本篇博客
1.事务
-
1.1 事物的作用
-
1.2 响应时间
-
1.3 添加事务
-
1.4 事务时间
-
1.5 判断事务结果
-
1.6 函数
2.检查点(检查业务是否成功)
2.1 检查点作用
2.2 函数
-
2.2.1文本检查
-
2.2.2图片检查
3.思考时间
-
3.1作用
-
3.2设置策略
-
3.3函数
4.集合点
-
4.1作用
-
4.2设置策略
-
4.3函数
5.Vugen常见函数
6.Controller控制器
总结:在代码里,参数化,事物,检查点必须要用。
关联(不一定要用,如果服务器的响应,在下一次的请求中不必带,就可以不要关联。)
作业1:用一次迭代,把四次定票都点一遍(要用到for循环)
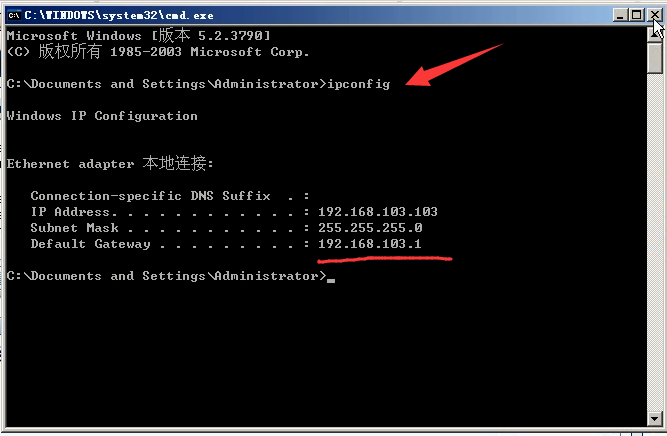
1)看一下ip(windows)
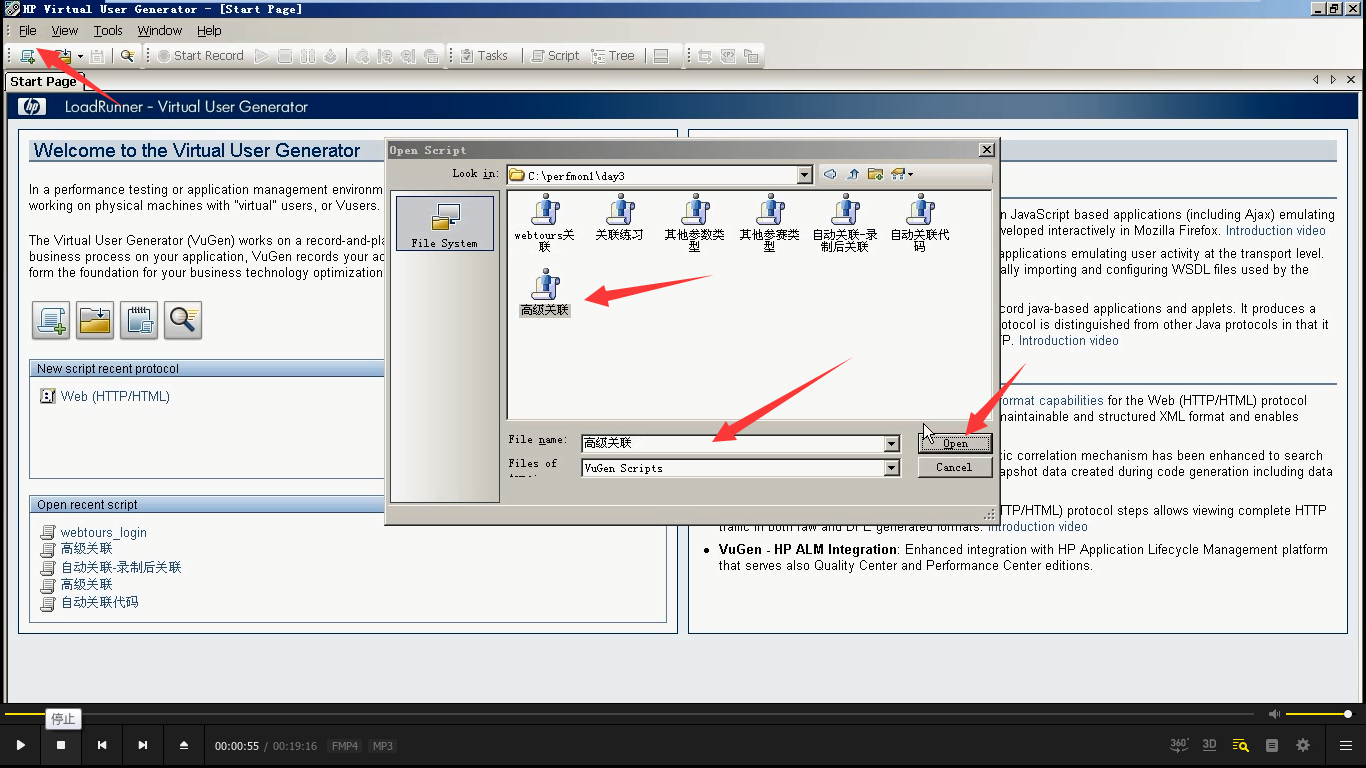
2)打开脚本file---open
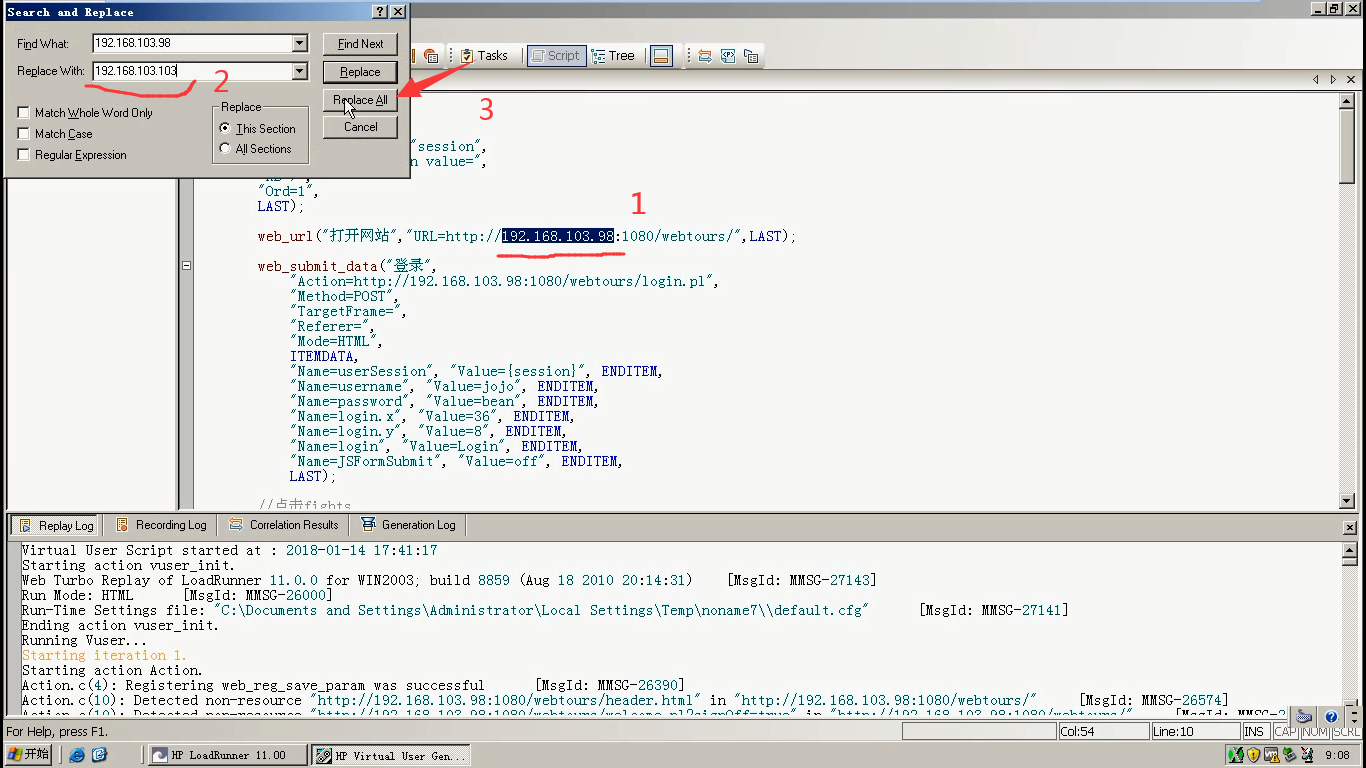
3)替换url(因为已经变了),ctrl+h
4)作业的理解:使用一次迭代,将选择的航班信息顺序的遍历一次。也就是把web_submit_data()点击一遍(4次)
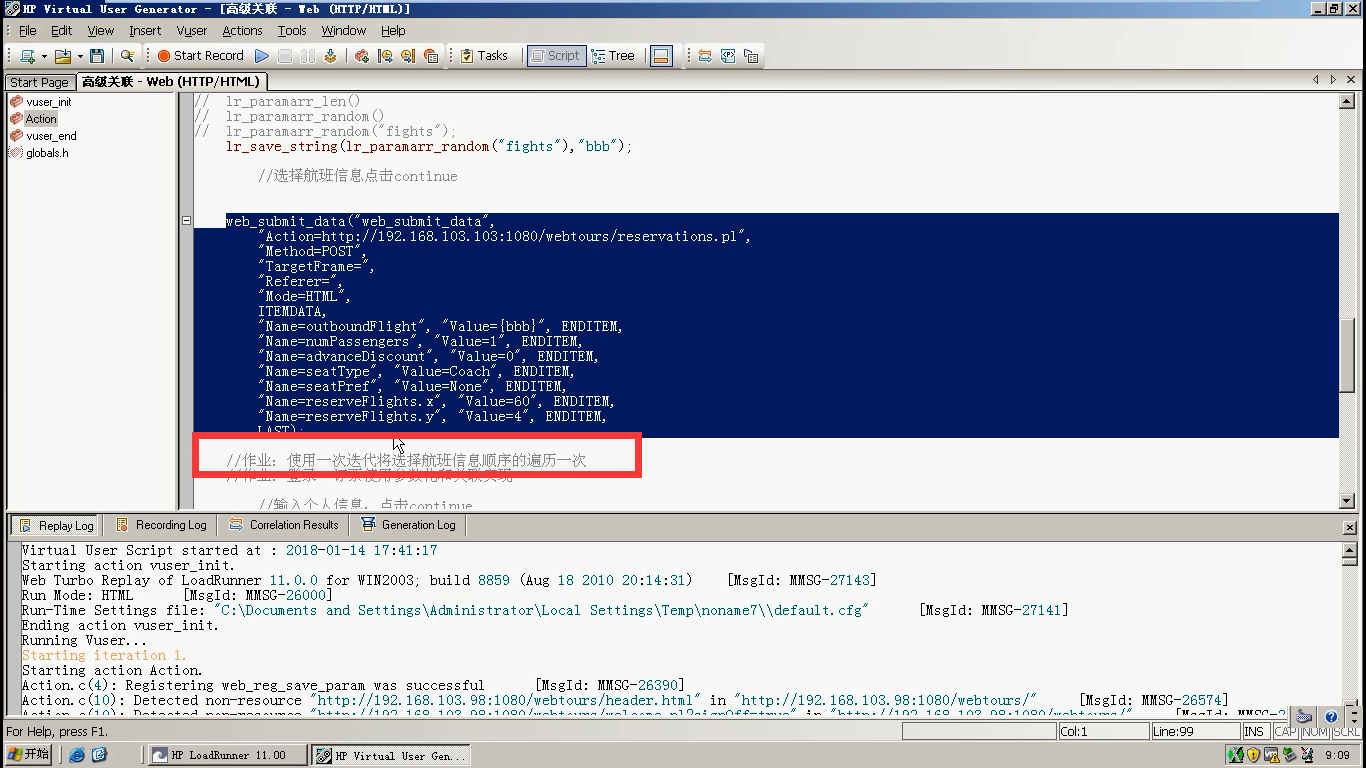
5)使用for循环。lr_paramarr_idx()获取参数数组指定参数。lr_save_string()把字符串保存到参数里。替换value={bbb}
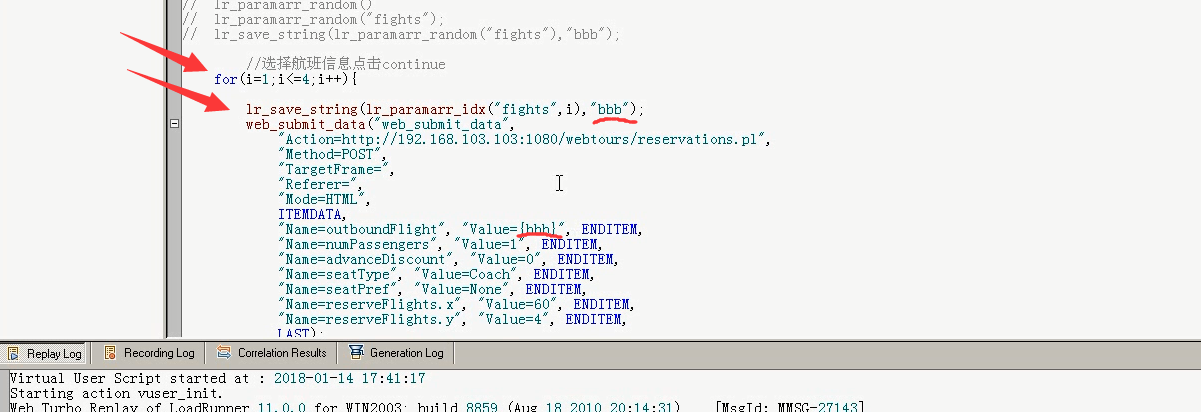
参数i要在首行定义

6)检查一下语法,没问题。

7)设置迭代1次
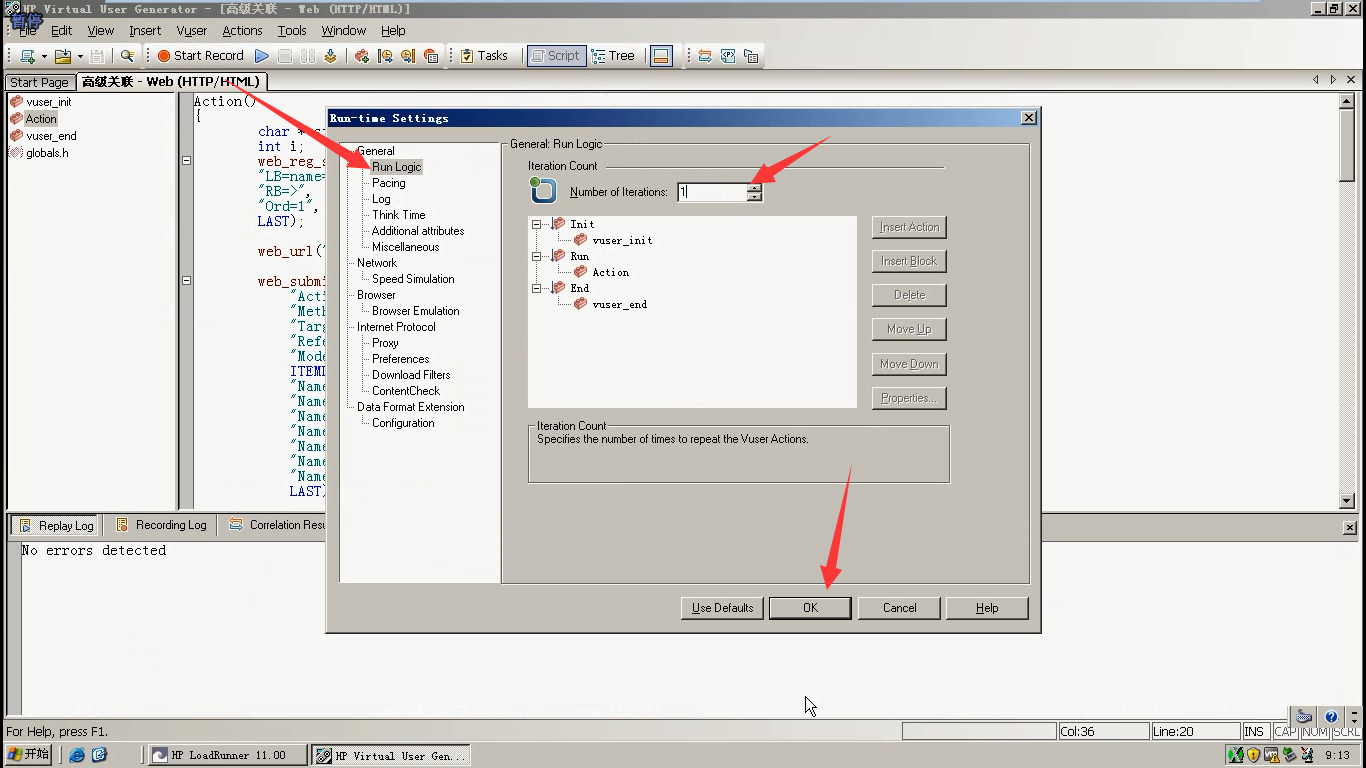
8)运行,查看结果view-----Test Results:顺序的点击4次。

9)想把"web_submit_data"的值替换成bbb的值。
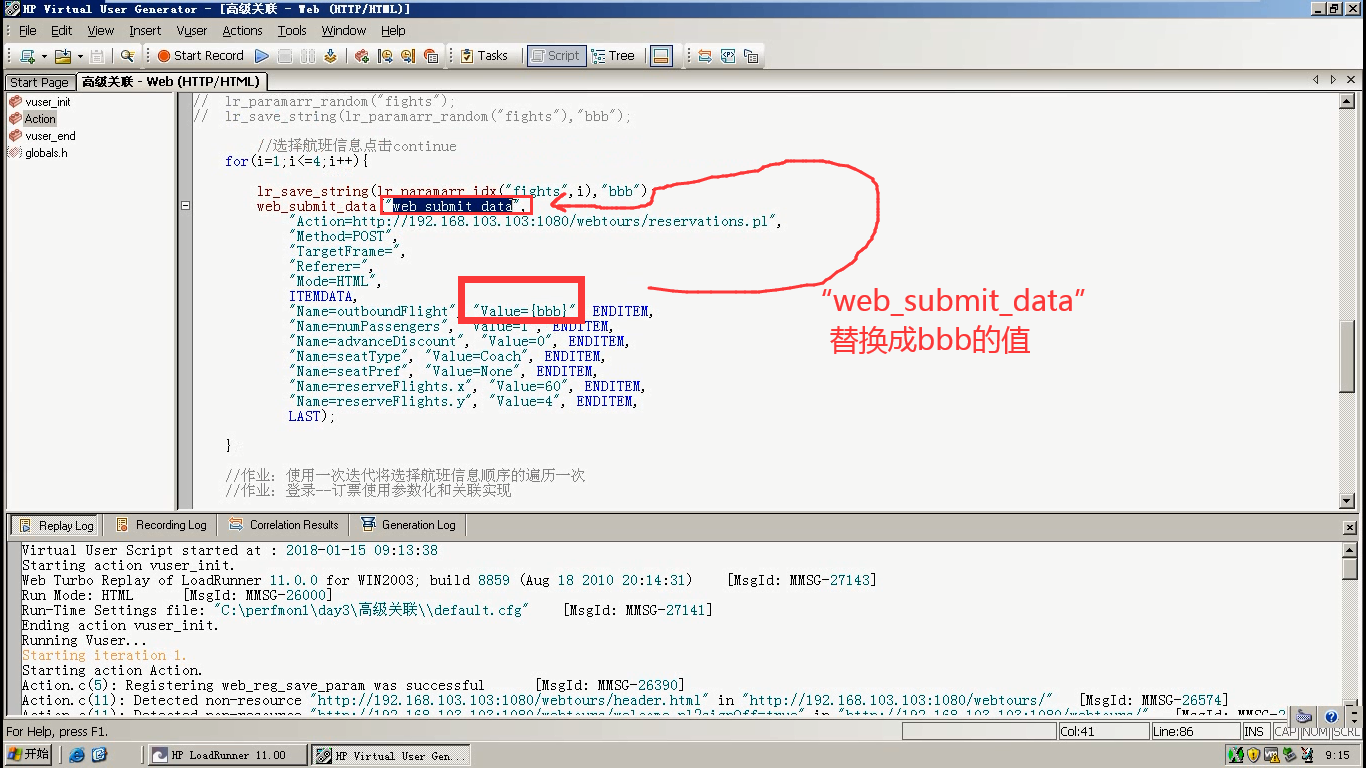
10)通过lr_eval_string("{bbb}"),获取bbb的值。不能在这里直接写{bbb}。因为那是参数,不是字符串。
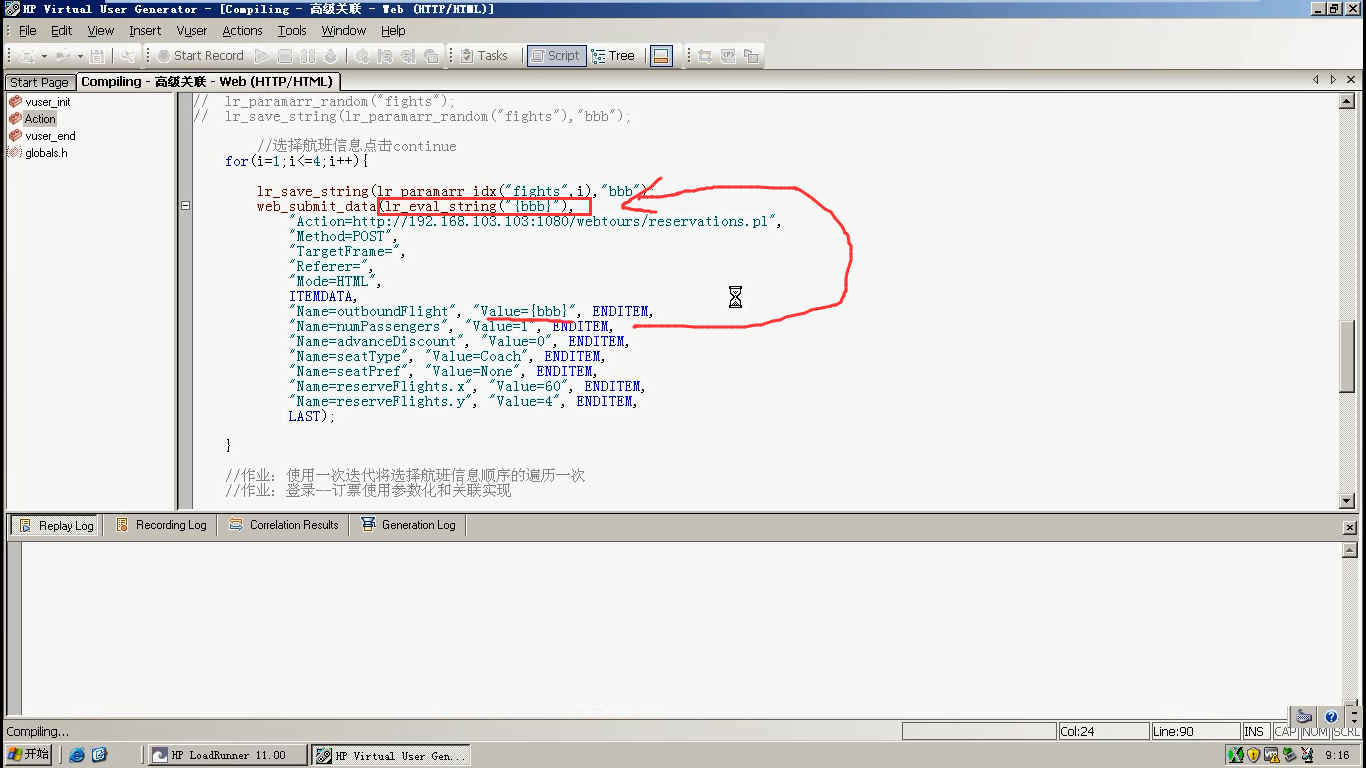
11)查看结果,就是取得名称获得的值。
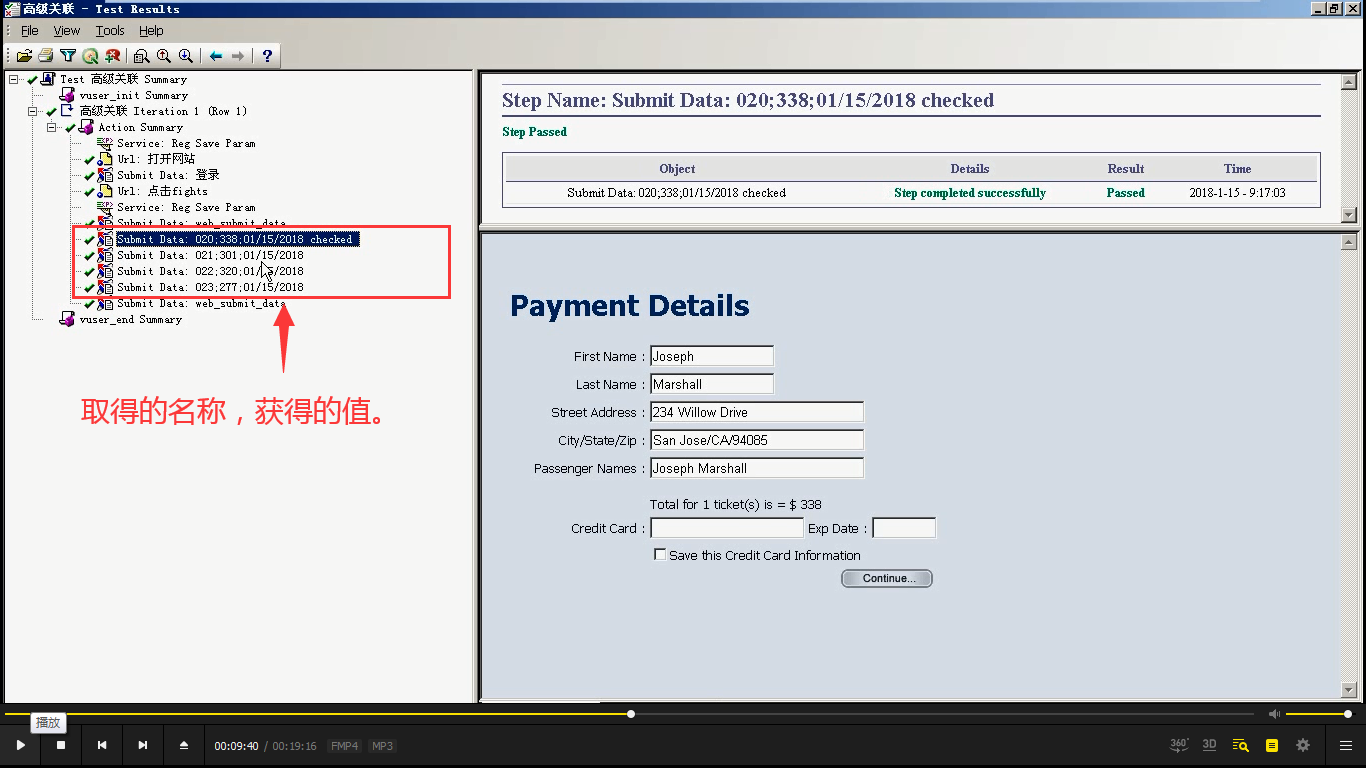
12)可以file_save as 保存一下。
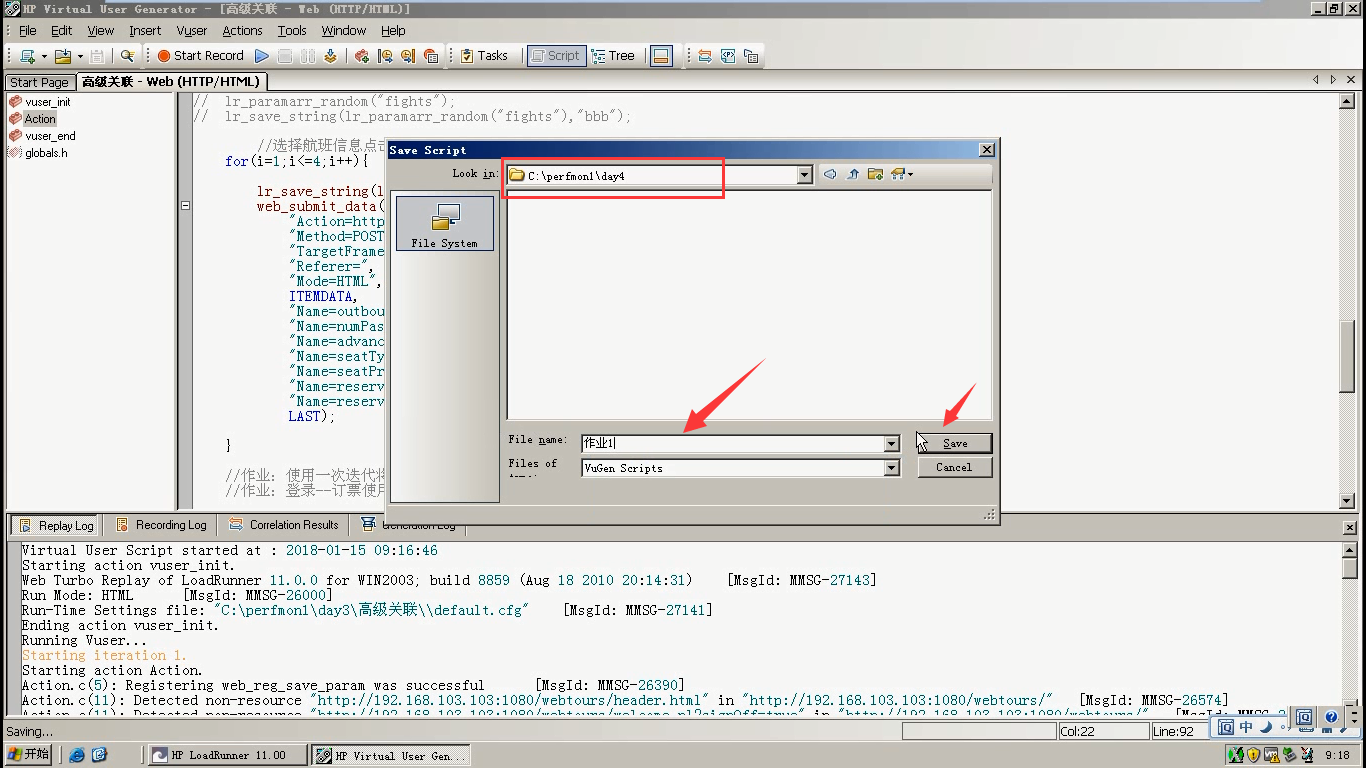
作业2:想把参数化也放在登陆接口上。(现在有关联在里面),把账号和密码参数化。

1)点击p图标,点击new----"user"-----点击create
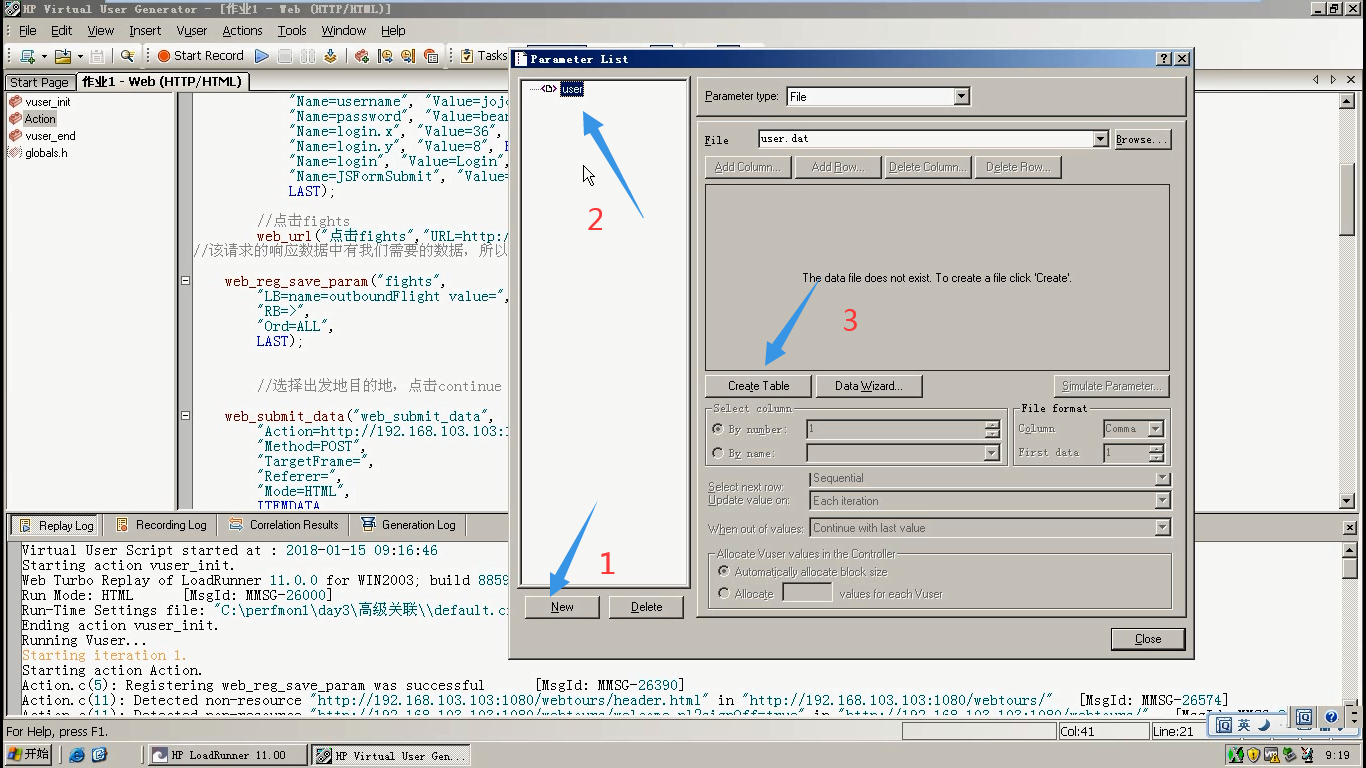
2)点击Add Row(填充user这下面所有列的用户名),点击close保存并关闭。(这里的pwd列可以不写,因为pwd会新建一个pwd文件)

3)jojo参数化:选中jojo-----右键-----Parameter properties
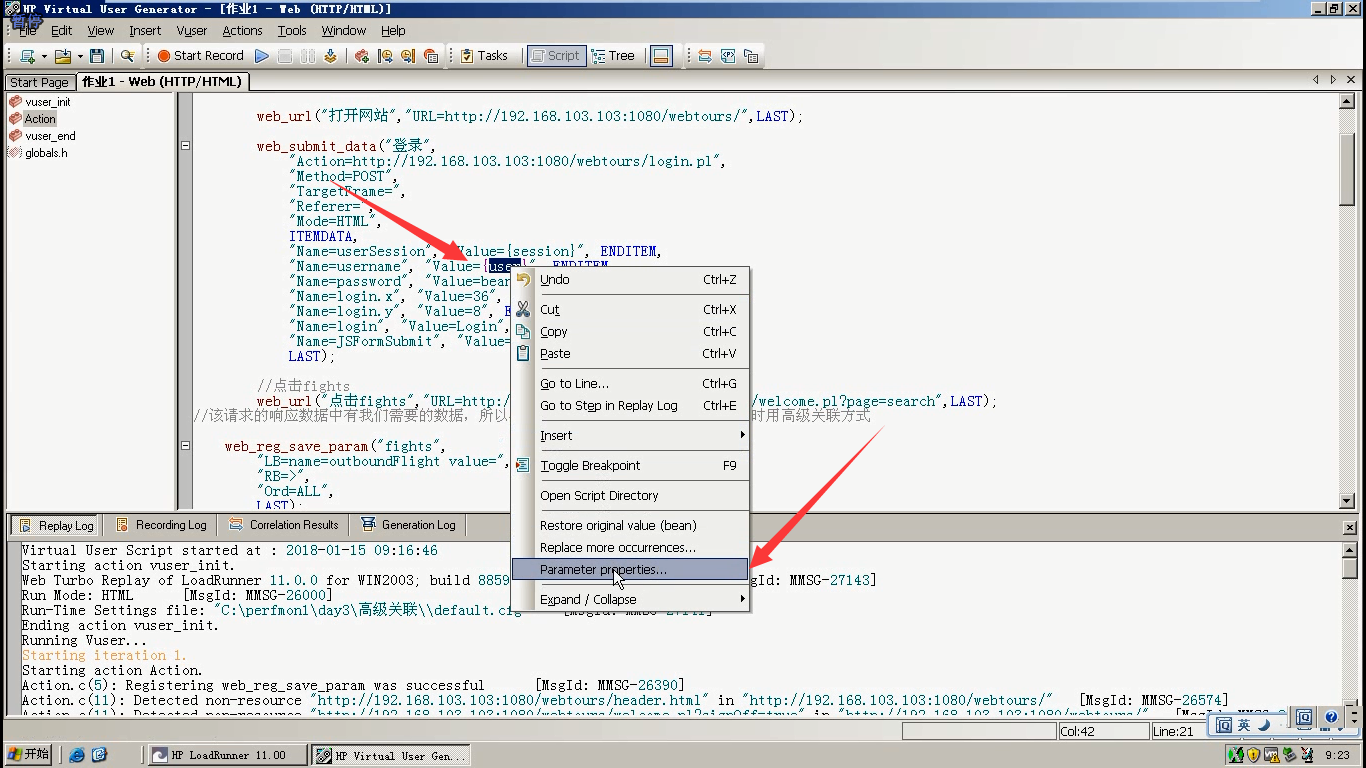
4)By name:user,点击close。
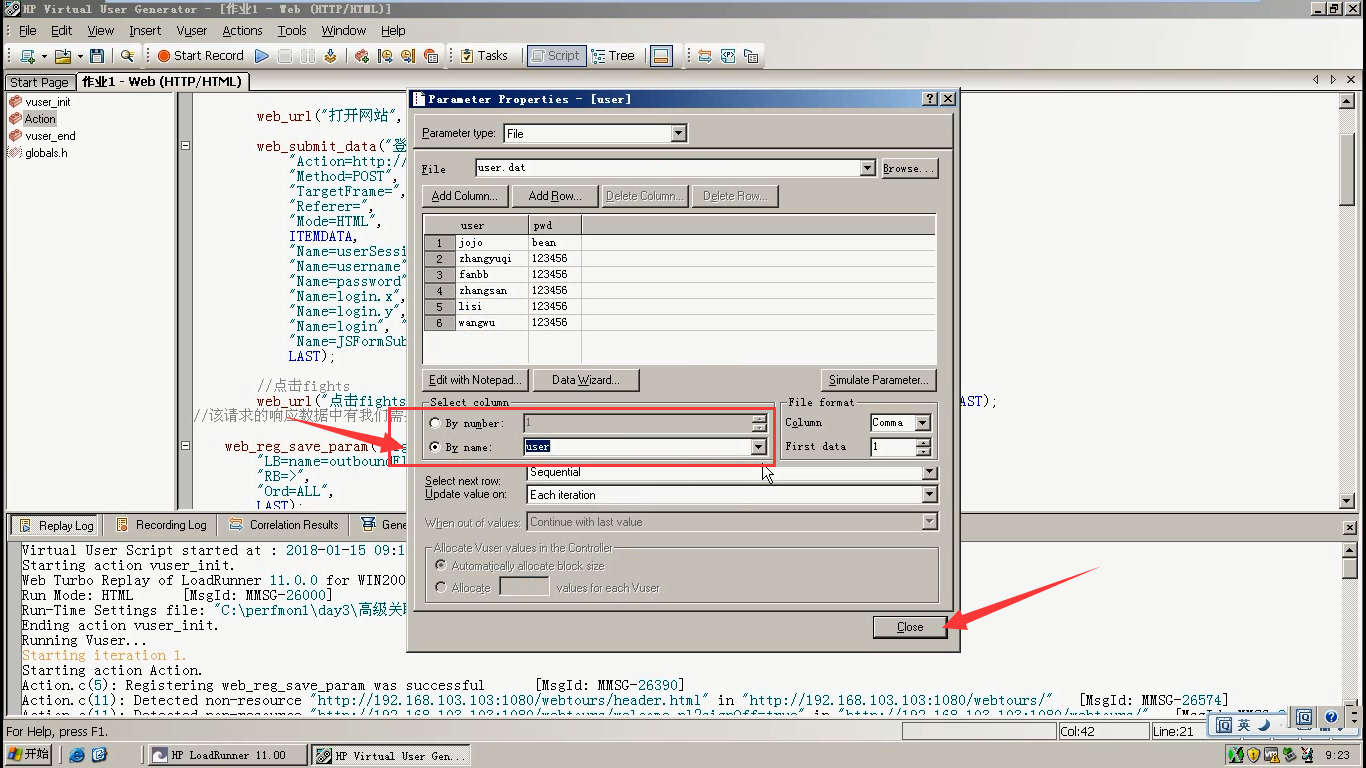
5)点击p图标,点击new----"pwd"-----点击create----点击Add Row(填充pwd这下面所有列的密码)。By number:1(从第1列读取),点击close关闭。
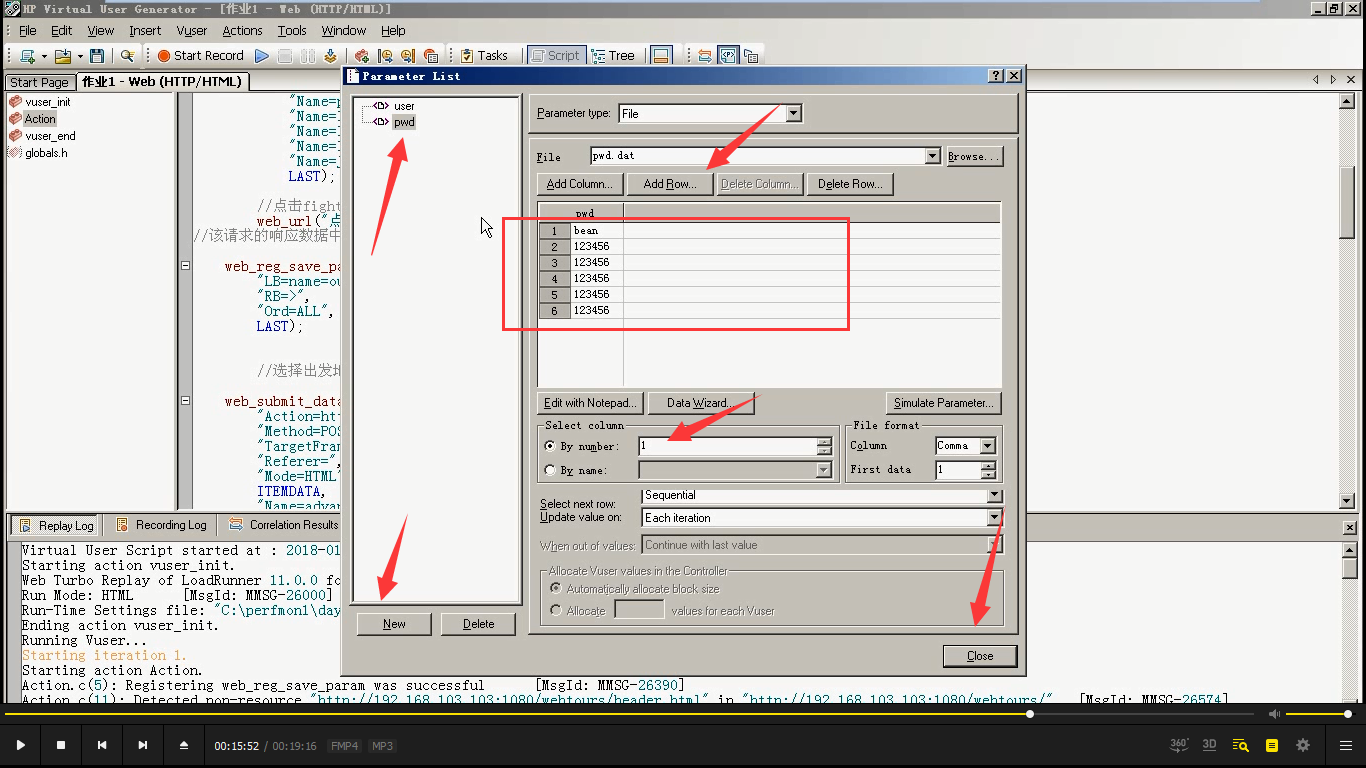
6)选中bean----------右键-----Replace with Parameter。同样选择pwd,点击ok

