一、概述
链接:https://pan.baidu.com/s/18nfxLB2cDE-ZLPXuS-TCjg
提取码:v5li
关注公众号:嬉皮工匠
获取更多论文笔记~
联邦学习(Federated Learning)结构由Server和若干Client组成,在联邦学习方法过程中,没有任何用户数据被传送到Server端,这保护了用户数据的隐私。此外,通信中传输的参数是特定于改进当前模型的,因此一旦应用了它们,Server就没有理由存储它们,这进一步提高了安全性。
下图为联邦学习的总体框架,由Server和若干Client构成,大概的思路是“数据不动模型动”。具体而言,Server提供全局共享的模型,Client下载模型并训练自己的数据集,同时更新模型参数。在Server和Client的每一次通信中,Server将当前的模型参数分发给各个Client(或者说Client下载服务端的模型参数),经过Client的训练之后,将更新后的模型参数返回给Server,Server通过某种方法将聚合得到的N个模型参数融合成一个作为更新后的Server模型参数。以此循环。
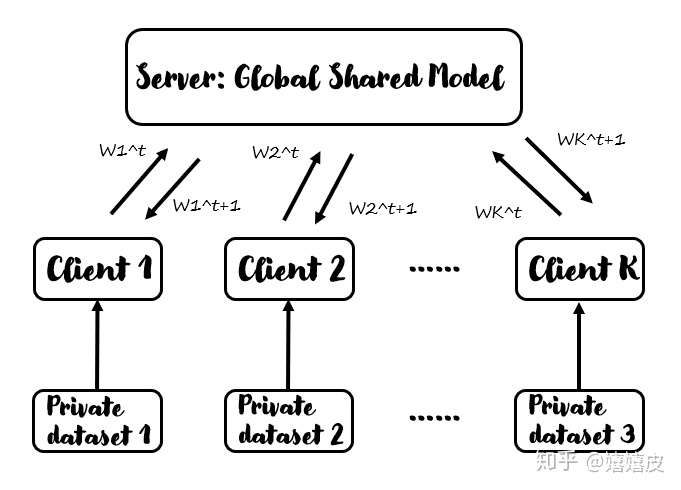
本文以FedAvg方法、Mnist数据集为例,假设共100个Client,实战联邦学习方法,梳理其方法流程,完成代码见文末。
首先,我们要为每个客户端分配数据,实际上是每个客户端自身有独有的数据,这里为了模拟,手动划分数据集给各个客户端。
客户端之间的数据可能是独立同分布IID,也可能是非独立同分布Non-IID的。
对于IID的情况,我们首先将数据集打乱,然后为每个Client分配600个样本。
对于Non-IID的情况,我们首先根据数据标签将数据集排序(即MNIST中的数字大小),然后将其划分为200组大小为300的数据切片,然后分给每个Client两个切片。
这两种数据分配方式的代码如下:
if isIID:
order = np.arange(self.train_data_size)
np.random.shuffle(order)
self.train_data = train_images[order]
self.train_label = train_labels[order]
else:
labels = np.argmax(train_labels, axis=1)
order = np.argsort(labels)
self.train_data = train_images[order]
self.train_label = train_labels[order]然后就可以用一个循环来为每个Client分配数据。
下面进入正题:联邦训练。
首先,Server初始化并共享其模型的参数。
net = Model() # 初始化模型
global_parameters = net.state_dict() # 获取模型参数以共享获取到共享的模型参数后,即可开始若干次的Server和Client间通信。通信的流程见代码注释:
# num_comm 表示通信次数,此处设置为1k
for i in range(args['num_comm']):
# 随机选择一部分Client,全部选择会增大通信量,且实验效果可能会不好
# clients_in_comm表示每次通讯中随机选择的Client数量
order = np.random.permutation(args['num_of_clients'])
clients_in_comm = ['client{}'.format(i) for i in order[0:num_in_comm]]
sum_parameters = None
# 每个Client基于当前模型参数和自己的数据训练并更新模型,返回每个Client更新后的参数
for client in tqdm(clients_in_comm):
# 获取当前Client训练得到的参数
local_parameters = myClients.clients_set[client].localUpdate(args['epoch'], args['batchsize'], net,loss_func, opti, global_parameters)
# 对所有的Client返回的参数累加(最后取平均值)
if sum_parameters is None:
sum_parameters = local_parameters
else:
for var in sum_parameters:
sum_parameters[var] = sum_parameters[var] + local_parameters[var]
# 取平均值,得到本次通信中Server得到的更新后的模型参数
for var in global_parameters:
global_parameters[var] = (sum_parameters[var] / num_in_comm) local_parameters = myClients.clients_set[client].localUpdate(args['epoch'], args['batchsize'], net,loss_func, opti, global_parameters)这一行代码表示Client端的训练函数,我们详细展开:
def localUpdate(self, localEpoch, localBatchSize, Net, lossFun, opti, global_parameters):
'''
:param localEpoch: 当前Client的迭代次数
:param localBatchSize: 当前Client的batchsize大小
:param Net: Server共享的模型
:param lossFun: 损失函数
:param opti: 优化函数
:param global_parameters: 当前通信中最新全局参数
:return: 返回当前Client基于自己的数据训练得到的新的模型参数
'''
# 加载当前通信中最新全局参数
Net.load_state_dict(global_parameters, strict=True)
# 载入Client自有数据集
self.train_dl = DataLoader(self.train_ds, batch_size=localBatchSize, shuffle=True)
# 设置迭代次数
for epoch in range(localEpoch):
for data, label in self.train_dl:
