huggingface的transformers框架,囊括了BERT、GPT、GPT2、ToBERTa、T5等众多模型,同时支持pytorch和tensorflow 2,代码非常规范,使用也非常简单,但是模型使用的时候,要从他们的服务器上去下载模型,那么有没有办法,把这些预训练模型下载好,在使用时指定使用这些模型呢?答案是肯定的。本文就是要讲明白这个问题。
1. 总览
总体是,将所需要的预训练模型、词典等文件下载至本地文件夹中 ,然后加载的时候model_name_or_path参数指向文件的路径即可。
2. 手动下载配置、词典、预训练模型等
首先打开网址:https://huggingface.co/models 这个网址是huggingface/transformers支持的所有模型,目前大约一千多个。搜索gpt2(其他的模型类似,比如bert-base-uncased等),并点击进去。
进入之后,可以看到gpt2模型的说明页,如下图图1,点击页面中的list all files in model,可以看到模型的所有文件。
通常我们需要保存的是三个文件及一些额外的文件,第一个是配置文件;config.json。第二个是词典文件,vocab.json。第三个是预训练模型文件,如果你使用pytorch则保存pytorch_model.bin文件,如果你使用tensorflow 2,则保存tf_model.h5。
额外的文件,指的是merges.txt、special_tokens_map.json、added_tokens.json、tokenizer_config.json、sentencepiece.bpe.model等,这几类是tokenizer需要使用的文件,如果出现的话,也需要保存下来。没有的话,就不必在意。如果不确定哪些需要下,哪些不需要的话,可以把图1中类似的文件全部下载下来。
以下图1为例,我们需要“右键”-“另存为”的文件是,config.json、vocab.json、pytorch_model.bin(或tf_model.h5)以及额外文件merges.txt。
下载到本地文件夹gpt2,同时这些名称务必注意保证与图1中的名称完全一致。下图图2是gpt2文件下载至本地,又从本地上传至我的服务器的样例。图中红色框是必须的,绿色框是二选一,pytorch及tensorflow 2模型二选一使用,其他文件是非必须的。
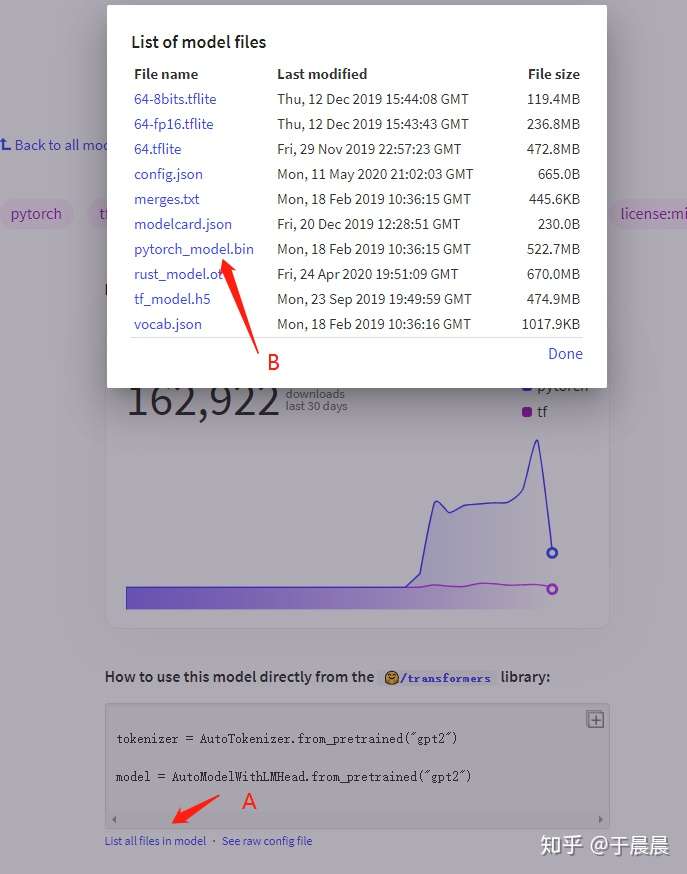 图1:下载配置、词典、预训练模型等
图1:下载配置、词典、预训练模型等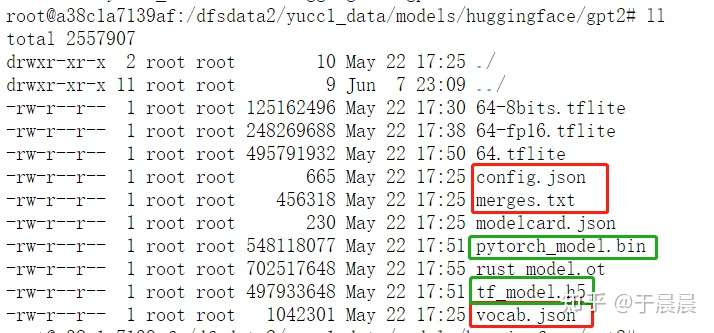 图2:我下载gpt2模型至本地,又从本地上传至服务器的截图。其中红色框是必须的,绿色框是二选一的,其他的是非必须的。其中merges.txt只有图1中出现这个文件才需要下载,没有的时候不用下载。
图2:我下载gpt2模型至本地,又从本地上传至服务器的截图。其中红色框是必须的,绿色框是二选一的,其他的是非必须的。其中merges.txt只有图1中出现这个文件才需要下载,没有的时候不用下载。
3. 使用下载好的本地文件
使用的时候,非常简单。huggingface的transformers框架主要有三个类model类、configuration类、tokenizer类,这三个类,所有相关的类都衍生自这三个类,他们都有from_pretained()方法和save_pretrained()方法。
from_pretrained方法的第一个参数都是pretrained_model_name_or_path,这个参数设置为我们下载的文件目录即可。
样例一:
下面的代码是使用GPT2去预测一句话的下一个单词的样例。这里的pytorch版本的,如果是tensorflow 2版本的,GPT2LMHeadModel.from_pretrained的参数需要额外加入from_tf=True。
import torch
from transformers import GPT2Tokenizer, GPT2LMHeadModel
# 从下载好的文件夹中加载tokenizer
# 这里你需要改为自己的实际文件夹路径
tokenizer = GPT2Tokenizer.from_pretrained('/dfsdata2/yucc1_data/models/huggingface/gpt2')
text = 'Who was Jim Henson ? Jim Henson was a'
# 编码一段文本
# 编码后为[8241, 373, 5395, 367, 19069, 5633, 5395, 367, 19069, 373, 257]
indexed_tokens = tokenizer.encode(text)
# 转换为pytorch tensor
# tensor([[ 8241, 373, 5395, 367, 19069, 5633, 5395, 367, 19069, 373, 257]])
# shape为 torch.Size([1, 11])
tokens_tensor = torch.tensor([indexed_tokens])
