一、 容器类:
下图摘自《Java编程思想》,很好地展示了整个容器类的结构。
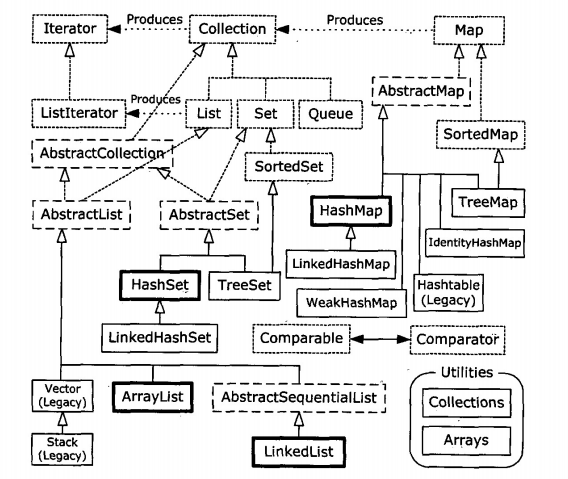
由上图可知,容器类库可分为两大类,各自实现了Collection接口和Map接口,下面就常见的类进行一下分类:
实现Collection接口的容器类
Collection
├List
│├LinkedList
│├ArrayList
│└Vector
│ └Stack
├Set
│├TreeSet
│└HashSet
└LinkedHashSet
├Queue
│├LinkedList
│├DelayQueue
│└PriorityQueue
实现Map接口的容器类
Map
├HashMap
└LinkedHashMap
├Hashtable
├IdentityHashMap
├TreeMap
└WeakHashMap
容器类由两个顶层接口自上而下扩展:
- Collection: 存放独立元素的序列
- Map:存放key—value类型的键值对元素。
其中值得注意的是:Collection提供了Iterable()模式,可以获取到Iterator对集合内的元素进行遍历,而Map则需要先得到Collection进而得到Iterator进行遍历。
其中 接口List、Set、Queue实现了Collection接口,对应的List、Set和Queue又有其具有实现的类。实现了Map接口的主要有HashMap、LinkedHashMap、Hashtable、IdentityHashMap、TreeMap、WeakHashMap。
二、 实现Collection接口的容器类
下面就List、Set和Queue下的几种常见容器展开简要的介绍
2.1 List接口
两种典型实现:
- LinkedList:
底层实现为链表,对于这种实现结构而言,插入和删除操作效率高,而随机访问元素时效率较ArrayList低。
同时,又由于LinkedList实现了Deque接口,故而它还能提供List接口中没有定义的方法,专门用于操作表头和表尾的元素,可以当做堆栈和队列使用。
- ArrayList:
底层实现为数组,此种结构在随机访问和查询时效率高,而在进行插入和删除操作时效率较低。此外,由于其底层实现是数组,故而当数组大小不足需要增加存储空间时,就需要将现有数组中已有的数据复制到新的存储空间中。
两种弃用的List实现:
- Vector:
Vector和ArrayList一样也是通过数组实现的,故而其特性和ArrayList类似(Vector底层数组实现在扩容时是扩展1倍,而ArrayList则扩展50%+1个),其中值得特别注意的一点是Vector是一种线程安全的容器,即在某一时刻只有一个线程能够写Vector,避免在多线程同时写时引起的不一致性,但由于实现同步(synchronized关键字)需要较高的代价,故访问速度较慢。
- Stack:
是Vector的一个子类,实现了一个标准的后进先出的栈。(现在实现堆栈的功能一般使用LinkedList)
2.2 Set接口
是一种不包含重复元素的Collection,同时Set允许null元素。加入set的元素必须定义equals()方法来确保对象的唯一性。
几种典型的实现:
- Hashset:
利用哈希函数进行了查询效率上的优化,是一种为快速查找而设计的Set,存入其中的元素必须定义hashCode();
- LinkedHashSet:
具有Hashset的查询速度,且内部使用链表来维护元素的顺序。元素同样必须定义HashCode()方法
- TreeSet:
保持有序的Set(实现了SortedSet接口),底层结构为红黑树,使用它可以从Set中得到有序的序列。元素必须实现Comparable接口
2.3 Queue接口:
- PriorityQueue:
存储在其中的元素该需要实现Comparable接口,即自己完成优先级的定义
- Deque:
双向队列,可以在任何一段添加或移除元素。其中LinkedList实现了Deque接口,可实现队列或栈的数据结构。
三、实现Map接口的容器类
Map没有继承Collection的接口,其提供了key到value的映射,一个Map中不能包含相同的key,每个key只能映射一个value。