data, label = data.to(self.dev), label.to(self.dev)
preds = Net(data)
loss = lossFun(preds, label)
loss.backward()
opti.step()
opti.zero_grad()
# 返回当前Client基于自己的数据训练得到的新的模型参数
return Net.state_dict()训练结束之后,我们要通过测试集来验证方法的泛化性,注意,**虽然训练时,Server没有得到过任何一条数据,但是联邦学习最终的目的还是要在Server端学习到一个鲁棒的模型,所以在做测试的时候,是在Server端进行的,**如下:
with torch.no_grad():
# 加载Server在最后得到的模型参数
net.load_state_dict(global_parameters, strict=True)
sum_accu = 0
num = 0
# 载入测试集
for data, label in testDataLoader:
data, label = data.to(dev), label.to(dev)
preds = net(data)
preds = torch.argmax(preds, dim=1)
sum_accu += (preds == label).float().mean()
num += 1
print('accuracy: {}'.format(sum_accu / num))总结:
回顾上述方法流程,有几个关键的参数。一个是每个Client的训练迭代次数epoch,随着epoch的增加,意味着Client运算量的增加;另一个参数是通信次数,通信次数的增加意味着会增加网络传输的负担,且可能收到网络带宽的限制。
参考:
二、实战
原文链接:https://towardsdatascience.com/federated-learning-a-simple-implementation-of-fedavg-federated-averaging-with-pytorch-90187c9c9577
搬运理由: 知乎没有联邦学习具体代码实现的教程(侵删)
在 Fedrated Learning 中,每个客户数据都分散地在本地训练其模型,仅将学习到的模型参数发送到受信任的 Server,通过差分隐私加密和安全聚合等技术得到主模型。然后,受信任的 Server 将聚合的主模型发回给这些客户端,并重复此过程。
在这种情况下,准备了一个具有 IID(独立同分布)数据的简单实现,以演示如何将在不同节点上运行的数百个不同模型的参数与 FedAvg 方法结合使用,以及该模型是否会给出合理的结果。此实现是在 MNIST 数据集上执行的。MNIST 数据集包含数量为 0 到 9 的 28 * 28 像素灰度图像。
FedAvg 训练过程:
- 由于主模型的参数和节点中所有局部模型的参数都是随机初始化的,所有这些参数将彼此不同。因此,在对节点中的本地模型进行训练之前,主模型会将模型参数发送给节点。
- 节点使用这些参数在其自身的数据上训练本地模型。
- 每个节点在训练自己的模型时都会更新其参数。训练过程完成后,每个节点会将其参数发送到主模型。
- 主模型采用这些参数的平均值并将其设置为新的权重参数,并将其传递回节点以进行下一次迭代。
函数介绍
数据分发
- split_and_shuffle_labels(y_data,seed,amount): 数据集的每个标签包含的样本量不相等,为了保证数据作为 IID 分发到节点,必须采用相等数量的数据。
该函数保证数据数量相同,并在其内部随机排序。(此处改组的是数据索引,以后我们将在检索数据时使用该索引)。
def split_and_shuffle_labels(y_data, seed, amount):
y_data=pd.DataFrame(y_data,columns=["labels"])
y_data["i"]=np.arange(len(y_data))
label_dict = dict()
for i in range(10):
var_name="label" + str(i)
label_info=y_data[y_data["labels"]==i]
np.random.seed(seed)
label_info=np.random.permutation(label_info)
label_info=label_info[0:amount]
label_info=pd.DataFrame(label_info, columns=["labels","i"])
label_dict.update({var_name: label_info })
return label_dict- get_iid_subsamples_indices(label_dict,number_of_samples,数量):均分每个索引,保证每个节点中各标签数量相等。
def get_iid_subsamples_indices(label_dict, number_of_samples, amount):
sample_dict= dict()
batch_size=int(math.floor(amount/number_of_samples))
for i in range(number_of_samples):
sample_name="sample"+str(i)
dumb=pd.DataFrame()
for j in range(10):
label_name=str("label")+str(j)
a=label_dict[label_name][i*batch_size:(i+1)*batch_size]
dumb=pd.concat([dumb,a], axis=0)
dumb.reset_index(drop=True, inplace=True)
sample_dict.update({sample_name: dumb})
return sample_dict- create_iid_subsamples(sample_dict, x_data, y_data, x_name, y_name) : 将数据分发到节点。
def create_iid_subsamples(sample_dict, x_data, y_data, x_name, y_name):
x_data_dict= dict()
y_data_dict= dict()
for i in range(len(sample_dict)): ### len(sample_dict)= number of samples
