朋友们可以关注下我的公众号,获得最及时的更新:

或者关注我的知乎账号 : https://www.zhihu.com/people/zhangyachen
关于分支预测的基本概念和详细算法可以参考我之前写的知乎回答,基本概念不再阐述了~~
https://www.zhihu.com/question/486239354/answer/2410692045
说几个常见的能够提升CPU分支预测效率的方法。
将最常见的条件比较单独从switch中移出
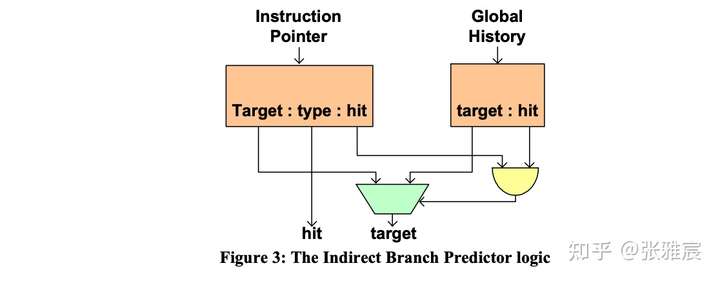
分支预测除了需要预测方向,还需要预测分支的目标地址。目标地址BTA(Branch Target Address)分为两种:
- 直接跳转(PC-relative, direct) : offset以立即数形式固定在指令中,所以目标地址也是固定的。
- 间接跳转(absolute, indirect):目标地址来自通用寄存器,而寄存器的值不固定。
对于直接跳转,使用BTB可以很好的进行预测。但是对于间接跳转,目标地址不固定,更难预测。switch-case的指令实现(类似jmpq *$rax,$rax是case对应label地址)、C++虚函数调用就属于间接跳转。间接跳转如果还用直接跳转的BTB预测,准确率只有50%左右。
很多CPU针对间接跳转都有单独的预测器,比如的Intel的论文The Intel Pentium M Processor: Microarchitecture and Performance中介绍额Indirect Branch Predictor:通过额外引入context-information——Global Branch History来提高间接跳转的目标地址预测准确率。
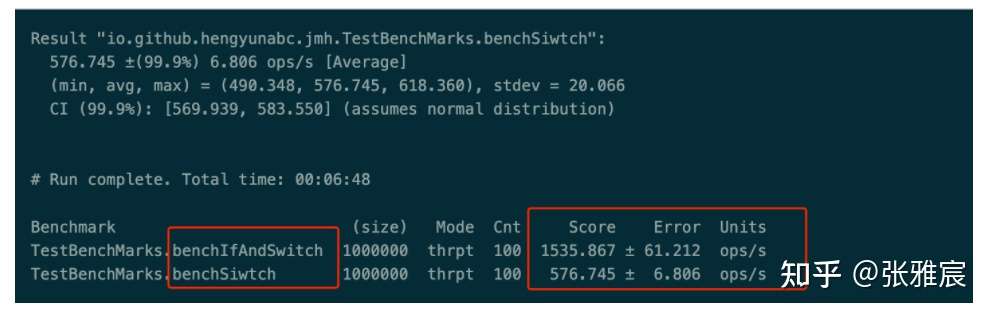
switch-case的优点是将诸多if/else(conditional branch)转换为统一的unconditioal branch,但缺点就是目标地址难以预测。如果某个case的命中率特别高,就可以将其从switch中单独提出来,这样该分支的预测方向 && 目标地址都很好预测。