几种典型的实现:
- Hashtable:
线程安全
任何非空(non-null)的对象都可作为key或者value。
添加数据使用put(key, value),取出数据使用get(key),这两个基本操作的时间开销为常数。
通过initial capacity和load factor两个参数调整性能。通常缺省的load factor 0.75较好地实现了时间和空间的均衡。增大load factor可以节省空间但相应的查找时间将增大,这会影响像get和put这样的操作。
由于key的对象将通过计算其散列函数确定与之对应的value的位置,因此任何作为key的对象必须实现hashcode和equeals方法。
- HashMap:
线程不安全
HashMap和Hashtable类似,不同之处在于HashMap是非同步的,并且允许null,即null value和null key,但是将HashMap视为Collection时(values()方法可返回Collection),其迭代子操作时间开销和HashMap的容量成比例。因此,如果迭代操作的性能相当重要的话,不要将HashMap的初始化容量设得过高,或者load factor过低
- IdentityHashMap:
比较键(和值)时使用引用“==”代替equal。即在 IdentityHashMap 中,当且仅当 (k1==k2) 时,才认为两个键 k1 和 k2 相等
而在正常 Map 实现(如 HashMap)中,当且仅当满足下列条件时才认为两个键 k1 和 k2 相等:(k1==null ? k2==null : e1.equals(e2)))。
该类是应用于特定场景下,即当我们必须使用地址相等来判断值相等的场合,以及我们确定只要其地址不相等,则其equals方法的结果也必定不相等的场合。
一个很好的例子就是线程本地存储中的ThreadLocal类,该类的原理是根据Thread从其内部的Map中获取线程独立的值,那么当我们使用只判断地址相等的IdentityHashMap就会比HashMap要快一些。
- WeakHashMap:
WeakHashMap是一种改进的HashMap,它对key实行“弱引用”,如果一个key不再被外部所引用,那么该key可以被GC回收。 - ConcurrentHashMap
线程安全的Map,与HashTable不同的,它的线程安全的实现不涉及到同步加锁,它引入了一个“分段锁”的概念,即将一个大的Map拆分成多个”HashTable”(实质上是Segment),当多线程访问容器中不同数据段的数据时,线程间就不存在锁的竞争关系。
ConcurrentHashMap是由Segment数组和HashEntry数组结构组成。其中Segment是一种可重入锁,HashEntry则用于存储键值对数据。
Segment的结构和HashMap类似,是一种数组和链表的结构。一个Segment中包含一个HashEntry数组。每个HashEntry是一个链表结构的元素。每个Segment守护着 一个HashEntry中的元素,当要对HashEntry数组的数据进行修改时,必须首先获得与它对应的Segment锁。
三、怎么选用容器类
在日常开发中,怎么选用合适的容器类关乎到程序的性能以及正确性等,所以怎么选用合适的容器类很关键。
首先一点,容器类中存储的都是对象的引用,而非对象本身。出于便利的角度,一般简称对象的引用为对象。正如上面讲到的不同的容器存储的对象类型不同,并且具有的方法也不同,或是在进行相同操作时的效率也存在差异。
简单来讲,我们将存储的对象分为元素和键值对两种。
元素一般采用实现Collection接口的容器类存储。又根据元素是否有序(TreeSet),元素是否唯一有所区别(实现Set接口的类),是否要求线程安全(Vector),常进行的操作(ArrayList和LinkedList的选用)等要求进行筛选;
而键值对则采用实现Map接口的容器类进行存储,又根据是否要求线程安全(ConcurrentHashMap)、是否有必要进行内存的释放(针对内存优化的WeakHashMap)、是否要求有序(TreeMap)、IdentityHashMap(是否可以用==替换equals来提示效率)等要求来进行筛选。