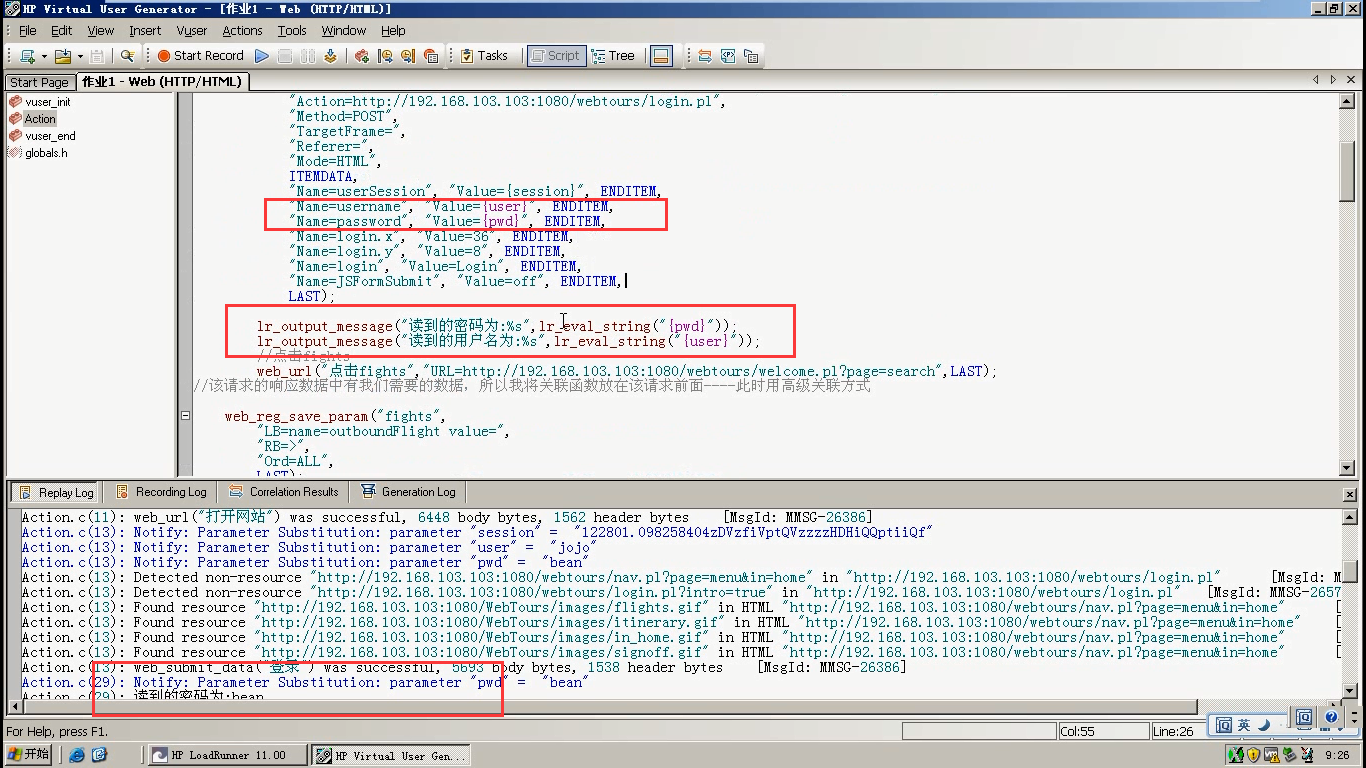
7)设置几次迭代,可以把得到的数据,打印出来。就能把所有的名称读到。
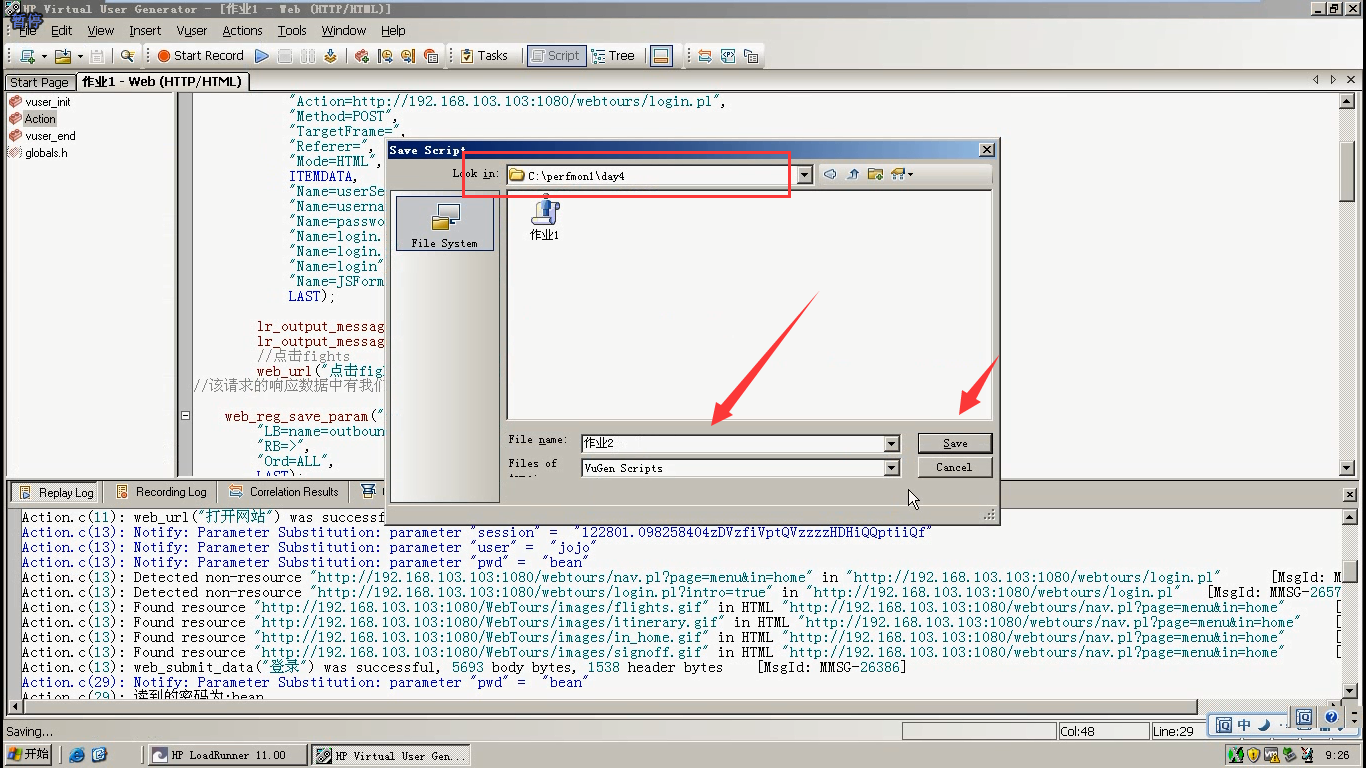
8)可以file_save as 保存一下。
1.事务
通过事务可以查看服务器的响应时间以及事务通过/失败率
1.1 事物的作用
测试人员可以将一个或多个操作步骤定义为一个事务,
可以通俗的理解事务为"人为定义的一系列请求(请求可以是一个或者多个)"。
在程序上,事务表现为被开始标记和结束标记圈定的一段代码区块。
Loadrunner根据事务的开头和结尾标记,计算事务响应时间、成功/失败的事务数。
1.2 响应时间
组成:浏览器---服务器整个处理过程
解释
1.网络时间
客户端发出请求首先通过网络来到Web Server上(消耗时间为N1);然后Web Server将处理后的请求发送给App Server(消耗时间为N2);App Server将操作数据指令发送给Database (消耗时
间为N3);Database服务器将查询结果数据发送回App Server(消耗时间为N4);App Server将处理后的页面发给Web Server(消耗时间为N5);最后Web Server将HTML转发到客户端(消耗
时间为N6)。 这里的Nx都是网络传输上的时间开销,没有计算业务处理所需要花费的时间。
2.服务器处理时间
各个服务器处理所需要的时间WT、AT、DT。
响应时间 = WT+AT+DT +(N1+N2+N3)+(N4+N5+N6) 也可以简单认为响应时间由网络开销(前端)和服务器开销(后端)两大部分组成,
1.3 添加事务(代码必须添加事物)
开始事物
结束事务
(开始事物和结束事物,就是确定一块代码区。这个代码区就是事物。严谨点,代码区就是要做性能测试的代码,或者就是要做性能测试的功能点。)
做性能测试需要分析出来需要测哪些点。这些点,分为两种:一种是独立功能方式(注册,登陆,下订单,退出等)的。还有一种是业务方式(整套多功能组合)的。
对于事物,其实就是确定这些点的一个东西,只有确定了这些要测的内容,我们才能统计该点的响应时间,该点的服务器消耗,网络消耗,服务器的吞吐,并发量等一些信息,只有加了事物,我们
才可以做。
注意:代码里必须要加事物,代码里没有事物,就统计不了时间,统计不了某一点对服务器资源的消耗。
1)file-open
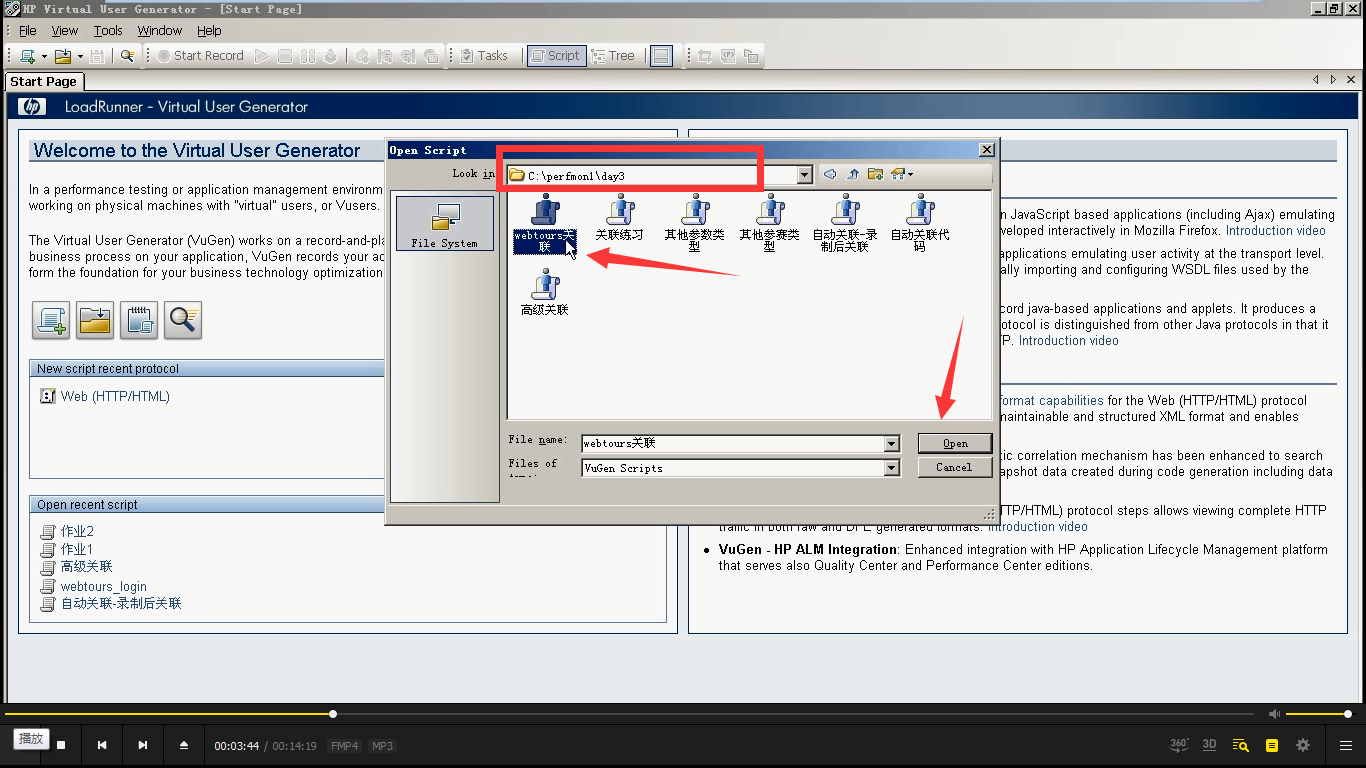
2)把登陆作为一个事物(想知道登陆的响应时间或者多用户并发的响应时间)
3)Insert----Start Transaction

4)取个事物的名称:login,点击ok

5)登陆代码之前,就加了一个事物的开始点。
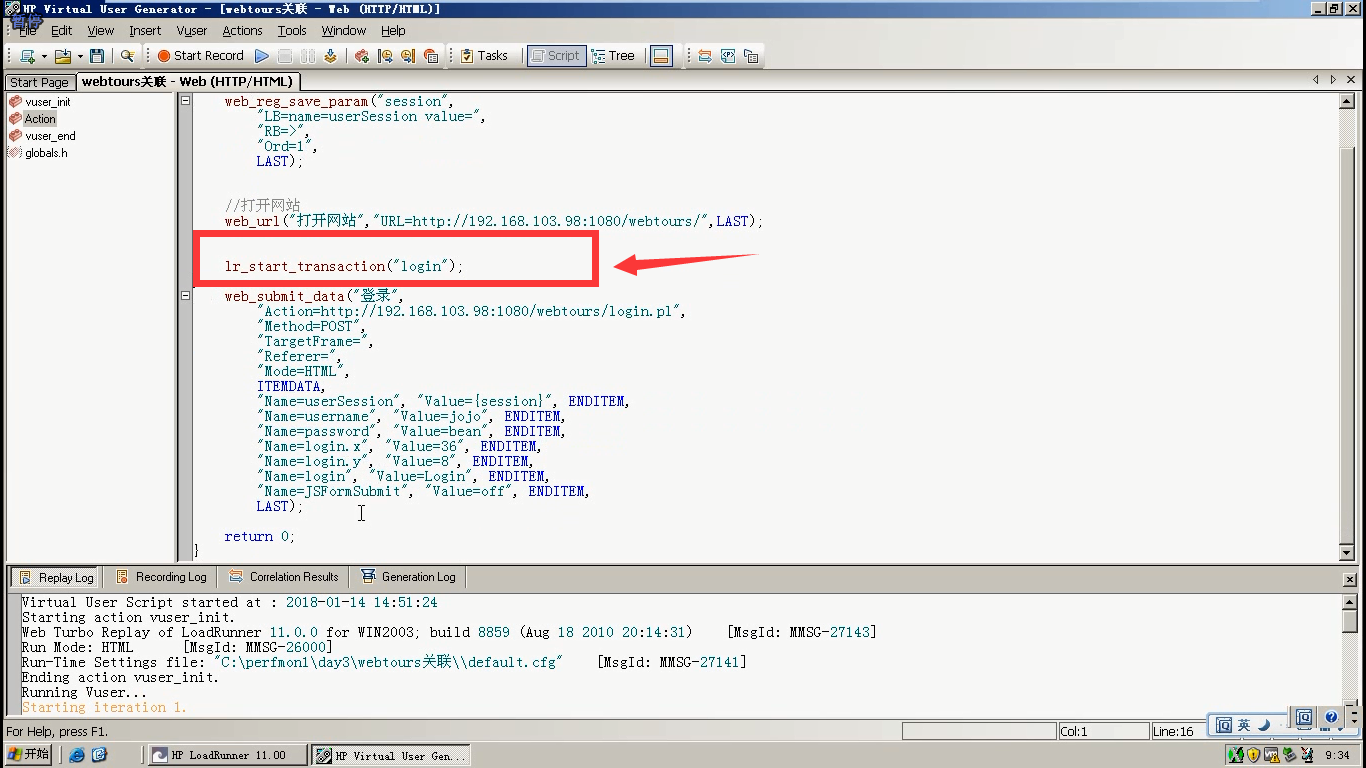
6)点击Insert End Trasaction的图标。(光标停留在登陆接口的后面)
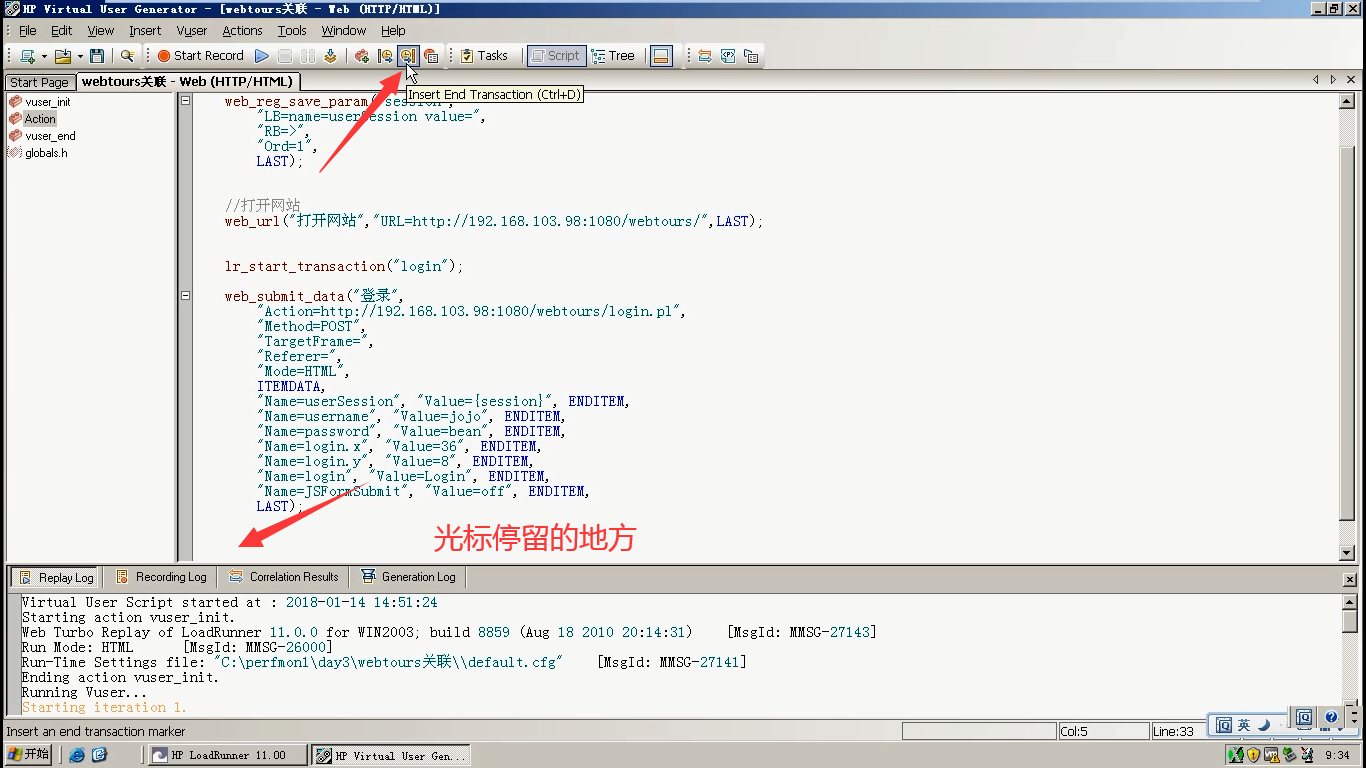
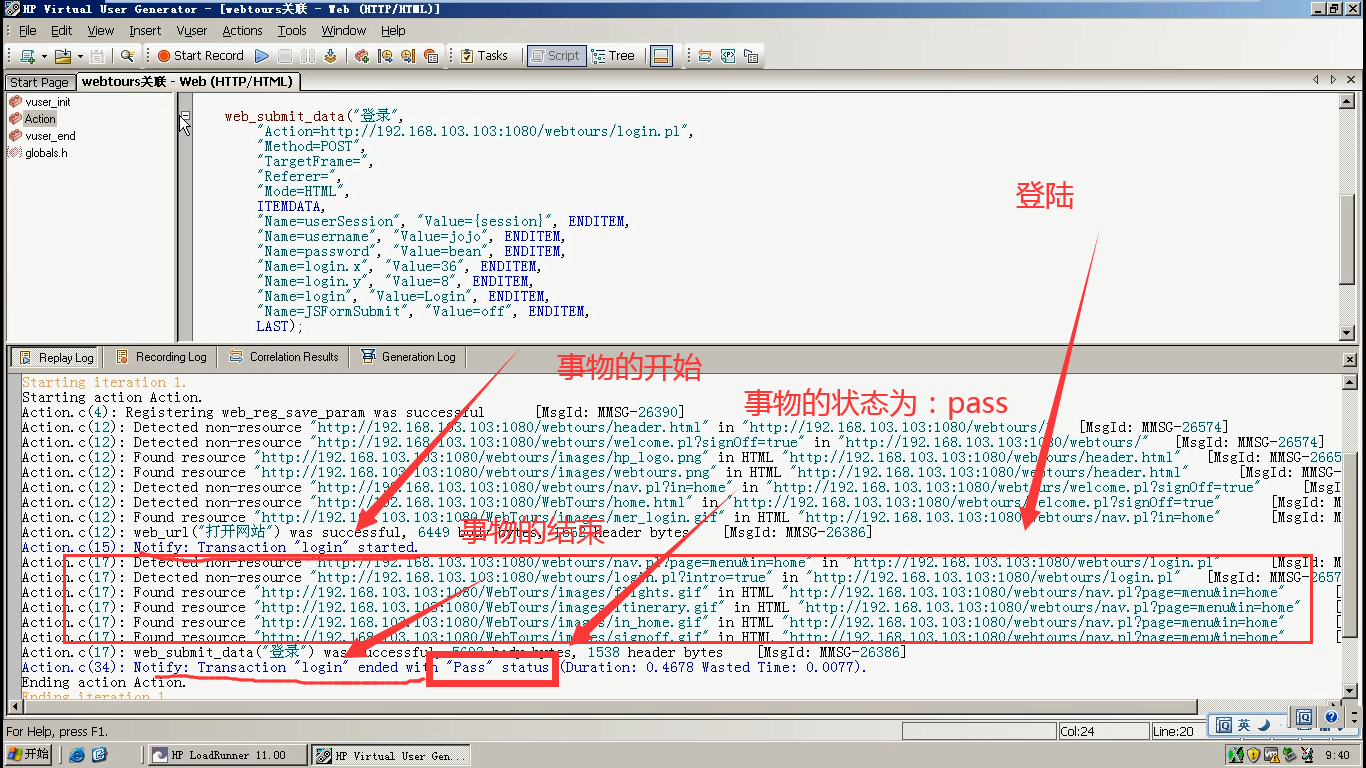
7)事物开始和结束要同一个名称:这里都是login,(也可以同时起一样别的名字)。这里选:LR_AUTO:自动判断事物的状态。点击ok。
Transaction Status(事物的状态):
- LR_AUTO:自动判断事物的状态。
- LR_PASS:事物的状态为成功。
- LR_FAILL:事物的状态为失败。
- LR_STOP:事物的状态为停止。

8)这里就有了一个结束事物的代码。

9)改一下ip:选中ip-----ctrl +h
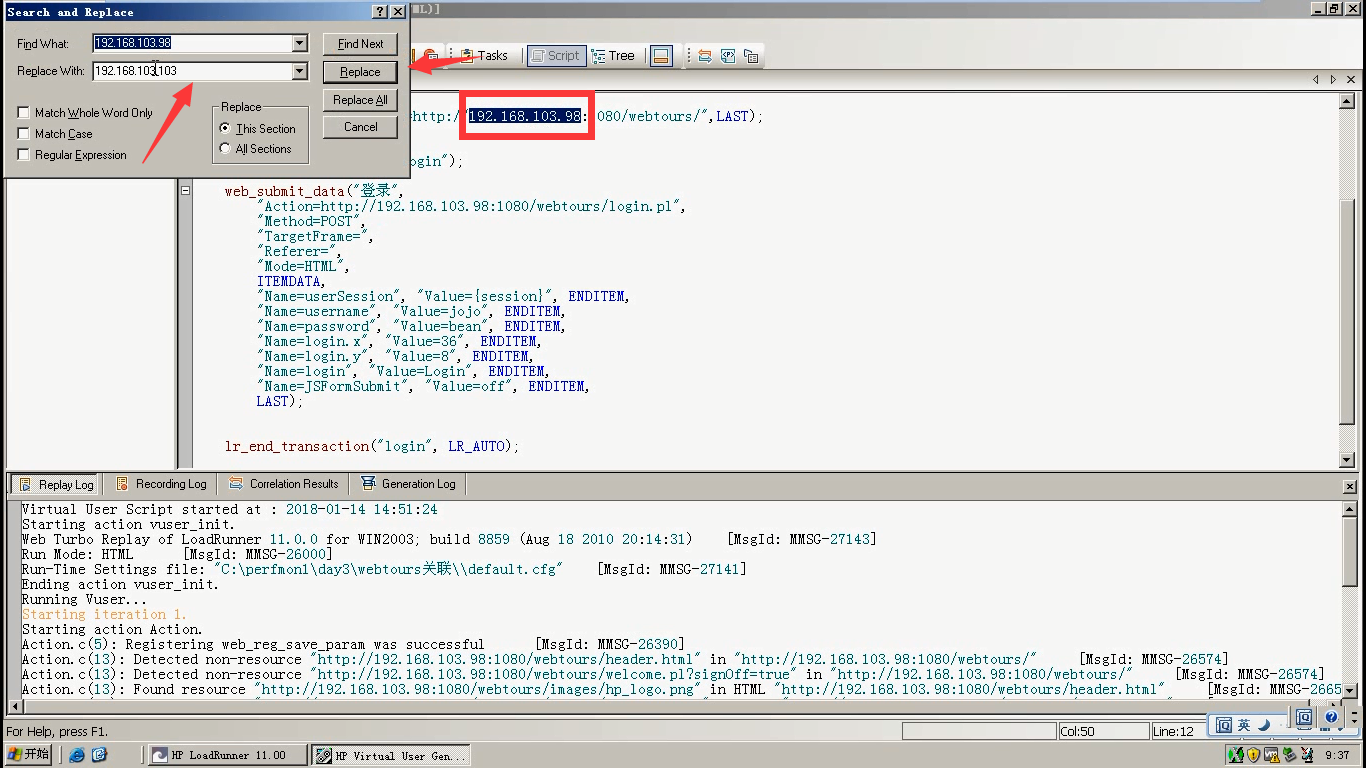
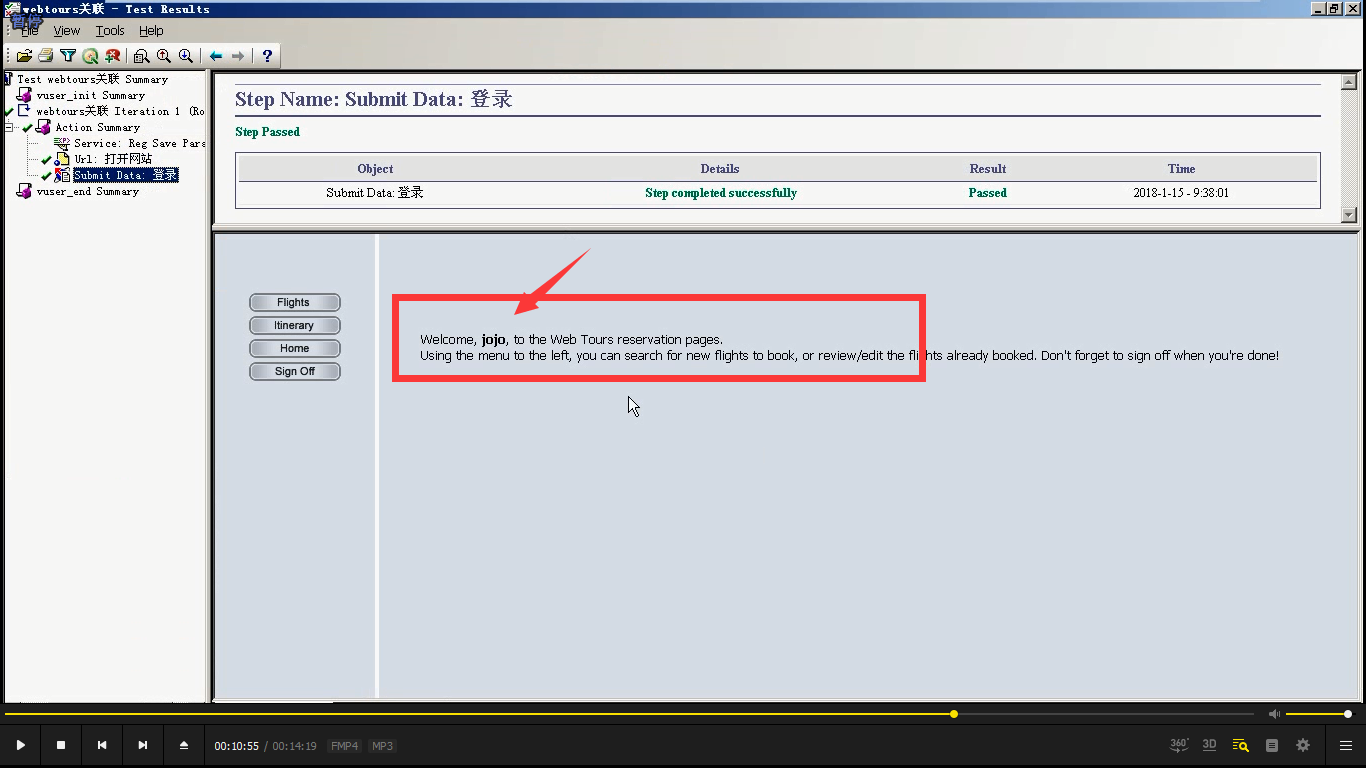
10)点击运行,(这里是迭代1次)查看结果,打开网站,登陆都没有问题。
11)查看日志,蓝色的标示:有事物的开始,事物的结束。事物的状态。
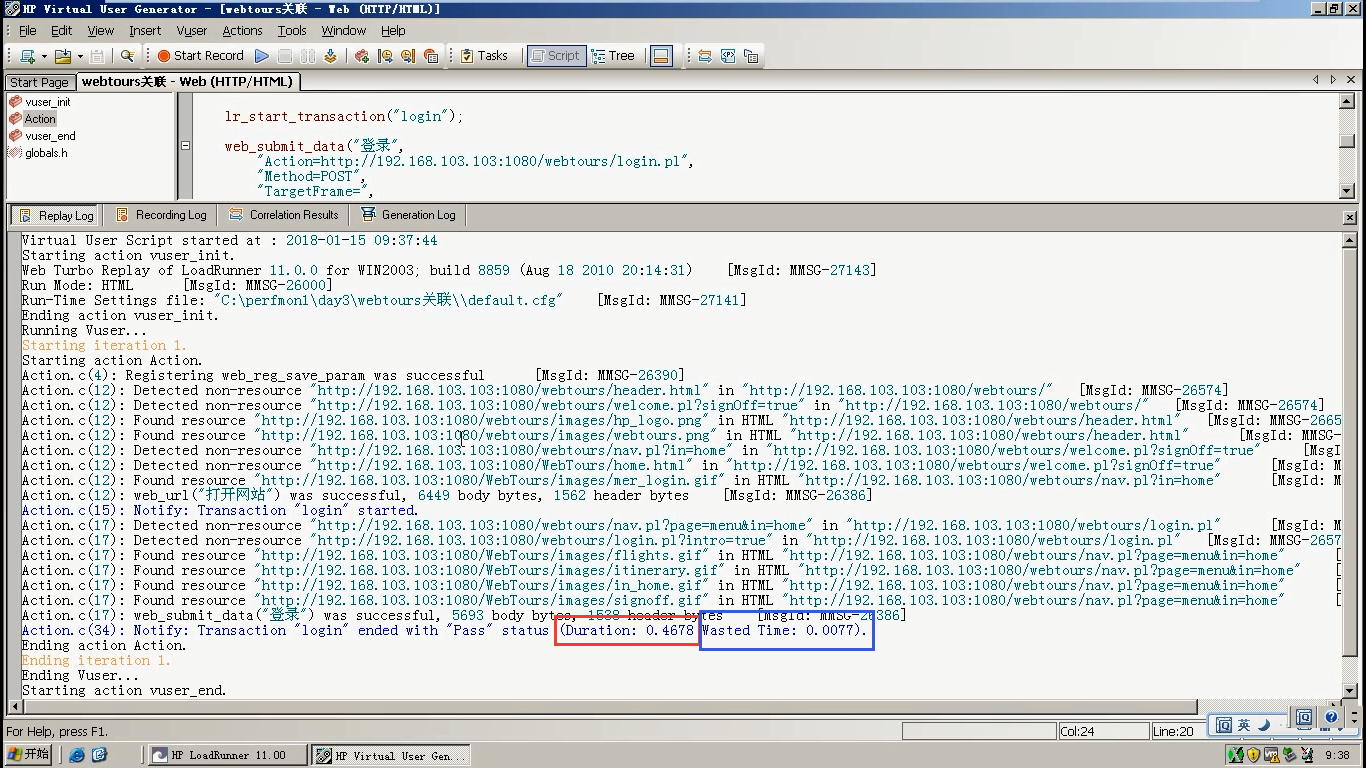
12)登陆事物时间=Duration-Waste Time=0.4601秒
Duration(登陆持续时间):0.4678秒
Waste Time(浪费时间):0.0077秒
浪费时间有:
1.登陆函数的执行时间,即函数本身的时间。(本身要看的是登陆请求出去以后到响应给我的数据,这一段时间。)
2.如果是录的,还有一些思考时间think time
3.结束事物的函数,在判断也有浪费时间。
1.4 事务时间
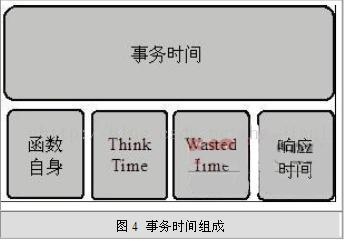
响应时间 = 事物时间-Wasted time
1.5 判断事务结果
1.自动判断:此处判断的是状态码
(LR_AUTO判断的是返回的状态码,并没有判断业务的成功或者失败。)
1)故意把密码写错
2)运行,查看结果:登陆失败
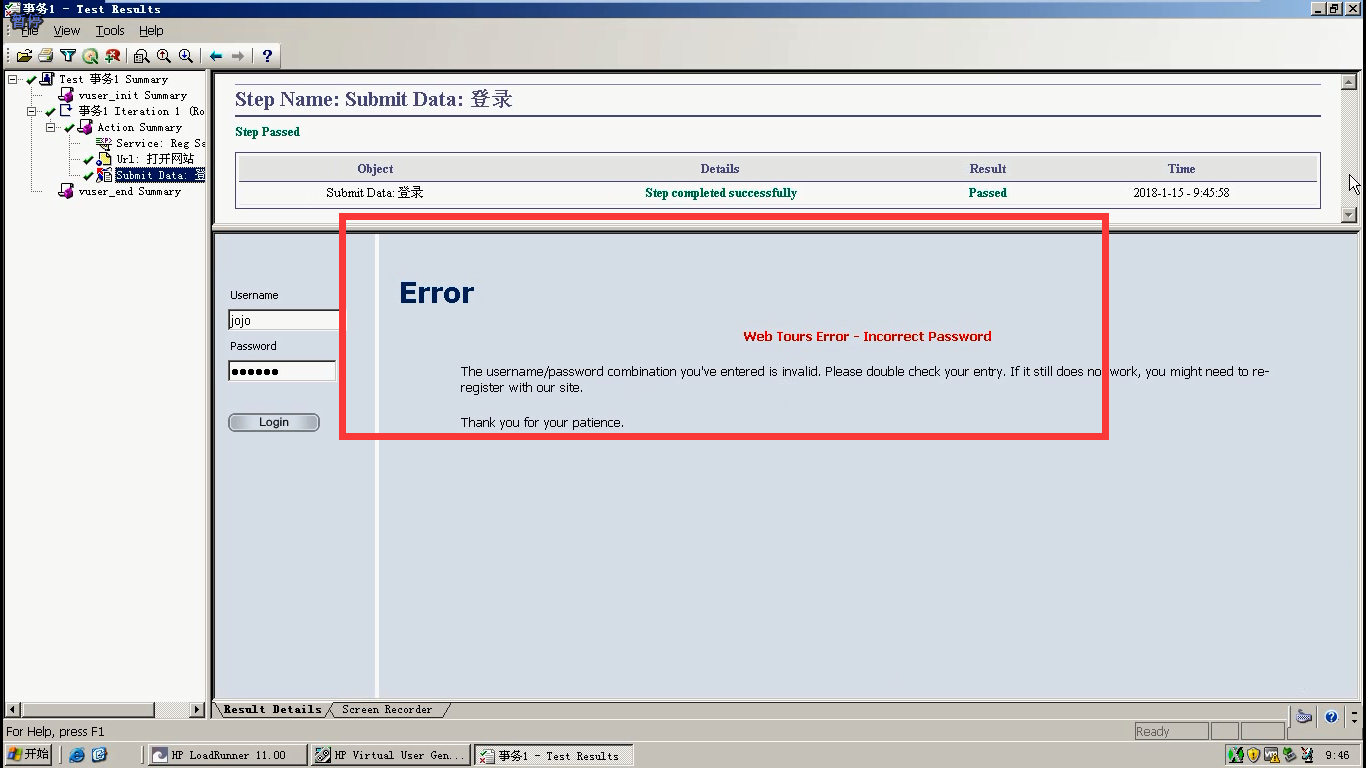
3)查看日志,是pass。没有失败。是因为LR_AUTO判断的不是业务的成功或者失败。这里判断的是服务器返回的状态码。(比如说,登陆成功,返回的状态码是200。输入错误的用户名,密码,
登陆失败了。返回的状态码还是200)。LR_AUTO判断的就是状态码。
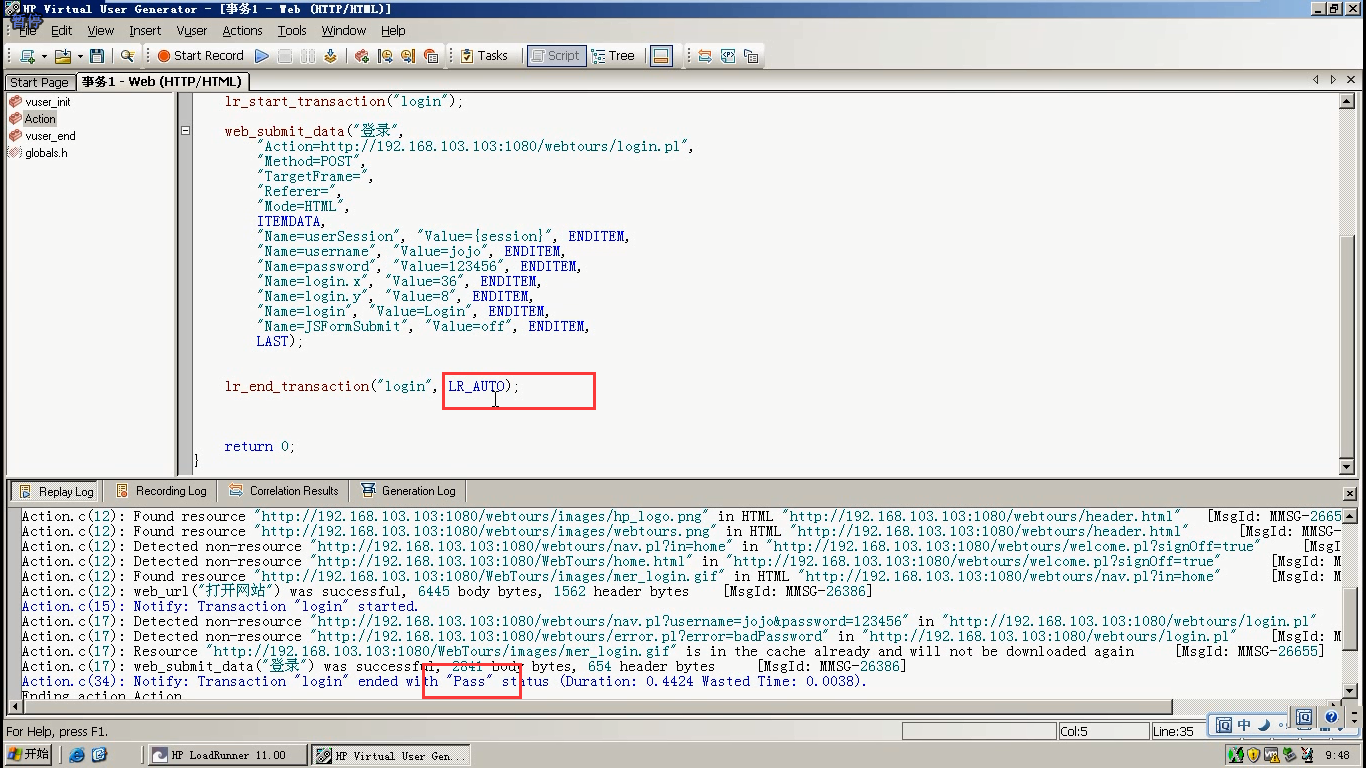
4)LR_AUTO是通过if else语句来实现的。