超过99.9%情况state取值都是ChannelState.RECEIVED ,将其单独提出来。官网博客有一个benchmark,性能有很大的改观。
将使用【控制】的条件转移转换为使用【数据】的条件转移
CMOV指令就是典型的例子。CPU无需进行分支预测,但是会计算一个条件的两种结果,然后通过检查条件码,要么更新目的寄存器,要么保持不变。
比如
v = test-expr ? then-expr : else-expr会转换为下列伪代码:
v = then-expr;
ve = else-expr;
t = test-expr;
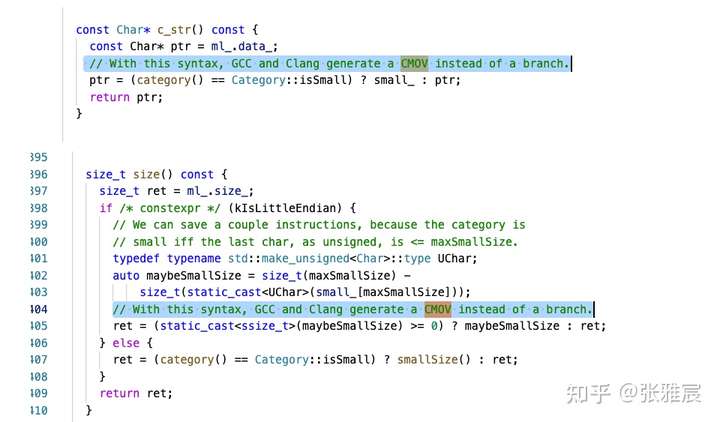
if(!t) v=ve;编译器会倾向于将使用三元运算符且两种结果的计算量不大的表达式转换为CMOV条件数据转移。例如facebook folly中的例子,注意看注释:
当分支的结果完全由外部输入决定,local branch history和global branch history都毫无规律时,效果会更好。下面这个是《Computer Systems A Programmer's Perspective 》5.11.2小节的例子,第二个版本性能是第一个三倍:
/* Rearrange two vectors so that for each i, b[i] >= a[i] */
void minmax1(long a[], long b[], long n) {
long i;
for (i = 0; i < n; i++) {
if (a[i] > b[i]) {
long t = a[i];
a[i] = b[i];
b[i] = t;
}
}
}
/* Rearrange two vectors so that for each i, b[i] >= a[i] */
void minmax2(long a[], long b[], long n) {
long i;
for (i = 0; i < n; i++) {
long min = a[i] < b[i] ? a[i] : b[i];
long max = a[i] < b[i] ? b[i] : a[i];
a[i] = min;
b[i] = max;
}
}使用算数逻辑代替分支
比如ARM优化手册里提到,可以将范围比较转换为无条件计算,编译器有时候也会自动做这个转换:
// origin version
int insideRange1(int v, int min, int max) {
return v >= min && v < max;
}
// optimized version
int insideRange2(int v, int min, int max) {
return (unsigned) (v - min) < (max - min);
}韦易笑大佬针对这个做过更详细的优化和测试,反正我是看晕了:
引用文章内的测试数据:
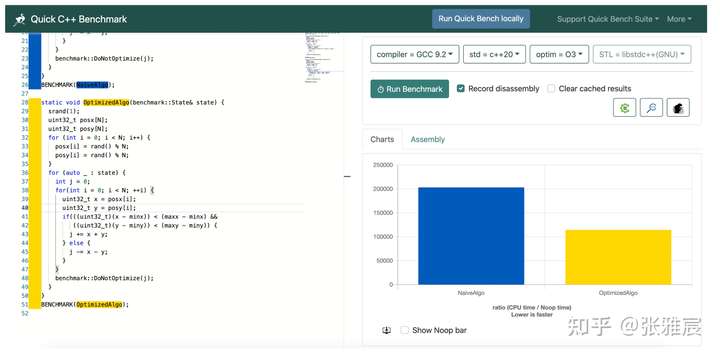
Avoiding Branches里有更多的例子,不过用之前还是做测试更靠谱。
使用template移除分支
2018年Stephen Yang的博士论文NanoLog: A Nanosecond Scale Logging System介绍了一款C++日志库Nanolog,将日志调用开销的中位数降为了个位数纳秒级别。作者在文章NANOLOG: A NANOSECOND SCALE LOGGING SYSTEM中提到了Nanolog的关键技术和优化,第三条就是将printf在运行时的大量分支逻辑利用C++ template优化成编译期的运算。

likely/unlikely
这个很多人已经介绍过了,C++20已经将其标准化,支持将更可能执行的代码放在hot path上,对icache更友好。例如facebook folly中的例子:
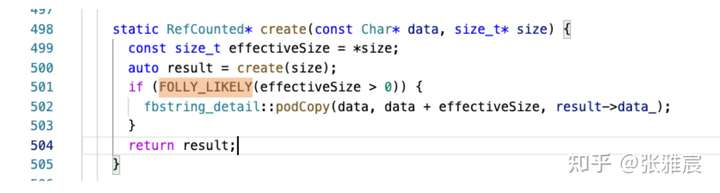
FOLLY_LIKELY是一个包装:

更进一步,有些ISA的分支指令有一个bit,支持programmer去指定分支是否taken。现代CPU使用的TAGE分支预测器,部分实现会使用该bit去初始化predictor(是初始化,不是一直使用programmer指定的跳转结果)。TAGE预测器可以参考下我开头放的回答:https://www.zhihu.com/question/486239354/answer/2410692045

(完)
朋友们可以关注下我的公众号,获得最及时的更新: