1,概述
任务型对话系统越来越多的被应用到实际的场景中,例如siri,阿里小密这类的产品。通常任务型对话系统都是基于pipline的方式实现的,具体的流程图如下:

整个pipline由五个模块组成:语音识别;自然语言理解;对话管理;自然语言生成;语音合成。现在越来越多的产品还融入了知识库,主要是在对话管理模块引入。在这里除了语音识别和语音合成模块不属于自然语言处理范畴且属于可选项之外,其他的三个模块都是必要的。
自然语言理解(NLU):主要作用是对用户输入的句子或者语音识别的结果进行处理,提取用户的对话意图以及用户所传递的信息。
对话管理(DM):对话管理分为两个子模块,对话状态追踪(DST)和对话策略学习(DPL),其主要作用是根据NLU的结果来更新系统的状态,并生成相应的系统动作。
自然语言生成(NLG):将DM输出的系统动作文本化,用文本的形式将系统的动作表达出来。
我们接下来将会详细讨论这四个模块(NLU,DST,DPL,NLG)。
2 意图识别和槽值填充
举一个简单的例子,以一个询问天气的任务型对话为例,根据专家知识,我们会预先定义该任务的意图和相应的槽,这句话该怎么理解呢?
比如用户输入:“今天深圳的天气怎么样?”,此时用户所表达的是查询天气,在这里我们可以认为查询天气就是一种意图,那具体查询哪里的天气,哪一天的天气?在这里用户也传递出了这些信息,(地点=深圳,日期=今天),而在这里地点和日期就是信息槽。
在一个任务型对话系统中会含有多种意图和槽值,对于意图识别来说本质上就是一个文本分类的任务,而对于槽值填充来说本质上是一个序列标注的任务(采用BIO的形式来标注)。
还是以“今天深圳的天气怎么样?”为例,在意图识别时用文本分类的方法将其分类到“询问天气”这个意图,而在做槽值填充时采用序列标注的方法可以将其标注为:
今 天 深 圳 的 天 气 怎 么 样
B_DATE I_DATA B_LOCATION I_LOCATION O O O O O O
除了上述两个主要的内容,NLU中还会涉及到领域识别,语义消歧等。
3、DST对话状态跟踪
首先我们来看下对话状态和DST的定义。
对话状态:在tt时刻,结合当前的对话历史和当前的用户输入来给出当前每个slot的取值的概率分布情况,作为DPL的输入,此时的对话状态表示为StSt。
DST(对话状态追踪):就是根据所有对话历史信息推断当前对话状态StSt和用户目标。
由于在ASR和NLU这两个环节会存在误差,因此输入到DST中的内容是N-best列表(对于ASR,不是输入一条句子,而是N条句子,每条句子都带一个置信度。对于SLU,不是输入一条意图(槽值对),而是N个意图(槽值对),每个意图(槽值对)都带一个置信度)。所以DST往往也是输出各个状态的概率分布,这样的表示也方便在多轮对话中对状态进行修改。具体的情况如下图所示:
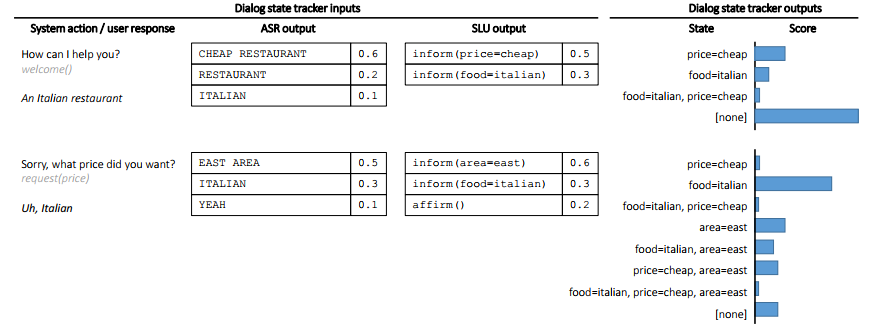
4,DST的常用方法
DST的常用方法主要有三种:基于规则的方法,生成式模型,判别式模型,目前来看判别式模型的表现最好,也是当前研究的最多的方向。
1)基于规则的方法
基于规则的方法一般是用1-best的结果作为输入,而且输出的状态也是确定型,基于规则的方法需要大量的人工和专家知识,因此在较复杂的场景适用性不强。当然基于规则的方法也有它的优点,基于规则的方法不依赖于对话数据,因此在没有对话数据的情况下很适合冷启动。基于规则的方法用N-best的结果作为输入也有研究,但总的来说实现起来很复杂。
2)生成式模型
生成式模型主要是利用贝叶斯网络推断来学得整个状态的概率分布,其通用表达式如下:
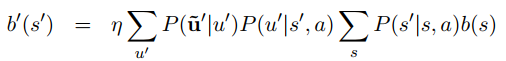
上面式子中b(s)b(s)代表上一时刻状态的概率分布,b′(s′)b′(s′)代表当前时刻的状态分布,u′u′代表当前时刻的用户输入,u~′u~′代表当前用户输入的观测输出,s′s′代表当前时刻的状态,ss代表上一时刻的状态,aa代表上一时刻的动作,ηη是一个常数。
可以看出上面的公式还是比较复杂的,因此实现起来也比较复杂,传统的生成式方法还要列出所有可能的状态,以及状态概率转移矩阵等。
3)判别式模型
判别模型用一个最简单的公式建模,可以表示成:
b′(s′)=P(s′|f′)b′(s′)=P(s′|f′)
其中b′(s′)b′(s′)表示当前状态的概率分布,而f′f′表示对ASR/NLU的输入的特征表示,早期的判别模型会利用SVM,最大熵模型,CRF等来建模。随着神经网络的兴起,DNN,RNN等模型也越来越多的占领了这个领域。
5、对话系统中的对话策略学习(DPL)
前面也说了DST+DPL组成了任务型对话中至关重要的DM,在开始介绍DPL前,先来看下DST和DPL的关系,以便于从整体上把握整个对话系统。
这里说下dialogue act,按我的理解act包括两类:用户的act和系统的act。
针对用户时,主要是识别用户act,dialogue act对应于SLU,包括意图和领域识别(一般是分类)+ 槽填充(一般是序列标注)。
针对系统时,主要是识别系统act,dialogue act对应于DPL,表明在限制条件(之前的累积目标、对话历史等)下系统要执行的动作(接下来的策略),这个动作可能不是追求当前收益最大化,而是未来收益最大化。
至于dialogue act是个什么任务,我感觉分类、序列标注、结构预测都OK。其对应的输入输出应该就是SLU的输入输出、DPL的输入输出。
DPL建模和实例说明
这里再重新回顾一下DST的建模,然后再对DPL建模。
何谓对话状态?其实状态St是一种包含0时刻到t时刻的对话历史、用户目标、意图和槽值对的数据结构,这种数据结构可以供DPL阶段学习策略(比如定机票时,是询问出发地还是确定订单?)并完成NLG阶段的回复。