某一个)
定义完成之后,我们需要在puppet master端重启服务:systemctl restart puppetmaster.services;然后执行puppet config print environment命令查看所支持的配置环境;
以上测试多环境配置时会有一点问题,这是因为上面的多环境配置方式只支持3.7.5之前的版本,到3.8以后就迁移到另外一种多环境配置机制了;
那么3.7.6及其之后的版本当中,大体上实现多环境配置的时候,已经不再支持单独使用像production、development、testing这样的配置段;而是在这之后puppet.conf仅支持main、master和agent三个配置段;
那么我们的多环境配置该怎么来搞呢?我们只需要指明一个环境路径,就是environment path之类的,来定义我们的环境信息在哪一个路径下即可;默认我们的多环境配置路径是在/etc/puppet/environments/目录下,要求在这个目录下创建子目录,实际上就是你的环境名称,子目录名称要与你的环境名称相同;那每一个环境我们要首先使用环境名称:ENVIRONMENT_NAME/
modules/
manifests/site.pp
environment.conf 在这个配置文件片段当中来指明当前环境的配置信息,例如模
块加载的路径和manifests/site.pp的相关的内容;
编辑vim /etc/puppet/puppet.confg文件:
将environmentpath = /etc/puppet/environments路径写在[main]下面是生效的;我
们可以systemctl restart puppetmaster.service重启服务,然后执行命令puppet config print
environmentpath命令,就会显示出路径/etc/puppet/environments了,对于这个信息来
讲, 其enviromentpath的默认路径其实就是/etc/puppet/enviroments,不修改也没什么
问题;
示例:
编辑pupppet.conf
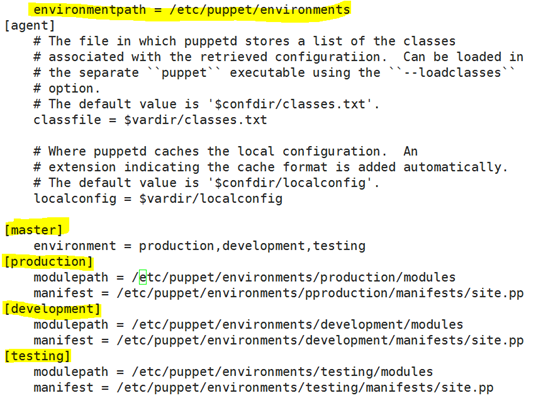
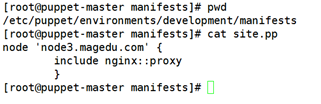
遇到的问题:

上图中的告警没查出个所以然来,但是puppet是可以跑成功的,该装的软件也能安装成功,如果介意该告警,则在.pp文件中添加"allow_virtual=> false"这一项即可取消告警;