需求:如图,我想把不良反应数据库中的每个药品的不良反应相关信息给获取到
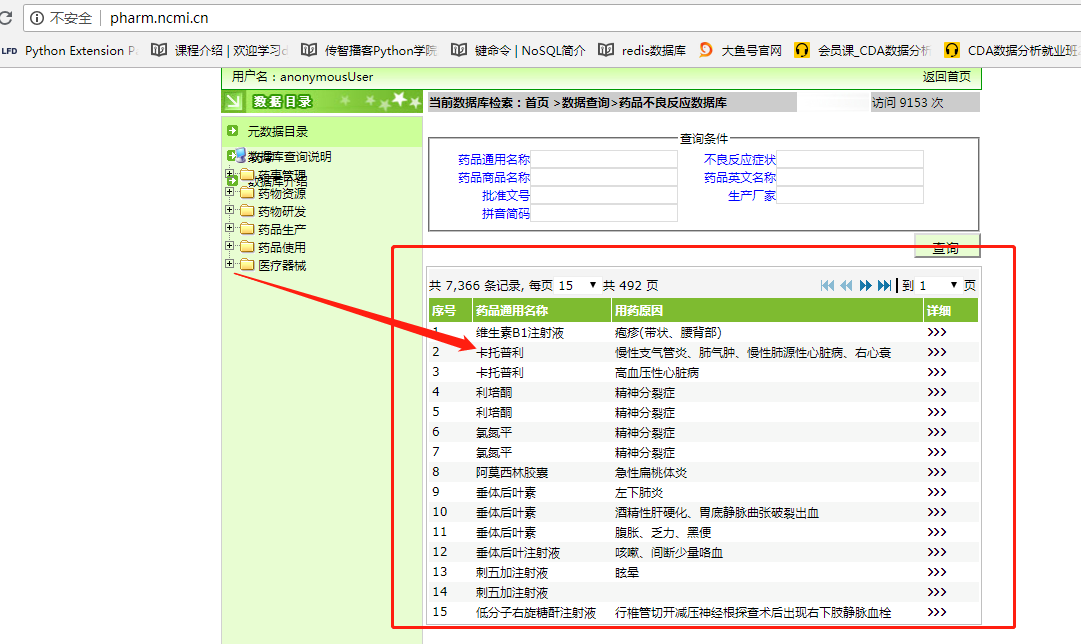
点击详细信息之后
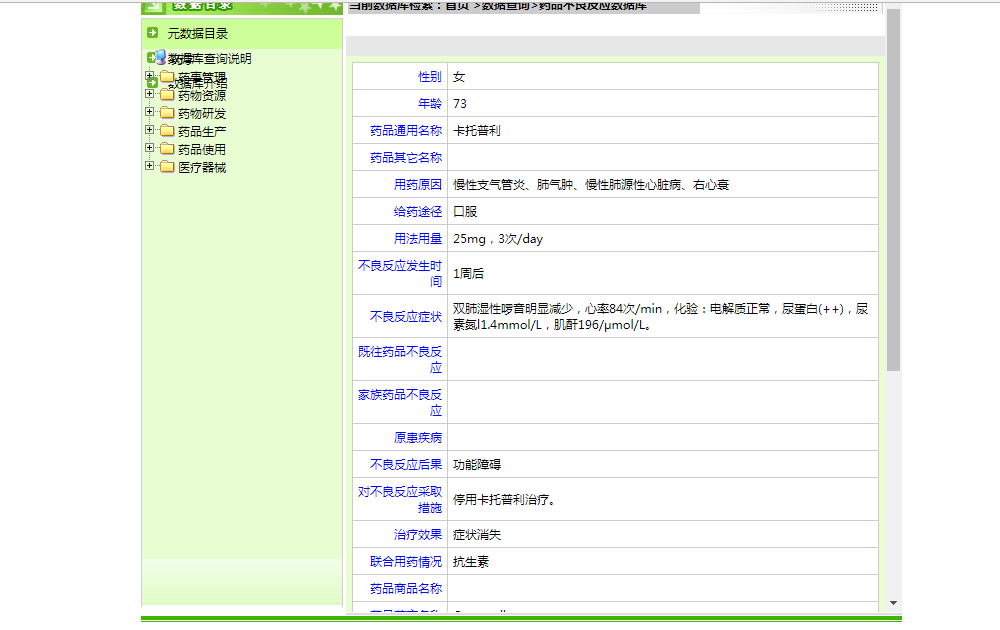
分析页面请求,发现是ajax请求,
- 第一步,我们需要获取详细页面的url,也就是药品ID
- 第二步,拿到详细页面的url,下载页面
- 第三步,提取页面中的适应症和不良反应,并将数据写入文件
代码
# -*- coding: utf-8 -*-
"""
@Datetime: 2019/1/11
@Author: Zhang Yafei
"""
import json
import numpy
import os
from gevent import monkey
monkey.patch_all()
import gevent
from urllib.parse import urljoin
import pandas as pd
import requests
from concurrent.futures import ThreadPoolExecutor
from lxml.etree import HTML
url_list = []
drug_list = []
def task(page):
origin_url = 'http://pharm.ncmi.cn/dataContent/dataSearch.do?did=6'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'}
data = {
'method': 'list',
'ec_i': 'ec',
'ec_crd': 200,
'ec_p': page+1,
'ec_rd': 200,
'ec_pd': page,
}
response = requests.post(origin_url, headers=headers, data=data)
return response
def done(future,*args,**kwargs):
response = future.result()
response = HTML(response.text)
hrefs = response.xpath('//table[@id="ec_table"]//tr/td[4]/a/@href')[1:]
for href in hrefs:
detail_url = urljoin('http://pharm.ncmi.cn', 'dataContent/' + href)
url_list.append(detail_url)
def main():
origin_url = 'http://pharm.ncmi.cn/dataContent/dataSearch.do?did=6'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'}
data = {
'method': 'list',
'ec_i': 'ec',
'ec_crd': 200,
'ec_p': 1,
'ec_rd': 200,
'ec_pd': 0,
}
response = requests.post(origin_url, headers=headers, data=data)
response = HTML(response.text)
hrefs = response.xpath('//table[@id="ec_table"]//tr/td[4]/a/@href')[1:]
url_list = []
for href in hrefs:
# http://pharm.ncmi.cn/dataContent/dataSearch.do?method=viewpage&id=145511&did=6
# http: // pharm.ncmi.cn / dataSearch.do?method = viewpage & id = 144789 & did = 6
detail_url = urljoin('http://pharm.ncmi.cn','dataContent/'+href)