xname= x_name+str(i)
yname= y_name+str(i)
sample_name="sample"+str(i)
indices=np.sort(np.array(sample_dict[sample_name]["i"]))
x_info= x_data[indices,:]
x_data_dict.update({xname : x_info})
y_info= y_data[indices]
y_data_dict.update({yname : y_info})
return x_data_dict, y_data_dictFunctions for FedAvg
- create_model_optimizer_criterion_dict(number_of_samples) : 创建模型,优化器和损失函数。
def create_model_optimizer_criterion_dict(number_of_samples):
model_dict = dict()
optimizer_dict= dict()
criterion_dict = dict()
for i in range(number_of_samples):
model_name="model"+str(i)
model_info=Net2nn()
model_dict.update({model_name : model_info })
optimizer_name="optimizer"+str(i)
optimizer_info = torch.optim.SGD(model_info.parameters(), lr=learning_rate, momentum=momentum)
optimizer_dict.update({optimizer_name : optimizer_info })
criterion_name = "criterion"+str(i)
criterion_info = nn.CrossEntropyLoss()
criterion_dict.update({criterion_name : criterion_info})
return model_dict, optimizer_dict, criterion_dict - get_averaged_weights(model_dict, number_of_samples) : 获取各个节点中权重的平均值。
def get_averaged_weights(model_dict, number_of_samples):
fc1_mean_weight = torch.zeros(size=model_dict[name_of_models[0]].fc1.weight.shape)
fc1_mean_bias = torch.zeros(size=model_dict[name_of_models[0]].fc1.bias.shape)
fc2_mean_weight = torch.zeros(size=model_dict[name_of_models[0]].fc2.weight.shape)
fc2_mean_bias = torch.zeros(size=model_dict[name_of_models[0]].fc2.bias.shape)
fc3_mean_weight = torch.zeros(size=model_dict[name_of_models[0]].fc3.weight.shape)
fc3_mean_bias = torch.zeros(size=model_dict[name_of_models[0]].fc3.bias.shape)
with torch.no_grad():
for i in range(number_of_samples):
fc1_mean_weight += model_dict[name_of_models[i]].fc1.weight.data.clone()
fc1_mean_bias += model_dict[name_of_models[i]].fc1.bias.data.clone()
fc2_mean_weight += model_dict[name_of_models[i]].fc2.weight.data.clone()
fc2_mean_bias += model_dict[name_of_models[i]].fc2.bias.data.clone()
fc3_mean_weight += model_dict[name_of_models[i]].fc3.weight.data.clone()
fc3_mean_bias += model_dict[name_of_models[i]].fc3.bias.data.clone()
fc1_mean_weight =fc1_mean_weight/number_of_samples
fc1_mean_bias = fc1_mean_bias/ number_of_samples
fc2_mean_weight =fc2_mean_weight/number_of_samples
fc2_mean_bias = fc2_mean_bias/ number_of_samples
fc3_mean_weight =fc3_mean_weight/number_of_samples
fc3_mean_bias = fc3_mean_bias/ number_of_samples
return fc1_mean_weight, fc1_mean_bias, fc2_mean_weight, fc2_mean_bias, fc3_mean_weight, fc3_mean_bias- set_averaged_weights_as_main_model_weights_and_update_main_model(main_model,model_dict, number_of_samples) : 将各个节点的平均权重发送到主模型,并将它们设置为主模型的新权重。
def set_averaged_weights_as_main_model_weights_and_update_main_model(main_model,model_dict, number_of_samples):
fc1_mean_weight, fc1_mean_bias, fc2_mean_weight, fc2_mean_bias, fc3_mean_weight, fc3_mean_bias = get_averaged_weights(model_dict, number_of_samples=number_of_samples)