把a参数的定义,放在首行。

5)把LR_AUTO注释掉,用自己写的。运行,结果为PASS。和LR_AUTO运行的结果一样。
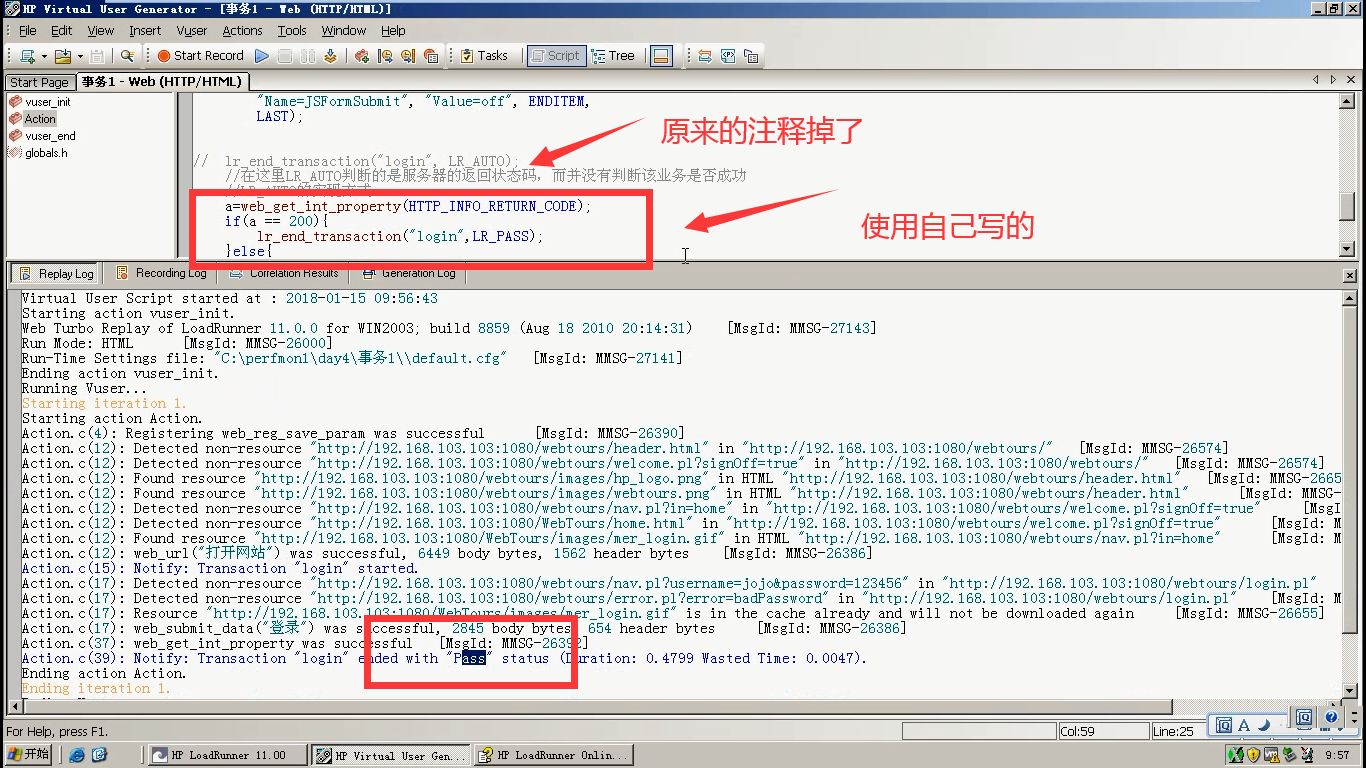
所以明显,LR_AUTO是不能帮我们判断业务的成果或者失败。
2.手工判断:
1)通过状态码判断
获取服务器http协议返回码函数
HttpRetCode = web_get_int_property(HTTP_INFO_RETURN_CODE);
判断返回码是否(这里的缩进是我自己加的,不知道对不对。)
if (HttpRetCode == 200) //lr_output_message("The script successfully accessed the discuz home page--- ----- -------------- -----------------"); lr_end_transaction("open", LR_PASS); else //输出信息到日志的函数 //lr_output_message("The script failed to access the discuz home page-------- ----- -------------- ----------------- "); lr_end_transaction("open", LR_FAIL);
2)通过检查点判断
通过web_reg_fing()函数,找到,num的个数。然后进行判断。
if(atoi(lr_eval_string("{num}"))>0) lr_end_transaction("login", LR_PASS); else lr_end_transaction("login", LR_FAIL);
1.6 函数
开始点:
lr_start_transaction("事务名")
结束点:(注意如果有一个事物,结束点的事物名称就是那个名称。如果有多个事物,事物名称,要看结束的是哪个事物。)
lr_end_transaction("事务名",事务状态)
注意: 正常情况下,事务内只存放目标请求,其他的检查点,关联,思考时间 等函数一般放在事务函数的外面
练习:iwebshop登录并检查验证
2.检查点(检查业务是否成功)
这个时候,就可以通过检查点的方式,来验证业务是否成功。如果存在要检查的内容,那么就给一状态LR_PASS。否则给LR_FAIL。
2.1 作用:检查请求触发的业务有没有真正成功
2.2 函数
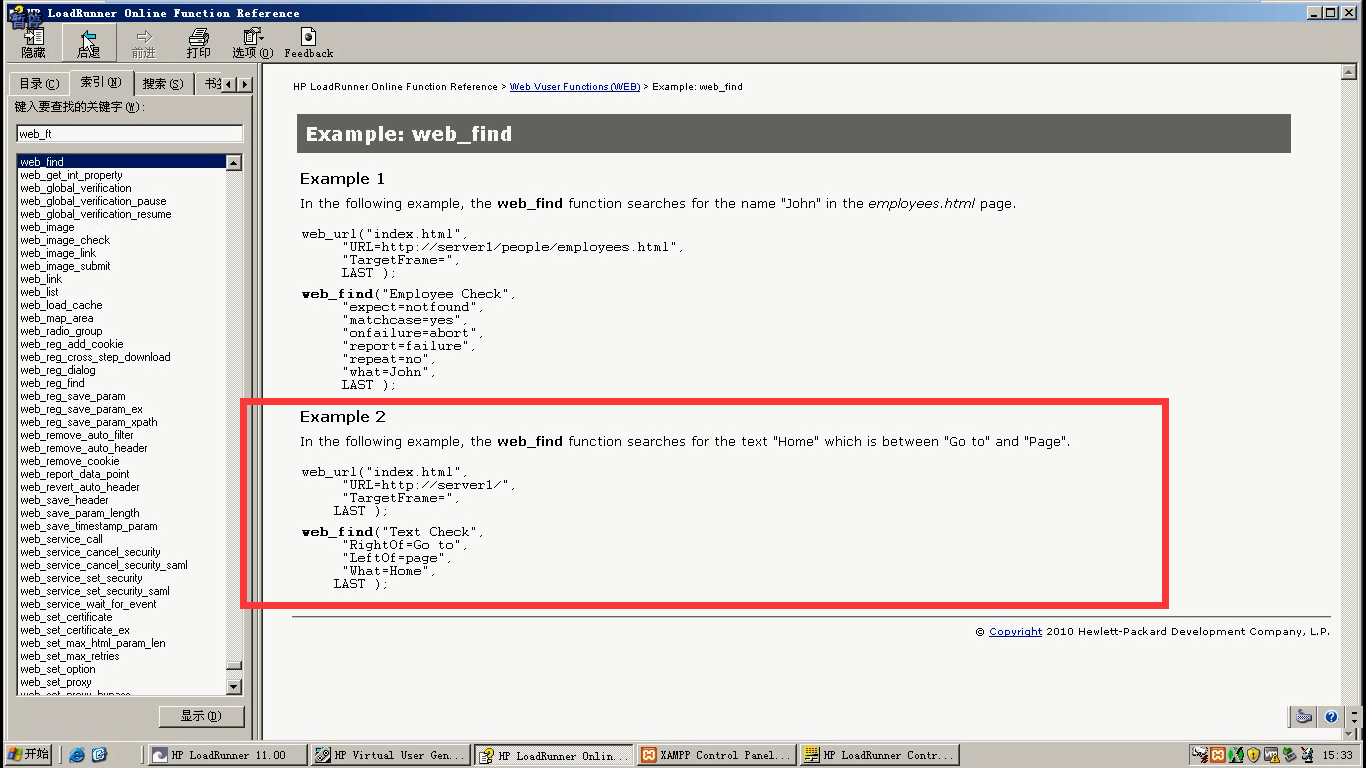
1)文本检查
web_find与web_reg_find区别
- 1、 这两个函数函数类型不同,web_find是普通函数,web_reg_find 是注册函数;
- 2、 web_find 使用时必须开启内容检查选项,而web_reg_find 则不没有此限制;
- 3、web_find 只能用在基于HTML模式录制的脚本中,而web_reg_find 没有此限制;
- (如果选URL_based script。是不能用web_find函数。)
- 4、web_find 是在返回的页面中进行内容查找,web_reg_find 是在响应中进行查找;
- 5、web_find 在执行效率上不如web_reg_find (因为先有响应数据,然后浏览器再渲染。);
- 6 、文本检查的时候:一般都使用web_reg_find函数
普通检查点函数
web_find()
注册型检查点函数
web_reg_find()
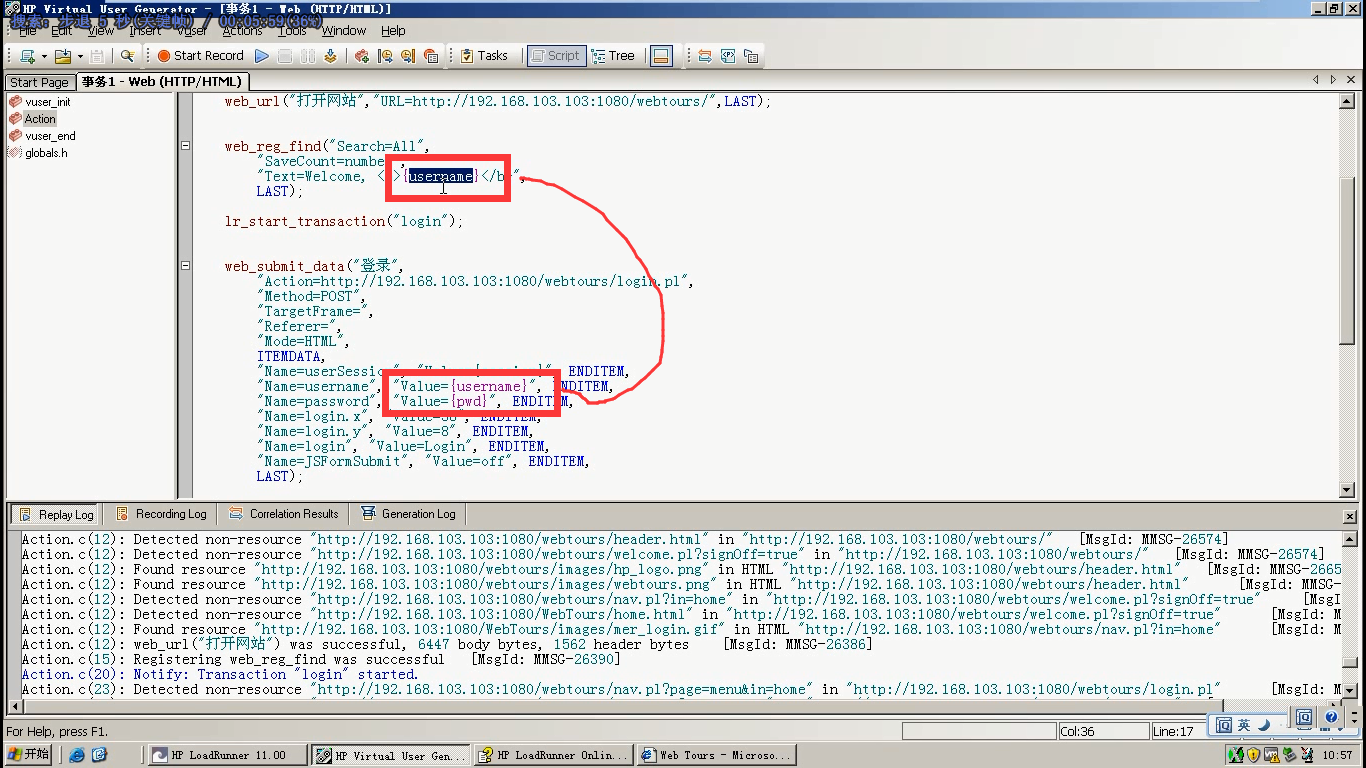
"Text=Welcome, <b>jojo</b>", 查找的字符串
"Search=Body", 查找范围
"SaveCount=num", 查找到的次数保存的参数名
LAST);
2)图片检查(同样要开始:图片文件检查相内容。)
web_image_check()
通过Alt属性
通过Src属性
例:web_reg_find()
带有reg的为注册型函数。特点:如果某一请求的响应数据中有想要的数据,那么就将该函数放在请求前面。
判断返回页面,有没有welcome jojo。(但是这里是浏览器解析后的样子。我们需要通过抓包工具,查看返回给我们原始的数据。)
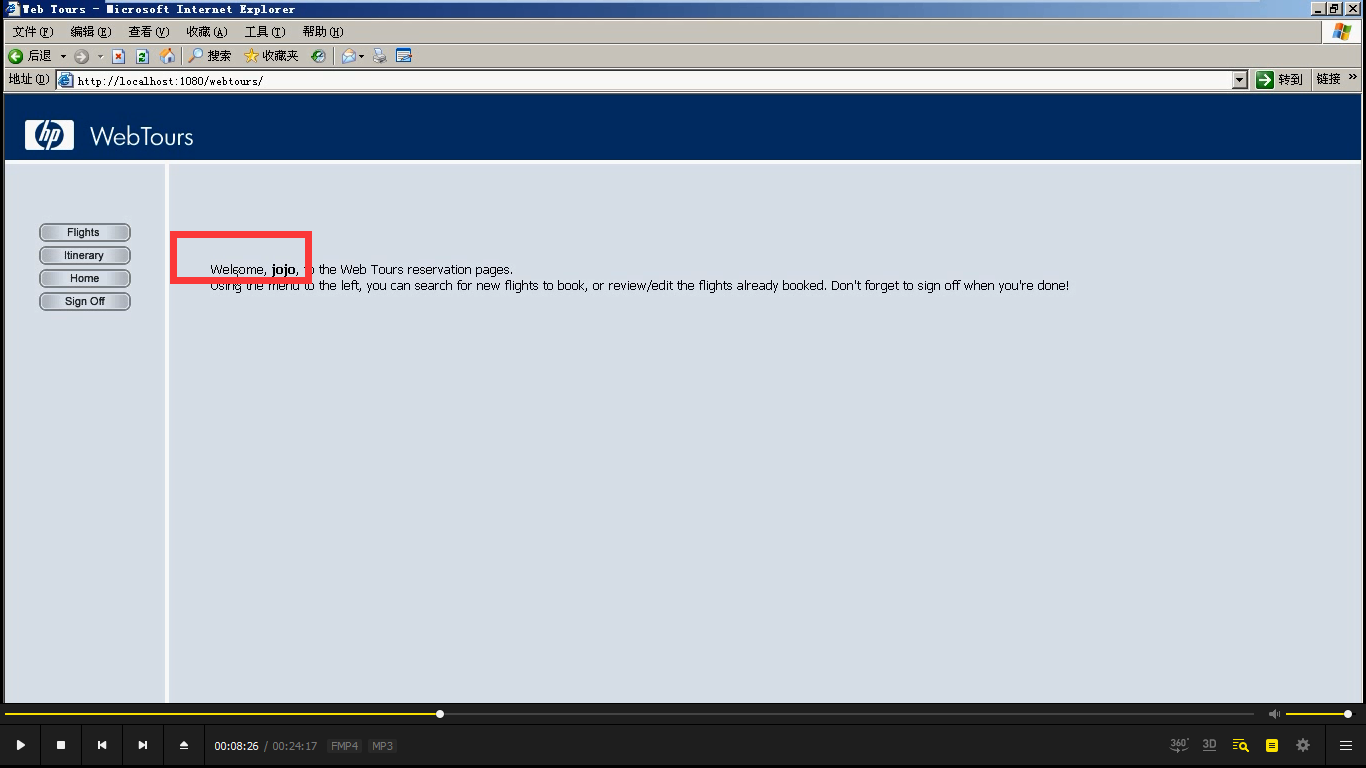
先通过抓包工具查看返回数据
1.数据过滤一下:点击filters---ip-----Run Filterset now(保存一下)
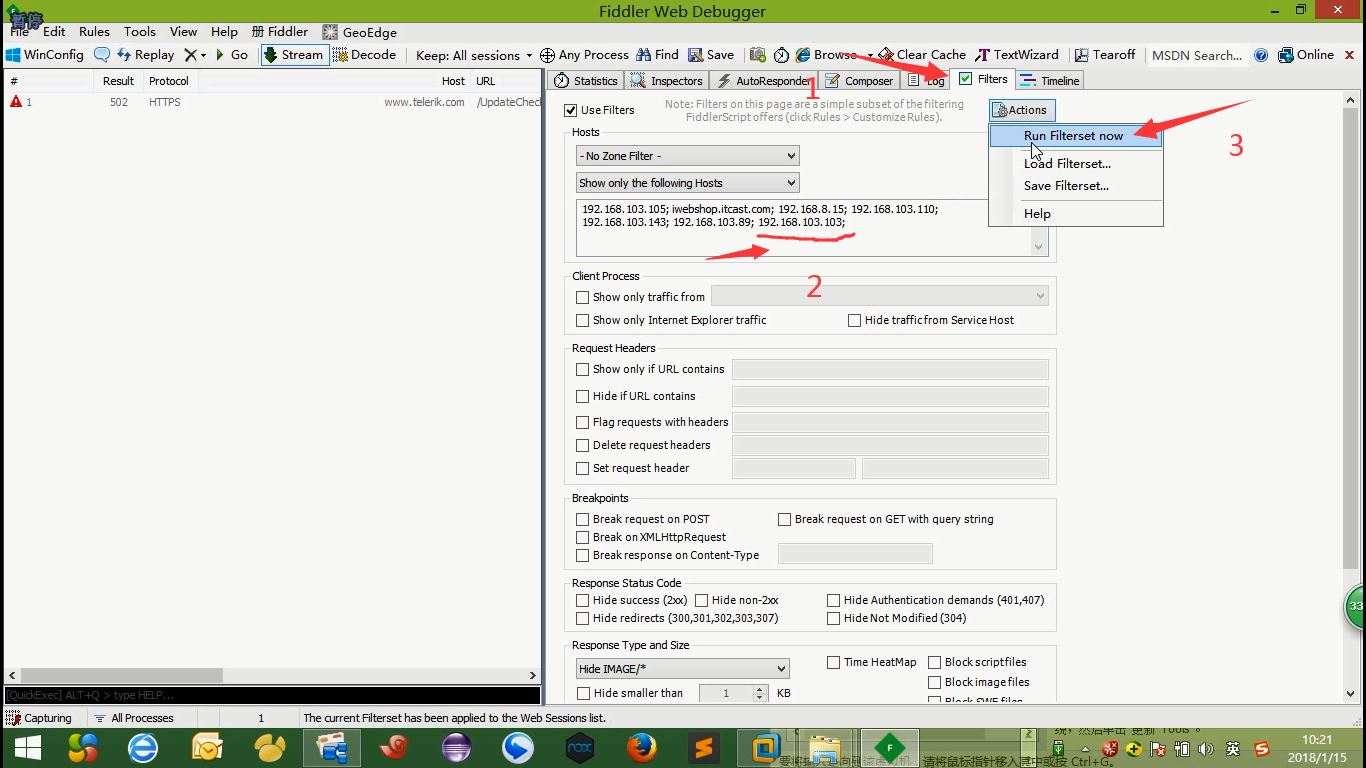
2.清除一下数据:Remove all
3.打开一个浏览器
4.输入要访问的url地址。可以Remove all再一次清除一下数据。刷新一下该网站
5.输入用户名,密码,登陆。这里打开页面的url编号目前是到3。
6.登陆url里面没有我们要的数据。但是有2个资源请求,是登陆后触发的后两个url的地址。
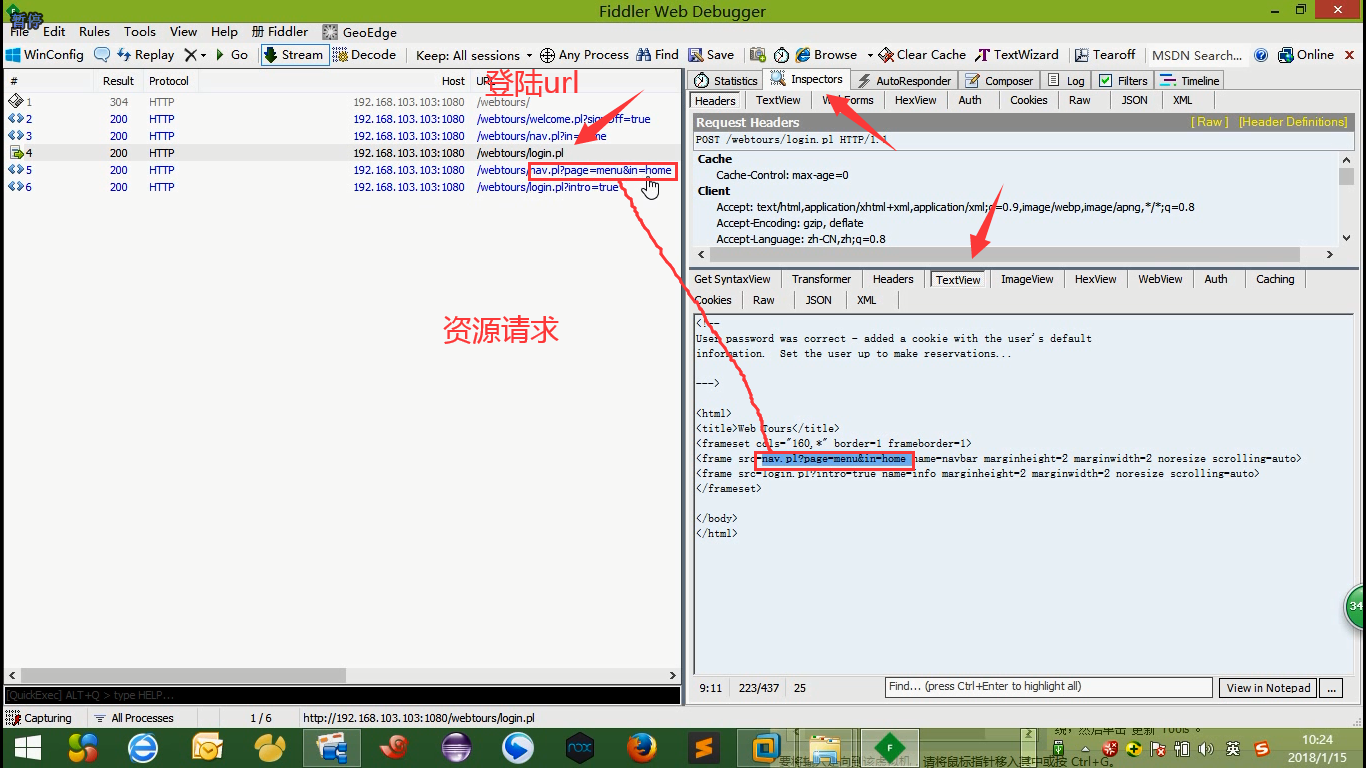
7.在两个url里面我们都搜一下:Welcome。发现第二个url里面有我们要的数据。
注意:我们以后也都是判断的是响应数据,而不是页面。
8.就判断响应数据有没有这个内容就可以了。先copy一下。
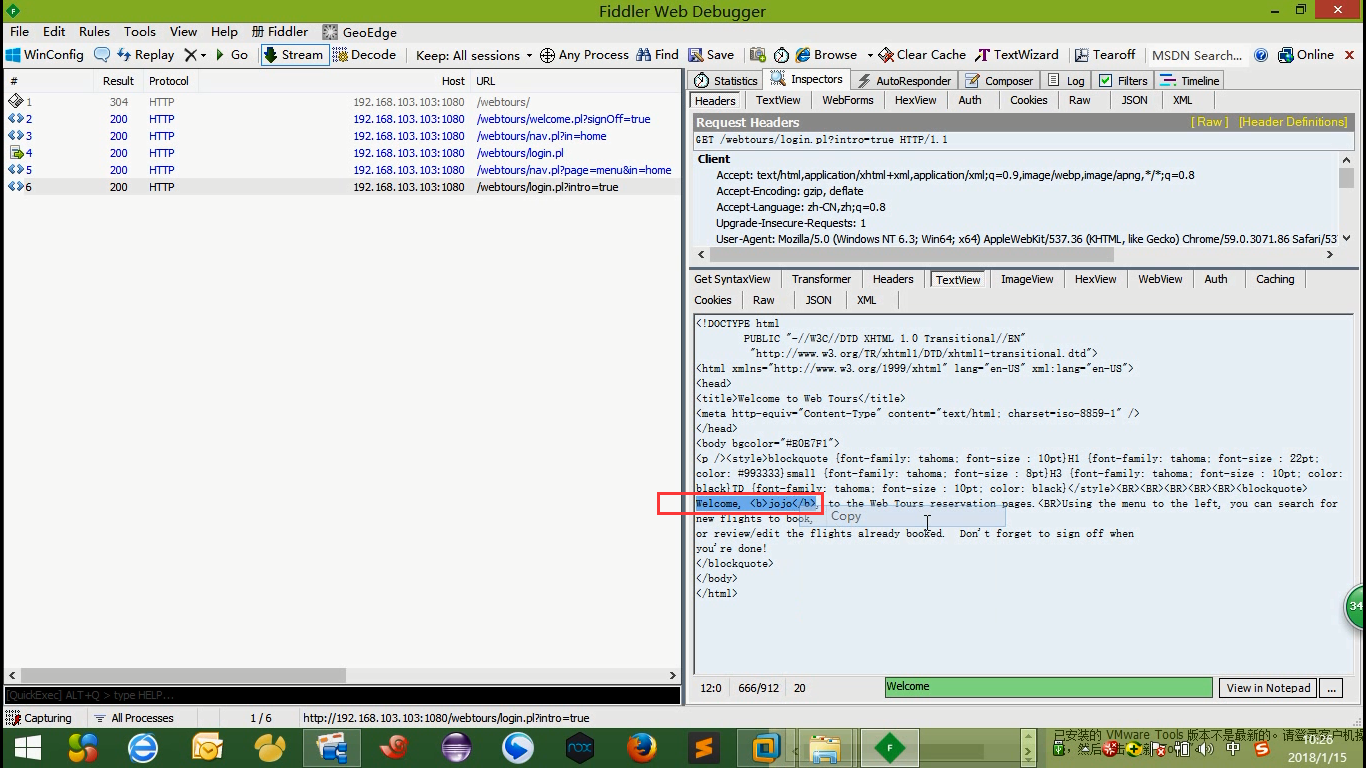
1)插入web_reg_find()函数。注意这个函数是在web_submit前面。但是不能放在事物开始函数的后面。(因为那样事物统计时间就更不准了。)但是可以放在事物开始函数的前面。web_reg_find()
函数自动忽略事物函数。

2)按照如下操作,点击ok
Search for specific Text:搜索的数据(刚才拷贝的)
Search in:ALL(整个响应数据里找)
Save count(保存次数):number(找到这个元素所对应的次数保存在number的参数里面)
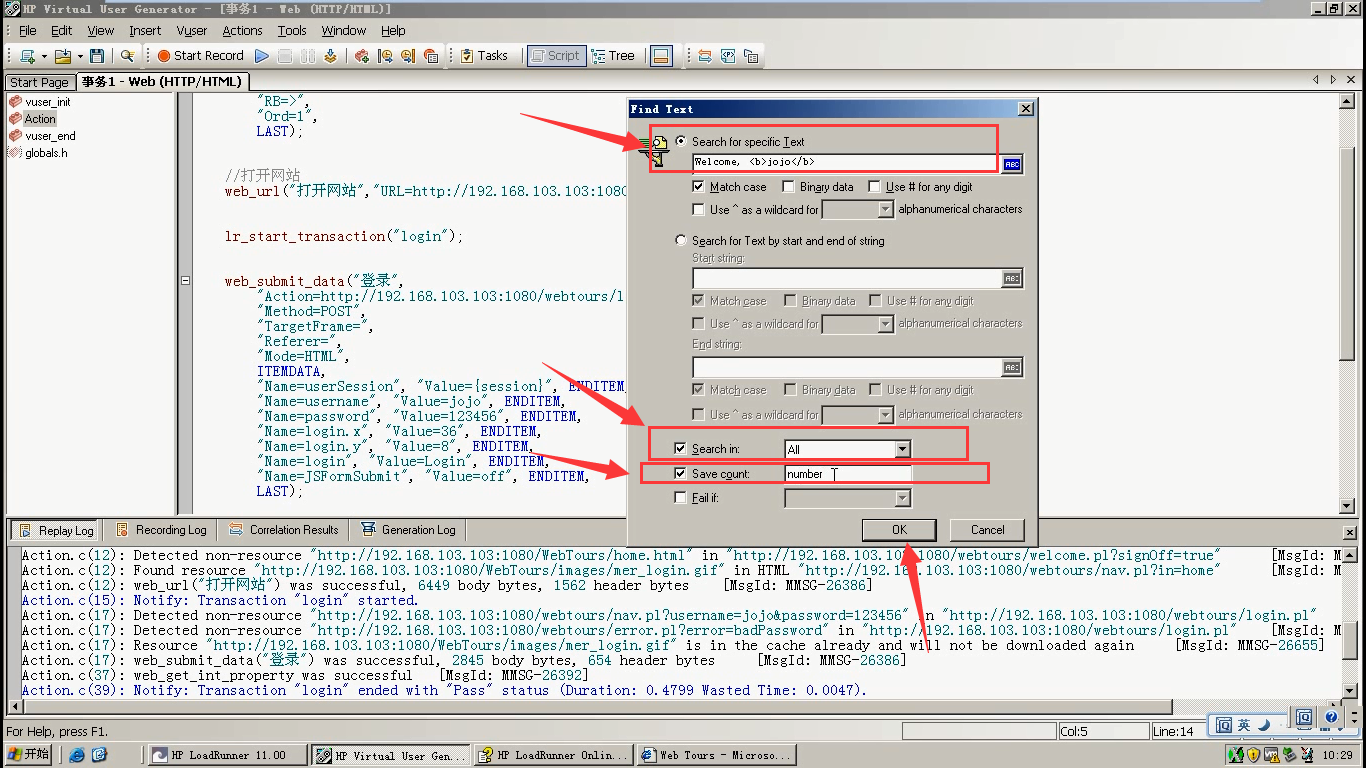
3)检查点函数就生成了。

4)加一个判断,注意用atoi把字符串转换为整数。

5)运行,还是错误的密码。日志显示失败,说明业务没有成功。
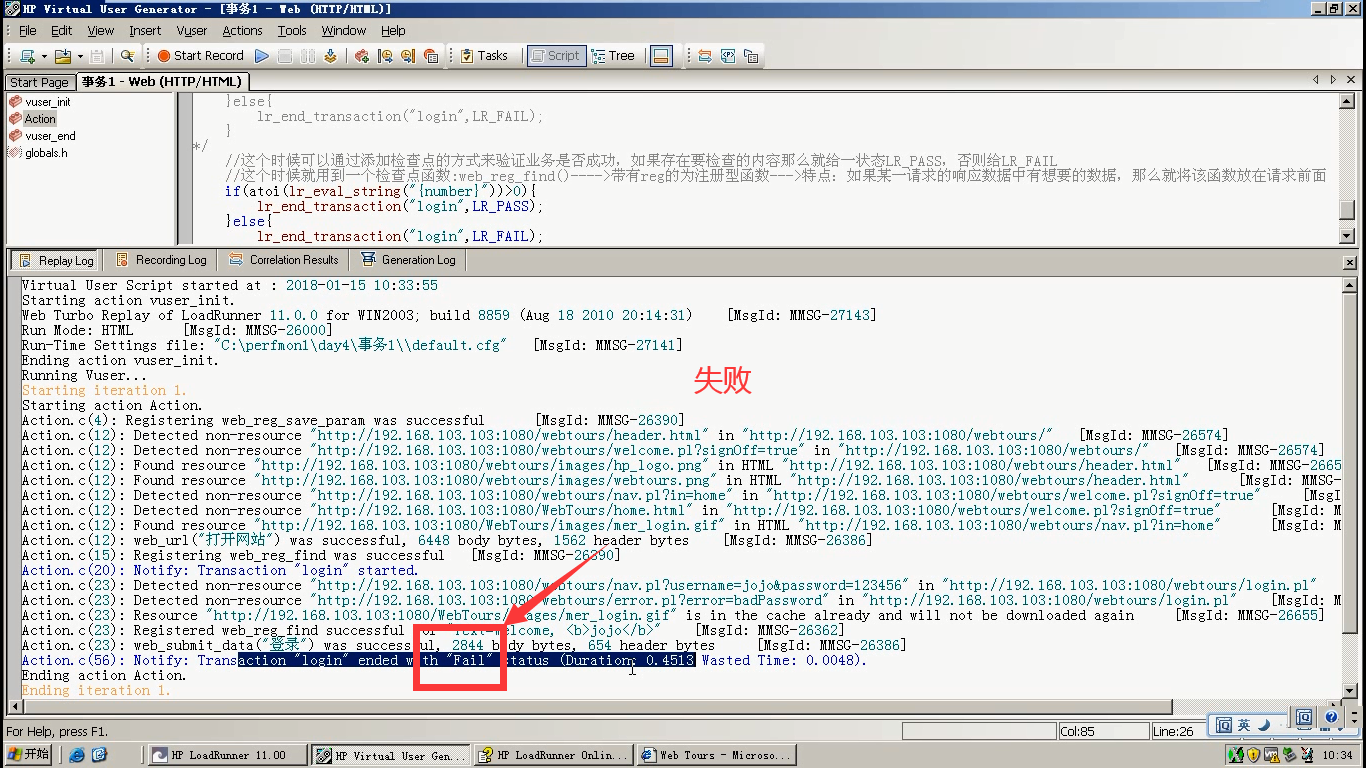
6)改成正确的用户名和密码,运行。显示成功。
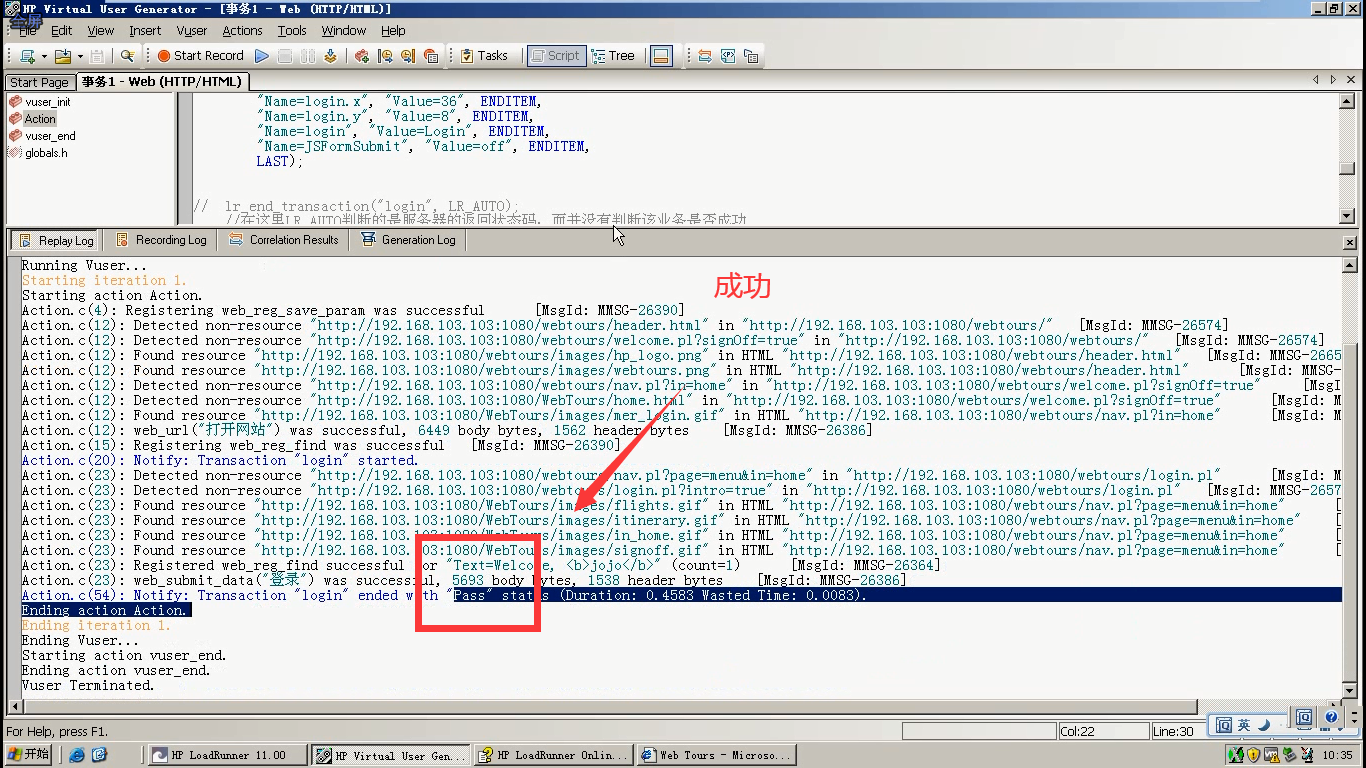
注意:以后写开始事物,结束事物。最好都要写一下检查点函数,判断业务有没有成功。
如果想偷懒:
代码采用录的方式。可以,但是,录的是请求页面的数据(web_submit_form),不是响应数据(web_submit_data)。我们要在响应数据里面找。所以说,要改一下模式。
第一种:选择URL-based script
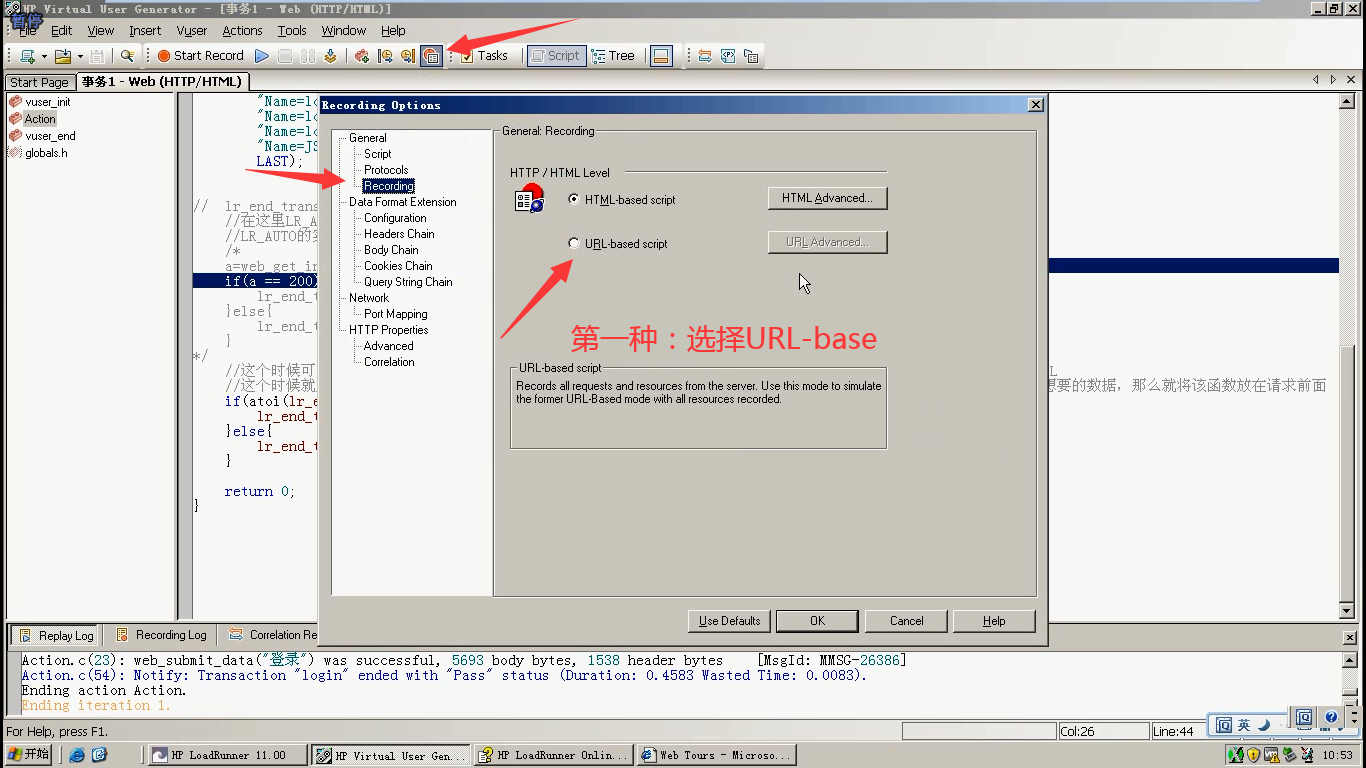
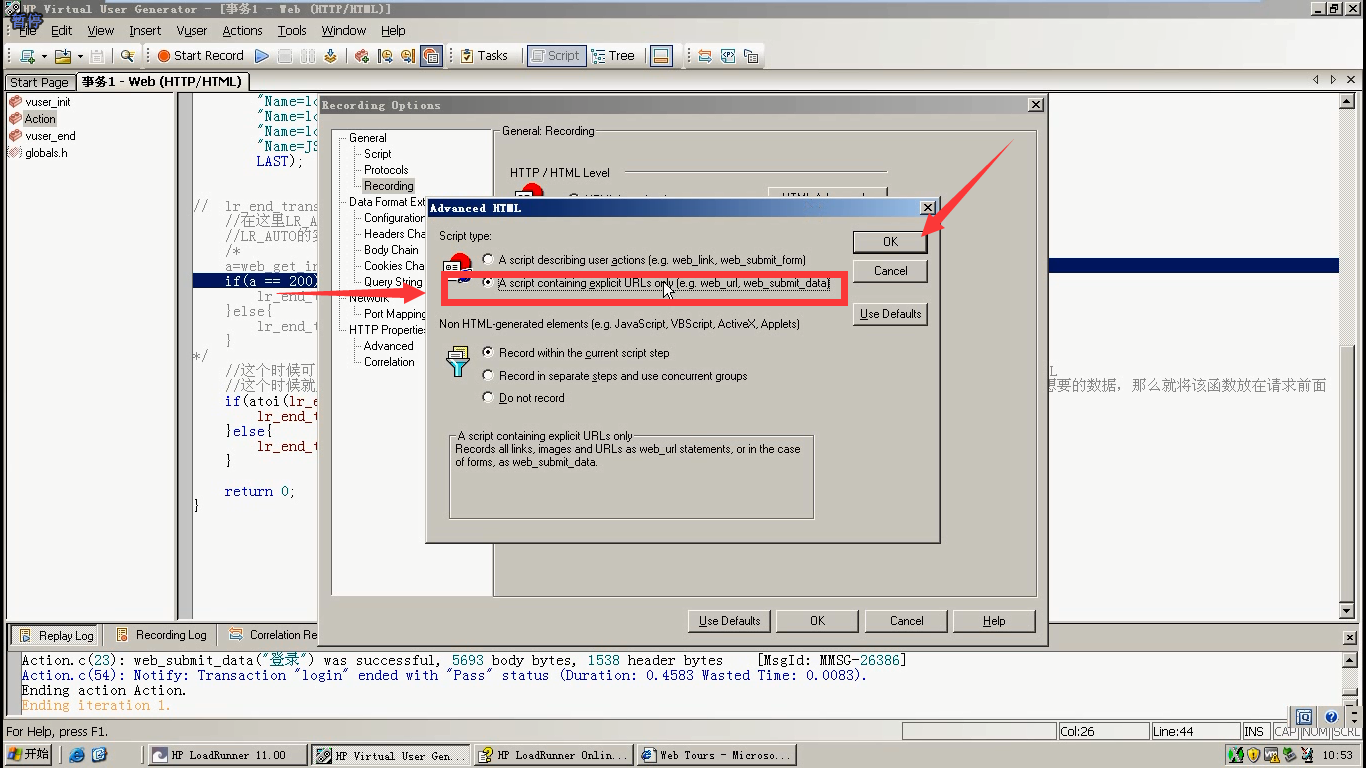
第二种:选择HTML-based script---点击HTML advaced----选择红色框框的。点击ok
例2:如果参数化名字和密码。检查点也该替换掉。
1)先把jojo参数化。
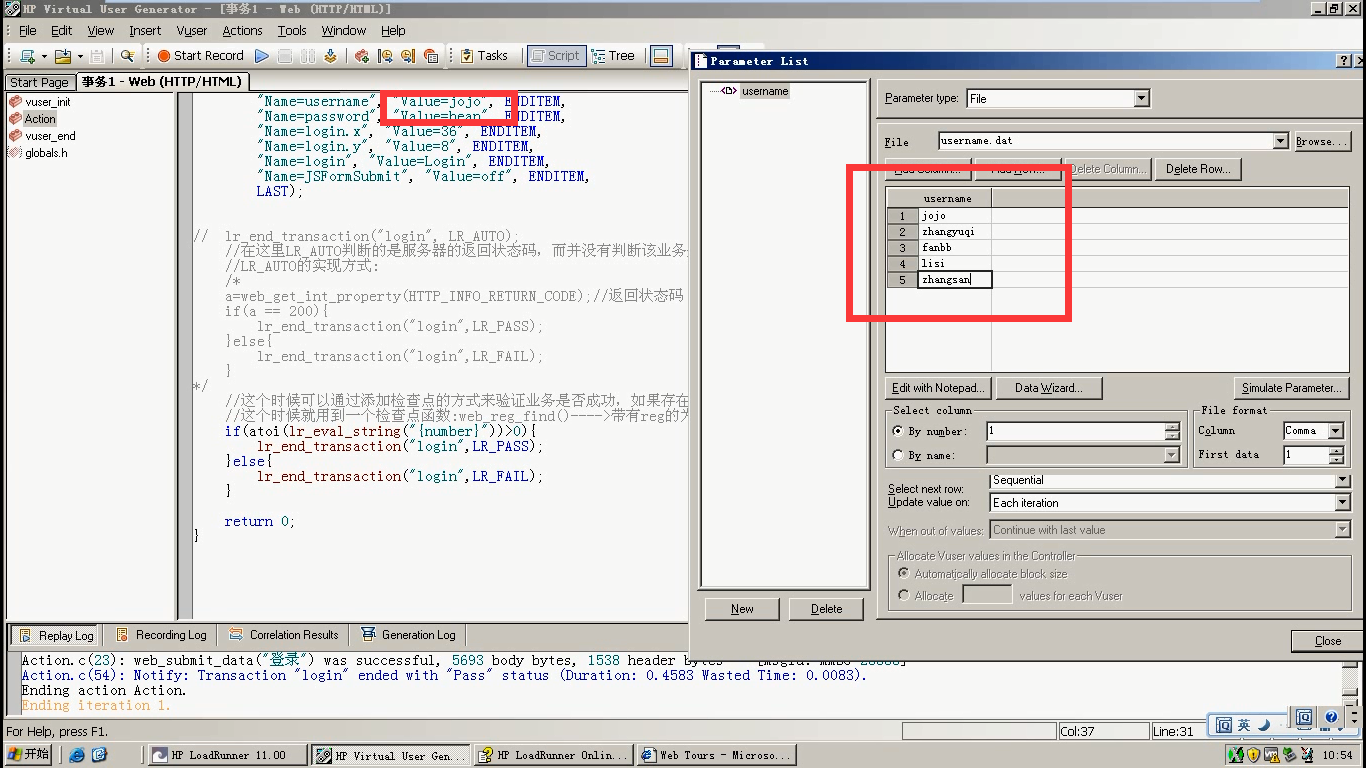
2)把jojo替换掉
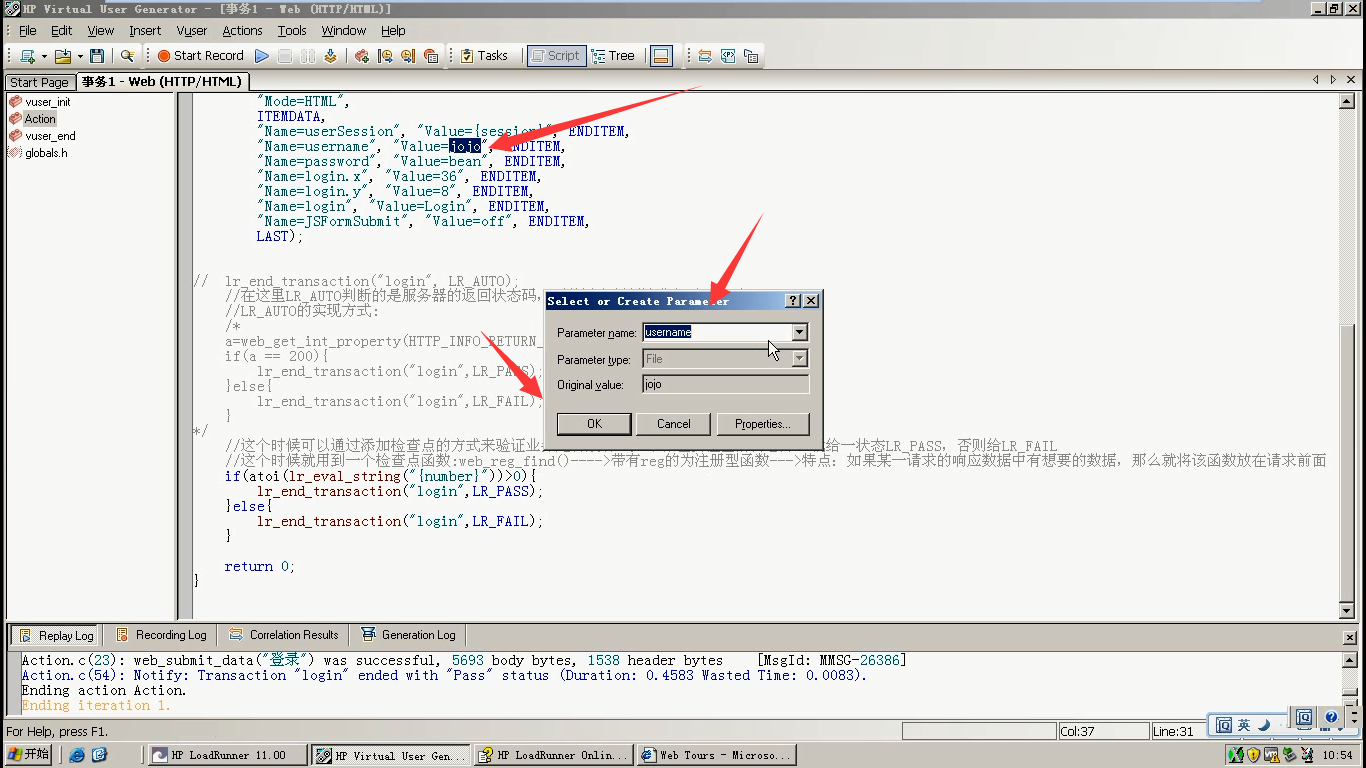
3)把密码也参数化掉
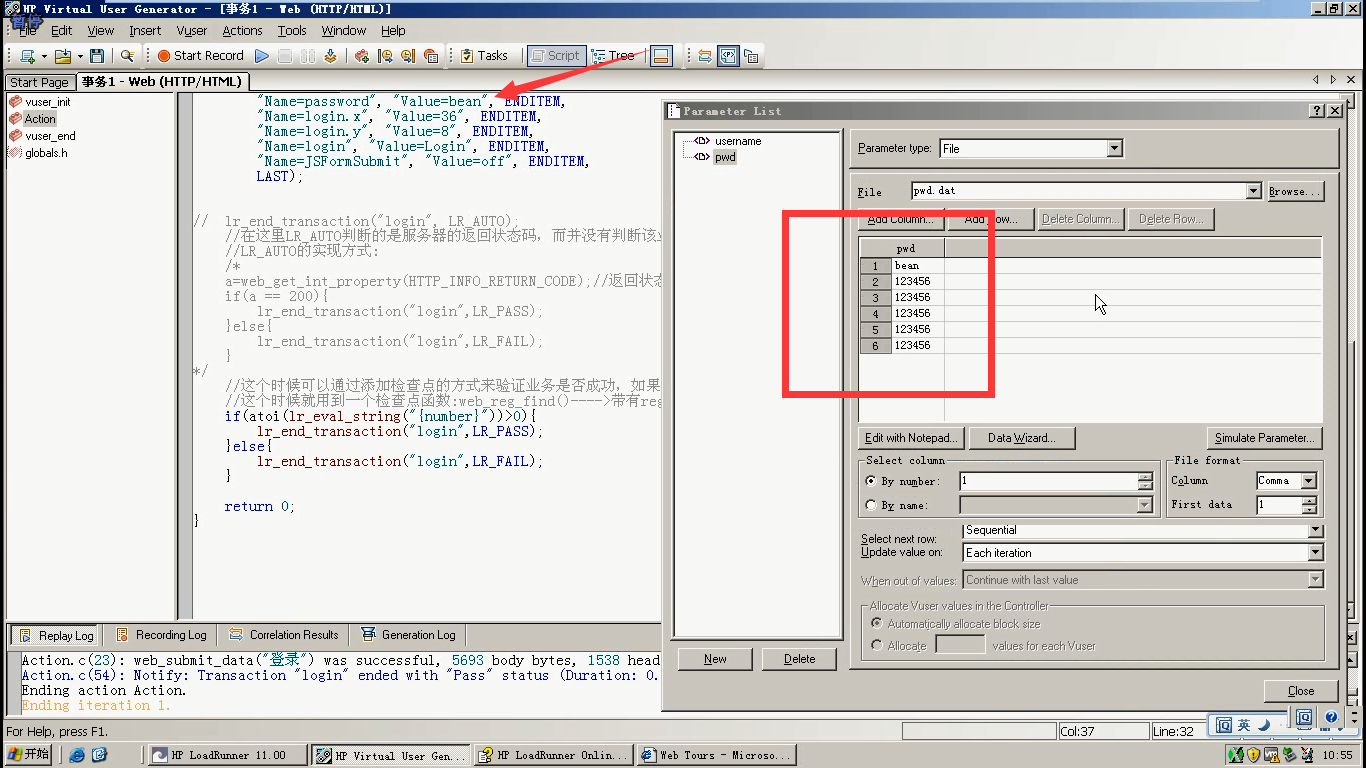
4)把密码替换掉
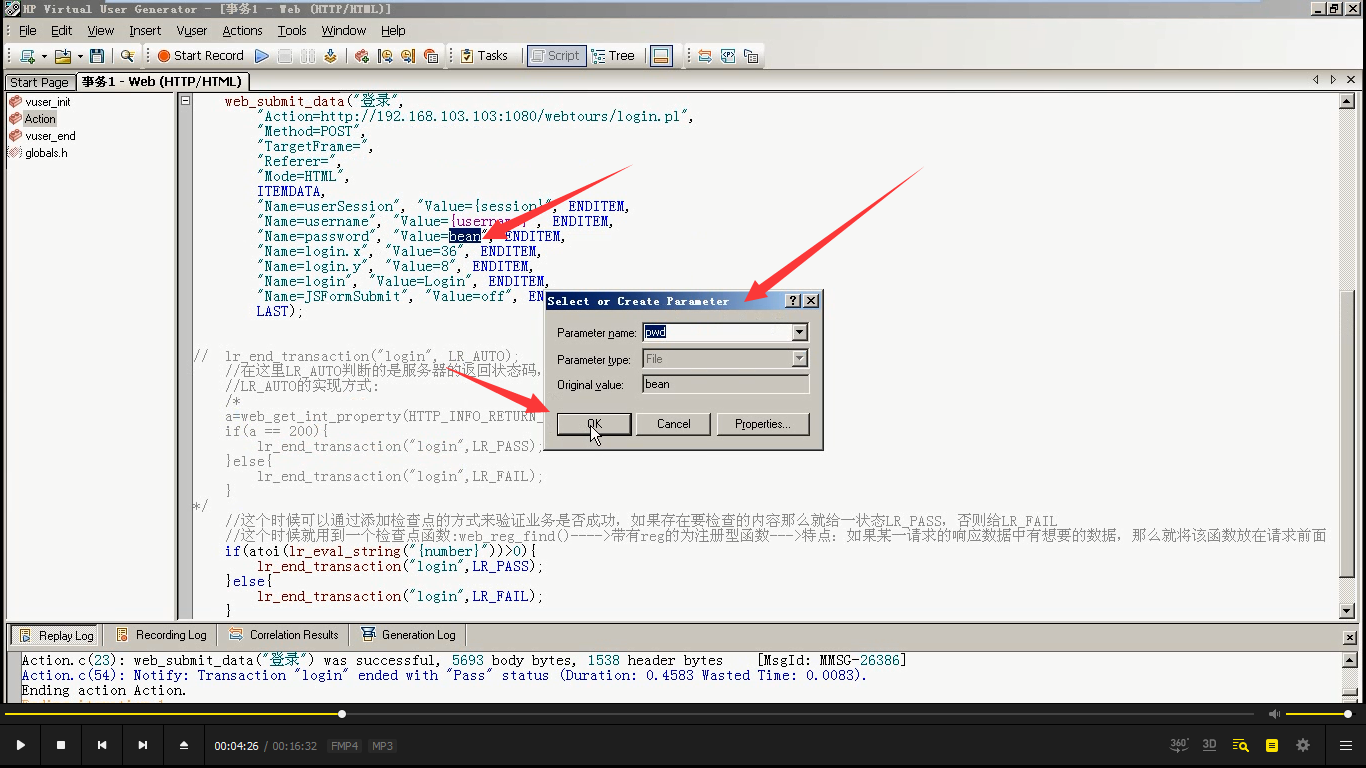
5)检查点函数的名字也要替换:{username}
6)5次迭代
7)运行,查看日志:全都pass(因为账号和密码全都是对的)
例3:统计成功和失败率(需要多用户)
1)多加一些数据。先注册一些用户,点击sign off

