shelve模块
shelve模块是pickle模块的扩展,可以通过key,value的方式访问pickle持久化保存的数据
持久化保存:
1 2 3 4 5 6 7 8 9 10 11 12 13 | import shelvesw = shelve.open('shelve_test.pkl') # 创建shelve对象name = ['13', '14', '145', 6] # 创建一个列表dist_test = {"k1":"v1", "k2":"v2"}sw['name'] = name # 将列表持久化保存sw['dist_test'] = dist_testsw.close() # 关闭文件,必须要有sr = shelve.open('shelve_test.pkl')print(sr['name']) # 读出列表print(sr['dist_test']) # 读出字典sr.close() |
说明:
1、其实shelve模块其实就是pickle模块的一个扩展,可以直接用key来读取持久化保存的数据,而不用原生pickle一样通过持久化的顺序来一个个读取出来
2、
sw['name']里的name其实就是key也就是自定义的一个名字,读取的时候通过这个key就可以方便读取出来
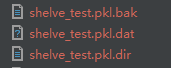
3、shelve_test.pkl并不是最终的文件名,shelve会自动生成如下三个后缀的文件
xml处理模块
xml是实现不同语言或程序之间进行数据交换的协议,跟json差不多,但json使用起来更简单,不过,古时候,在json还没诞生的黑暗年代,大家只能选择用xml呀,至今很多传统公司如金融行业的很多系统的接口还主要是xml。
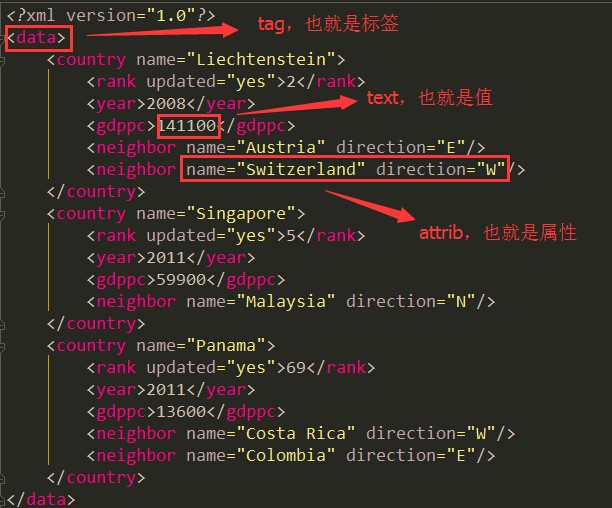
我们先来,通过一张图认识一下xml文件的组成结构
说明:
最外层的标签我们称之为跟标签、也就是root,其他标签都是子标签,也就是child
1 2 3 4 5 6 7 8 | import xml.etree.ElementTree as ETtree = ET.parse('test.xml') # 读取xml文件,并以Element对象的形式保存root = tree.getroot() # 获取根for child in root: # 遍历root下的子标签 print(child.tag, child.attrib) # 打印标签名和属性 for i in child: print(i.tag, i.text, i.attrib) # 打印标签名值和属性 |
输出结果:
country {'name': 'Liechtenstein'}
rank 2 {'updated': 'yes'}
year 2008 {}
gdppc 141100 {}
neighbor None {'direction': 'E', 'name': 'Austria'}
neighbor None {'direction': 'W', 'name': 'Switzerland'}
country {'name': 'Singapore'}
rank 5 {'updated': 'yes'}
year 2011 {}
gdppc 59900 {}
neighbor None {'direction': 'N', 'name': 'Malaysia'}
country {'name': 'Panama'}
rank 69 {'updated': 'yes'}
year 2011 {}
gdppc 13600 {}
neighbor None {'direction': 'W', 'name': 'Costa Rica'}
neighbor None {'direction': 'E', 'name': 'Colombia'}
我们也可以通过标签名来获取某一类标签的内容
1 2 | for node in root.iter('year'): # 仅遍历标签名为year的标签 print(node.tag, node.text, node.attrib) |
输出结果:
year 2008 {}
year 2011 {}
year 2011 {}
xml的常用操作
修改:
1 2 3 4 5 6 7 8 9 | import xml.etree.ElementTree as ETtree = ET.parse('test.xml') # 读取xml文件,并以Element对象的形式保存root = tree.getroot() # 获取根for node in root.iter('year'): # 遍历year标签 node.text = str(int(node.text) + 1) # 将year标签的值+1,注意,读出来的标签的值都是字符串形式,注意数据类型转换 node.set('updated', 'yes') # 更新该标签tree.write('test_2.xml') # 将结果写到文件,可以写到源文件也可以写到新的文件中 |
删除:
1 2 3 4 5 6 7 8 9 10 | import xml.etree.ElementTree as ETtree = ET.parse('test.xml') # 读取xml文件,并以Element对象的形式保存root = tree.getroot() # 获取根for country in root.findall('country'): # 遍历所有country标签 rank = int(country.find('rank').text) # 在country标签查找名为rank的纸标签 if rank > 50: # 判断如果rank标签的值大于50 root.remove(country) # 删除该标签tree.write('test_3.xml') |
