要求0:作业地址:https://edu.cnblogs.com/campus/nenu/2016CS/homework/2110
要求1:git仓库地址:https://git.coding.net/NekoMia/wf.git
要求2:
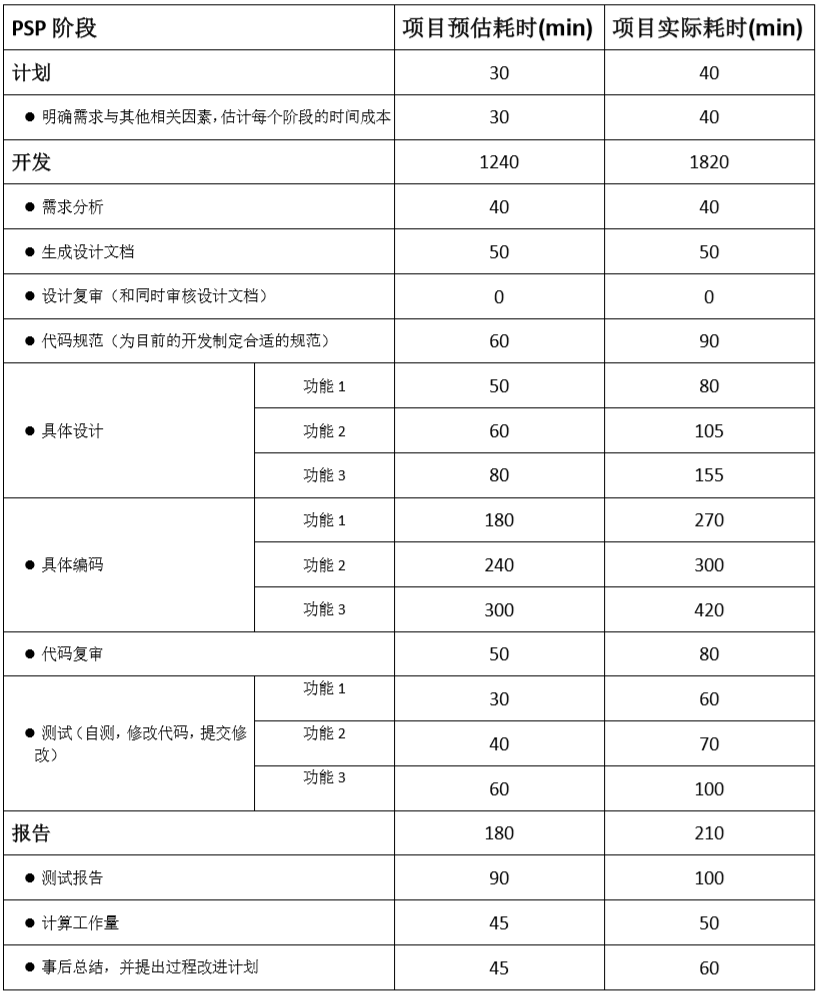
1.词频计数项目PSP表格:
2.对于预估时间与实际时间差距所产生的原因分析:
- 这次编程我是用的是JAVA语言,这门语言我已经有接近一年没有使用过了,对语言掌握的不熟练是导致差距的原因之一。
- 这次编程需要实现三个功能,并且每一个功能的输出要求有差别,在前期具体设计上,只想着一步一步的来完成,比如先完成文本文件的读取,再实现对文件的分割,再对分割单词进行合法性判断,最后进行输出处理。预想的步骤是这样,但实际在网上搜索资料时,并无法单独的把这些功能叠加,需要进行关联修改,导致具体编码以及修改代码时耗费过多时间。
- 这次编程的分割部分查阅资料时,发现大多用到正则表达式,但是自己并没有使用过正则表达式,于是在网上搜索了许多关于正则表达式的资料,并且一一进行尝试,刚开始时,始终不太清楚怎样编写符合自己要求的正则表达式,在网上也搜索了分割单词的正则表达式,但都没能完全满足,于是边学习边构思自己的正则表达式,所以在这个过程中也耗时颇多。
要求3:
1.解题思路描述:
(1)功能类(wfDao.java)的解决思路:刚开始看完整个题目要求时,我发现需要实现3个功能,并且功能是依次深入的,于是我先看了一遍功能1的要求以及样例输出,大概有了思路是:读取文本文件——>文件单词分割——>判断单词是否符合要求——>按样例输出处理。
在查阅资料后,发现这篇博客(https://blog.csdn.net/u010908743/article/details/40302429)的这张图,感觉思路很清晰,奉上:

功能1:由于使用的是比较生疏的JAVA语言(为什么使用它, 是基于之前室友用C写的代码时候十分的长,所以。。。),于是我按照这个思路一步步的去查阅相关资料,使用BufferedReader完成了文件的读取。第二部是文件分割,基于之前Python的学习基础,知道有split这个函数,于是按照这个搜索,又获取到了Pattern与Matcher的搭配使用,但是在正则表达式上没太能解决,后来搜索了许多资料(推荐这个正则表达式大全http://www.cnblogs.com/shuqi/p/4427693.html),完成了预期的效果。判断单词是否符合要求这一步还比较顺利,最后是样例输入,发现功能1的输出顺序总是字典序,查阅后发现Java将Map对象按字典序排列,并且封装成URL的工具类,于是又进行了一步处理,使其按文本顺序输出。其中参考博客(https://blog.csdn.net/wxz_2014/article/details/52850550)
功能2:有了功能1的基础,功能2只需要将文件名改为文件路径即可,于是开始查阅如何获取文件夹路径,完成了readFile这一功能。
功能3:功能3主要是多了按照词频排序这一步,在查阅过程中发现了Collections的sort()方法,于是用它实现了词频排序。
(2)主函数(wfMain.java)的解决思路:测试类主要是对命令行的获取与处理,经过3个功能的观察,发现根据命令的长度,判断为-c还是-f以及-c,-f的位置完成这3个功能的区分。于是仍然是以空格符处理输入的命令,然后通过if-else来进行判断,并调用相对应的函数功能进行处理。
2.代码重难点:
(1)难点:其一是正则表达式的运用,刚开始查阅相关资料接触到它时,真的感觉有些乱,看不懂,不懂他们为什么那样组合,组合成那样可以实现怎样的功能。虽然用到它的只有分割以及判断合法性那里,但我感觉却是非常重要的一个地方,一旦无法正确分割,正确识别,输出样本必然是不对的。其二是文件夹路径的获取,其三是按词频顺序输出,这三个是3个功能的核心。
(2)重点代码片段展示:
PS:在wfDao.java中已声明:
private String path; private String line; StringBuffer words = new StringBuffer(); Set<String> wdSet = new HashSet<String>(); private HashMap<String,Integer> map = new HashMap<String,Integer>();
1)process_c()函数:还有precess_f()函数与process()函数,由于这三个函数异曲同工,此处只展示其一
/** 函数名:process_c()
* 函数功能:当cmd命令为 wf -c 文件名时,读取文件、单词计数
*/
public void process_c() {
try {
FileInputStream iptStream = new FileInputStream(new File(path));
@SuppressWarnings("resource")
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(iptStream));
//将文本文件内容存入words中
String line = bufferedReader.readLine();
while(line != null) {
//由于readLine在读取时一行一行读取,所以需要手动换行
words.append(line + " ");
line = bufferedReader.readLine();
}
//将文本转换成小写,满足输出的单词均为小写字母的要求
String str = words.toString().toLowerCase();
//使用正则表达式"[^a-zA-Z0-9]|\s"分割字符串,将其存入word数组
String[] wd = str.split("[^a-zA-Z0-9]|\s");
int num =0;
Map<String,Integer> Map = new TreeMap<String,Integer>();
for(int i = 0; i < wd.length; i++) {
boolean contains = Map.containsKey(wd[i]);
//判断单词是否有效
if(isValid(wd[i])) {
//判断Map集合对象中是否包含该单词。如果Map集合中包含该单词,则返回true,否则返回false
if(contains) {
num = Map.get(wd[i]);
//Java将Map对象按字典序排列,并且封装成URL的工具类
Map.put(wd[i], num+1);
}
else {
Map.put(wd[i], 1);
}
}
}
List<Map.Entry<String, Integer>> list = new ArrayList<Map.Entry<String,Integer>>(Map.entrySet());
System.out.println("total" + " " + list.size());
//解决Map对象按字典序排列的问题,使其满足功能1的输出格式
for(int i = 0; i < wd.length; i++) {
boolean contains = Map.containsKey(wd[i]);
if(contains) {
System.out.printf("%-15s %d
", wd[i], Map.get(wd[i]));
Map.remove(wd[i]);
}
}
bufferedReader.close();
iptStream.close();
}catch(FileNotFoundException e) {
System.out.println("找不到指定文件!");
}catch(IOException e) {
System.out.println("文件读取错误!");
}
}
2)isValid()函数:
/** 函数名:isValid()
* 函数功能:判断所分割的单词是否有效
* @param wd(分割的单词word)
* @return
*/