url_list.append(detail_url)
list(map(parse, url_list))
def parse(file):
with open(file=file, encoding='utf-8') as f:
response = f.read()
response = HTML(text=response)
drug_name = response.xpath('//form/table[1]//table/tr[3]/td[2]/text()')[0].strip()
adverse_reaction = response.xpath('//form/table[1]//table/tr[9]/td[2]/text()')[0].strip()
indiction = response.xpath('//form/table[1]//table/tr[last()-1]/td[2]/text()')[0].strip()
if not indiction:
indiction = numpy.NAN
drug_dict = {
'药品通用名称': drug_name,
'不良反应':adverse_reaction,
'适应症': indiction,
}
drug_list.append(drug_dict)
print(file+'提取成功')
def task1(i, url):
response = requests.get(url)
filename = 'html/{}.html'.format(i)
if not os.path.exists(filename):
with open(filename,'w',encoding='utf-8') as f:
f.write(response.text)
if __name__ == '__main__':
# 1.获取所有url
# pool = ThreadPoolExecutor()
# for page in range(37):
# v = pool.submit(task, page)
# v.add_done_callback(done)
#
# pool.shutdown(wait=True)
# 2.将url写入文件
# with open('url.py','w') as f:
# json.dump(url_list, f)
# 3.读取url并下载页面
# with open('url.py') as f:
# url_list = json.load(f)
# pool = ThreadPoolExecutor()
# for i, url in enumerate(url_list):
# v = pool.submit(task1, i, url)
#
# pool.shutdown(wait=True)
# 4.读取页面提取有用信息,并写入文件
for base_path, folders, files in os.walk('html'):
file_list = list(map(lambda x:os.path.join(base_path, x), files))
# list(map(parse, file_list))
pool = ThreadPoolExecutor()
for file in file_list:
v = pool.submit(parse, file)
pool.shutdown(wait=True)
df = pd.DataFrame(data=drug_list)
df = df.loc[:, ['药品通用名称','适应症','不良反应']]
writer = pd.ExcelWriter('adverse_reaction_database.xlsx')
df.to_excel(writer, 'adverse_reaction', index=False)
writer.save()