with torch.no_grad():
main_model.fc1.weight.data = fc1_mean_weight.data.clone()
main_model.fc2.weight.data = fc2_mean_weight.data.clone()
main_model.fc3.weight.data = fc3_mean_weight.data.clone()
main_model.fc1.bias.data = fc1_mean_bias.data.clone()
main_model.fc2.bias.data = fc2_mean_bias.data.clone()
main_model.fc3.bias.data = fc3_mean_bias.data.clone()
return main_model- compare_local_and_merged_model_performance(number_of_samples : 比较主模型和在各节点运行的本地模型的准确性。
def compare_local_and_merged_model_performance(number_of_samples):
accuracy_table=pd.DataFrame(data=np.zeros((number_of_samples,3)), columns=["sample", "local_ind_model", "merged_main_model"])
for i in range (number_of_samples):
test_ds = TensorDataset(x_test_dict[name_of_x_test_sets[i]], y_test_dict[name_of_y_test_sets[i]])
test_dl = DataLoader(test_ds, batch_size=batch_size * 2)
model=model_dict[name_of_models[i]]
criterion=criterion_dict[name_of_criterions[i]]
optimizer=optimizer_dict[name_of_optimizers[i]]
individual_loss, individual_accuracy = validation(model, test_dl, criterion)
main_loss, main_accuracy =validation(main_model, test_dl, main_criterion )
accuracy_table.loc[i, "sample"]="sample "+str(i)
accuracy_table.loc[i, "local_ind_model"] = individual_accuracy
accuracy_table.loc[i, "merged_main_model"] = main_accuracy
return accuracy_table- send_main_model_to_nodes_and_update_model_dict(main_model, model_dict, number_of_samples) : 将主模型的参数发送到各节点。
def send_main_model_to_nodes_and_update_model_dict(main_model, model_dict, number_of_samples):
with torch.no_grad():
for i in range(number_of_samples):
model_dict[name_of_models[i]].fc1.weight.data =main_model.fc1.weight.data.clone()
model_dict[name_of_models[i]].fc2.weight.data =main_model.fc2.weight.data.clone()
model_dict[name_of_models[i]].fc3.weight.data =main_model.fc3.weight.data.clone()
model_dict[name_of_models[i]].fc1.bias.data =main_model.fc1.bias.data.clone()
model_dict[name_of_models[i]].fc2.bias.data =main_model.fc2.bias.data.clone()
model_dict[name_of_models[i]].fc3.bias.data =main_model.fc3.bias.data.clone()
return model_dict- start_train_end_node_process_without_print() : 在节点中训练各个局部模型。
def start_train_end_node_process_without_print(number_of_samples):
for i in range (number_of_samples):
train_ds = TensorDataset(x_train_dict[name_of_x_train_sets[i]], y_train_dict[name_of_y_train_sets[i]])
train_dl = DataLoader(train_ds, batch_size=batch_size, shuffle=True)
test_ds = TensorDataset(x_test_dict[name_of_x_test_sets[i]], y_test_dict[name_of_y_test_sets[i]])
test_dl = DataLoader(test_ds, batch_size= batch_size * 2)
model=model_dict[name_of_models[i]]
criterion=criterion_dict[name_of_criterions[i]]
optimizer=optimizer_dict[name_of_optimizers[i]]
for epoch in range(numEpoch):
train_loss, train_accuracy = train(model, train_dl, criterion, optimizer)