# 从下载好的文件夹中加载预训练模型
model = GPT2LMHeadModel.from_pretrained('/dfsdata2/yucc1_data/models/huggingface/gpt2')
# 设置为evaluation模式,去取消激活dropout等模块。
# 在huggingface/transformers框架中,默认就是eval模式
model.eval()
# 预测所有token
with torch.no_grad():
# 将输入tensor输入,就得到了模型的输出,非常简单
# outputs是一个元组,所有huggingface/transformers模型的输出都是元组
# 本初的元组有两个,第一个是预测得分(没经过softmax之前的,也叫作logits),
# 第二个是past,里面的attention计算的key value值
# 此时我们需要的是第一个值
outputs = model(tokens_tensor)
# predictions shape为 torch.Size([1, 11, 50257]),
# 也就是11个词每个词的预测得分(没经过softmax之前的)
# 也叫做logits
predictions = outputs[0]
# 我们需要预测下一个单词,所以是使用predictions第一个batch,最后一个词的logits去计算
# predicted_index = 582,通过计算最大得分的索引得到的
predicted_index = torch.argmax(predictions[0, -1, :]).item()
# 反向解码为我们需要的文本
predicted_text = tokenizer.decode(indexed_tokens + [predicted_index])
# 解码后的文本:'Who was Jim Henson? Jim Henson was a man'
# 成功预测出单词 'man'
print(predicted_text)样例二:
huggingface/transformers官方样例,使用gpt2进行文本生成。https://github.com/huggingface/transformers/tree/master/examples/text-generation
此处一样使用将model_name_or_path参数改为文件夹的路径即可。
python run_generation.py
--model_type=gpt2
--model_name_or_path=/dfsdata2/yucc1_data/models/huggingface/gpt2掌握了以上方法后,transformers库、文档里的其他样例都是一样的操作,无非是换个路径及模型。
4. 我下载好的一些预训练模型
大家按照上面的方法进行下载,并使用即可。
我自己也下载了一些常用的模型,上传到百度网盘了,后期我自己使用到一些其他模型也会更新上去,如果大家想使用可以照着下面图3的办法获得链接即可。
目前分享的链接里有的模型有:bert-base-cased、bert-base-uncased、bert-base-multilingual-cased、bert-base-multilingual-uncased、albert-base-v2、gpt2、microsoft/DialoGPT-small、microsoft/DialoGPT-medium、microsoft/DialoGPT-large、openai-gpt、roberta-base、xlm-roberta-base、xlm-roberta-large等。
 图3:关注并回关键字:huggingface,可以下载我分享的一些下载好的模型文件
图3:关注并回关键字:huggingface,可以下载我分享的一些下载好的模型文件
5. 基本原理
使用的基本原理也非常简单,from_pretrained的参数pretrained_model_name_or_path,可以接受的参数有几种,short-cut name(缩写名称,类似于gpt2这种)、identifier name(类似于microsoft/DialoGPT-small这种)、文件夹、文件。
对于short-cut name或identifier name,这种情况下,本地有文件,可以使用本地的,本地没有文件,则下载。一些常用的short-cut name,可以从这个链接查看:https://huggingface.co/transformers/pretrained_models.html。
对于文件夹,则会从文件夹中找vocab.json、pytorch_model.bin、tf_model.h5、merges.txt、special_tokens_map.json、added_tokens.json、tokenizer_config.json、sentencepiece.bpe.model等进行加载。所以这也是为什么下载的时候,一定要保证这些名称是这几个,不能变。
对于文件,则会直接加载文件。
官方给的样例,通常都是short-cut name,这里操作就是替换成下载好文件的文件夹。至此,我们完成了模型、词典等各种文件的本地加载。