public boolean isValid(String wd) {
//以字母开头,只接收大小写字母和数字的字符串
String reg = "^[a-zA-Z][a-zA-Z0-9]*$";
//Pattern类用于创建一个正则表达式,也可以说创建一个匹配模式,它的构造方法是私有的,不可以直接创建,
//但可以通过Pattern.complie(String regex)简单工厂方法创建一个正则表达式,
Pattern p = Pattern.compile(reg);
Matcher m = p.matcher(wd);
if(m.matches()) {
return true;
}else {
return false;
}
}
3)判断输入命令的if-else片段:
if(cmd.length == 3)
{
//当输入语句为 wf -c 文件名时
if(cmd[1].equals("-c"))
{
path = cmd[2];
wfDao word = new wfDao(path);
word.process_c();
}
//当输入语句为 wf -f 文件路径时
else
{
wfDao word = new wfDao();
path = word.readFile(cmd[2]);
word.setpath(path);
word.process_f();
}
}
else if(cmd.length == 5)
{
//当输入语句为 wf -f 文件路径 -n 数量时
if(cmd[1].equals("-f"))
{
wfDao word = new wfDao();
path = word.readFile(cmd[2]);
word.setpath(path);
word.process(Integer.parseInt(cmd[4]));
}
//当输入语句为wf -c 文件名 -n 数量
else if(cmd[1].equals("-c"))
{
path = cmd[2];
wfDao word = new wfDao(path);
word.process(Integer.parseInt(cmd[4]));
}
//当输入语句为 wf -n 数量 -c 文件名
else if(cmd[3].equals("-c"))
{
path = cmd[4];
wfDao word = new wfDao(path);
word.process(Integer.parseInt(cmd[2]));
}
//当输入语句为 wf -n 数量 -f 文件路径
else if(cmd[3].equals("-f"))
{
wfDao word = new wfDao();
path = word.readFile(cmd[4]);
word.setpath(path);
word.process(Integer.parseInt(cmd[2]));
}
(3)结果展示:
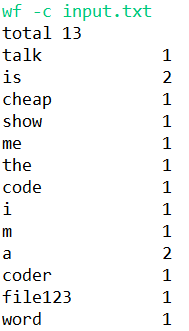

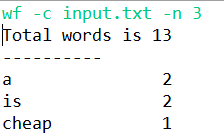



ps:另附一张网上找的英文文本的词频分析展示

(4)项目的心路历程与收获:
通过这次编程经历,我真的是重拾了很多东西,由于自己总是上完某节课之后就基本不会再去使用这课上所学习到的语言,除非是自己感兴趣的所,以Java真的是忘了很多。初期编程时,其实十分手足无措,找了好几个代码,但是修改都不太成功,感觉仅凭自己的思维力量真的很难,通过查阅资料,询问他人的方式,我才慢慢建立起来那个思路框架,然后开始贴贴补补,到处完善修改。这次的作业看似功能简单,但其实也算是一个小项目了,涉及到很多规范,代码规范,结构规范等等,就像构建之法中那个PSP表格所呈现那样,真正的职业软件工程师其实编码时间不长,完成好前期的需求分析,框架思路都理清了,编码也会自然而然的流畅起来,而不是我们现在这样磕磕巴巴。其次就是体会到老师以前上课所说的,注释十分重要,如果不去注释,可能在修改的途中你就不清楚这些函数,这些变量都代表的什么意思。注释及时对自己的负责,也是对别人的负责。