2)密码可以设置123456(一共注册10个)
3)一共10个用户名。可以用notepad添加,最后留一个空行。

10个密码,改成有2个错误密码。
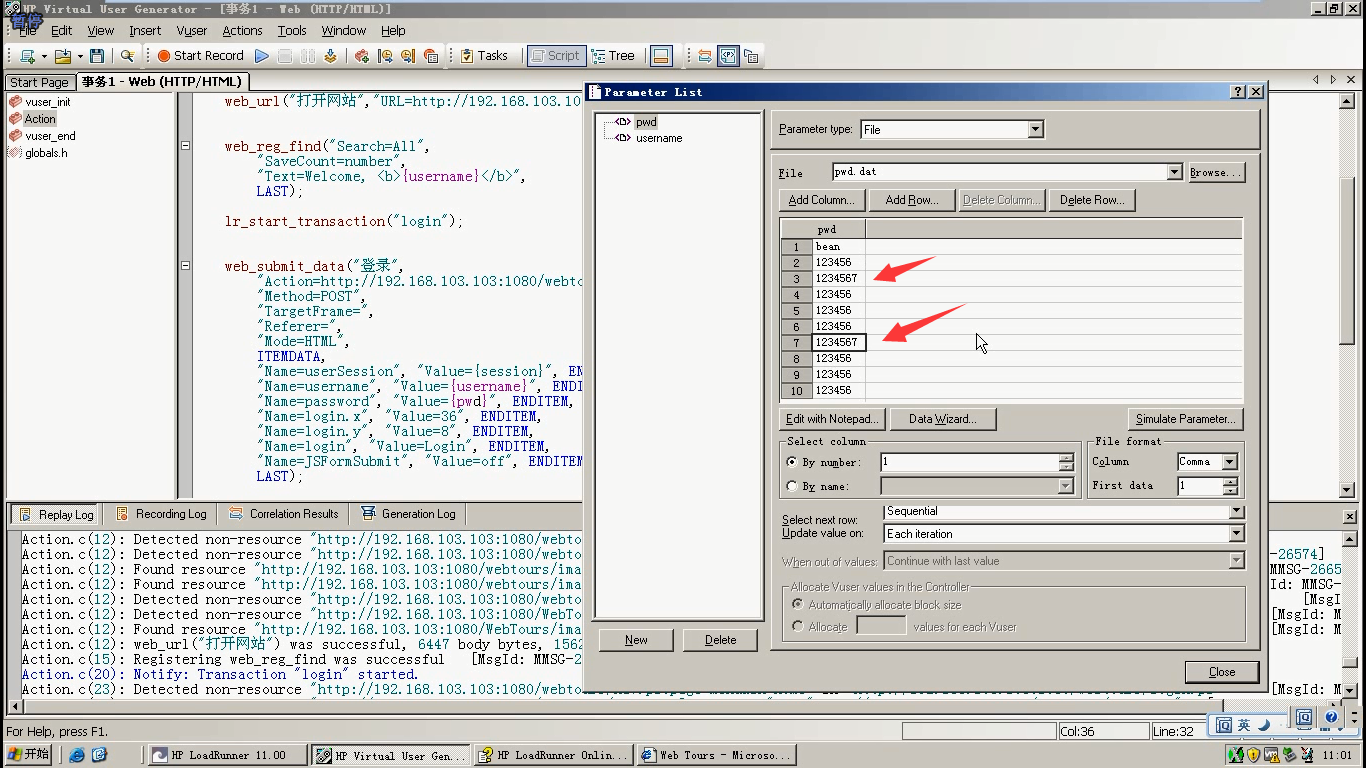
4)file---save保存一下先。关闭浏览器
5)打开controller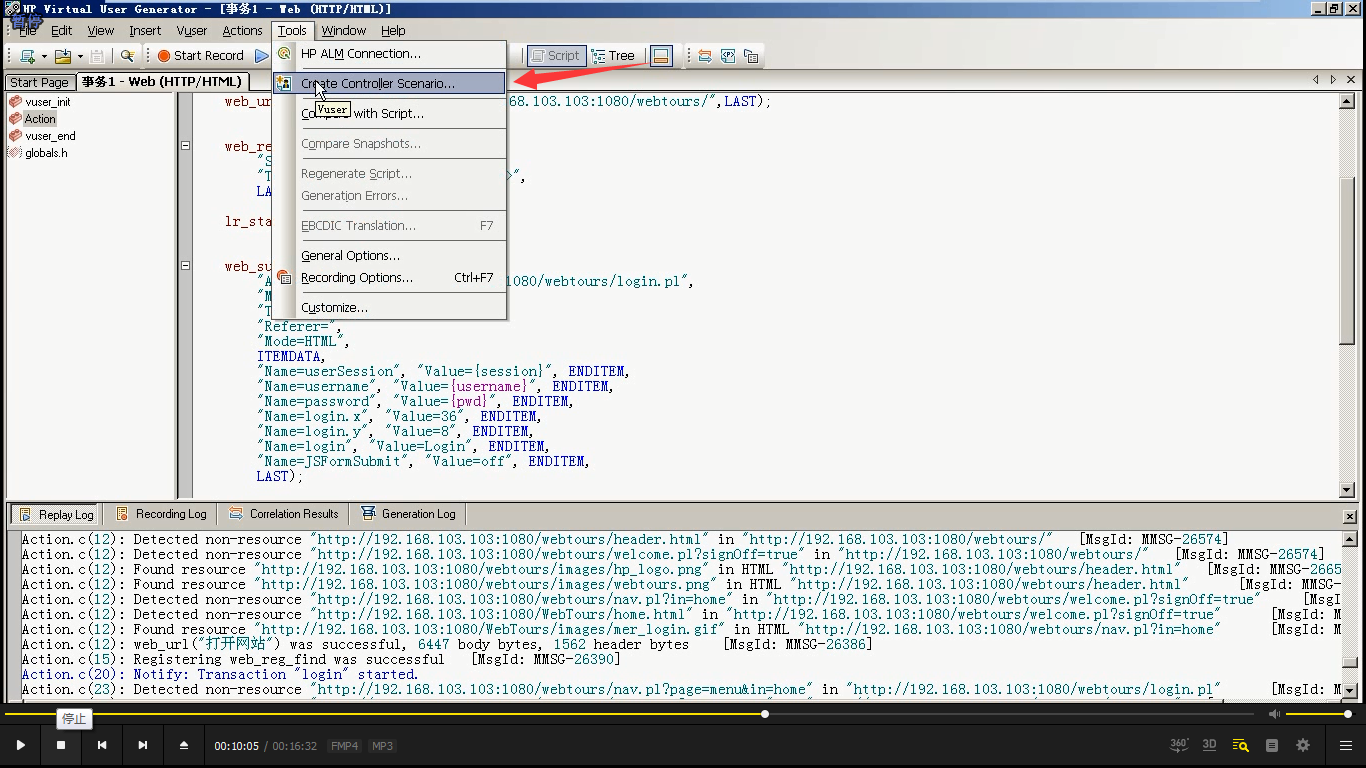
6)用户10个。这个LR是破解100个。不能超过这个值。要想要更多用户,可以找网上破解的。
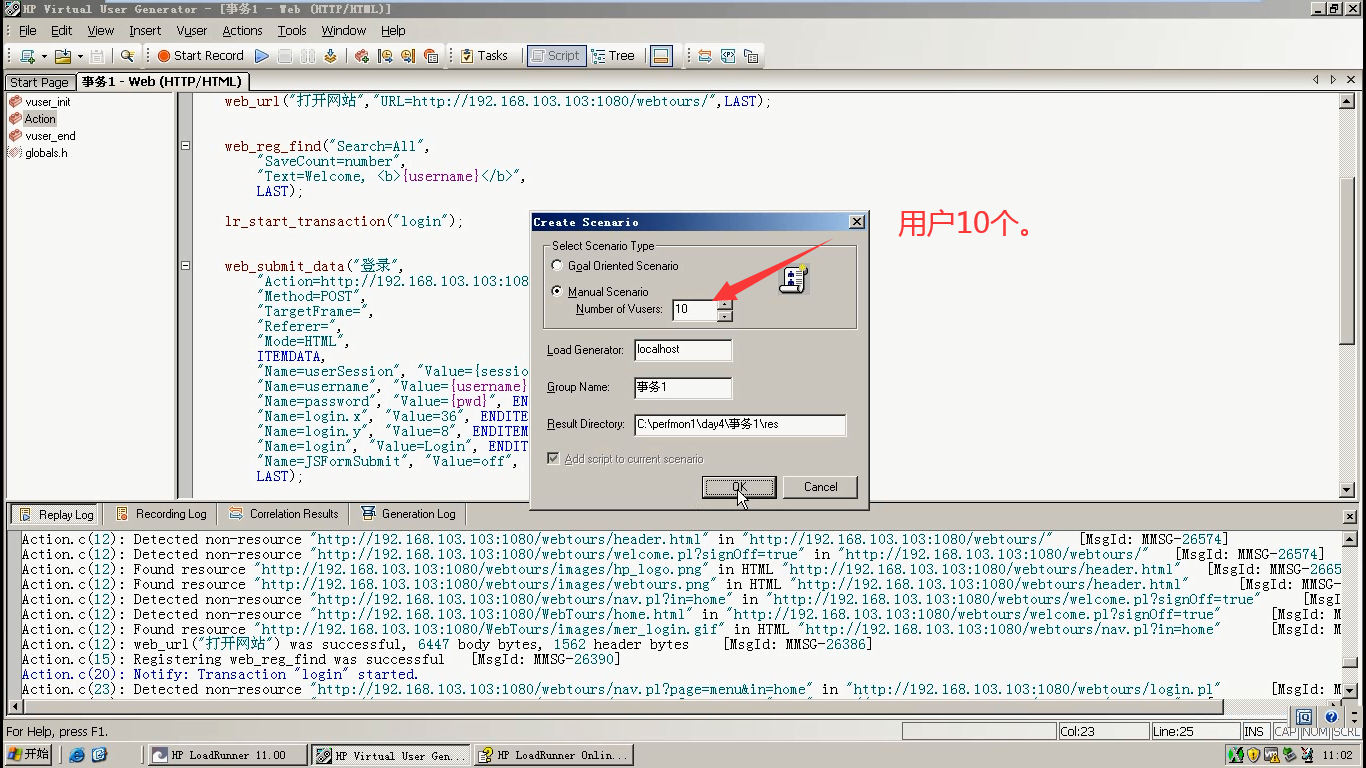
7)按如下操作

8)选择最基本的,持续时间2分钟。
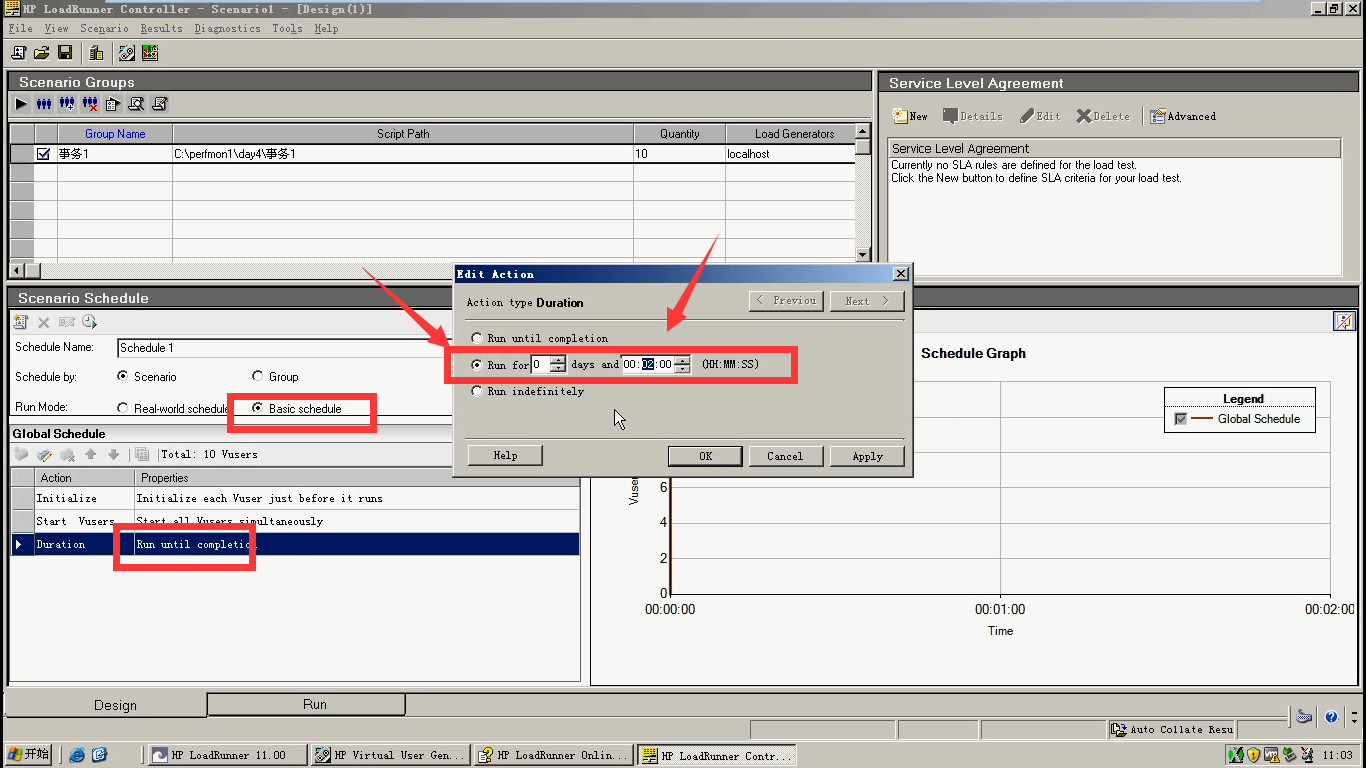
9)运行,点击是。等待2分钟。通过成功:286,失败:71。一般成功率保证在99%,98%,左右。
成功率:286/(286+71)=80%
失败率:71/(286+71)=19%
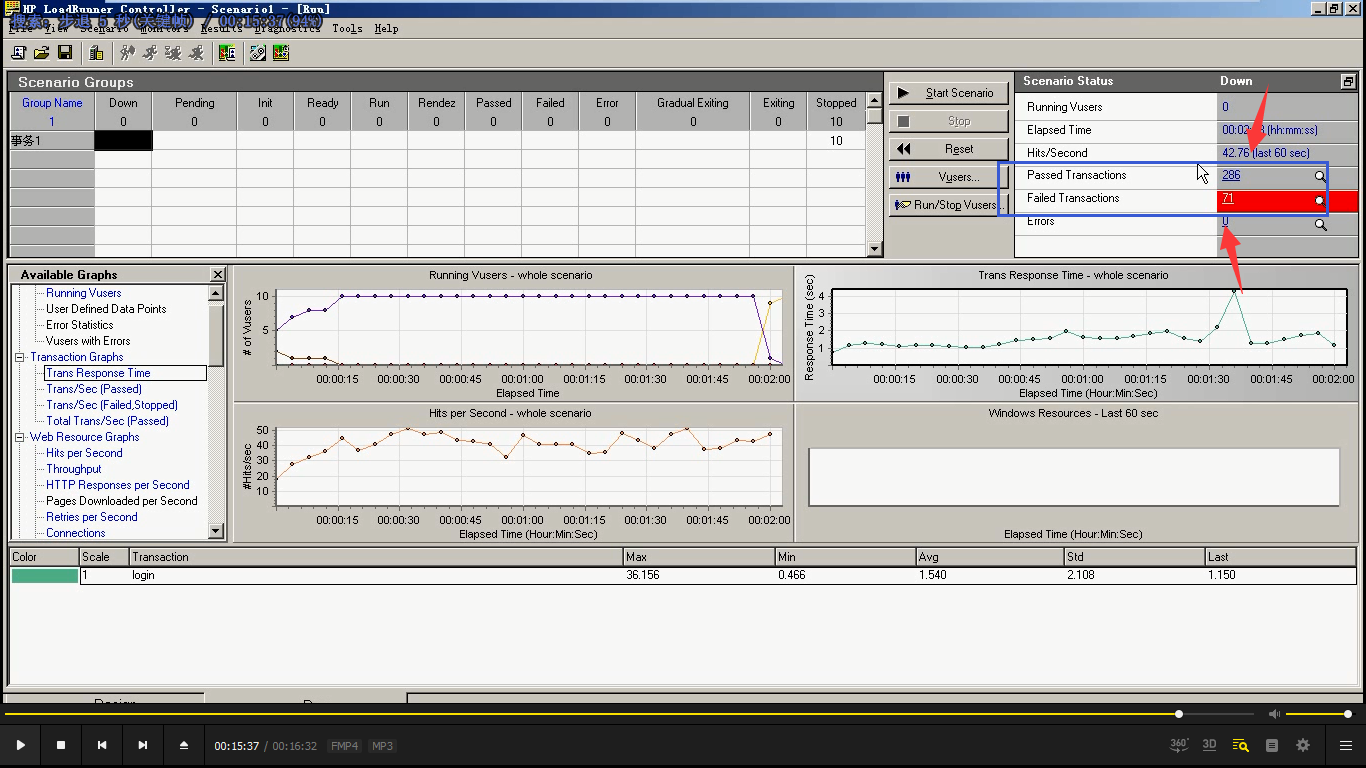
关闭的时候,点击切换到,取消掉就可以了。
例:web_find()函数
对于web_find函数,必须启用图片和文本检查:Enable Image and Text check(勾上)。才能执行web_find函数。
不带reg的函数,我们称普通函数。注册型函数,必须放在那个请求函数前面。普通函数,只要按照逻辑往下写。
web_find函数不好:
1.因为检查的是页面的内容,因为页面内容。有可能是浏览器导致的原因。
2.不能结合事物来用,因为web_find函数不能取出,像web_reg_find函数取出的num参数来使用。
要求:在登陆后,判断有没有welcome jojo。
1)在登陆函数以后做的检查。web_find()放在结束事物后面。

2)插入web_find()函数
3)搜索:web_find。出现Text Check(文本检查),点击ok。
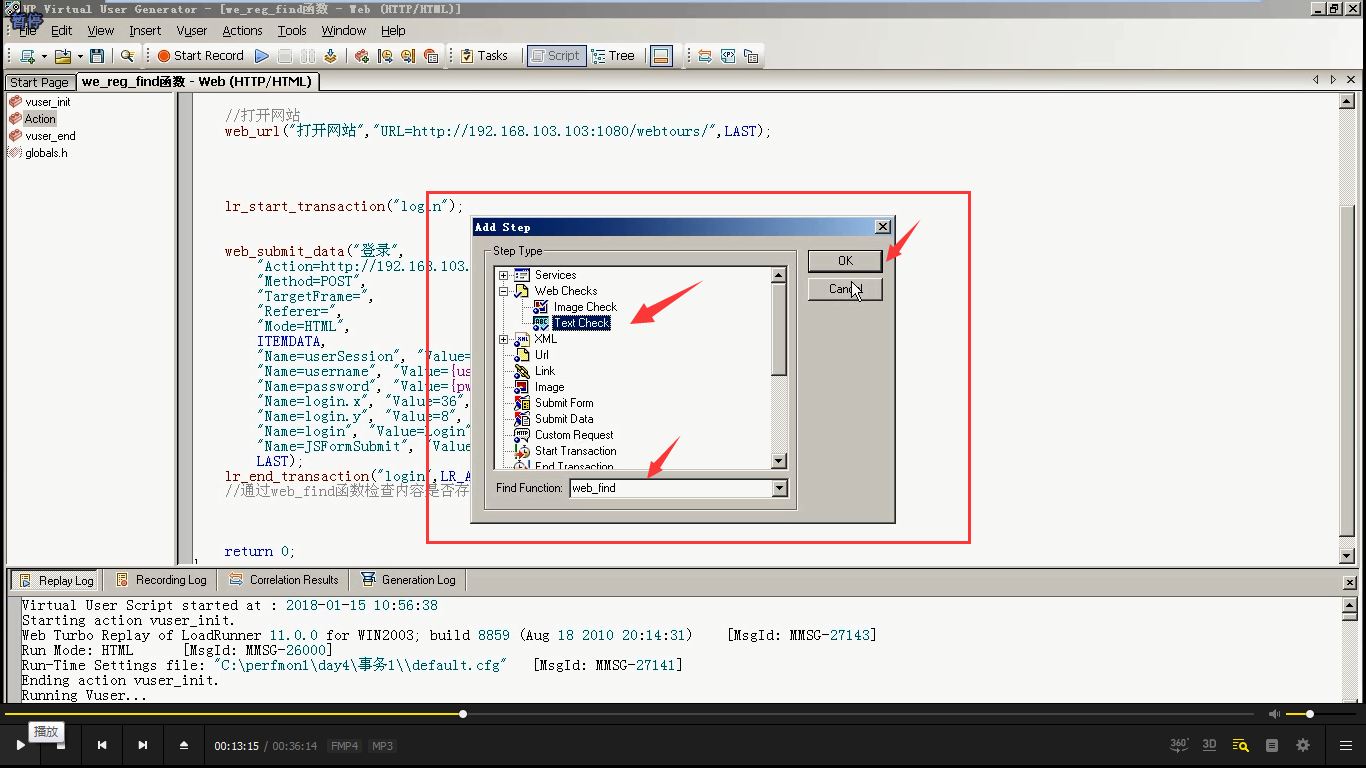
4)页面上welcome jojo 是我们想检查的内容。(web_find()函数检查的是页面,而不是响应数据。),直接复制welcome jojo。左边为:空,右边为:, (是一个逗号)
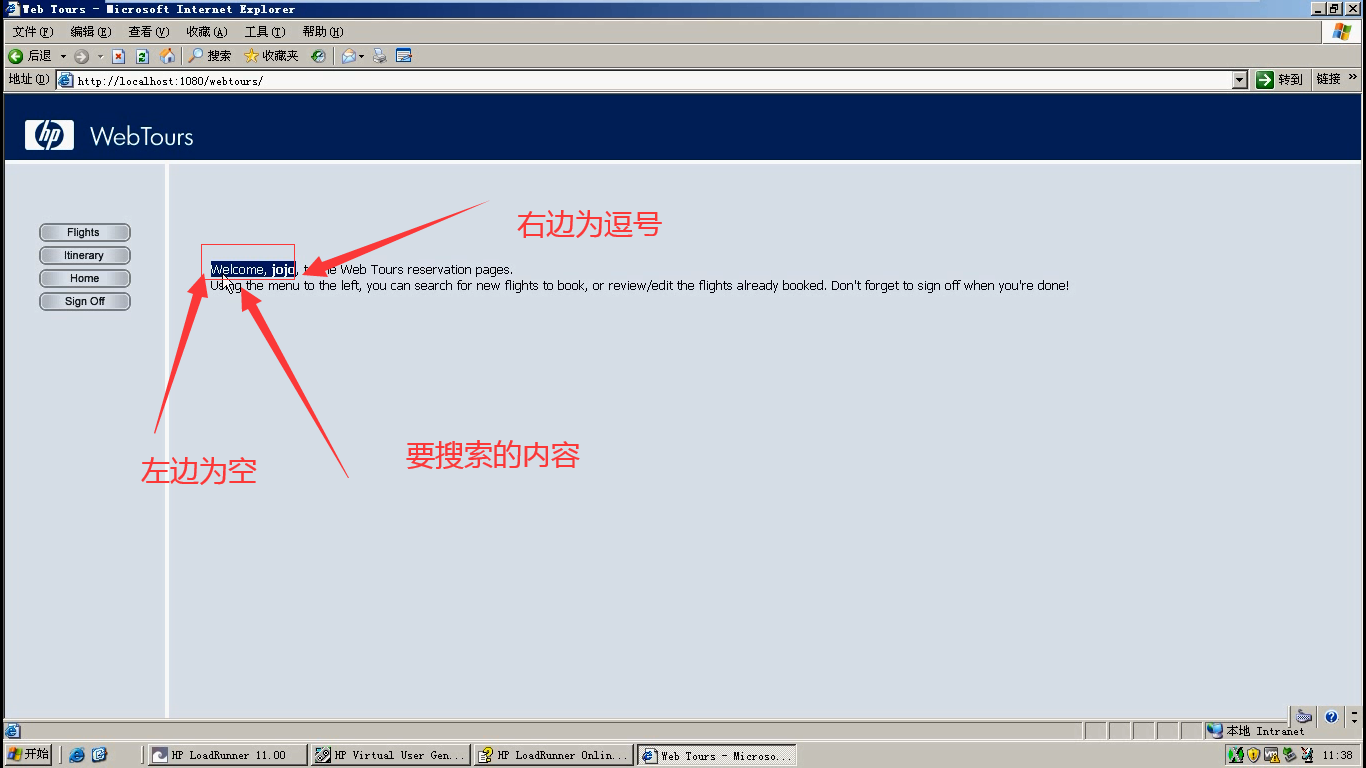
5)按如下操作。选择Specification
Search for(搜索内容) :这里不是响应内容,而是页面。
Right of(这里是左边,没有看错,是左边):不勾。
Left of(右边):, (是一个英文逗号)
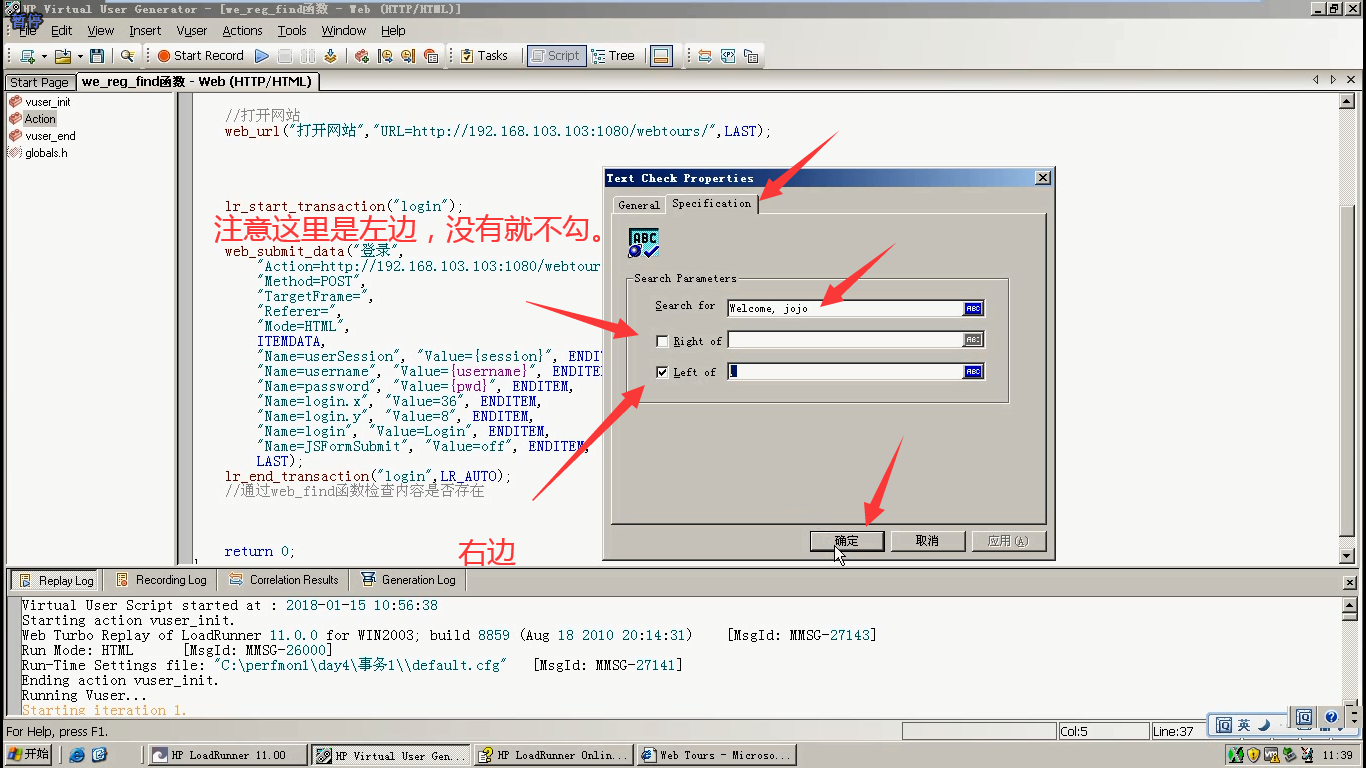
6)web_find()函数就出现。把用户名,密码还原回去。
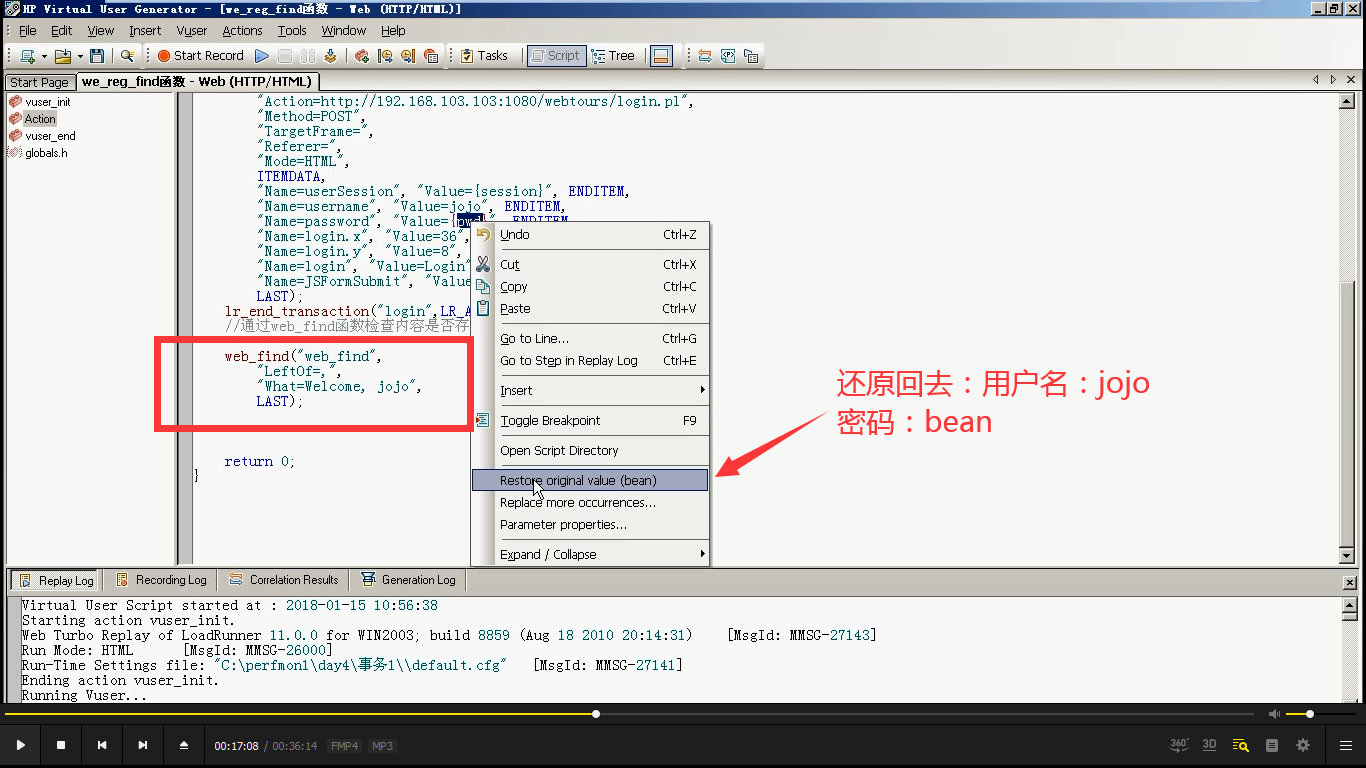
7)点击运行,没有红色报错。说明是ok的。
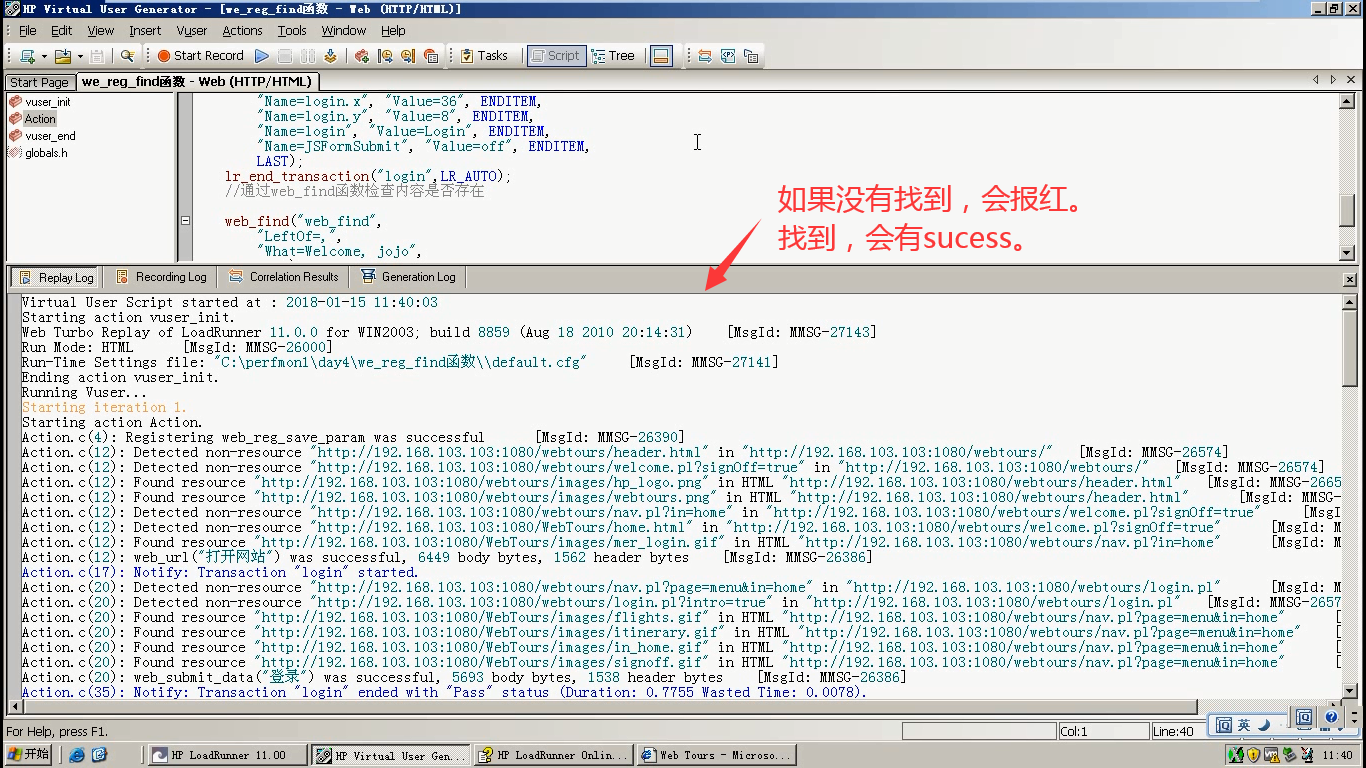
8)迭代:1次
9)随便改一下搜索内容。
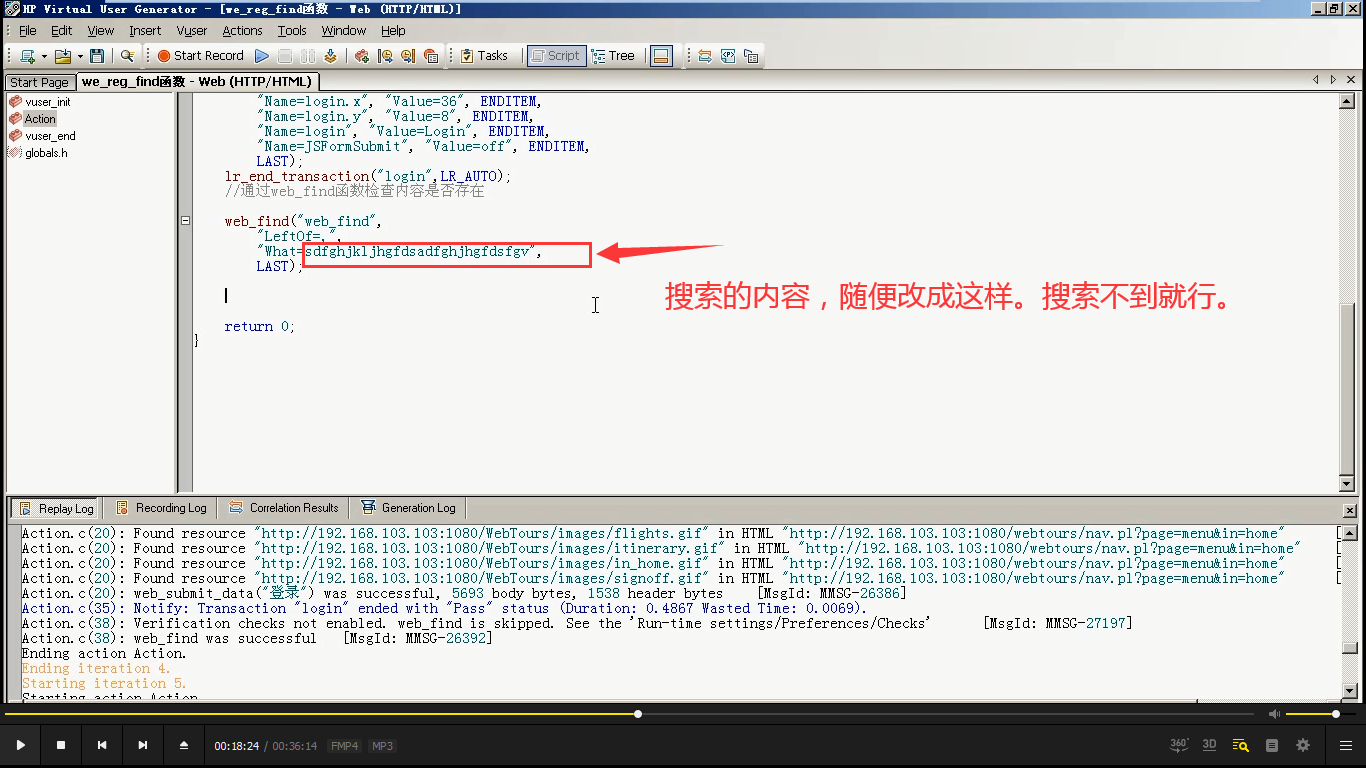
10)点击运行,应该会报错,因为没有检查到内容。但是为什么就是不报错?因为web_find()函数没启用,被忽略掉了。
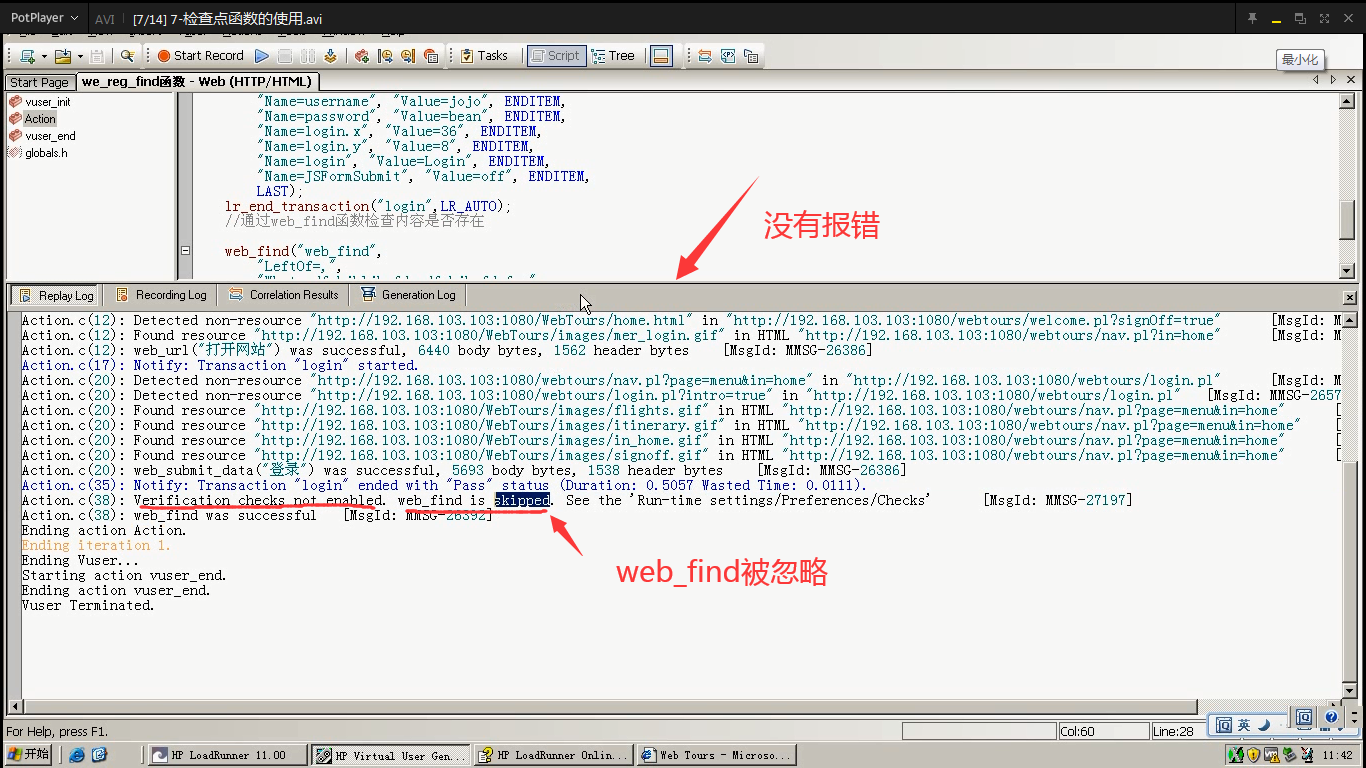
11)运行设置
12)Preferences-------Enable Image and Text check(勾上)-----点击ok
对于web_find函数,必须启用图片和文本检查:Enable Image and Text check(勾上)
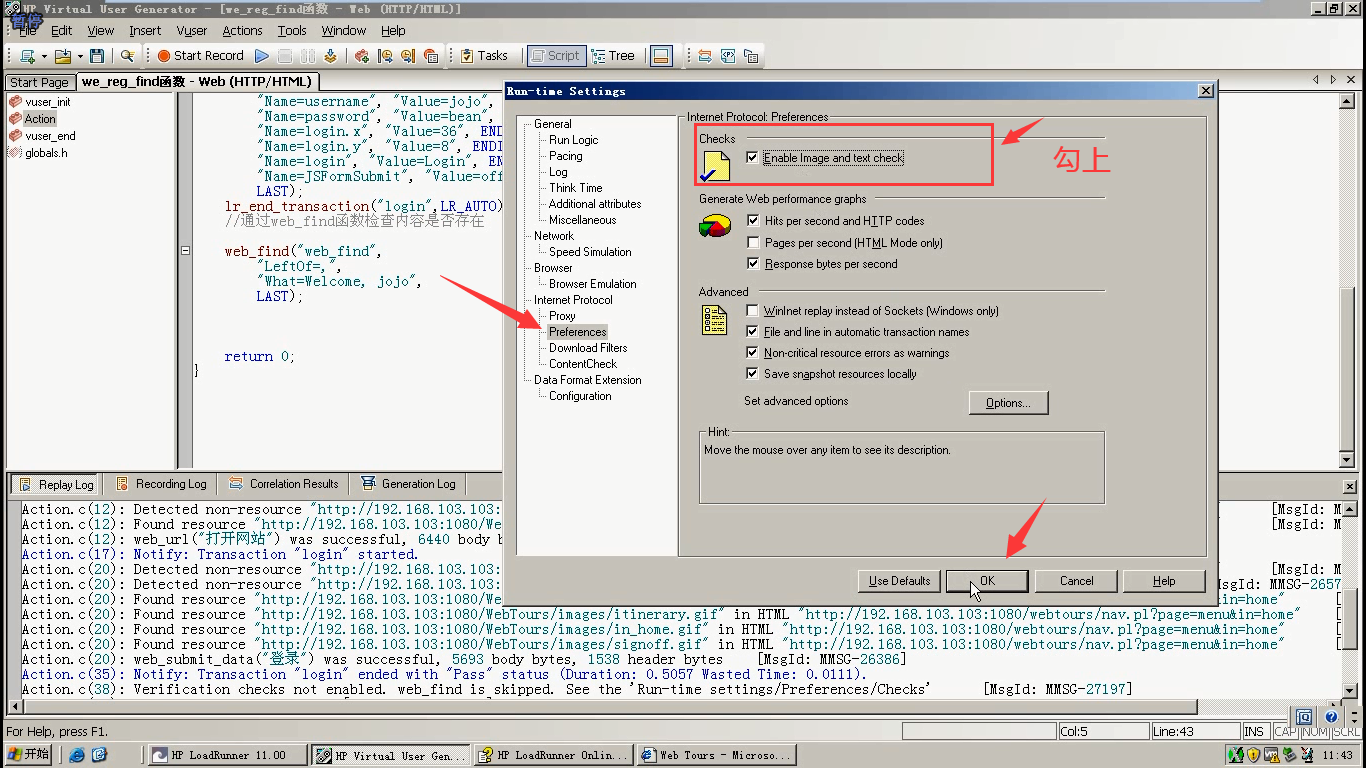
13)点击运行,报错了,找到0个这样的东西。

14)改成正确的,点击运行。Success,找到一个这样的。
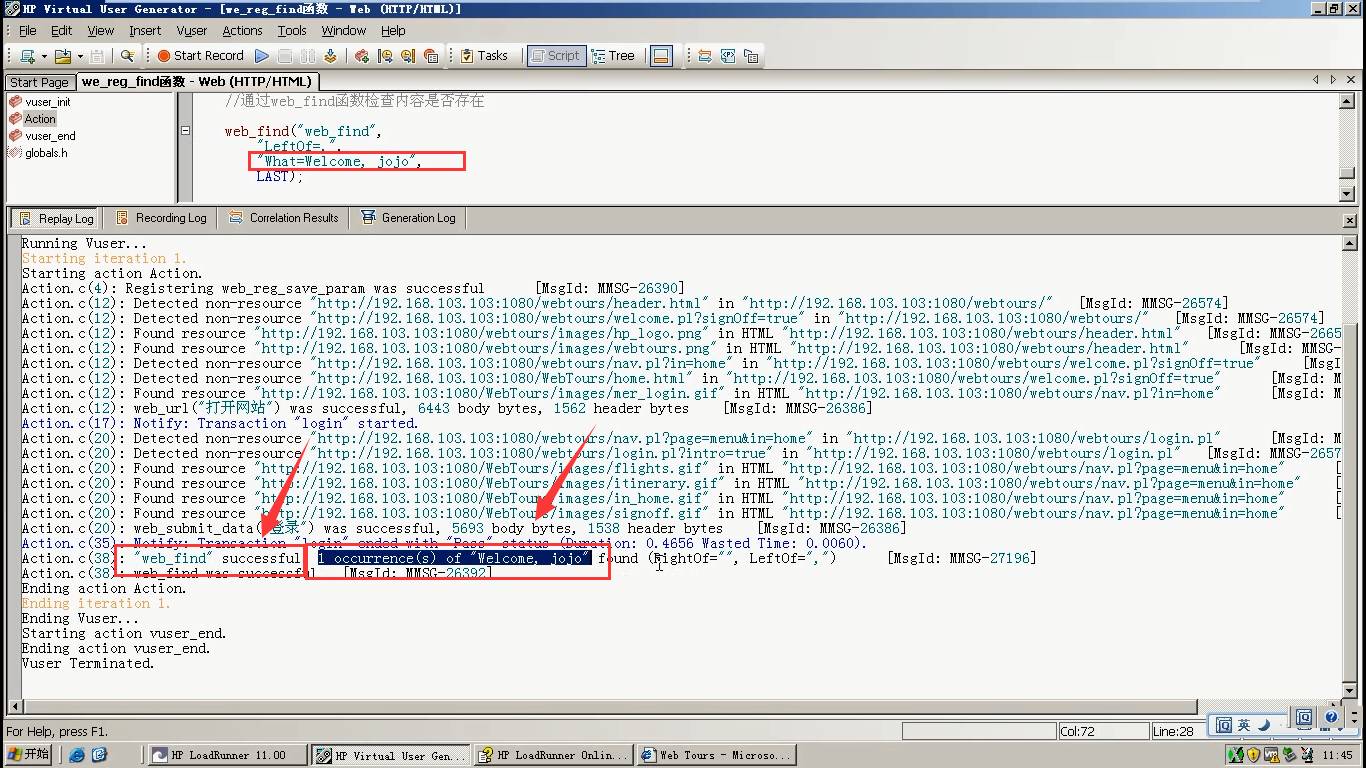
例:图片检查:web_image_check(同样要开启图片文本检查相),这个函数用的也比较少。
1)选中fight---右键---检查-----拷贝一下img标签

2)复制到文本里,有src属性,alt属性
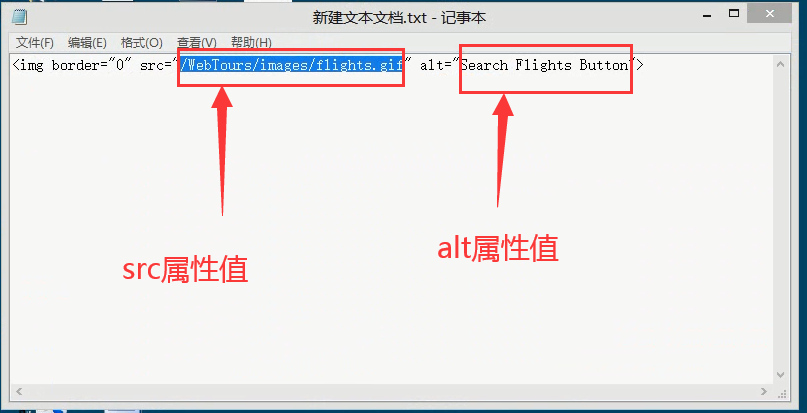
3)插入web_image_check函数。点击ok
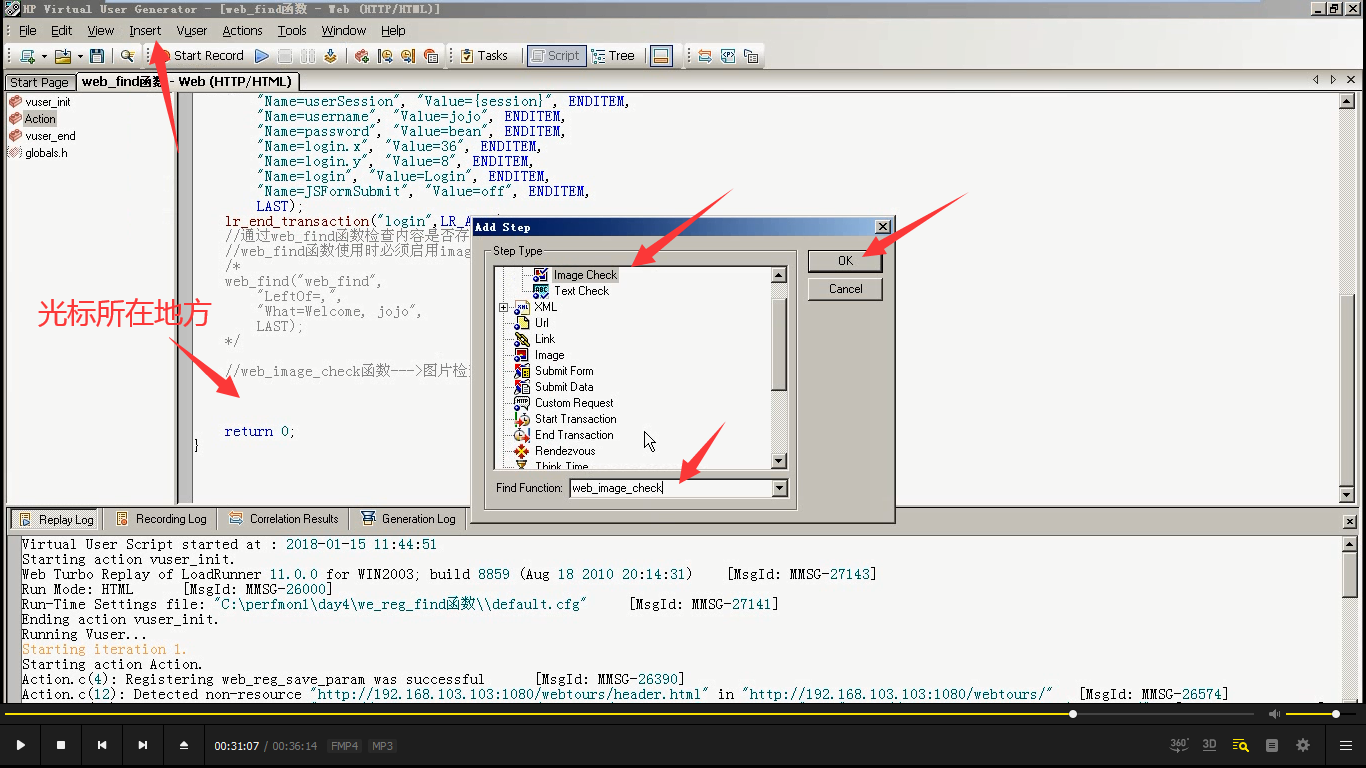
4)填写alt属性和src属性。(前面的要勾上)
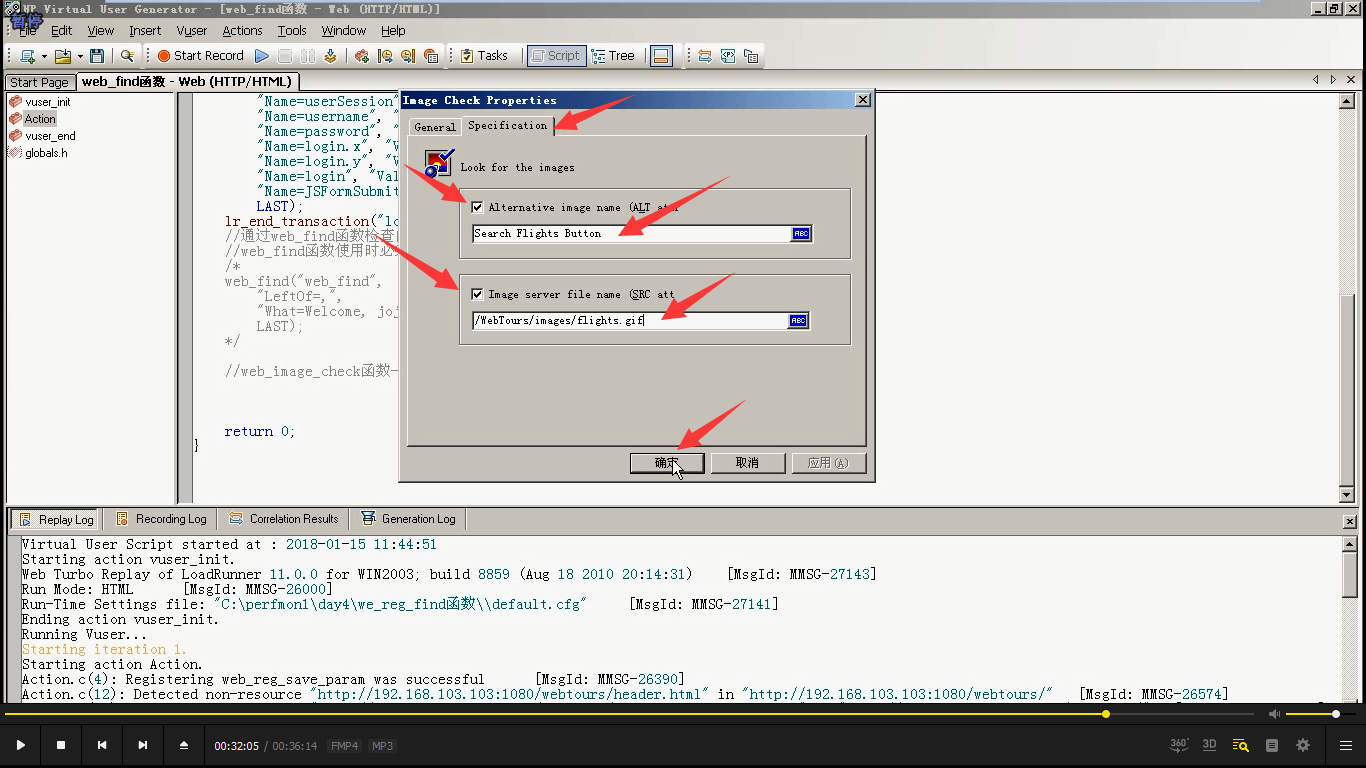
5)勾上文本图片检查

6)运行,找到了。(src属性是这样的,alt属性是这样的。)
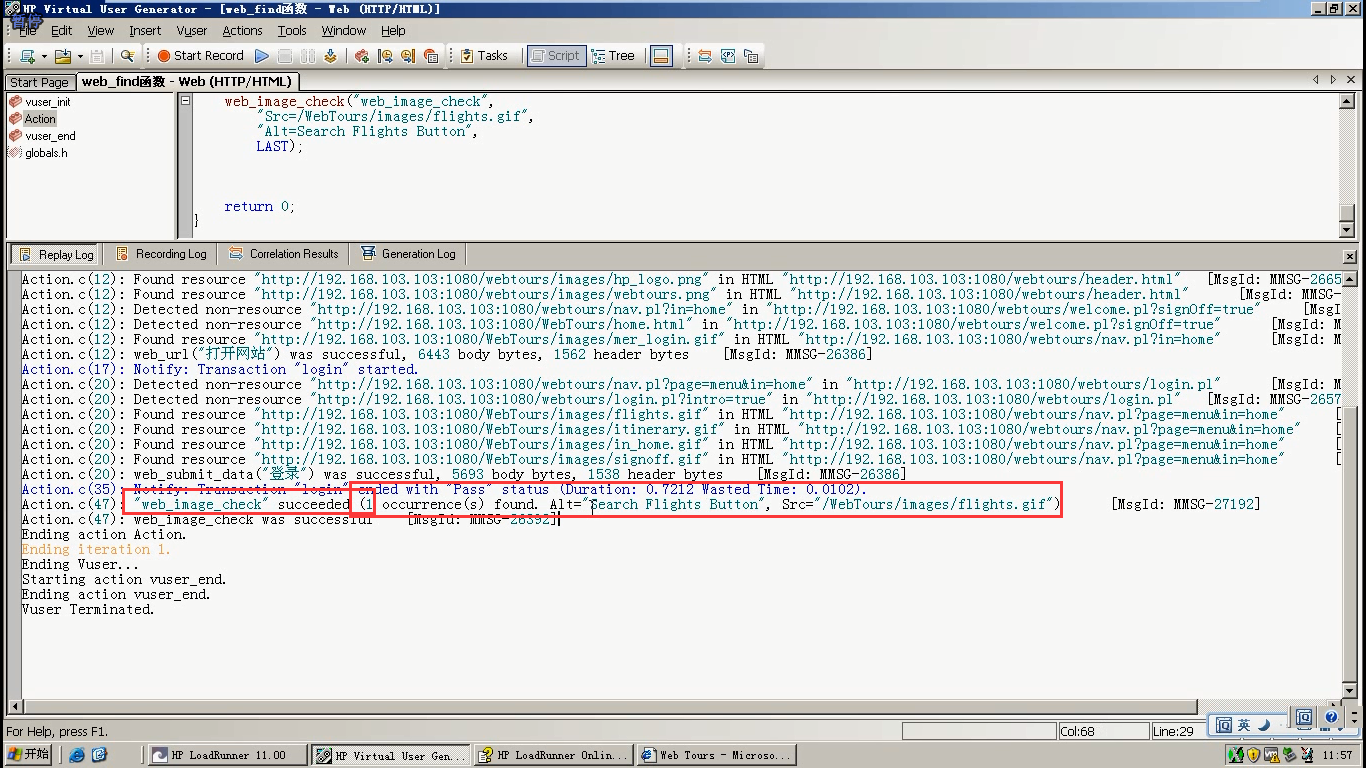
3.思考时间
3.1作用:更加真实模拟用户发出请求之间的延迟,也就是用户暂停发请求的时间
3.2设置策略
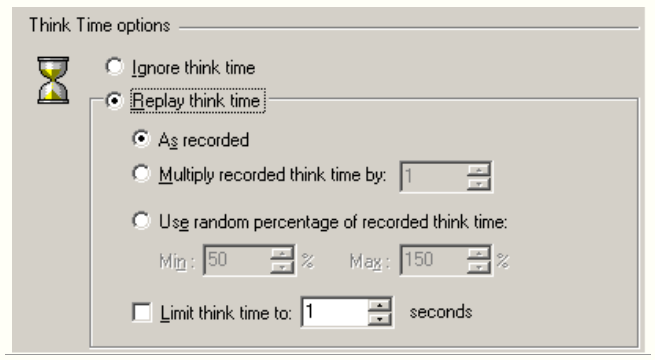
lr_think_time():忽略、按脚本中时间执行、脚本中时间的倍数、脚本中时间的百分比
3.3函数
lr_think_time(秒数)
注意:
1.实际情况下,获取真实场景的系统的性能指标时一般加入思考时间(1-2S) 如果是做压力测试获取系统的峰值指标时,一般忽略思考时间
2.一般情况下,思考时间函数不要放入事务内,以免后期影响计算事务响应时间
4.集合点(代码也可以不要集合点。)
集合点:模拟多用户同时操作
单功能脚本:没必要加集合点(做一个注册,或者做一个登陆等单独功能来说,就不需要设置集合点。完全可以由Controller,设置加载方式来,达到用户的集合。)
多功能脚本:可以加集合点
4.1作用:
设集合点是为了更好模拟并发操作。设了集合点后, 运行过程中多个用户可以在集合点等待到一定条件后再一起发后续的请求。
4.2设置策略
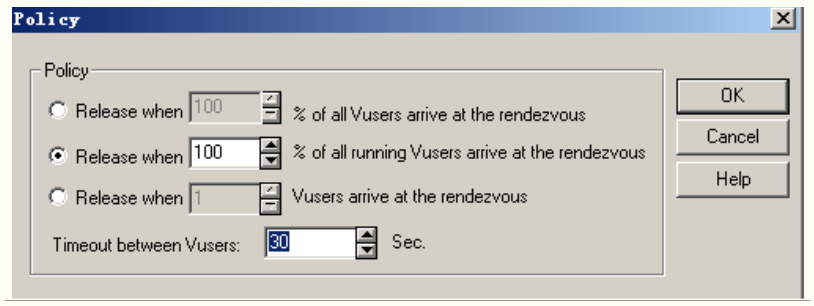
三种策略:
1.所有用户达到指定的百分比以后,释放用户
2.运行中的用户达到指定的百分比以后,释放用户
3.指定达到一定用户量以后进行释放
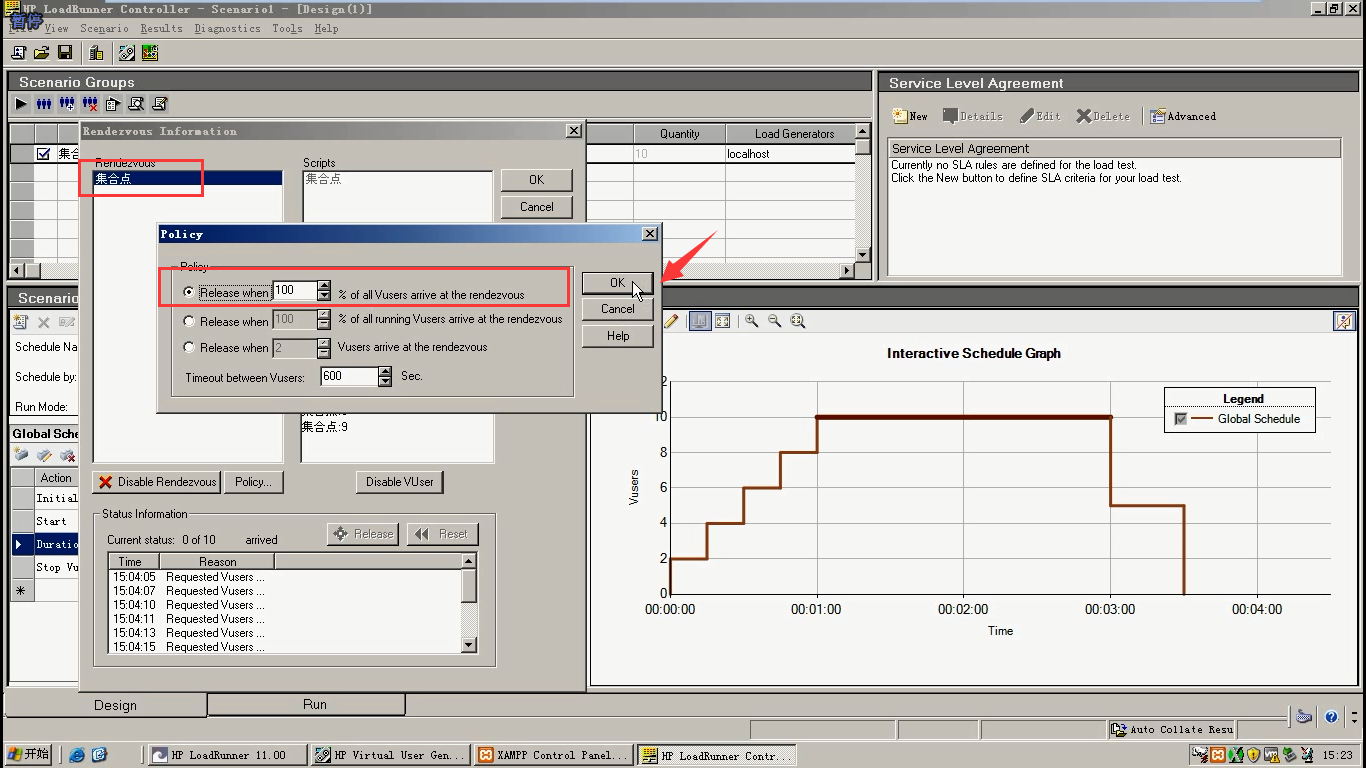
图示1:Controller---scenario--Rendezvous--policy
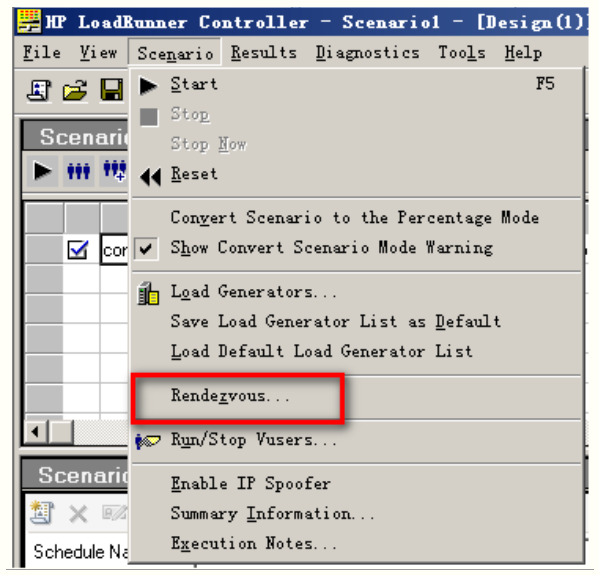
图示2:三种策略
4.3函数
lr_rendezvous("集合点");
例:集合点的使用
目标:假设有10个用户,都打开网站后,设置集合点。同时登陆。
1) 打开脚本
2)只做了简单的登陆操作
3)设置集合点:Insert-----Rendezvous(集合点,设置在开始事物前面。)
集合点,设置在开始事物前面的原因。 如果在事物里面,响应时间会增加很多,每一个用户和每一个用户的等待过程,这个等待过程并不是我们向服务器请求过程。第一个用户等的时间最长,事物
的响应时间是每一个用户操作事物时间相加/ 总的用户数=平均事物的响应时间。
4)取一个集合点名称。随便叫一个:集合点。

5)集合点函数就生成了。
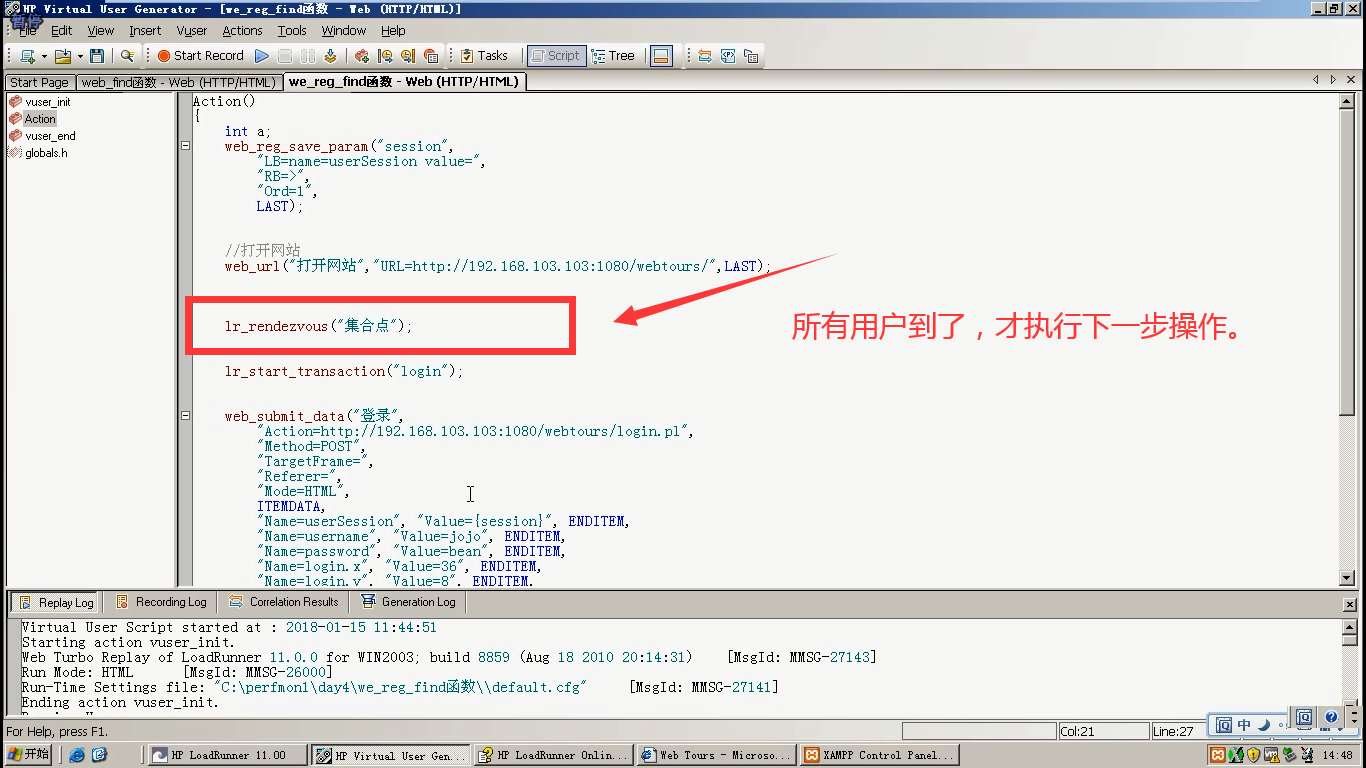
6)保存一下:file-save as(这里运行,看不了效果,因为是单用户,要到Controller去看)

Controller
1.打开Controller
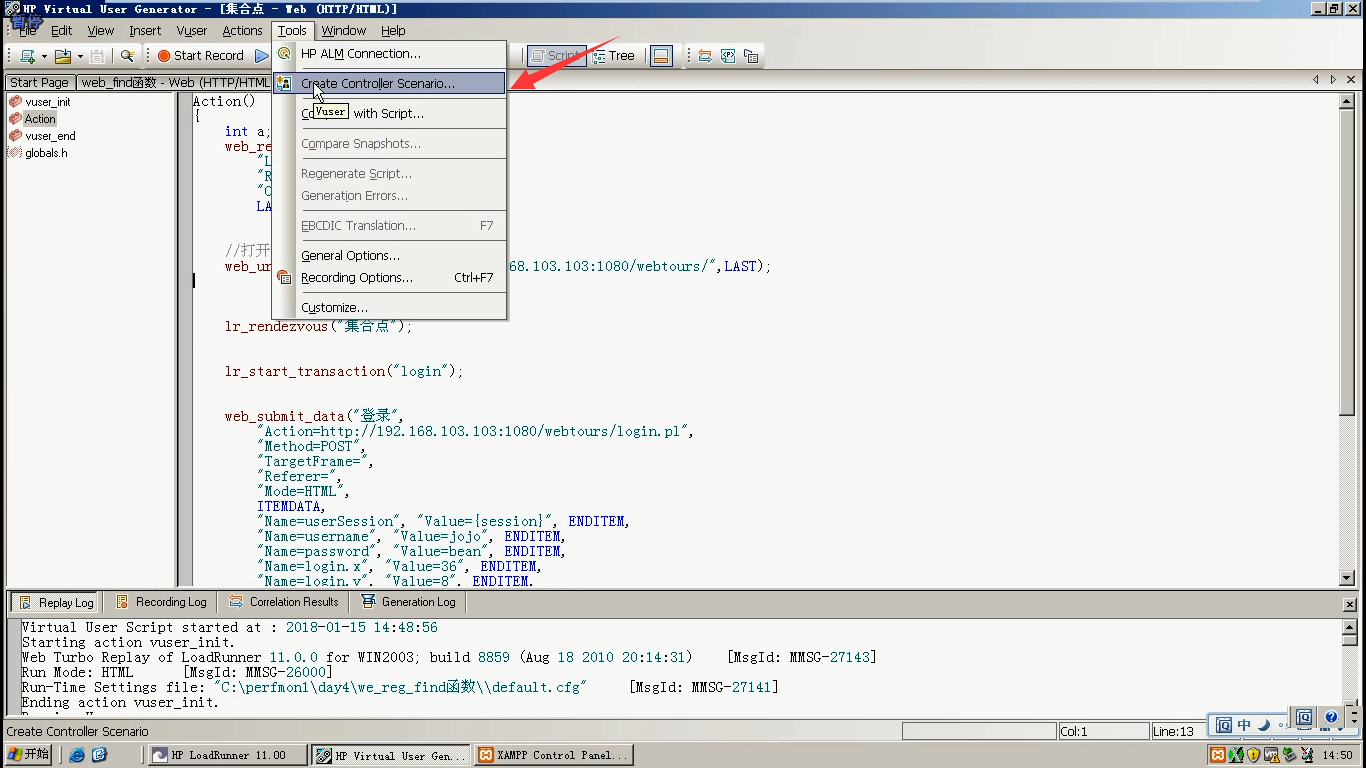
2.设置10个用户

3.不操作,等待

4.找到刚才的代码:集合点,添加进来,点击ok

5.设置集合点:选中----Scenario-----Rendezvou(如果刚才在代码中没有设置集合点,Rendezvou是灰的点不了。)
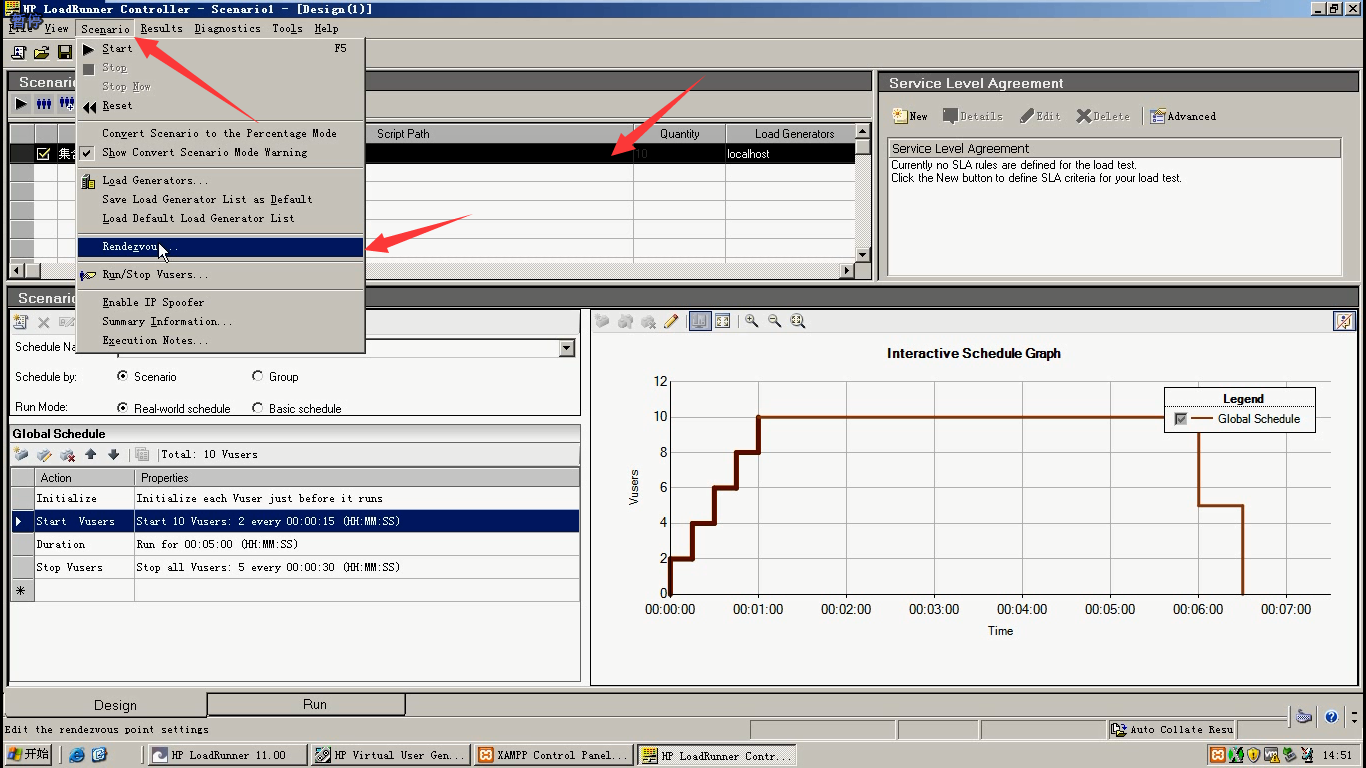
6.设置策略:点击Policy
Rendezvous(集合点名称):集合点
Script(所属脚本):集合点
Vusers(虚拟用户):这里有10个用户
Disable Vuser:选中用户,点击这个。会让该用户不参加集合。(没必要,我们就想10个用户参加)
Disable Rendezvous:点击这个,会让该集合点不参加集合。

7.第一种:选中第一个,点击两次ok。(当100%的用户到达集合点时,开始释放)
Controller---scenario--Rendezvous--policy
1.当%x的全部用户到达集合点时,开始释放
2.当%x的正在运行的用户到达集合点时,开始释放
3.当x个的用户到达集合点时,开始释放
限制虚拟用户之间的超时时间为xxS
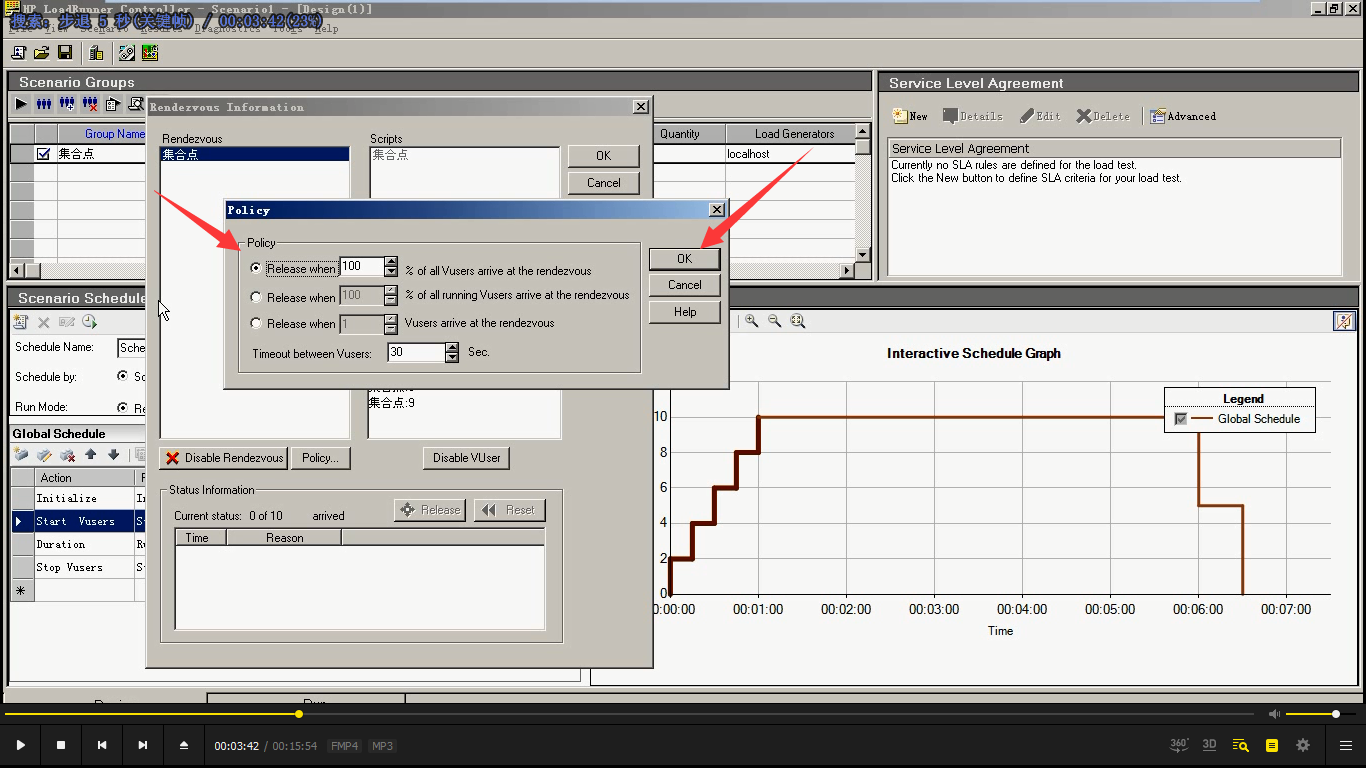
8.设置持续运行2分钟:点击Duration---设置2分钟---点击Apply----点击ok
每15秒添加2用户,75秒添完10个用户。这75秒不会有事物产生,只有在持续运行过程中才会执行下一步操作。(其实集合点这么设和这个没有什么太大影响)
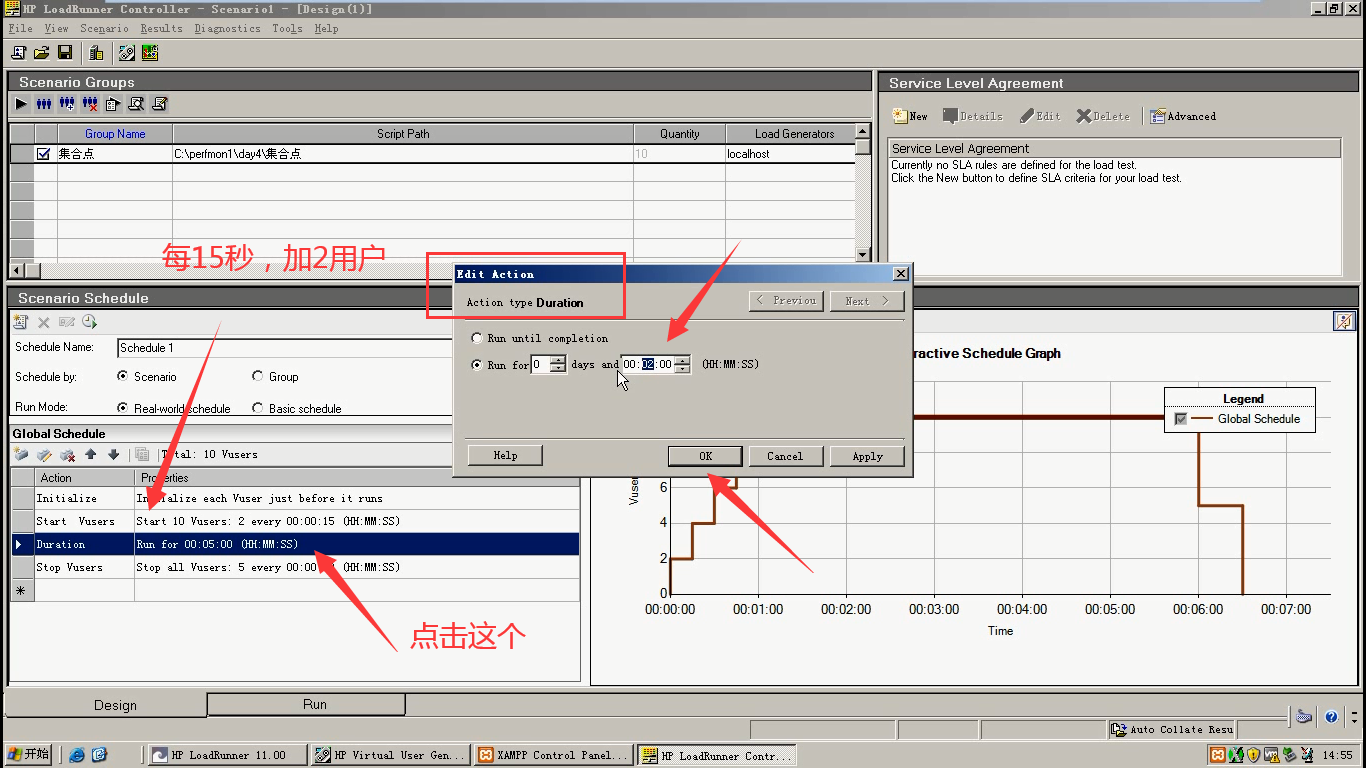
9.点击运行,是。Rendez:用户集合,集合到10个。开始Run。点击Stop,不会立马停。有的用户在Action里面,正在登陆。它会执行登陆操作完,再Vuser end,停下来。
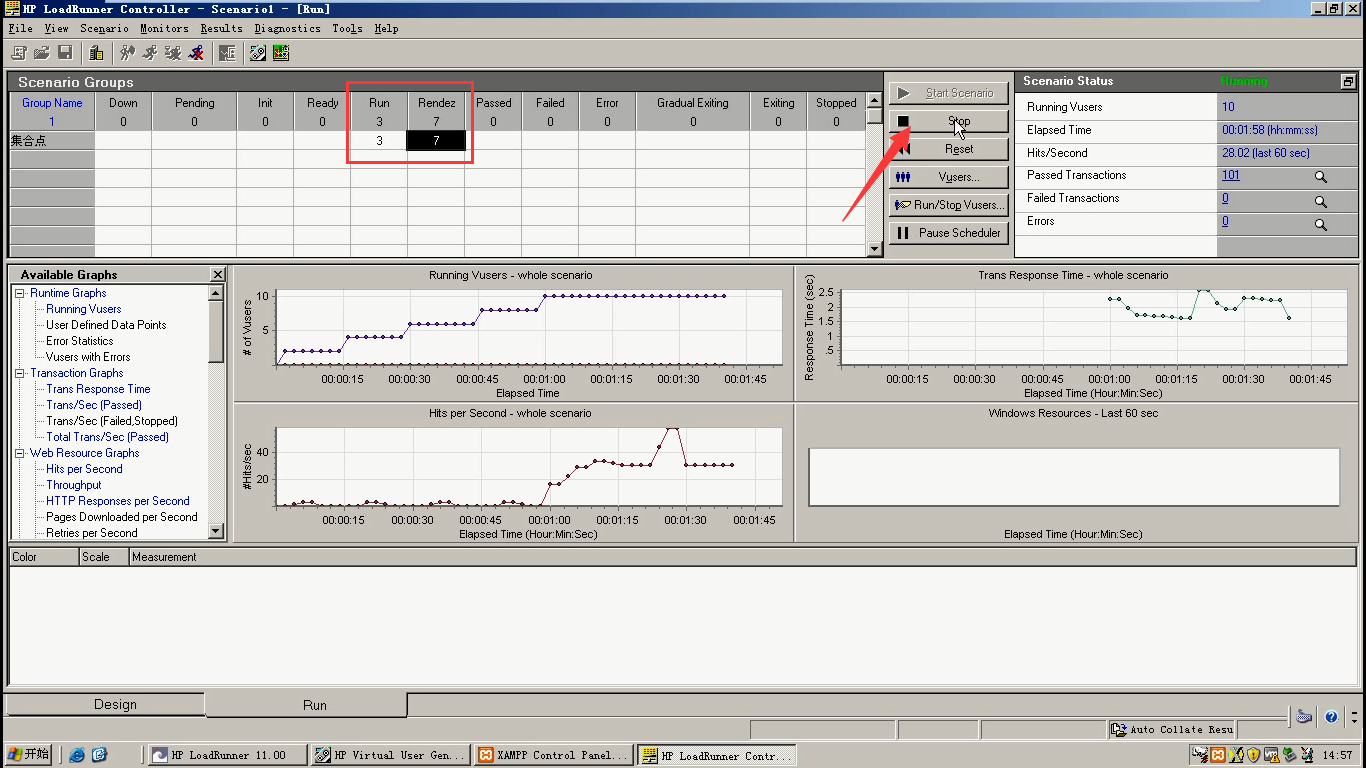
10. Controller---scenario--Rendezvous--policy
第二种:选择第二个,点击ok。当100%的正在运行的用户到达集合点时,开始释放
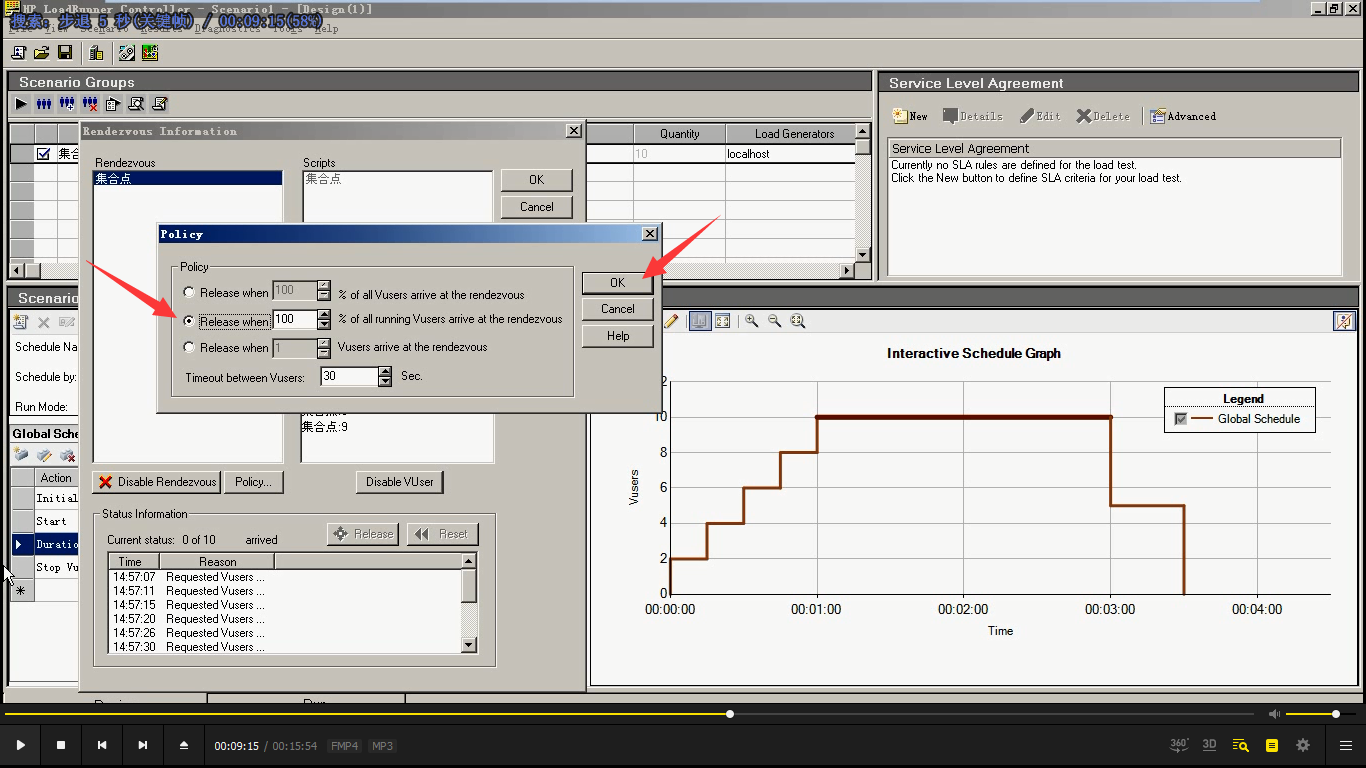
理解:当100%的正在运行的用户到达集合点时,开始释放
15秒增加2个用户,是100%。30秒增加4个用户是100%。45秒增加6个用户是100%。当前的用户达到设置的值后,就可以去释放。
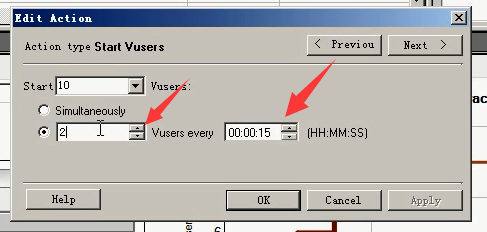
11.运行。当Rendez:达到2个用户,开始Run。当Rendez:达到4个用户,开始Run。当Rendez:达到6个用户,开始Run。(可以点击stop停下来。)
第二种是每一阶段进行集合,然后操作。第一种是总共的设置达到多少的用户数,再进行操作。

12. Controller---scenario--Rendezvous--policy
第三种:选择第三个,写5,点击ok。指定达到5个用户量以后进行释放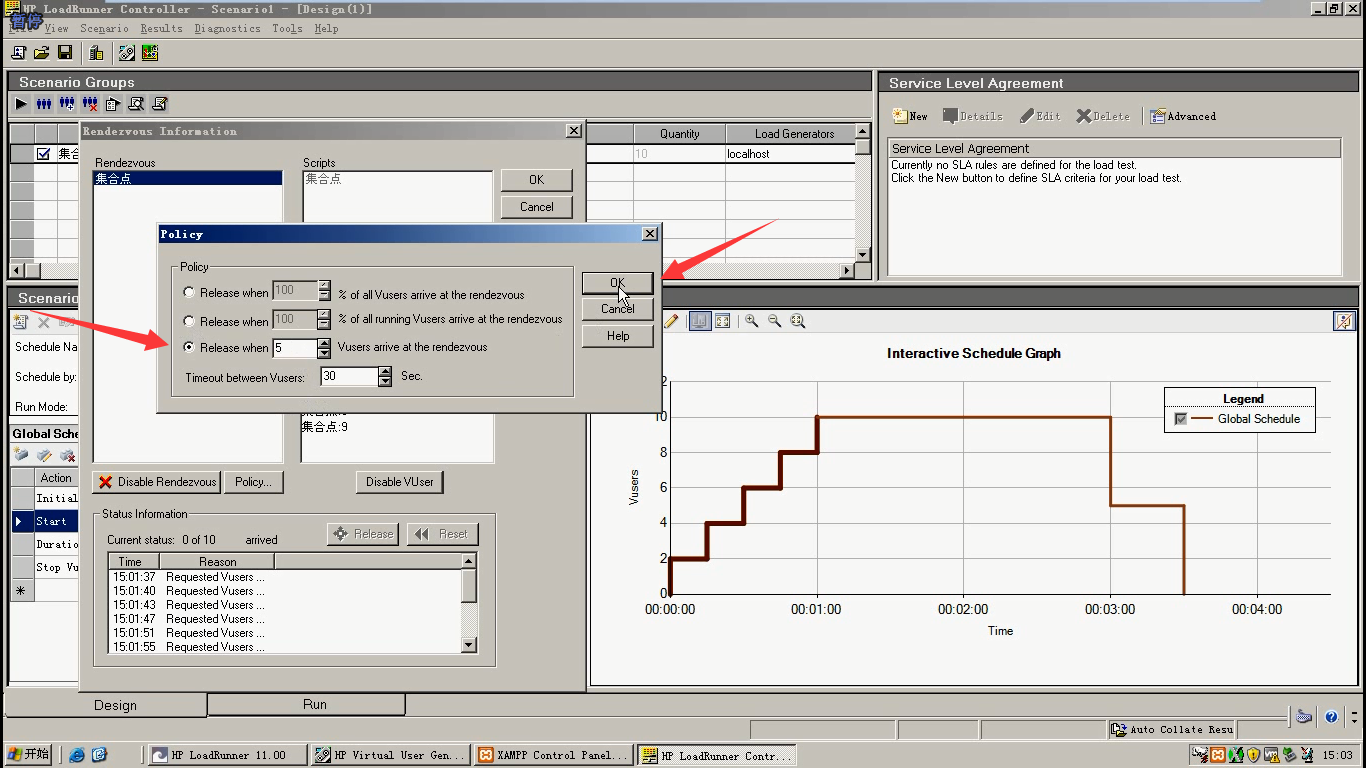
13运行。当Rendez:达到5个用户,开始Run。(可以点击stop停下来。)
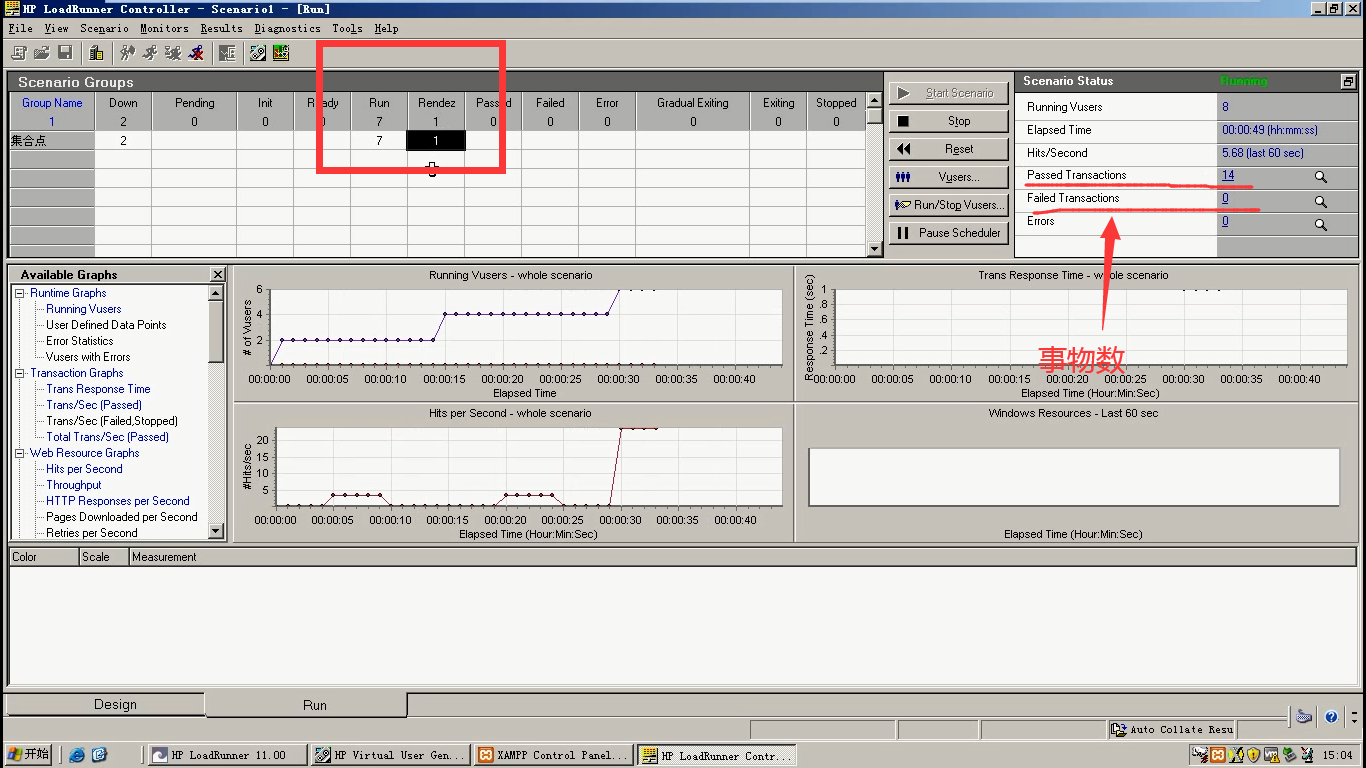
14.Timeout between Vuser (当超过多少秒,如果没有达到上面三种设置其中的一种的数量,就释放掉。)
比如:超过60秒,2个用户还没添加进来。就释放掉。(这个时间是肯定能添加进来,所以这个参数是没什么意义的。可以把它时间弄更长,让它失去作用)
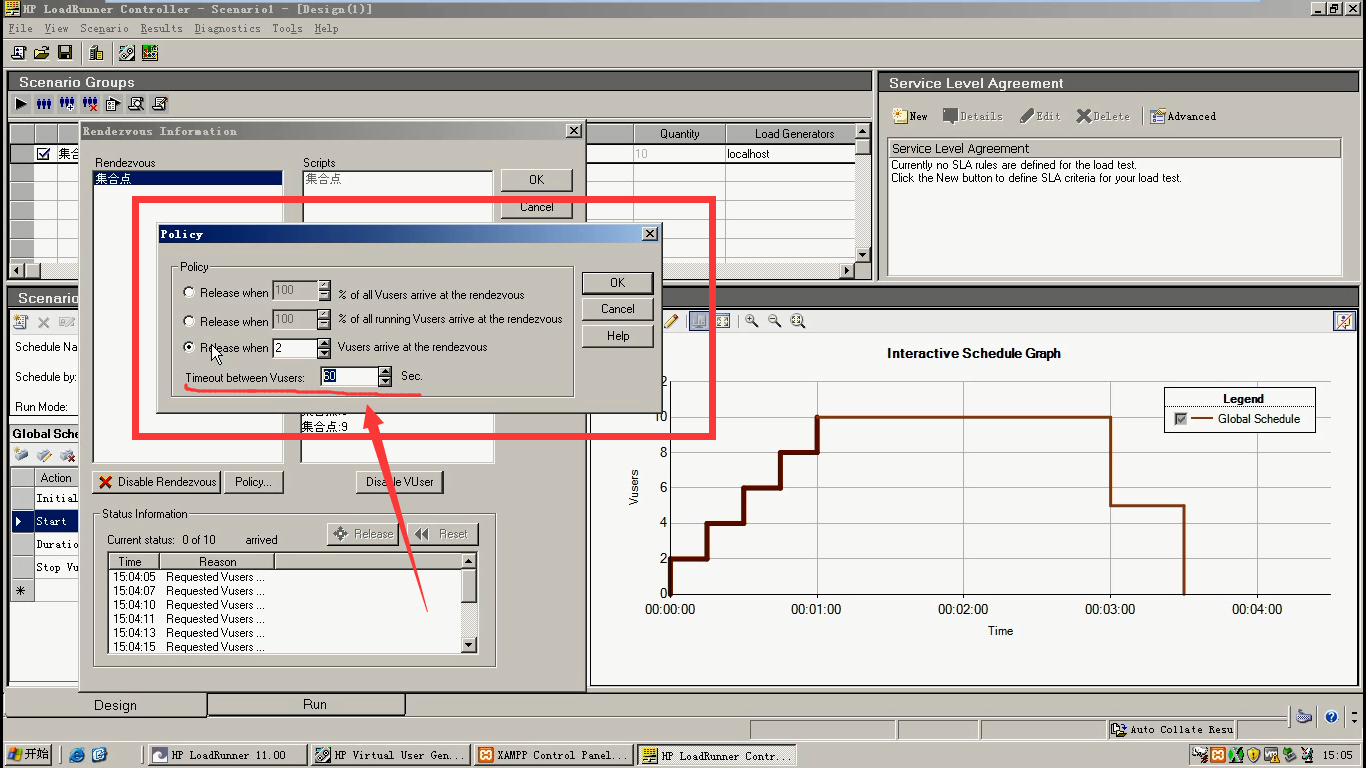
集合点:就是模拟同时操作。有时也不必要加集合点。因为下面的设置,和设置集合点是同一个效果。
下面就是每15秒加2个用户,达到10个用户,再一起操作。
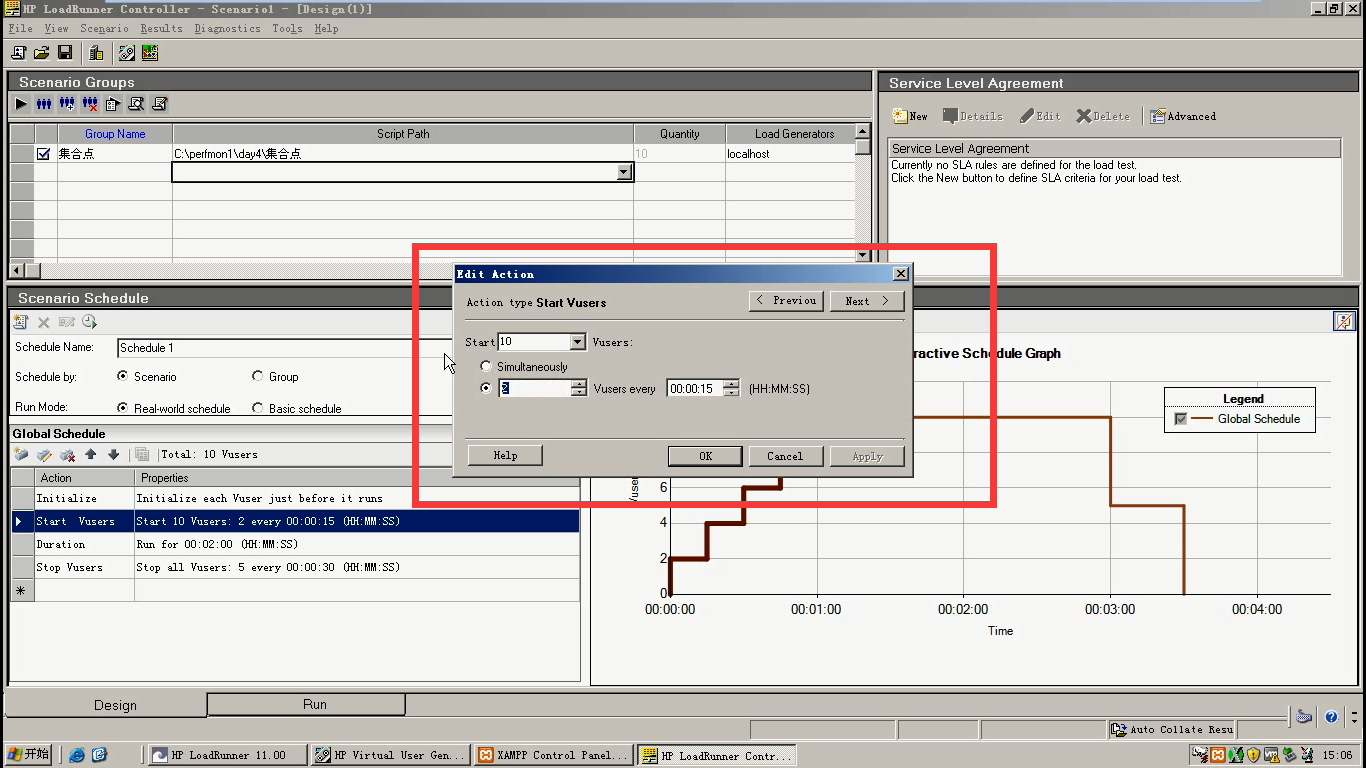
最终脚本: iwebshop
要求:
- 访问首页
- 登陆
- 登录事务
- 检查点
- 参数化

如果代码有中文报错,编码不一致导致的。解决如下。
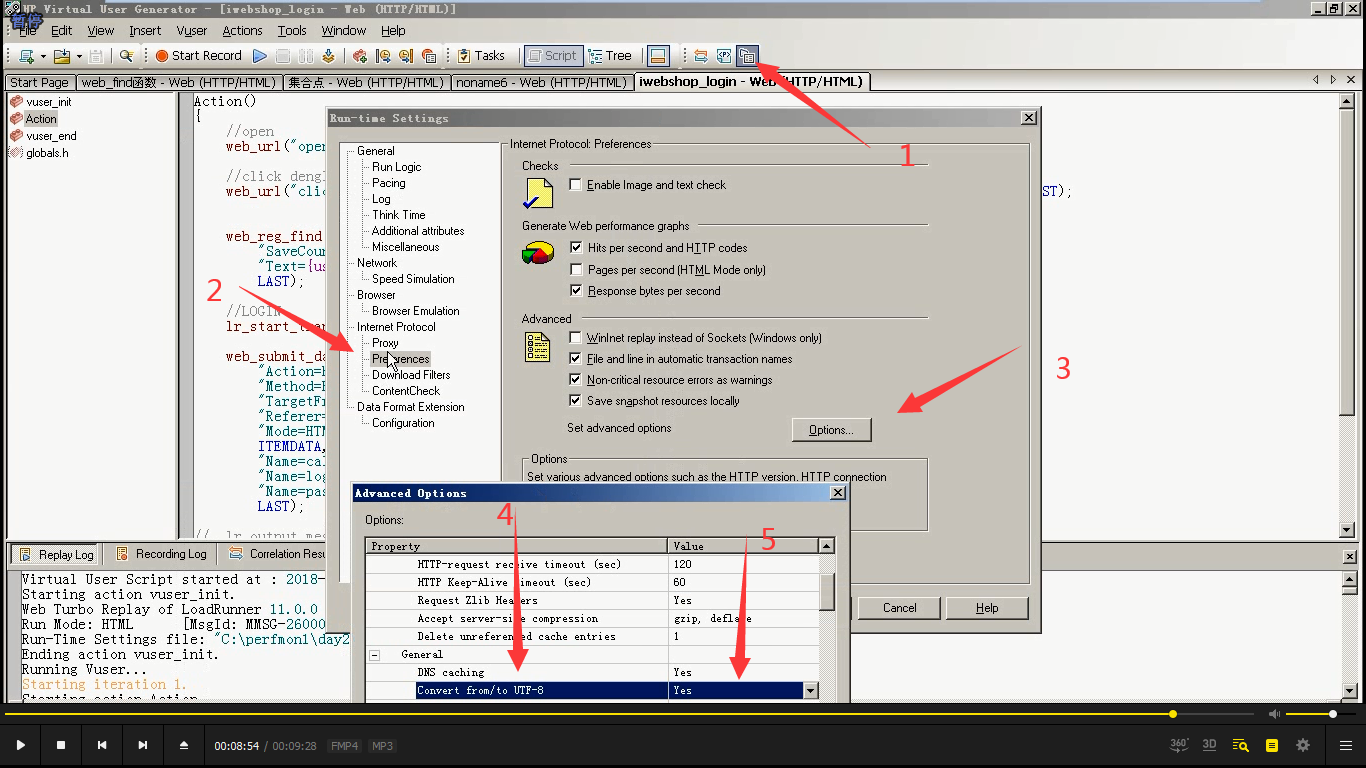
思考一下设置:每15秒增加两个用户,在登陆前设置集合点。持续运行时间为2分钟。这2分钟一直是运行登陆还是Action?
答:持续运行的是Action。
每15加两个,每15秒加两个。大概75秒的时候,10个用户加上来了。这10个用户都到达了打开网页这一步,到了这一步,就做一次释放操作(也就是登陆操作)。释放完了,因为有持续2分钟。
它会怎么操作?会打开网站,再次集合10个用户。然后再去执行释放操作(登陆)。然后再打开网站,再次集合10个用户。然后再去进行登陆操作。当达到1分钟以后,该停了。假如这10个用户都
在Action里面运行,这10个用户就会执行最后一次Action。(因为时间到了,它又没有执行完这个Acion。)会把最后一次Action执行完,进入vuser_end结束掉。
总结:持续运行的是Action,集合点设置的是登陆前的(在登陆前做了一次集合)。
1)每15秒增加两个用户,持续运行时间为2分钟。

2)在登陆前设置集合点,选择第一种模式。
5.Vugen常见函数
1.发送get请求
web_url()
2.发送get,post请求。
web_submit_data()
web_link();录制时用。
web_submit_form();录制时用
3.请求函数,发送任何方式的请求
web_custom_request()
4.关联函数
web_reg_save_param()
5.获取参数的返回值
lr_eval_string()
lr_save_string();将字符串保存到参数中
lr_output_message()把信息,输出到日志中。
lr_paramarr_idx();参数数组,指定位置元素的获取方式。
lr_paramarr_random();参数数组,随机位置元素的获取方式。
lr_paramarr_len()参数数组长度函数
6.检查点函数
web_reg_find()
web_find()普通检查点函数
web_image_check()图片检查点函数
7.将字符串转为整数的函数
atoi()
itoa();将整数转为字符串的函数
8.思考时间函数
lr_think_time()
9.事物开始点函数
lr_start_transaction()
10.事物结束点函数
lr_end_transaction()
11.集合点函数
lr_rendezvous()
web_get_int_property() 获取状态码函数
以后学习到别的函数,可以通过F1帮助文档(查看例子,或者参数和返回参数)
6.Controller控制器
6.1 性能测试的分类
性能测试:对系统进行施加压力,与预定目标进行比较
负载测试:属于性能测试的一种,通过逐步增加系统负载,确定在满足性能指标情况下, 系统所能承受的最大负载量,找系统挂之前的那个点(找到第二个拐点,甚至第一个拐点。)
压力测试:属于性能测试的一种,确定在什么负载条件下长时间运行,系统失效(在重负载区:第二个拐点之前一点压)
基准测试:性能测试出现问题做基准测试。
配置测试:用相同的基准测试脚本进行回归测试。
例:简单看一下效果(要先做负载,逐步增压)
1)保存:file ----save。打开Controlle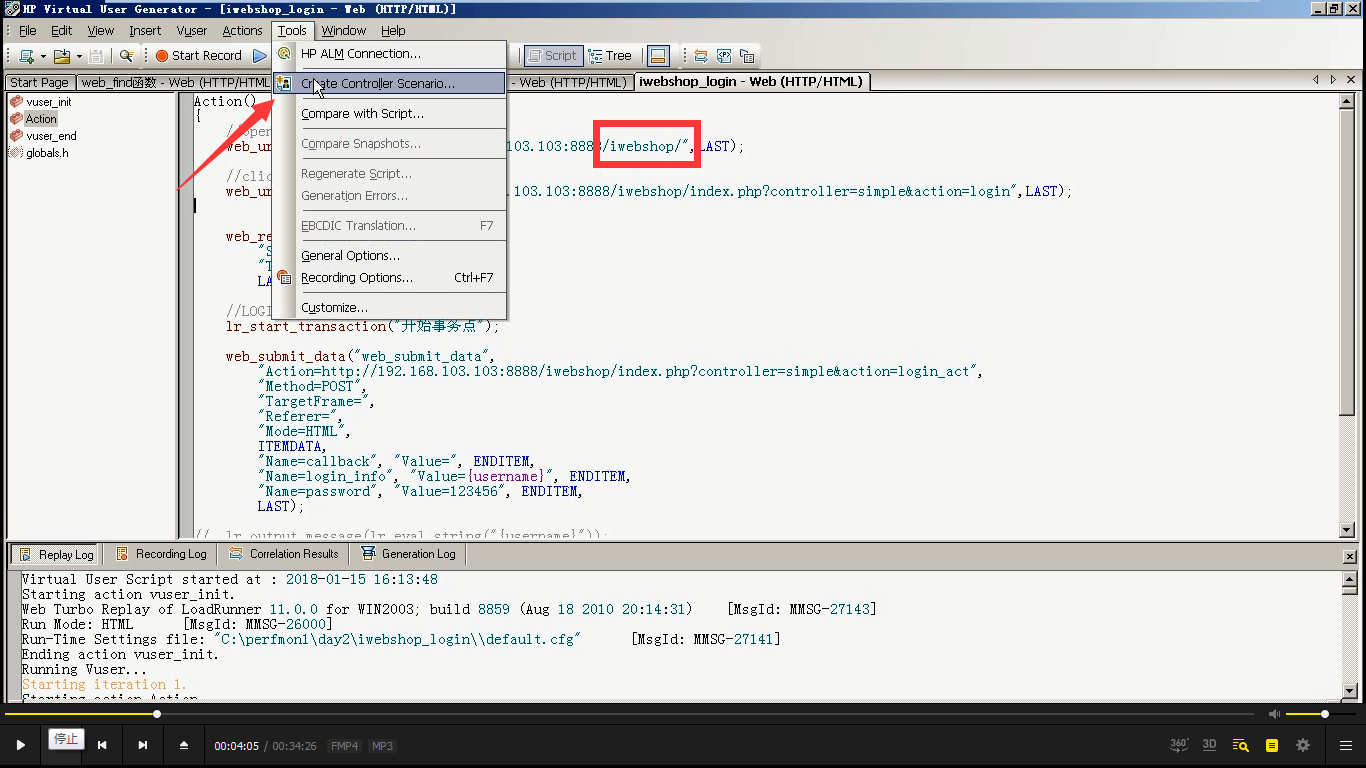
2)设置10个用户数。(下面有两类三种)
两类,表示有两种打开方式:
Goal Oriented Scenario方式
Mumber of Vusers方式
三种:分别为
第一种:Goal Oriented Scenario
第二种:Mumber of Vusers----数量添加进去的
第二种:Mumber of Vusers----百分比添加进去的
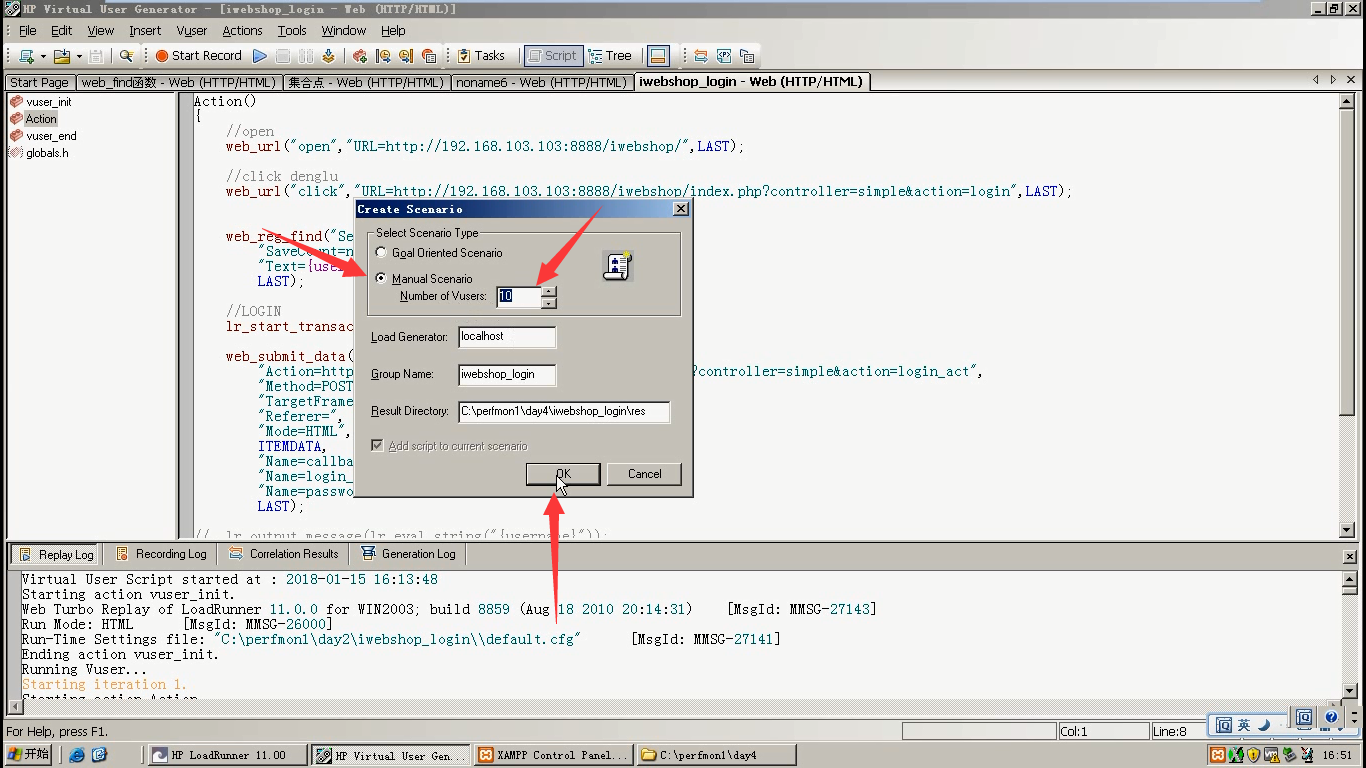
3)初始化选择第三种,点击Apply-----点击Next
第三种:在运行前(这里是Action脚本运行前)初始化每一个用户。