test_loss, test_accuracy = validation(model, test_dl, criterion)基于 centralized-data 模型的性能如何?
centralized_model = Net2nn()
centralized_optimizer = torch.optim.SGD(centralized_model.parameters(), lr=0.01, momentum=0.9)
centralized_criterion = nn.CrossEntropyLoss()
train_ds = TensorDataset(x_train, y_train)
train_dl = DataLoader(train_ds, batch_size=batch_size, shuffle=True)
valid_ds = TensorDataset(x_valid, y_valid)
valid_dl = DataLoader(valid_ds, batch_size=batch_size * 2)
test_ds = TensorDataset(x_test, y_test)
test_dl = DataLoader(test_ds, batch_size=batch_size * 2)
print("------ Centralized Model ------")
for epoch in range(numEpoch):
central_train_loss, central_train_accuracy = train(centralized_model, train_dl, centralized_criterion, centralized_optimizer)
central_test_loss, central_test_accuracy = validation(centralized_model, test_dl, centralized_criterion)
print("epoch: {:3.0f}".format(epoch+1) + " | train accuracy: {:7.4f}".format(central_train_accuracy) + " | test accuracy: {:7.4f}".format(central_test_accuracy))
— — — Centralized Model — — —
epoch: 1 | train accuracy: 0.8743 | test accuracy: 0.9437
epoch: 2 | train accuracy: 0.9567 | test accuracy: 0.9654
epoch: 3 | train accuracy: 0.9712 | test accuracy: 0.9701
epoch: 4 | train accuracy: 0.9785 | test accuracy: 0.9738
epoch: 5 | train accuracy: 0.9834 | test accuracy: 0.9713
epoch: 6 | train accuracy: 0.9864 | test accuracy: 0.9768
epoch: 7 | train accuracy: 0.9898 | test accuracy: 0.9763
epoch: 8 | train accuracy: 0.9923 | test accuracy: 0.9804
epoch: 9 | train accuracy: 0.9941 | test accuracy: 0.9784
epoch: 10 | train accuracy: 0.9959 | test accuracy: 0.9792
— — — Training finished — — -此处的目的是比较通过将在自己的数据上训练的局部模型的参数与在所有训练数据上训练的集中式模型相结合而形成的主模型的性能。
将数据分发到节点
label_dict_train=split_and_shuffle_labels(y_data=y_train, seed=1, amount=train_amount)
sample_dict_train=get_iid_subsamples_indices(label_dict=label_dict_train, number_of_samples=number_of_samples, amount=train_amount)
x_train_dict, y_train_dict = create_iid_subsamples(sample_dict=sample_dict_train, x_data=x_train, y_data=y_train, x_name="x_train", y_name="y_train")
label_dict_valid = split_and_shuffle_labels(y_data=y_valid, seed=1, amount=train_amount)
sample_dict_valid = get_iid_subsamples_indices(label_dict=label_dict_valid, number_of_samples=number_of_samples, amount=valid_amount)
x_valid_dict, y_valid_dict = create_iid_subsamples(sample_dict=sample_dict_valid, x_data=x_valid, y_data=y_valid, x_name="x_valid", y_name="y_valid")
label_dict_test = split_and_shuffle_labels(y_data=y_test, seed=1, amount=test_amount)
sample_dict_test = get_iid_subsamples_indices(label_dict=label_dict_test, number_of_samples=number_of_samples, amount=test_amount)
x_test_dict, y_test_dict = create_iid_subsamples(sample_dict=sample_dict_test, x_data=x_test, y_data=y_test, x_name="x_test", y_name="y_test")创建主模型
main_model = Net2nn()