说明:
iter方法用于查找的最终标签,也就是下面没子标签的标签,获取他的值和属性的
findall方法用于查找还有子标签的子标签,然后和用fandall返回的对象的find方法获取找到的标签的子标签
创建自己的xml文档
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | import xml.etree.ElementTree as ETnew_xml = ET.Element("namelist") # 新建根节点,或者说xml对象name = ET.SubElement(new_xml,"name",attrib={"enrolled":"yes"}) # 给新xml对象创建子标签age = ET.SubElement(name,"age",attrib={"checked":"no"}) # name标签在创建子标签age,attrib变量为属性sex = ET.SubElement(name,"sex")sex.text = '33' # 给标签赋值name2 = ET.SubElement(new_xml,"name",attrib={"enrolled":"no"})age = ET.SubElement(name2,"age")age.text = '19'et = ET.ElementTree(new_xml) #生成文档对象et.write("test.xml", encoding="utf-8",xml_declaration=True) # 将xml对象保存到文件xml_declaration表示xml文档的声明ET.dump(new_xml) #打印生成的格式 |
ConfigParser模块
ConfigParser模块是用来处理配置文件的包,配置文件的格式如下:中括号“[ ]”内包含的为section。section 下面为类似于key-value 的配置内容。常见很多服务的都是类似这种格式的,比如MySQL
假设我们有这样一个配置文件
[DEFAULT]
name = www.qq.com
[dbs]
username = root
passord = 123.com
host = 127.0.0.1
[server]
name = www.baidu.com
port = 80
读取配置文件
1 2 3 4 | import configparserconfig = configparser.ConfigParser() # 创建configparser对象config.read('example.ini') # 读取配置件print(config.sections()) # 获取所有的session |
输出结果
['dbs', 'server']
注意:
可以看到这里没有输出DEFAULT,因为在Python中DEFAULT session有特殊用途,相当于所有session的默认值,也就是当DEFAULT中定义了一个key和value,此时session中这个不存在的时候,这个key的值就是DEFAULT定义的value
例如
1 | print(config['dbs']['name']) |
输出结果就是
www.qq.com
说明:
可以看到读取配置文件后的返回的对象有点类似于字典,可以通过key的方式将配置文件中的值一一取出来,甚至可以使用in关键字判断key是否存在
1 | print('server' in config) |
输出结果
True
其他常用操作
读:
1 | print(config.options('dbs')) # 获取某个session下的所有option,也就是key |
输出结果
['username', 'passord', 'host', 'name']
1 | print(config.items('dbs')) # 获取某个session的键值列表,类似字典的items方法 |
输出结果
[('name', 'www.qq.com'), ('username', 'root'), ('passord', '123.com'), ('host', '127.0.0.1')]
1 | print(config.get('dbs', 'host')) # 获取某个session下的某个option的值 |
输出结果
127.0.0.1
1 2 3 | port = config.getint('server', 'port') # 获取某个session下的某个option的值,并以int的方式返回print(port)print(type(port)) |
类似的方法还有getfloat和getboolean方法,当然前提是配置文件中的值就是对应的类型,否则会报错
说明:
配置文件中yes、True、1、true等为真,也就是通过getboolean返回的是True,no、False、0、false等为假,也就是返回的是False
删除:
1 2 | config.remove_option('dbs','host') # 删除optionconfig.remove_section('server') # 删除session |