4)Start Vusers启动用户为10个(因为破解的原因,当前的LR最大只能到100),每隔50秒加载一个用户。点击Apply-----点击Next。
逐步增压就是靠这个来做的:每隔多长时间执行多少个。时间尽可能长,用户数量尽可能少。
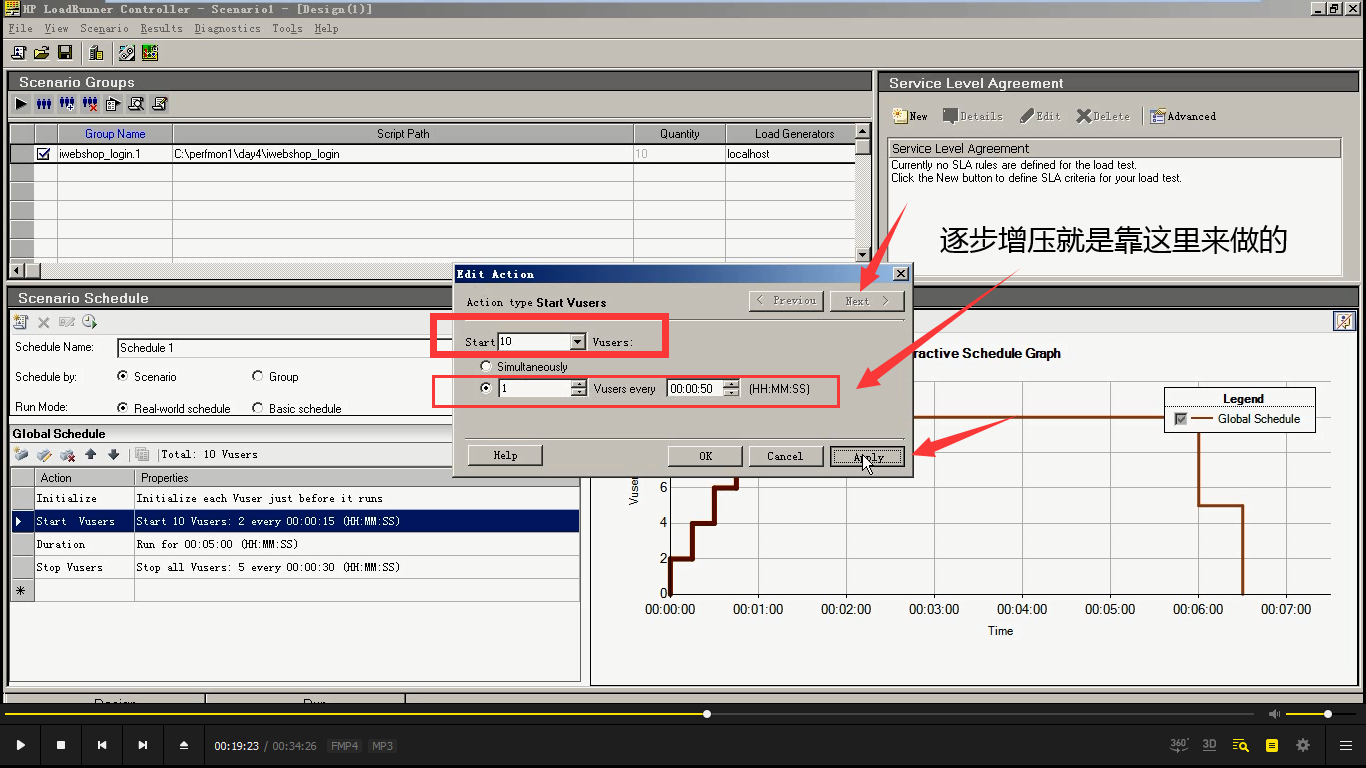
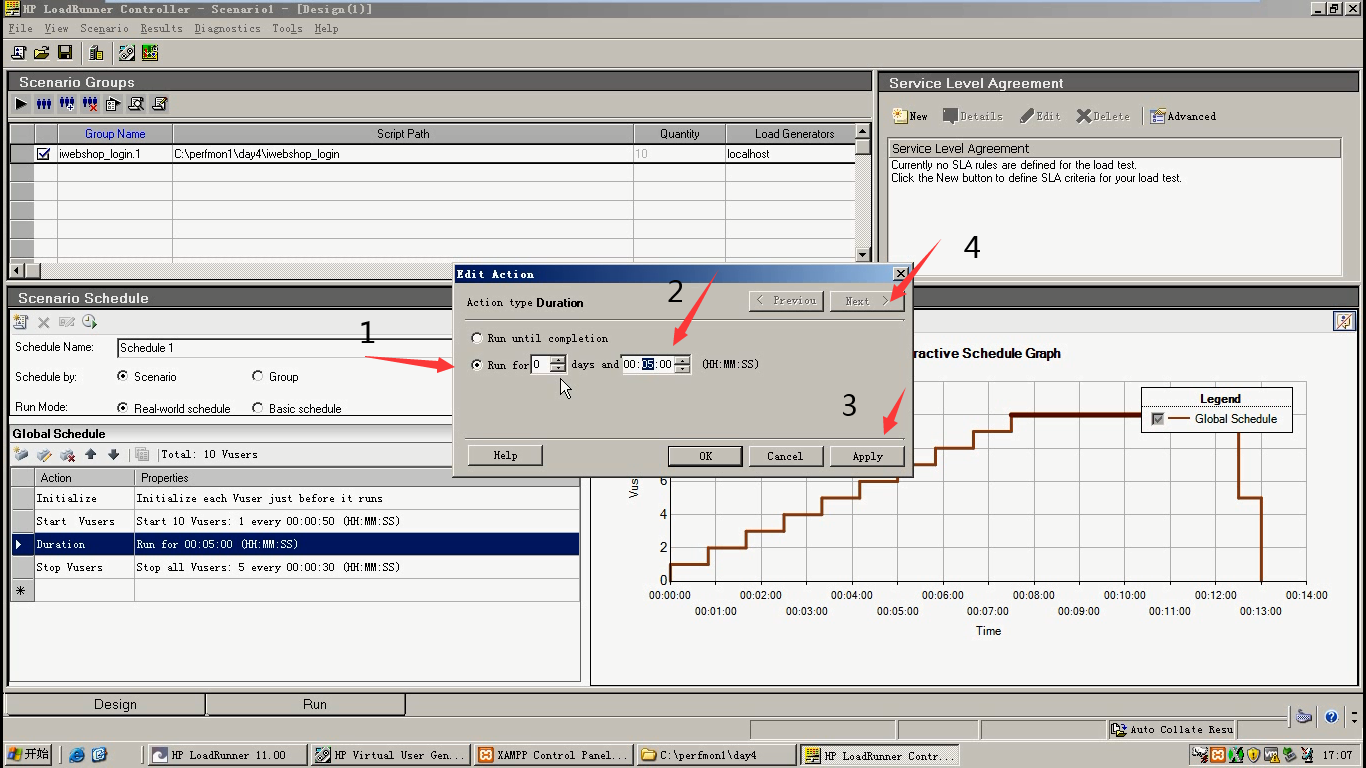
5)Duration,选择第二种:写5分钟。点击Apply-----点击Next。
第一种,第二种这两种和迭代的关系?
第一种:当10个运行完就不再走了。这个跟Runtime Setting里的迭代次数有关系,设置迭代多少次,就迭代多少次。
第二种:写了多长时间,那些用户都进来以后,就运行多长时间。所运行的次数,和迭代次数没有关系。一般选第二种。
选第二种,假如写5分钟。如果每一秒完成Action的运行,5分钟就有很多次。
简单的压力测试:20-30分钟的时间
稳定性测试:3*24h=72h
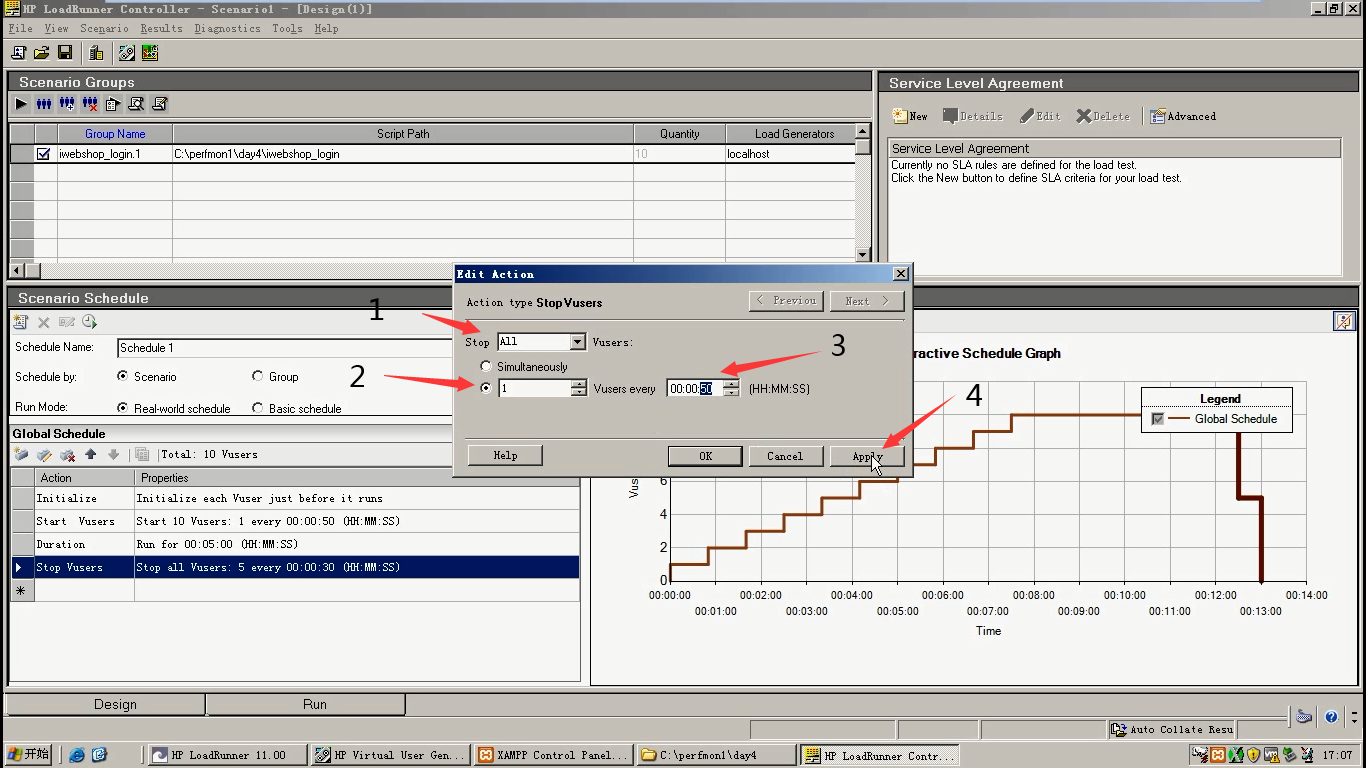
6)stop vusers:每50秒停一个用户。点击Apply---点击ok
7)左边设置好后,右边就有一个图表(vusers将来执行的时候,一个执行方案)出来了。
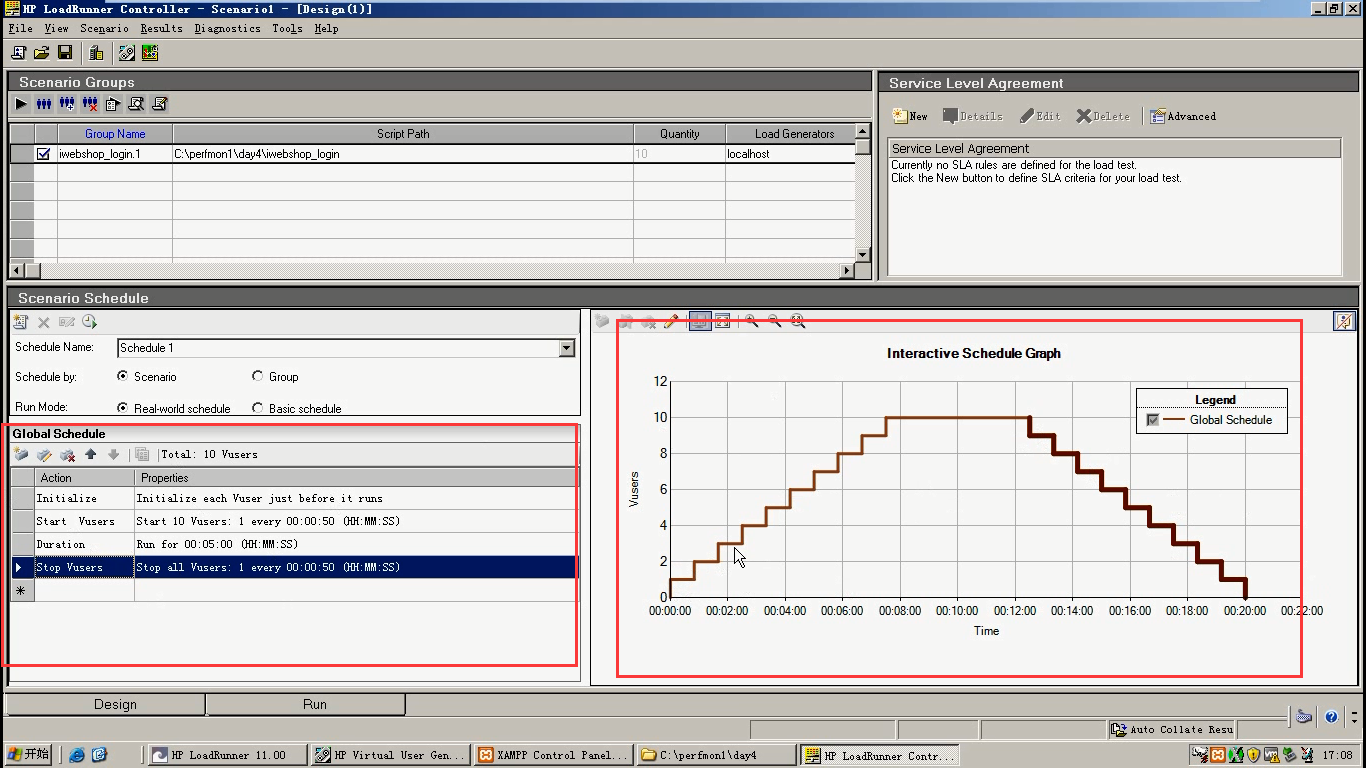
8)运行前,想把几个简单的数据表拿过来。选中,点击下面的RUN。
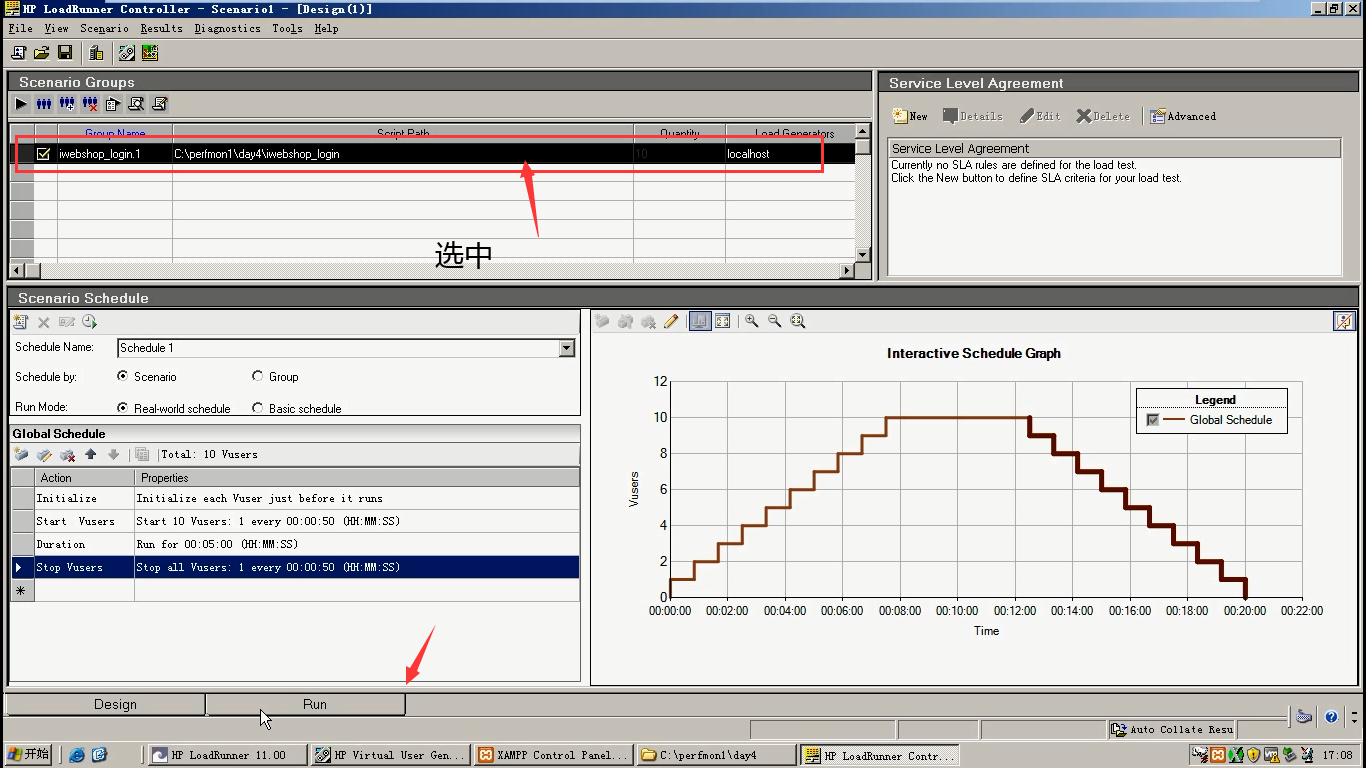
要有这四个小图标:都可以从左边的Available Graphs中拖拽过来。
Running Vusers--whole scenario:运行的用户量显示
Trans Response Time----whole scenario:运行过程中事物的响应时间的显示
Hits per second ----whole scenario:每秒的请求数量显示
Thrioughput----whole scenario:吞吐,服务器处理能力
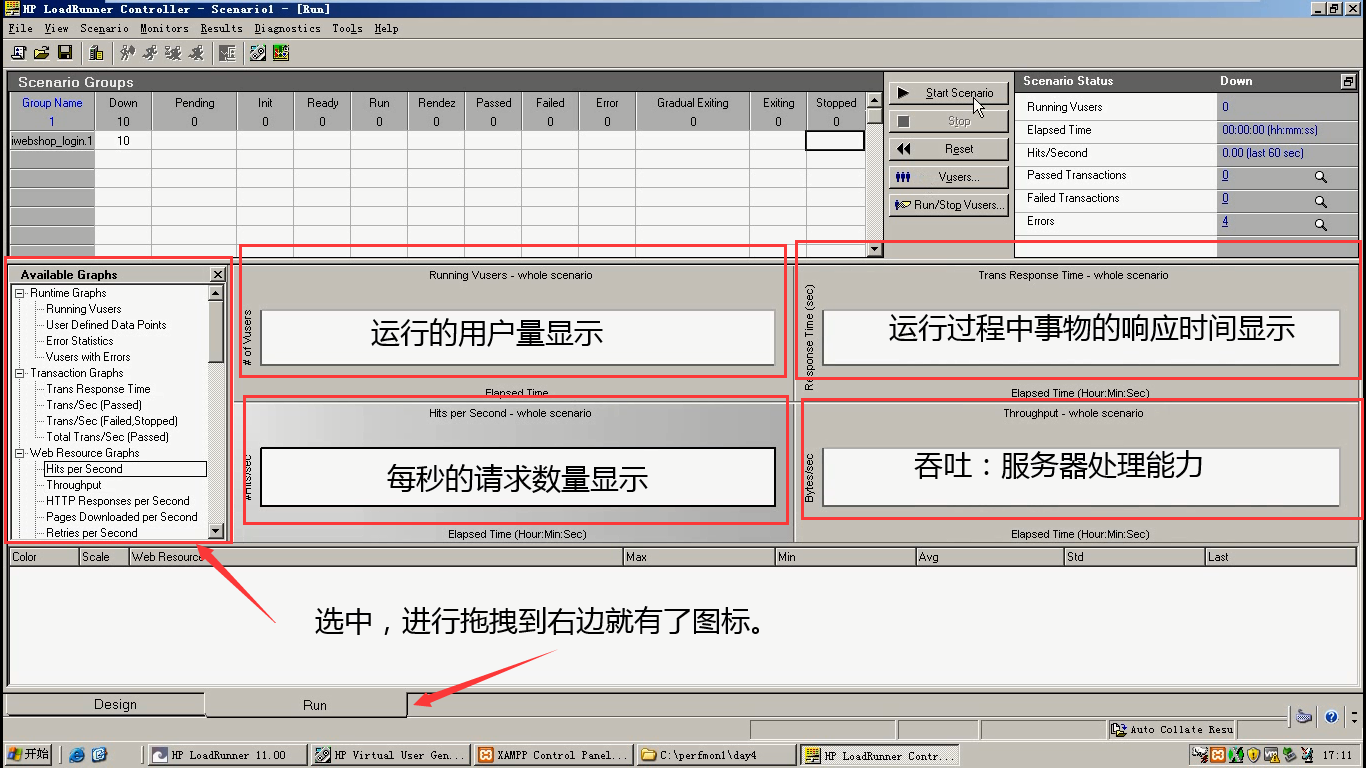
这里不用做什么,只是介绍区域以及参数的作用。
Scenario Groups:脚本跑的过程的区域
- Down:关闭,还没开始跑
- Pending:挂起
- Init :初始化
- Ready:准备
- Run:开始跑
- Rendez:集合(设置集合点的化就有)
- Passed:通过
- Failed:失败
- Eroor:报错
- Gradual Exiting:逐渐退出(进入vuser_end)
- Exiting:执行完vuser_end
- Stop:退出
Scenario Status:scenario的状态
- Running Vusers:运行的用户数
- Elapsed Time:消耗的时间
- Hits/Second:每秒的点击数(近60秒)
- Passed Transaction:事物通过数量
- Failed Transaction:事物失败数量
- Errors:错误数量(可以点击进去查看错误信息)
9)点击运行假设45秒是第一个拐点,用户数量对应的是1。
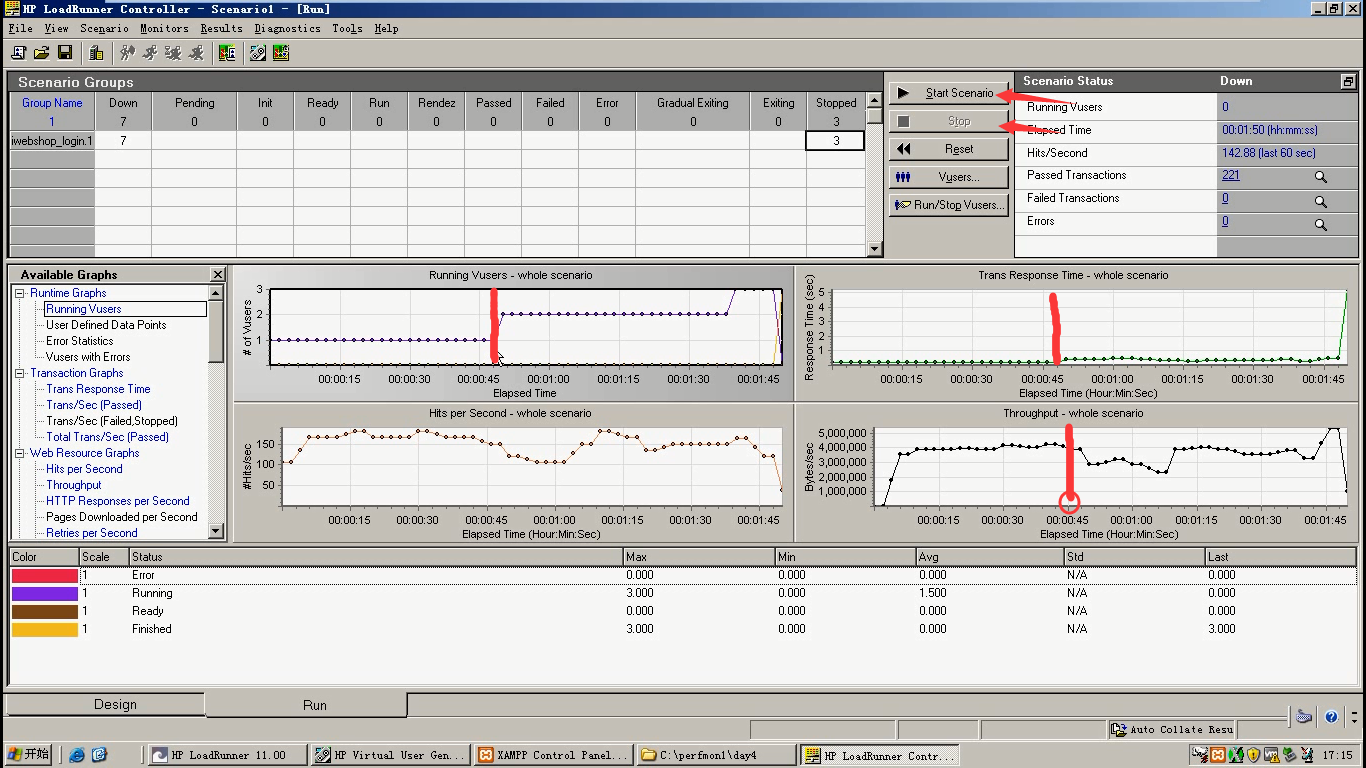
调一下用户为1
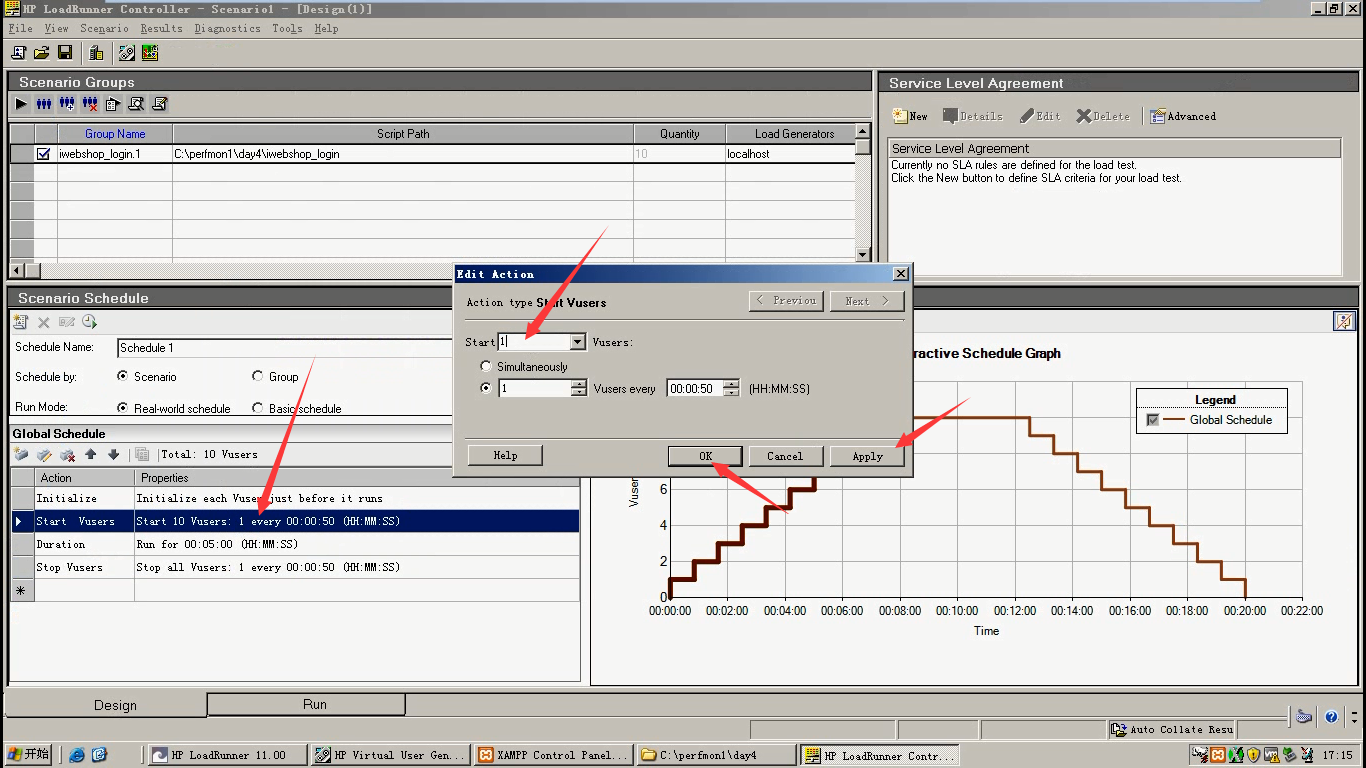
10)最佳并发点做的性能测试。继续压,停止。然后再调用户数量为5,逐步增压的方式来调。逐渐出现第二个拐点。当出现Error的时候,就找到了第二个拐点。
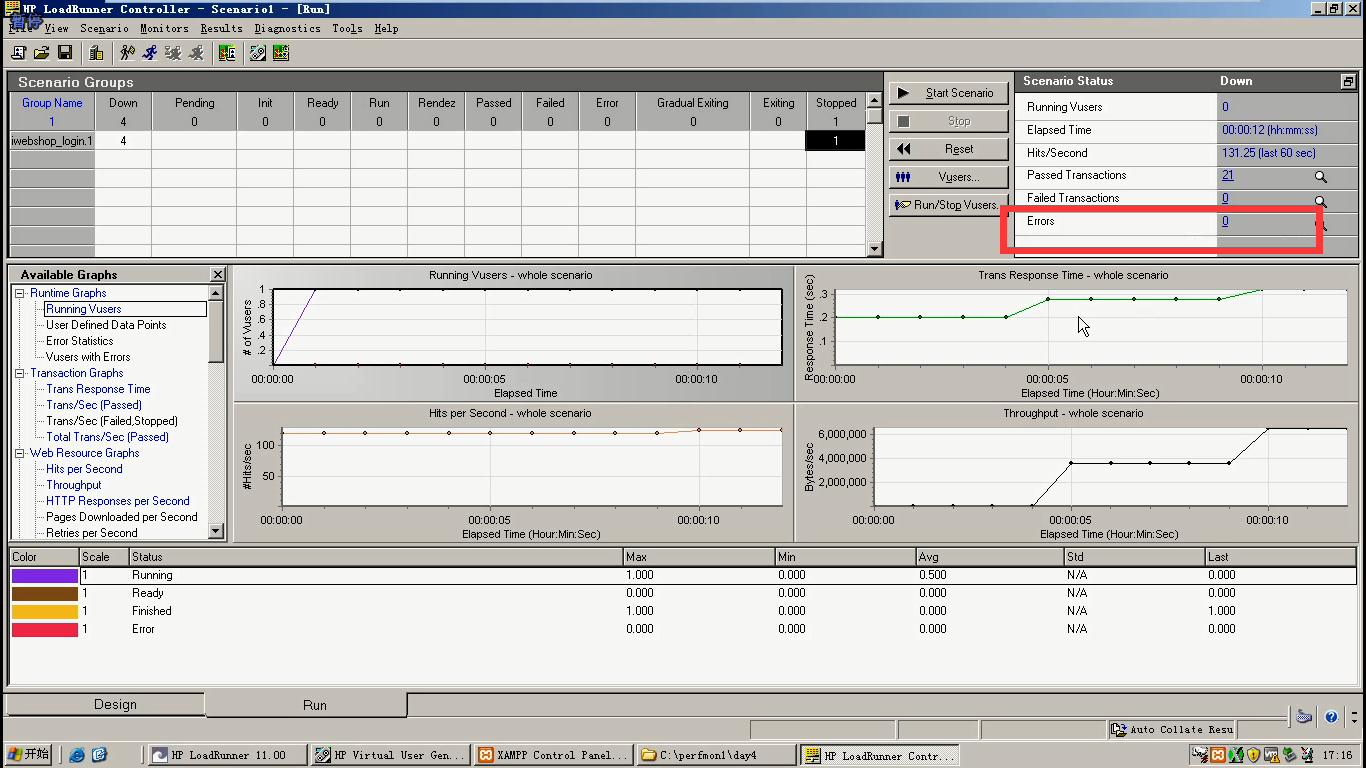
注意:在实际性能测试中,一定是逐渐增压的方式,来找拐点。只要细心,找到拐点,就能做相应点的测试。
跑的过程,想那张图。结合多张来想:
什么时候,响应时间开始变化。什么时候,我的吞吐不再变。第一个点出来了。
什么时候吞吐开始降,什么时候响应时间开始急剧增长。(或者出现Errors)第二个点就出来了。
每出现一个点,就stop。因为后面的数据是没有用的。
假设出现这种情况:有5个用户在跑,5个用户全都加进来了。吞吐还在长,响应时间没怎么变化。在哪个区?答:在轻负载区。可以继续加用户数量,压。什么时候出现第一个点。
一定要把脚本完成,该加的点加上,再做性能测试。
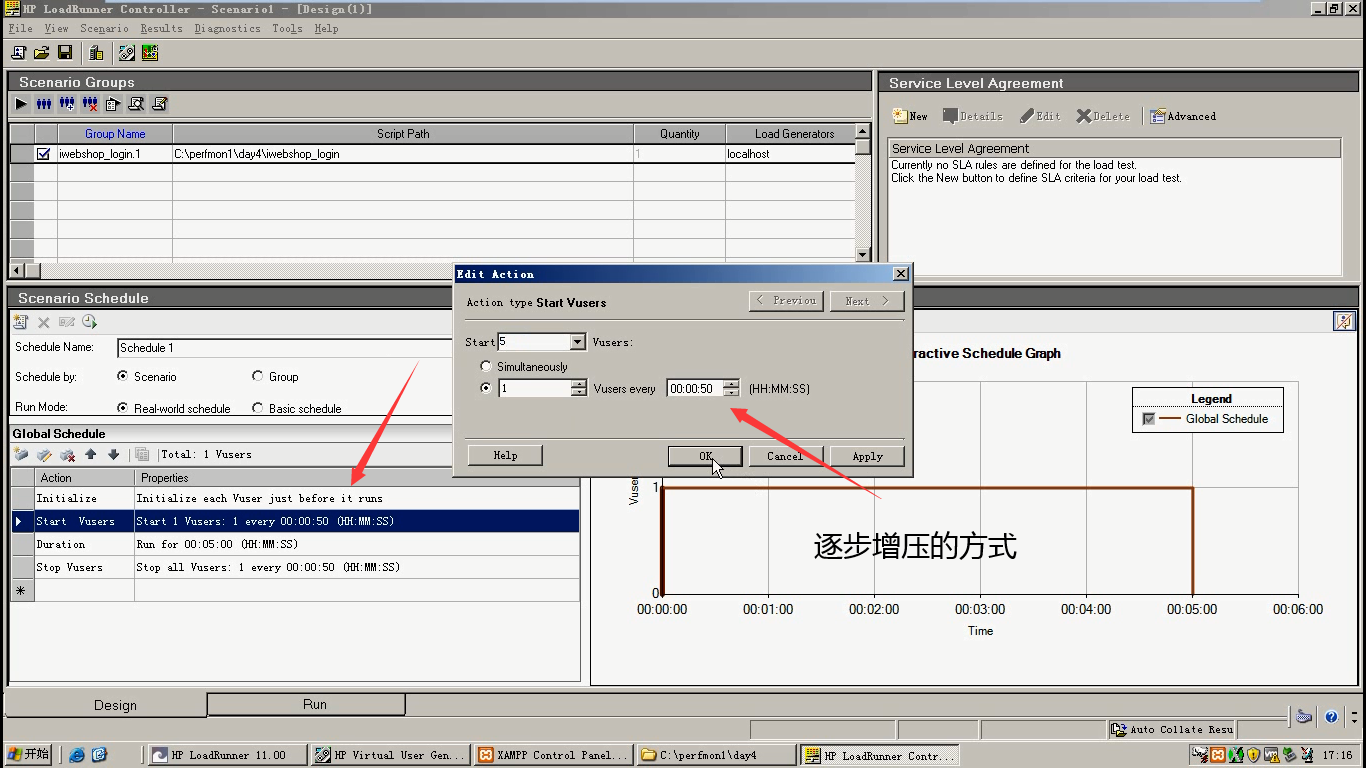
现在我们都是把所有功能写在一个脚本,按照模式的Basic schedule
其实一个功能,写一个脚本,按照组的模式 ,也是可以的。

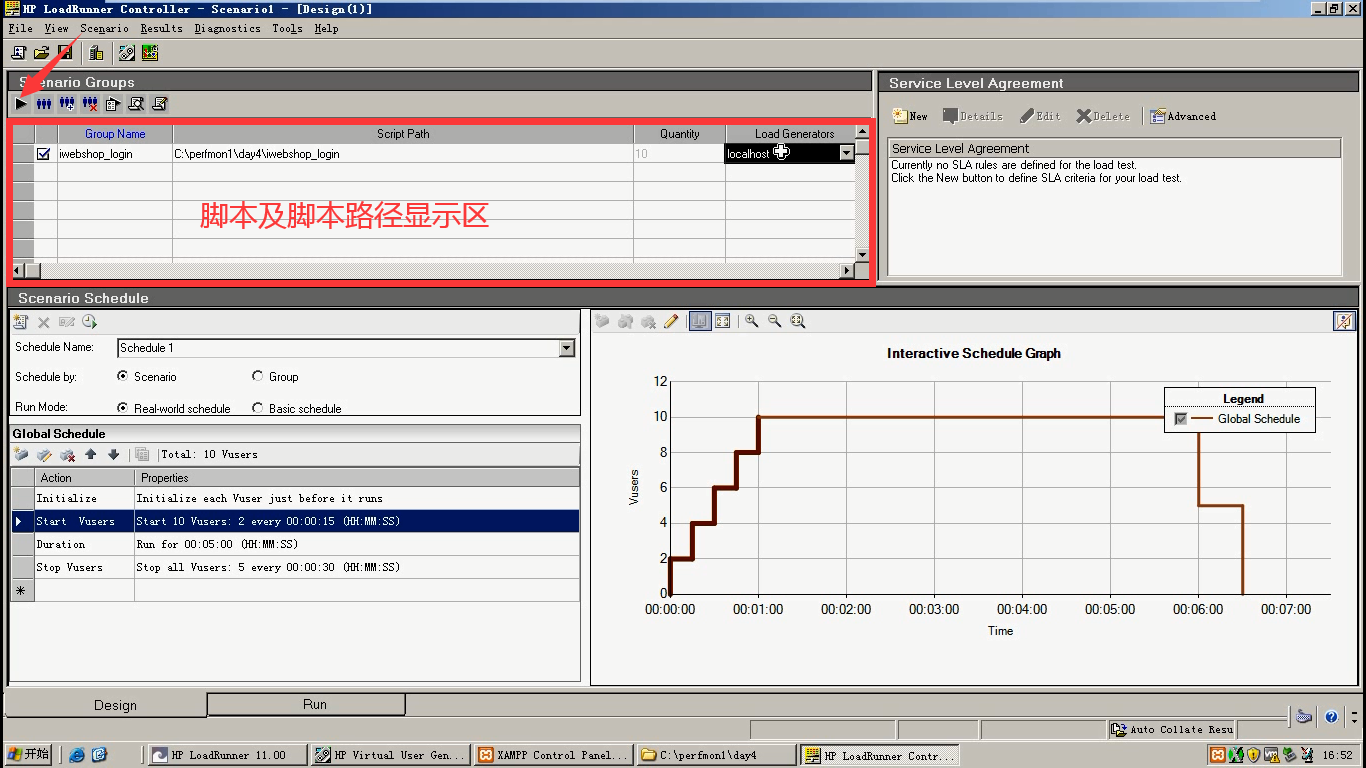
介绍Controller各个功能和区域
1.脚本及脚本路径显示区
- Group Name :脚本名称
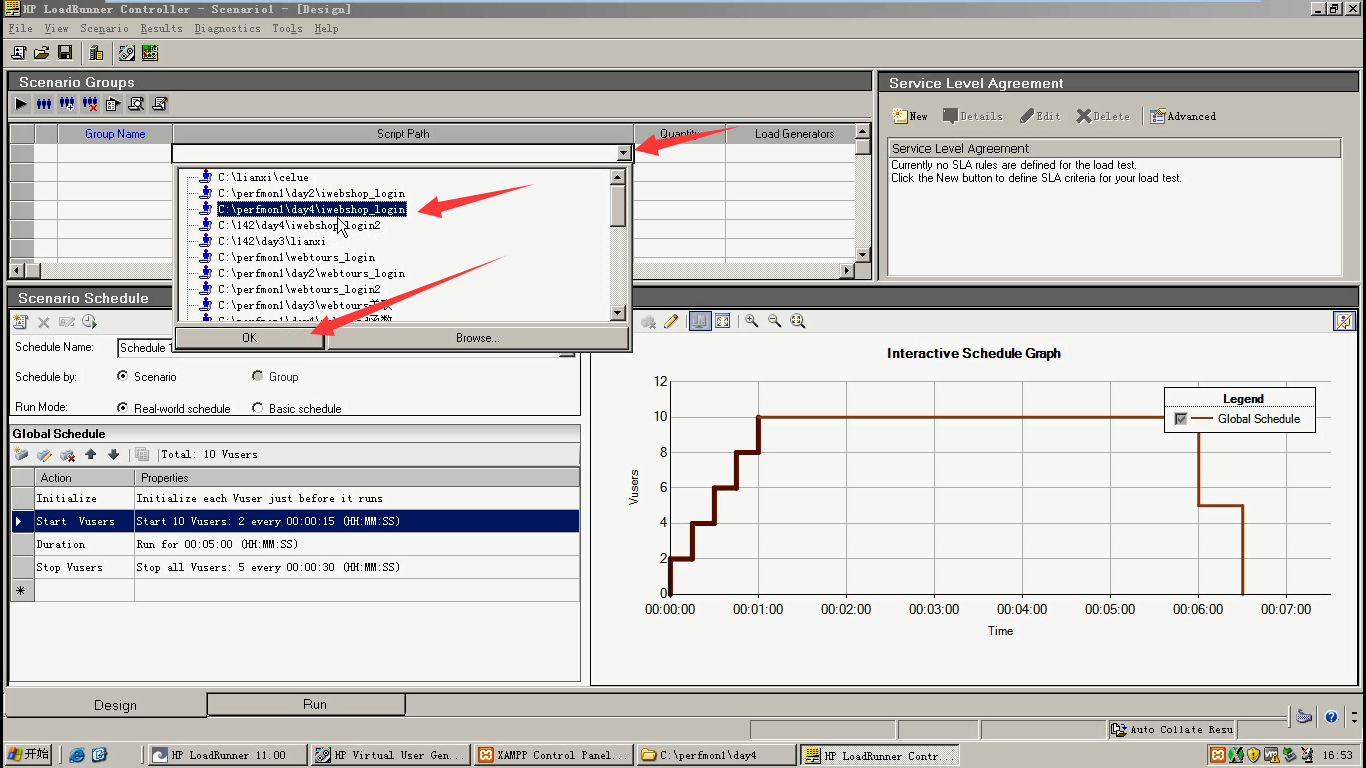
- Script Path:脚本路径(可以更改,换脚本)
- Quantity:用户数量
- Load Generators:压力机(localhost本机)
三角形:运行按钮
2.三个小人:虚拟用户,可以点击Add Vusers:添加用户。
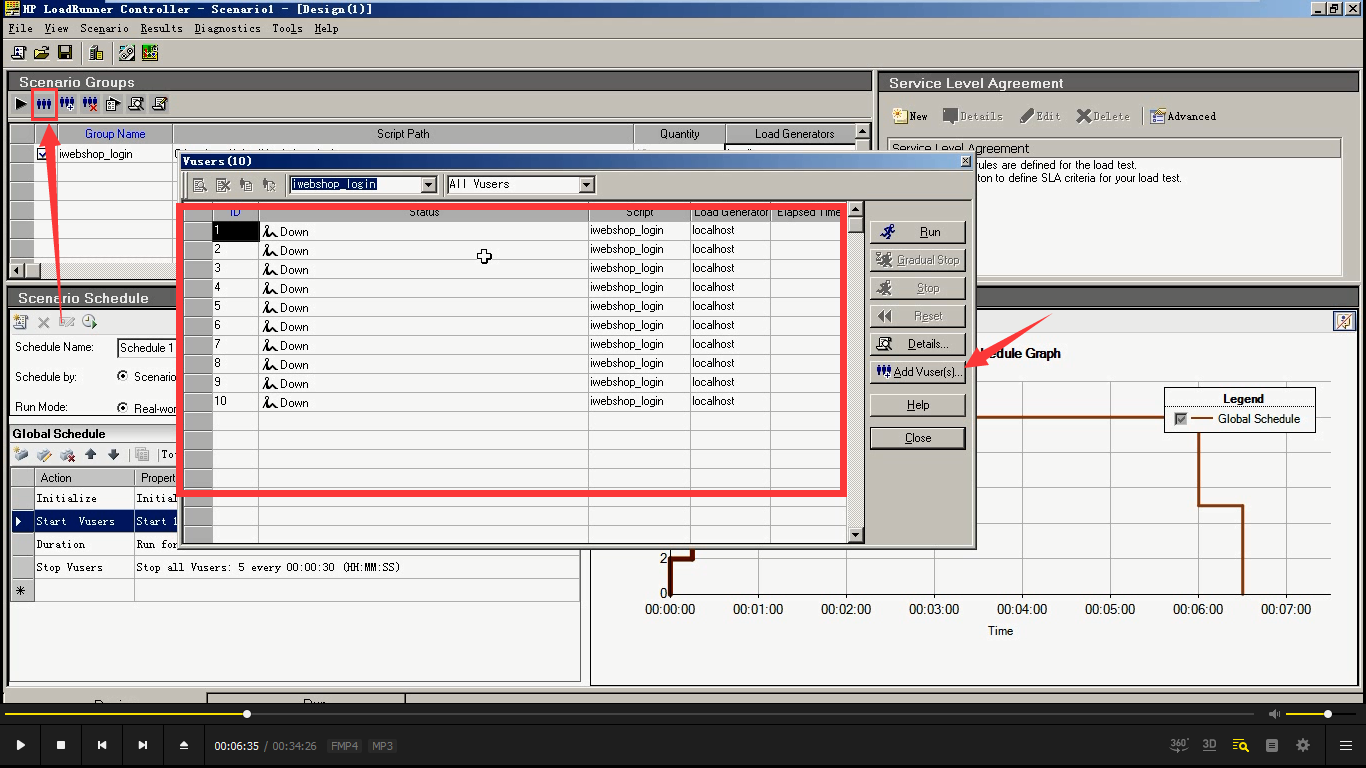
3.三个小人加:添加脚本