main_optimizer = torch.optim.SGD(main_model.parameters(), lr=learning_rate, momentum=0.9)
main_criterion = nn.CrossEntropyLoss()定义节点中的模型,优化器和损失函数
model_dict, optimizer_dict, criterion_dict = create_model_optimizer_criterion_dict(number_of_samples)将字典键变为可迭代类型
name_of_x_train_sets=list(x_train_dict.keys())
name_of_y_train_sets=list(y_train_dict.keys())
name_of_x_valid_sets=list(x_valid_dict.keys())
name_of_y_valid_sets=list(y_valid_dict.keys())
name_of_x_test_sets=list(x_test_dict.keys())
name_of_y_test_sets=list(y_test_dict.keys())
name_of_models=list(model_dict.keys())
name_of_optimizers=list(optimizer_dict.keys())
name_of_criterions=list(criterion_dict.keys())主模型的参数发送到节点
由于主模型的参数和节点中所有本地模型的参数都是随机初始化的,因此所有这些参数将彼此不同。因此,在对节点中的本地模型进行训练之前,主模型会将其参数发送给节点。
model_dict=send_main_model_to_nodes_and_update_model_dict(main_model, model_dict, number_of_samples)训练节点中的模型
start_train_end_node_process_without_print(number_of_samples)让我们比较一下联邦学习主模型和 centralized-model 的性能
before_test_loss, before_test_accuracy = validation(main_model, test_dl, main_criterion)
main_model= set_averaged_weights_as_main_model_weights_and_update_main_model(main_model,model_dict, number_of_samples)
after_test_loss, after_test_accuracy = validation(main_model, test_dl, main_criterion)
print("Before 1st iteration main model accuracy on all test data: {:7.4f}".format(before_test_accuracy))
print("After 1st iteration main model accuracy on all test data: {:7.4f}".format(after_test_accuracy))
print("Centralized model accuracy on all test data: {:7.4f}".format(central_test_accuracy))Before 1st iteration main model accuracy on all test data: 0.1180
After 1st iteration main model accuracy on all test data: 0.8529
Centralized model accuracy on all test data: 0.9790
当重复迭代10次以上时主模型的性能:
for i in range(10):
model_dict=send_main_model_to_nodes_and_update_model_dict(main_model, model_dict, number_of_samples)
start_train_end_node_process_without_print(number_of_samples)
main_model= set_averaged_weights_as_main_model_weights_and_update_main_model(main_model,model_dict, number_of_samples)
test_loss, test_accuracy = validation(main_model, test_dl, main_criterion)
print("Iteration", str(i+2), ": main_model accuracy on all test data: {:7.4f}".format(test_accuracy))
Iteration 2 : main_model accuracy on all test data: 0.8928
Iteration 3 : main_model accuracy on all test data: 0.9073
Iteration 4 : main_model accuracy on all test data: 0.9150
Iteration 5 : main_model accuracy on all test data: 0.9209
Iteration 6 : main_model accuracy on all test data: 0.9273
Iteration 7 : main_model accuracy on all test data: 0.9321
Iteration 8 : main_model accuracy on all test data: 0.9358
Iteration 9 : main_model accuracy on all test data: 0.9382
Iteration 10 : main_model accuracy on all test data: 0.9411
Iteration 11 : main_model accuracy on all test data: 0.9431Github 源码地址https://github.com/eceisik/fl_p