4.三个人叉:删除脚本(选中下面的,点击。就删除脚本了。)

删完了,还可以拿进来
5.运行时设置,和脚本区那个东西看着一样。
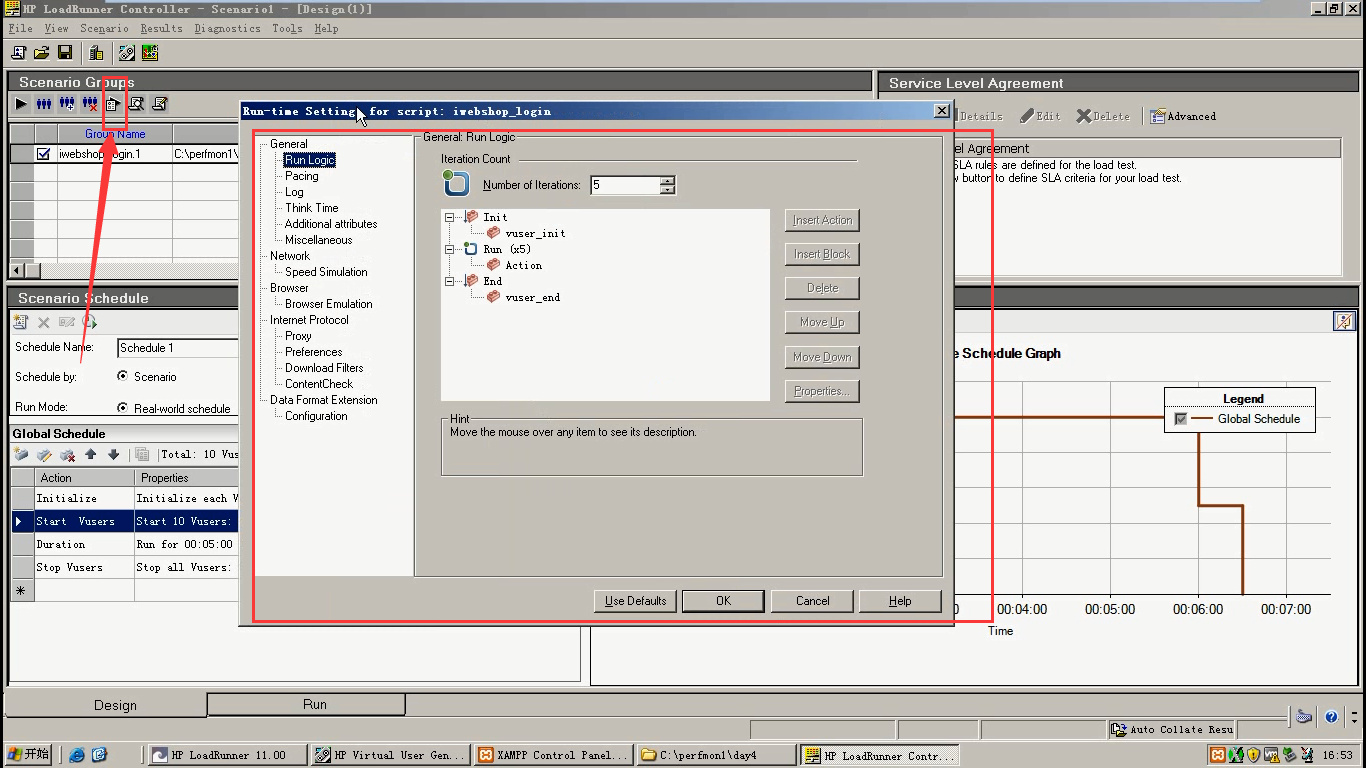
如果:运行脚本时,如果不是让它一次性加上来,而是通过时间加上来。 并且加上来后,让它运行一段时间。Runtime setting设置10000次循环。它是按循环走,还是按时间走。答:是按时间走。
如果Duration没有时间,是按循环走。Duration有运行时间就按时间走。
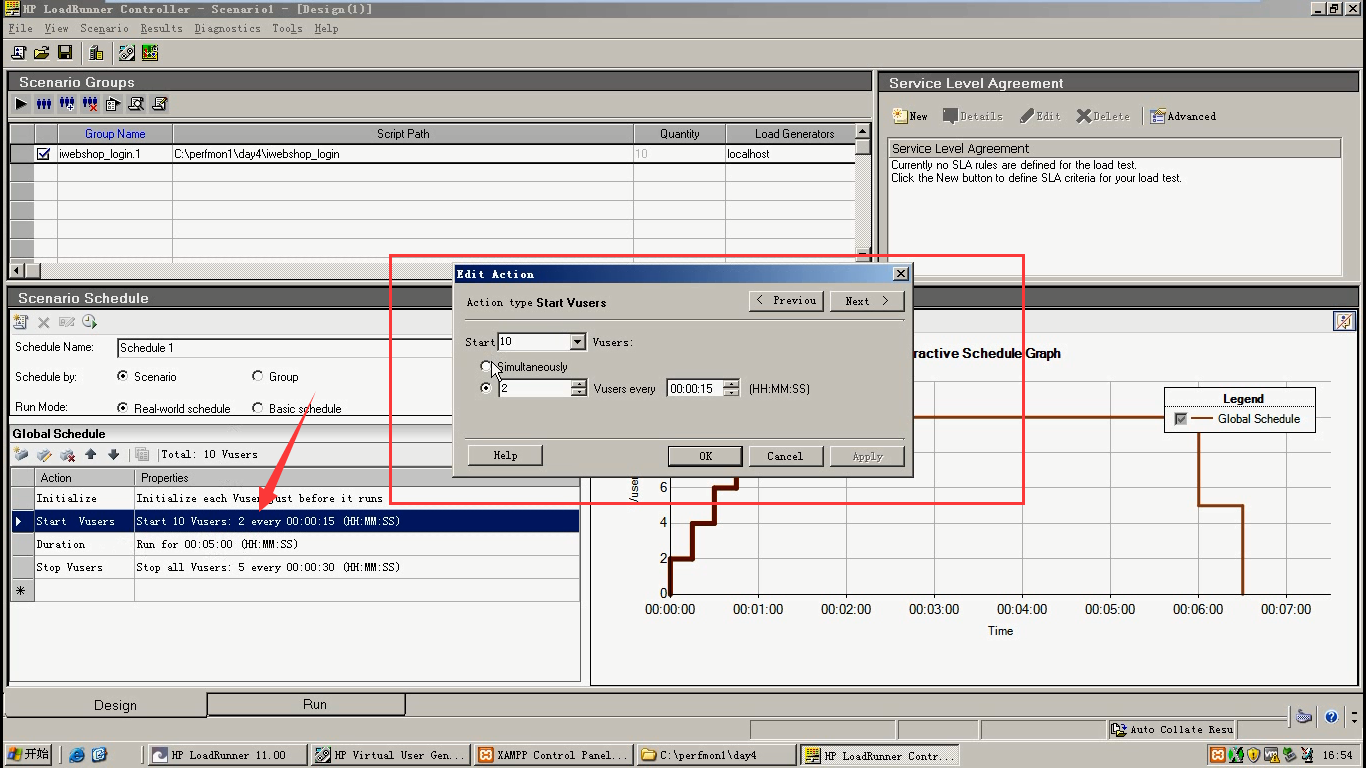
并且加上来后,让它运行一段时间

Runtime setting设置10000次循环
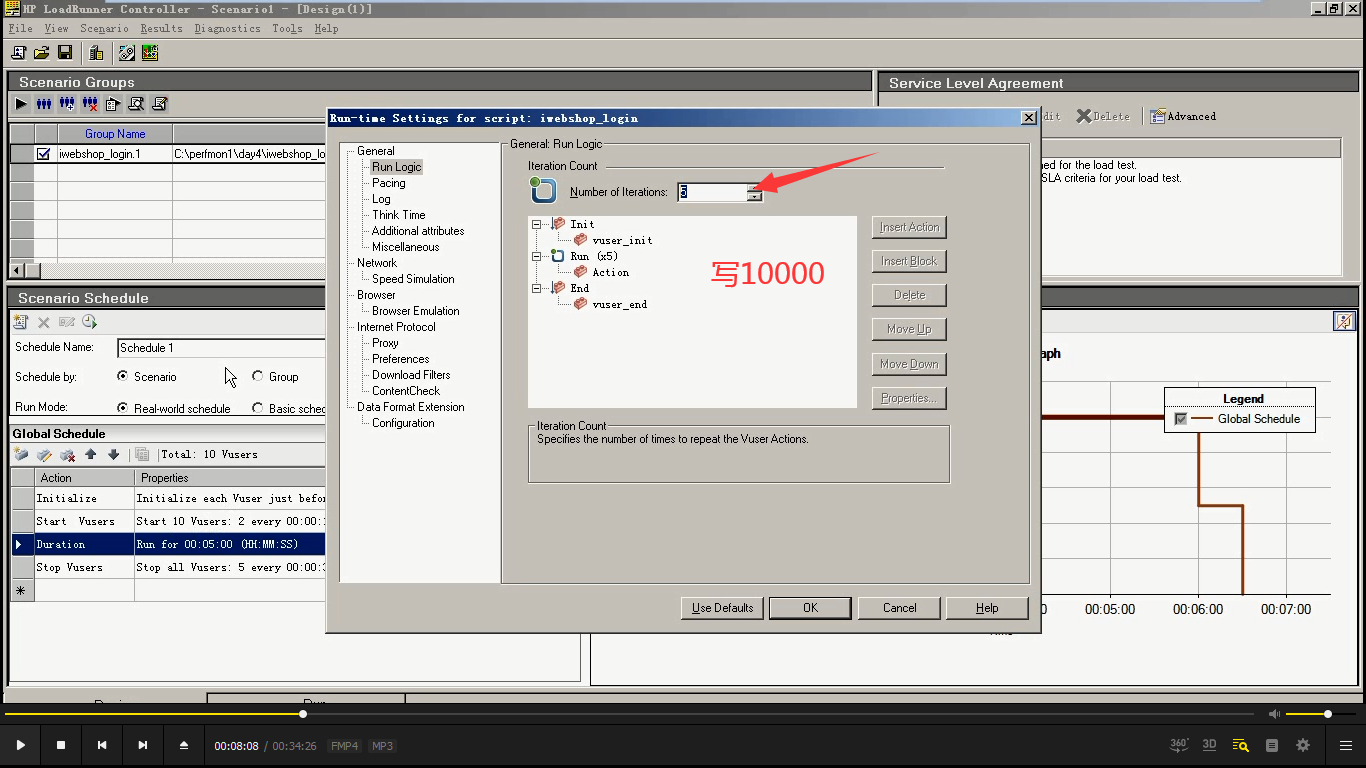
6.如果更改脚本,或者改了脚本的运行设置(迭代次数:1次)。一般是保存,关闭Controller,再Controller重新打开脚本。

现在不需要这样了,直接点检放大镜----Refresh(点击script:重新刷新脚本。点击Runtime setting:刷新脚本运行时设置),点击ok。
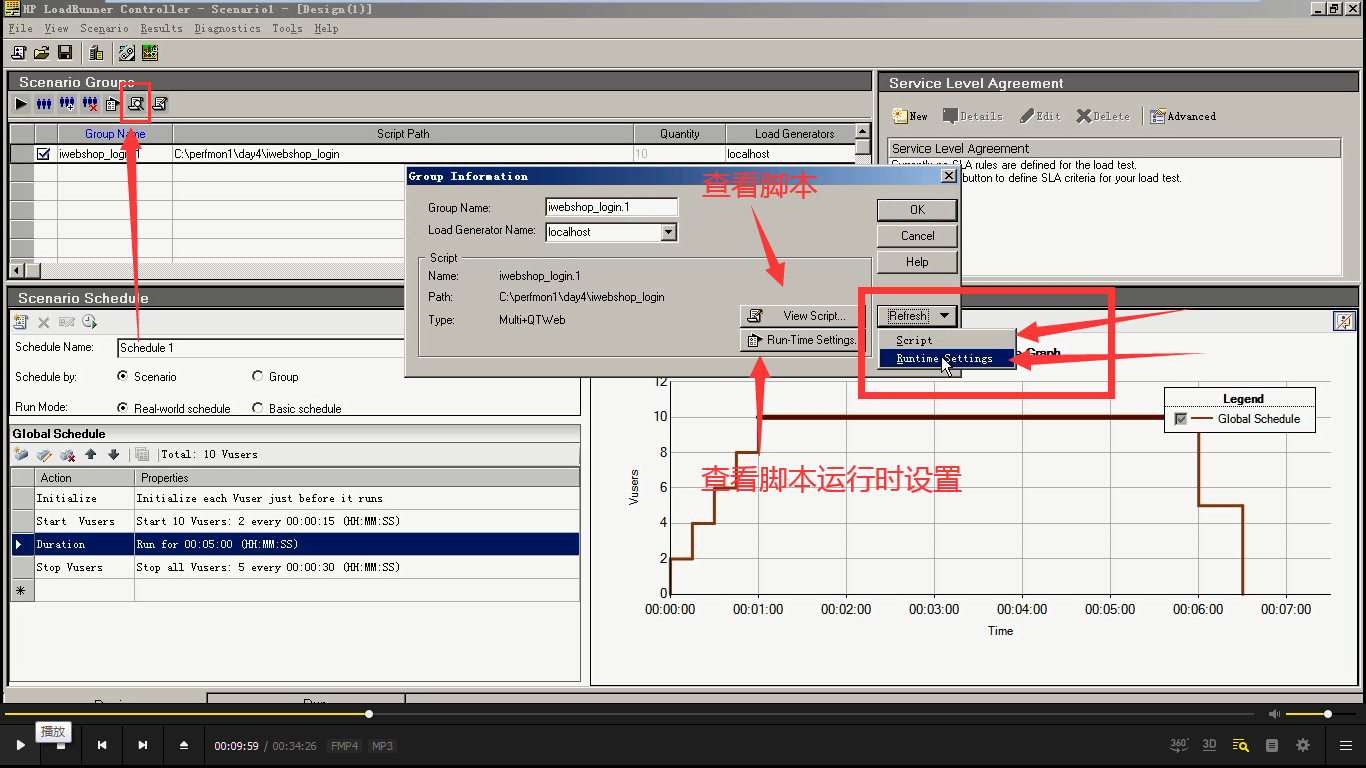
这时候,点击图标。迭代次数就为1次。
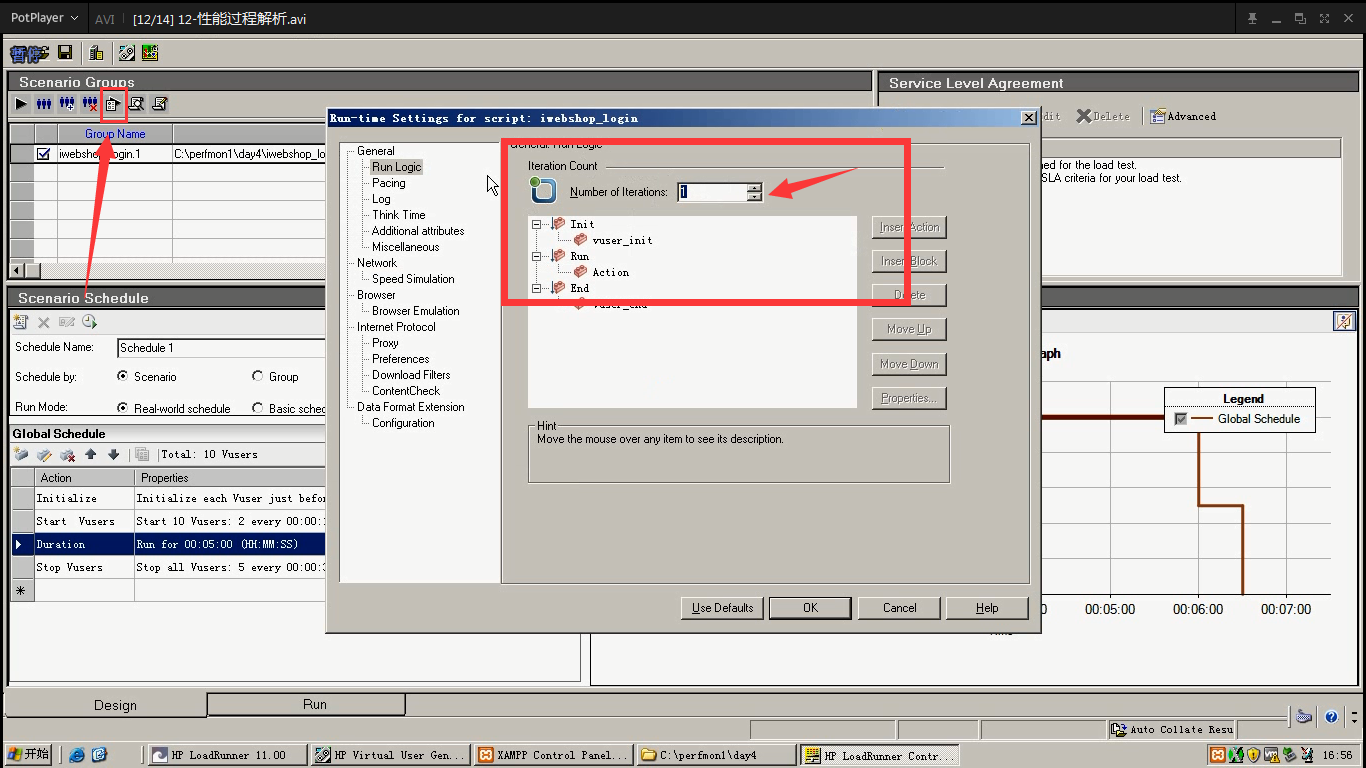
7.点击最右边的---查看脚本,就会打开脚本编辑区。可以编写,如果编写好,就需要保存一下。再点击放大镜-----Refresh(点击script:重新刷新脚本。),点击ok。
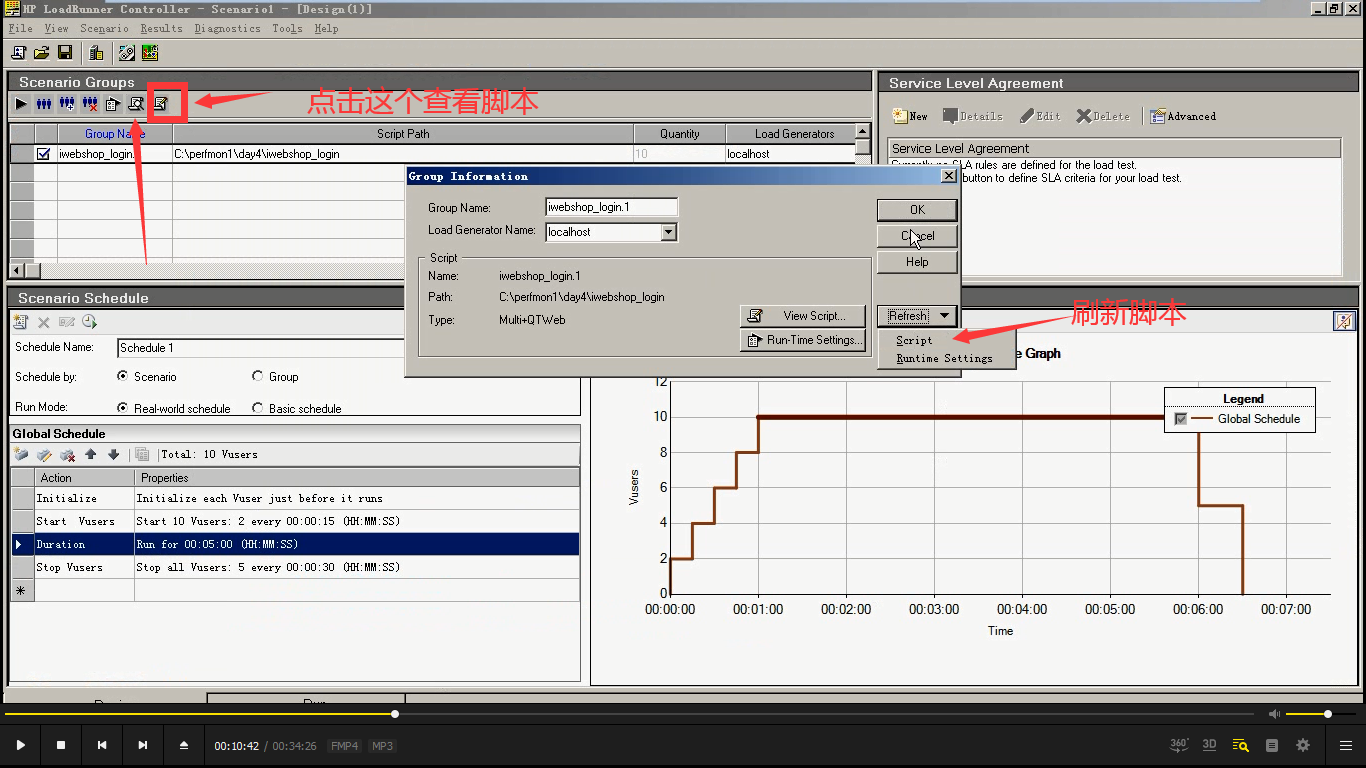
就会打开脚本编辑区。就可以编写,如果编写好,就需要保存一下。

8.小房子图标:压力机
Name :Localhost(当前所用的压力机是本机)
Status:Down(目前状态是没有开启的状态)
Platform:Windows(操作系统为Windows)
看能不能用。直接点击Contect。如果Status为:Ready,就表示可以直接用。
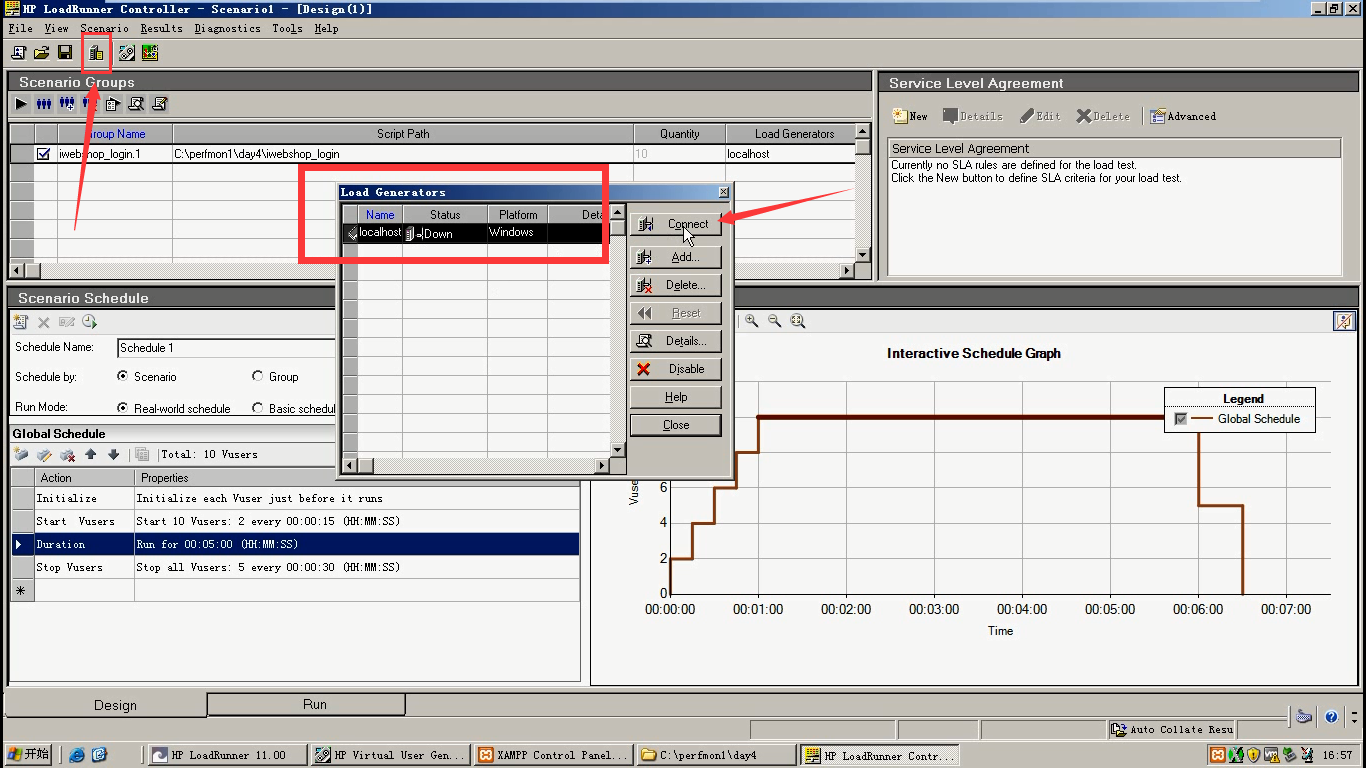
添加压力机:Name为IP(有装LoadRunner或者LoadGenerotr的机器),点击ok。
这个ip可以先ping一下,看可能ping通。
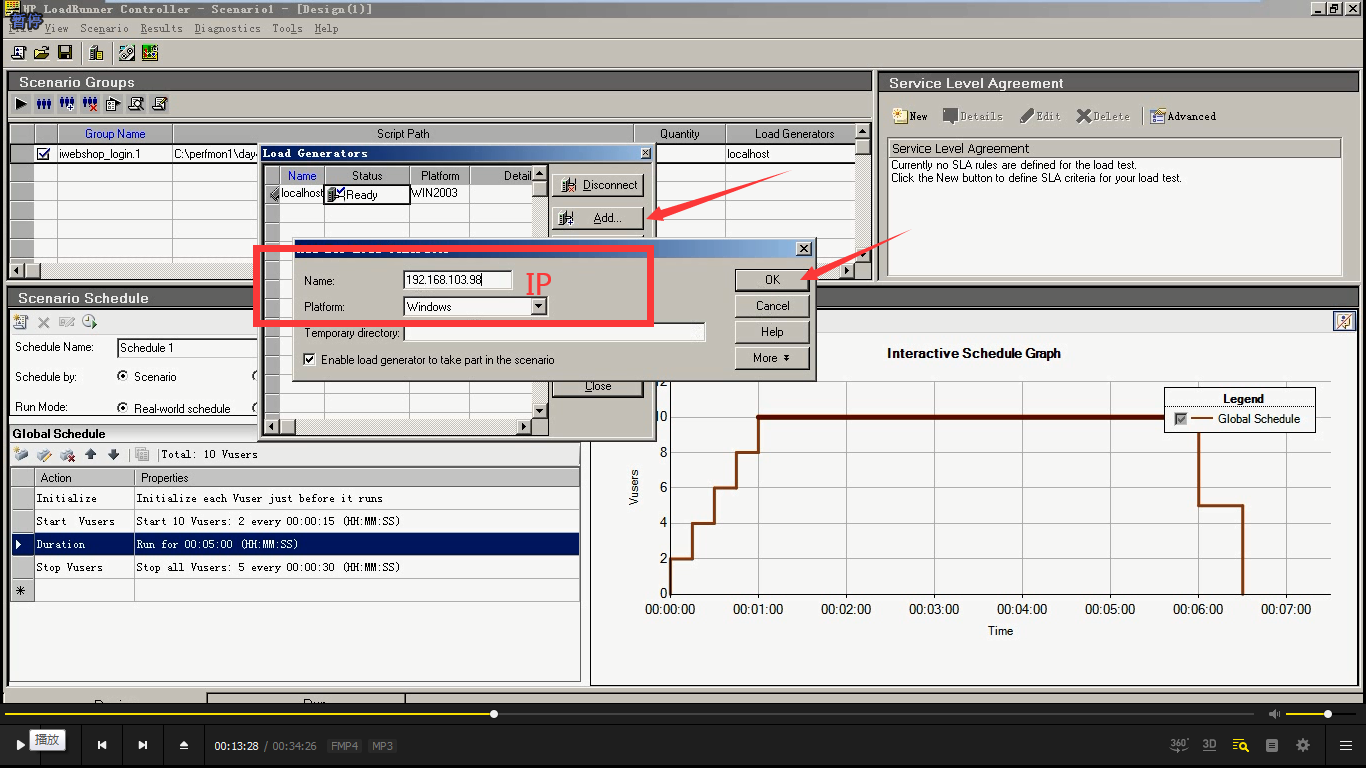
这个时候,又多了一台压力机。而不是Controller,Controller是给这台压力机下命令,让它执行的。
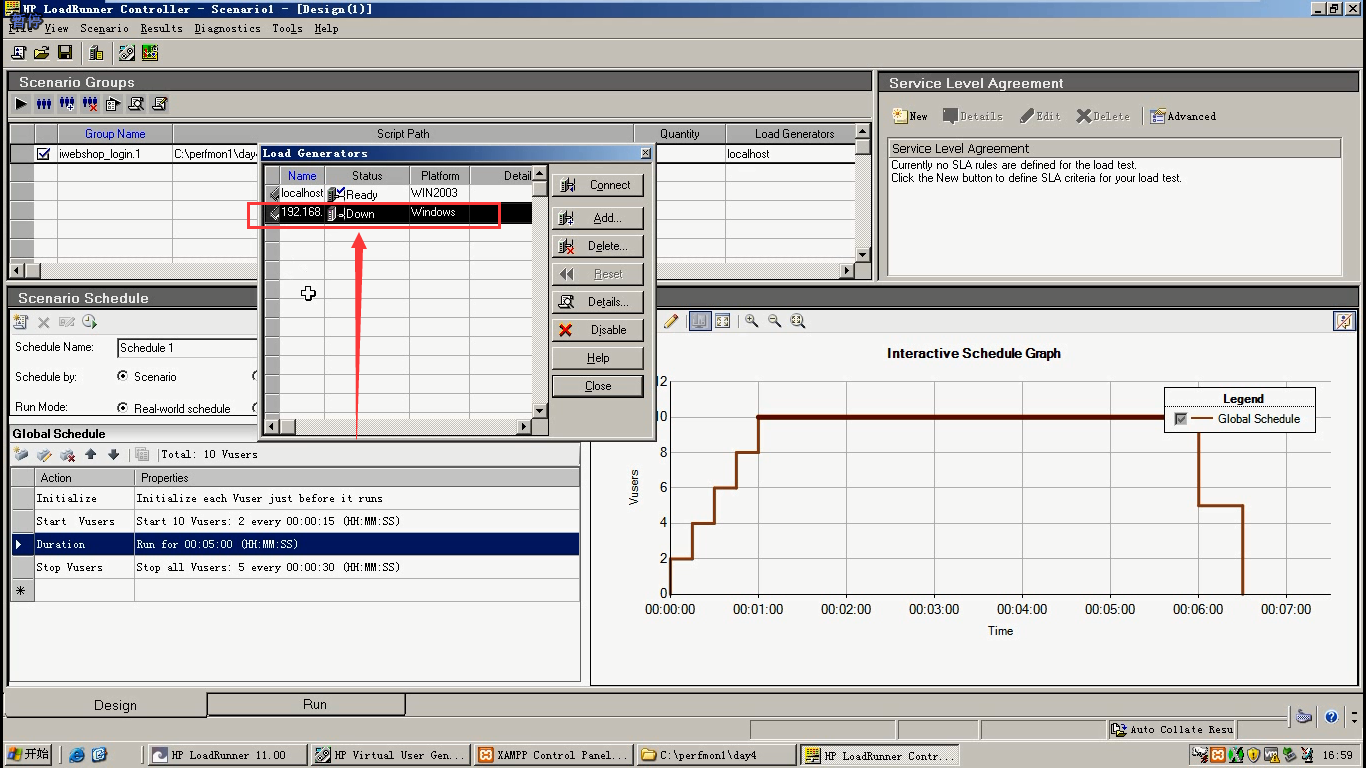
如果想让别的机器,跑我的脚本, 选中这台机器,点击connect。连上即可。只要ping通,那台机器装上压力机(有装LoadRunner或者LoadGenerotr的机器)就可以。
但是有时还是会出现失败,因为对方没有开启压力机代理。你要连的那台机子,需要在开始菜单里,点击LoadRunner Agent Prcoess。再去连它,及出现Ready状态。
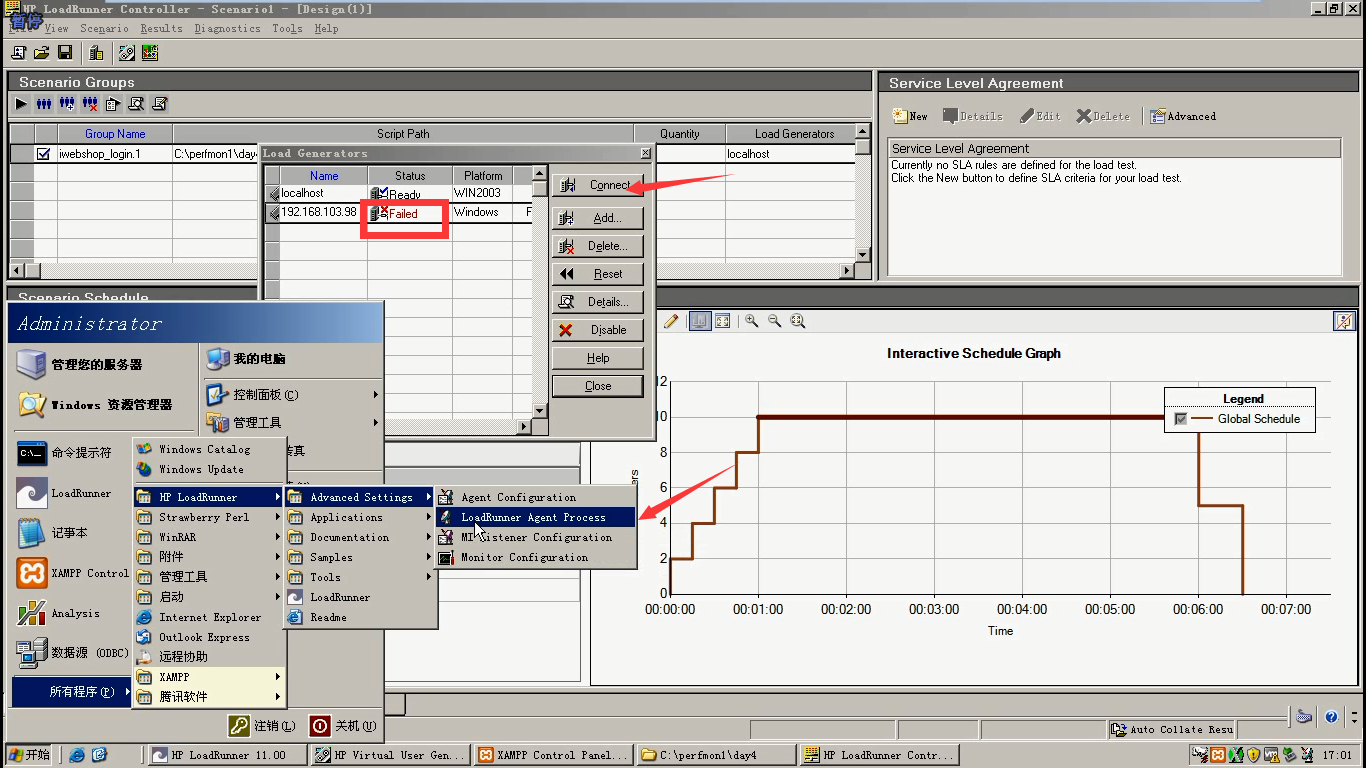
这里还是选择本机作为压力机,选中,点击close
9. 启动Generotr和启动分析器。
10.Scenario Schedule区域
Schedule by(场景方案):1.Scenario(场景形式) 2.Group(脚本形式)
scenario:多个脚本之间按照相同的版模式跑,将总的虚拟用户数按照一定的比例分配给各个脚本。
group:多个脚本之间按照独立设置模式跑,各个脚本可以单独设置虚拟用户、运行时间等。
Run Mode(运行模式):1. Real-world schedule 2.Basic Schedule
组合:Scenario+Basic Schedule
这样的组合,可以设定加载过程,和持续时间来做相应的负载,性能,压力测试。(需要不停的调整里面的策略。)

11.Global Schedule区域介绍
来一张清楚的。
Initialize
双击,显示如下界面:
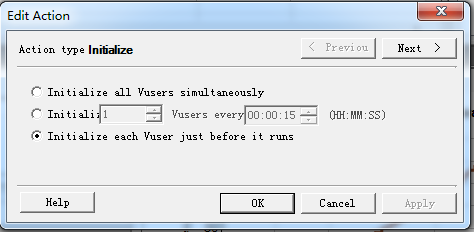
Initialize all Vusers simultaneously:同时加载所有用户
Initialize (1) Vusers every (2):设置每隔(1)时间就添加(2)用户个数
Initialize each Vuser just before it runs:在运行前初始化每一个用户
Start Vusers
双击,显示如下界面:

Start Vusers:输入要加载的总的用户数
Simultaneously:同时加载所有用户
Vusers every:每隔多少时间加载多少用户(逐步增压就是靠这个来做的。)
Duration
双击,显示如下界面:
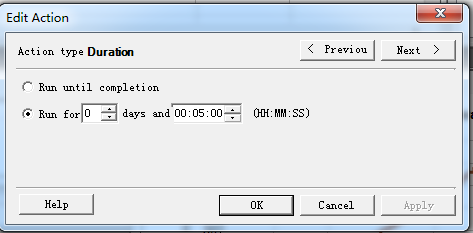
Run until completion:运行直到结束
Run for(1) days and (2):运行(1)天+(2)小时分秒这么长时间
Stop vusers
双击,显示如下界面:

Stop Vuser:停止多少用户数,默认全部
Simultaneously:同时停止所有用户
Vusers every:每多少时间停止多少用户
6.2 负载和压力设置的曲线图(很重要,会画要理解)
1.在性能测试入门的时候,在理解了一些基本的概念等基础知识之后,就需要研究一下性能测试曲线模型。以便获得更加深入的理解。
2.性能测试曲线模型是一条随着测试时间不断变化的曲线,与服务器资源,用户数或其他的性能指标密切相关的曲线。如下图所示。
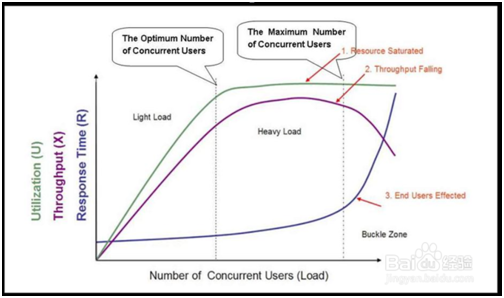
3.在图中,我们的曲线图主要分为3个区域,分别是:轻负载区:light load ,重负载区:heavy load ,奔溃区:buckle load 。
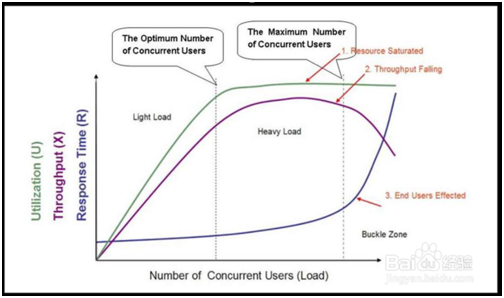
4.图中的3条曲线,分别表示资源的利用情况(Utilization,包括硬件资源和软件资源)、吞吐量(Throughput,这里是指每秒事务数)以及响应时间(Response Time)。
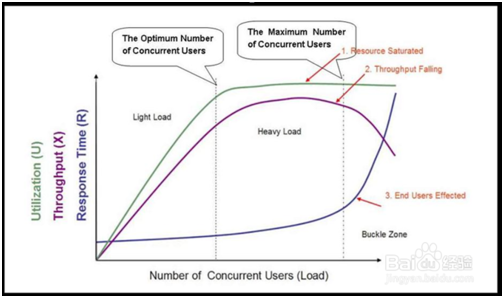
5.图中坐标轴的横轴从左到右表现了并发用户数(Number of Concurrent Users)的不断增长。
6.在进行性能测试的时候,我们需要对图的曲线进行分析。分开来看的时候,响应时间(RT)、吞吐量(TPS)和资源利用率的变化情况分别是:
响应时间:随着并发用户数的增加,在前两个区,响应时间基本平稳,小幅递增。在第三个区域:急剧递增。在第三个区的点为拐点。
吞吐量:随着并发用户数的增加,在前两个区,对于一个良好的系统来说,并发用户数的增加,请求增加,吞吐量增加,中间的区域,处理达到顶点。
在第三个区:资源利用率:呈直线,表示饱和。
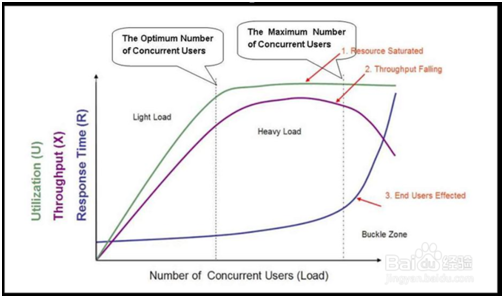
7. 三条曲线合起分析:吞吐量下降,排队现象,服务器宕机,响应时间越来越大。
8.整体的分析思路:
当系统的负载等于最佳并发用户数时,系统的整体效率最高,没有资源被浪费,用户也不需要等待;当系统负载处于最佳并发用户数和最大并发用户数之间时,系统可以继续工作,但是用户的等待
时间延长,满意度开始降低,并且如果负载一直持续,将最终会导致有些用户无法忍受而放弃;而当系统负载大于最大并发用户数时,将注定会导致某些用户无法忍受超长的响应时间而放弃。
关于拐点的理解:

第一拐点:最佳并发用户数点
在这个点可以做并发测试(性能测试的一种)
第二个拐点:最大并发用户数量点。(如果超过它,服务器会崩溃掉。)
在这个点往前一点,可以做压力测试。(压力测试:在一定饱和的情况下持续的压力。)
通过负载测试(逐步增压),可以找到这两个点。
最佳并发用户数点(特点):
- 1.吞吐不再变化
- 2.请求数不再变(因为它处理不掉这么多请求了。)
- 3.每秒处理的事物数也不再变化。
这时候,我们就认为它达到第一个点上了。
最大并发用户数点(特点):
吞吐开始降,响应时间开始急剧增长。(或者说出现了Errors)第二个点就出来了。
6.3手工场景
1)用于设计用户的添加和减少过程,模拟真实用户请求模型
2)设置用户负载方式
1.通过Scenario Schedule中的Schedule by和Run Mode来设置的
2.画曲线图
Initialize
Start Vusers:选1.表示以多少个并发数开始运行的
Duriation:选2.表示持续运行多长时间
Stop Vusers:1.Simultaneously:立即结束 选择2.每多长时间结束几个
点击Add action添加action
3.设置的几种组合
3.1 多个脚本间按照相同模式跑,运行轨迹时一样的:
Scenario+Real-world schedule
3.2 多个脚本之间按照独立设置模式跑
Group+Real-world schedule
3.3 Basic schedule不常用
4.Scenario Groups中的设置
4.1 view Script 用来打开代码,可进行修改代码
4.2 Details---Refresh---script:修改完代码之后要进行刷新下代码
4.3 Details--Run-time Settings
- 1.和代码中的不一样
- 2.Run Logic 设为1
- 3.Log 选择Enable logging -----忽略log
- 4.Think Time选择lgnore think time------忽略think time
- 5.Miscellaneous 选择Run Vuser as a thread------以线程运行
- 6.线程和进程区别(6个用户)
- 按照进程跑:任务管理器中(mmdrv.exe)有6个进程
- 优点:进程独立运行,不发生抢占资源
- 缺点:耗费资源
- 按照线程跑:任务管理器中(mmdrv.exe)有1个进程,在1个进程中有6个线程
- 优点:节省资源,CPU内存
- 缺点:彼此抢占资源,导致有些线程会失败
4.4 Add Group:添加代码
4.5 Vusers----Add Vusers:添加用户